
OpenAIの最新画像生成モデルであるGPT-Image-1.5は、制御性、視覚的な忠実度、マルチモーダル統合の面で大きな飛躍を遂げました。初期の独立した拡散モデルとは異なり、GPT-Image-1.5はより広範なGPTエコシステムに深く統合されており、開発者は自然言語を使用して、より高い精度と一貫性で画像を生成、編集、反復することができます。
本ガイドでは、以下の内容について解説します。
- GPT-Image-1.5とは何か
- 従来の画像モデルとの違い
- APIの効果的な使用方法
- 本番環境でのワークフロー
GPT-Image-1.5とは?
OpenAIが新たにリリースした画像モデル「GPT‑Image‑1.5」は、APIを通じて高品質で制御可能な画像を提供することを目的としています。単なる遊びではなく、実務での利用を前提に構築されています。
また、本モデルはOpenAIのより広範なエコシステムの一部として組み込まれているため、プロンプト生成に役立つテキストモデルや、画像を理解するビジョンモデルと連携可能です。さらに、エージェント、パイプライン、SaaSツールといった自動化ワークフローに組み込むこともできます。
主要な機能 – OpenAIによる定義
- プロンプトに対する高い忠実度を備えたテキストからの画像生成
- 指示に基づく編集機能 – モデルに指示を与えることで既存の画像を修正可能
- 反復的な洗練ワークフロー – 生成、調整、再生成のサイクル
- 複数回の実行における優れた一貫性

何が変わったのか
1. クリエイティビティから制御性へ
従来のモデルは非常にクリエイティブでしたが、予測不可能でもありました。何が出てくるか分からない状態でしたが、新しいモデルはより構造化された出力を生成し、プロンプトにより忠実に従います。
2. 単一出力から反復ワークフローへ
旧バージョンでは、一度「完成品」の画像を生成して終了することが推奨されていました。GPT‑Image‑1.5は、「生成・編集・洗練・拡張」というループを回すために設計されています。
3. デモツールから本番インフラへ
これは重要です。本モデルは、ECサイトの画像パイプラインやマーケティングのクリエイティブ自動化、AIを活用したデザインツールなど、実際の業務ワークロードに向けて設計されており、単なるギャラリー用の作品作りだけを目的としていません。
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| 機能 | GPT-Image-1.5 | DALL·E |
| プロンプト精度 | 高 | 中 |
| 編集能力 | 強力 | 限定的 |
| 一貫性 | 高 | 低 |
| ワークフロー対応 | 本番利用可 | デモ向き |
| API統合 | ネイティブ | 限定的 |
なぜ開発者にとって重要なのか
これまで、次のような問題に直面したことはありませんか?
第一に、反復処理に時間がかかること。
画像を生成しても、あと一歩ということがあります。色が違ったり、背景が間違っていたりする場合、従来のモデルではゼロから再生成する必要があり、時間とAPIクレジットを浪費していました。GPT‑Image‑1.5では編集が可能なため、色を変えたり背景を差し替えたりして、他の要素を維持できます。これにより、反復にかかる時間を大幅に短縮できます。
第二に、プロンプトが無視されること。
詳細な説明を書いても、モデルが半分しか反映しなかったり、頼んでいないものを追加したりすることがありました。このモデルは指示を正確に反映します。完璧ではありませんが、以前より格段に向上しており、オブジェクトの関係性は維持され、シーンの構成は指示通りになり、スタイルの指定も正しく適用されます。
第三に、スケールに伴う一貫性の欠如。
同じ製品の画像を10枚生成しても、まるで10人のカメラマンが撮ったかのように見えてしまうことがあります。光や角度、色がバラバラでは、ECサイトやブランディングには使えません。GPT‑Image‑1.5はそうしたバラつきを抑えるように学習されており、バッチ全体を通して統一感のある出力が得られます。
第四に、多くのツールでAPI統合が後付けのように感じられること。
スタンドアロンのアプリは試すには便利ですが、画像生成をバックエンドシステムに組み込む際にはWeb UIは役に立ちません。GPT‑Image‑1.5には認証、エンドポイント、レート制限、Webhookを備えた本格的なAPIが付属しており、開発者が真に必要とする環境が整っています。
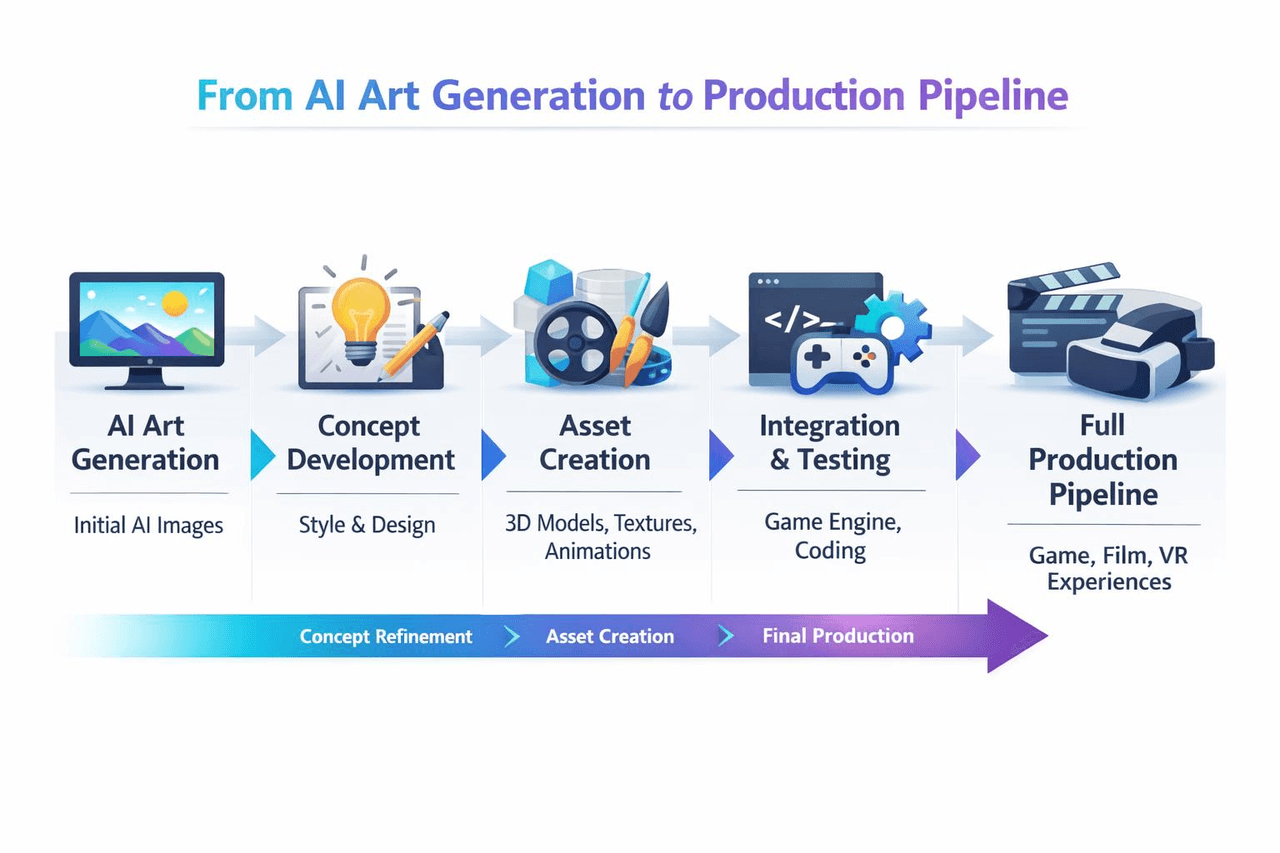
API統合ガイド
Atlas Cloudでは、複数のモデルを並べて比較することができます。まずはプレイグラウンドで試して感触を確かめ、その後に単一のAPIですべてを呼び出すことが可能です。
方法1: Atlas Cloudプレイグラウンドで直接使用する
GPT-Image-1.5を使い始める最も簡単な方法は、Atlas Cloudプレイグラウンドを直接使用することです。これは、開発者、デザイナー、マーケターがコードを書かずにAI画像生成を試せるWebベースのインターフェースです。
方法2: API経由でアクセスする
ステップ1: APIキーを取得する
コンソールでAPIキーを作成し、後で使用するためにコピーします。
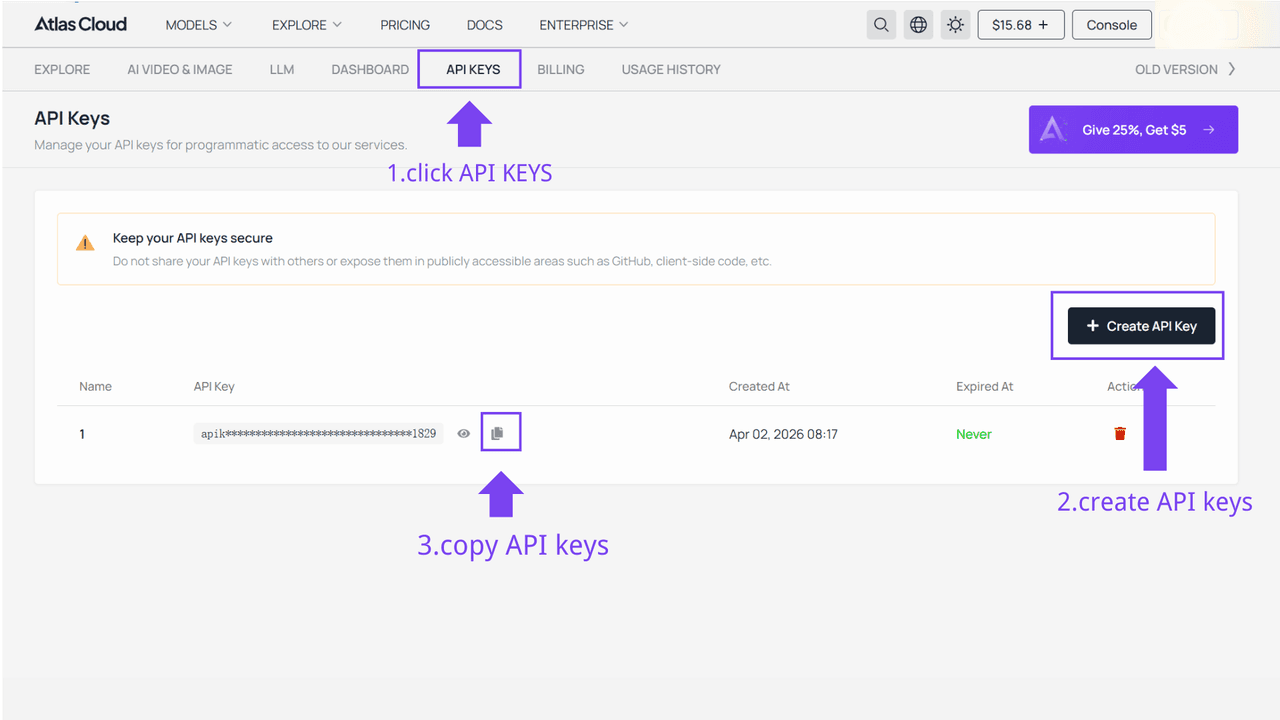
ステップ2: APIドキュメントを確認する
当社のAPIドキュメントで、エンドポイント、リクエストパラメータ、認証方法を確認してください。
ステップ3: 最初のAPIリクエストを実行する(Pythonの例)
以下は、OpenAI GPT-Image-1.5を使用して画像を生成するシンプルな例です:
plaintext1import requests 2import time 3# ステップ1: 画像生成を開始 4generate_url = "https://api.atlascloud.ai/api/v1/model/generateImage" 5headers = { 6 "Content-Type": "application/json", 7 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 8} 9data = { 10 "model": "openai/gpt-image-1.5/text-to-image", # 必須 11 "enable_base64_output": False, # Trueの場合、出力はURLではなくBASE64文字列としてエンコードされます 12 "enable_sync_mode": False, # Trueの場合、結果が生成されアップロードされるまで待機してから応答を返します 13 "output_format": "jpeg", # 出力画像のフォーマット。jpeg | png 14 "prompt": "end-to-end AI image production pipeline, prompt generation, image creation, QA, deployment, SaaS workflow diagram\n\n", # 必須。生成のためのポジティブプロンプト 15 "quality": "medium", # 生成画像の品質。low | medium | high 16 "size": "1536x1024", # 生成メディアのサイズ(幅×高さ)。デフォルト: "1024x1024"。1024x1024 | 1024x1536 | 1536x1024 から選択 17} 18generate_response = requests.post(generate_url, headers=headers, json=data) 19generate_result = generate_response.json() 20prediction_id = generate_result["data"]["id"] 21# ステップ2: 結果をポーリング 22poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 23def check_status(): 24 while True: 25 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 26 result = response.json() 27 if result["data"]["status"] == "completed": 28 print("Generated image:", result["data"]["outputs"][0]) 29 return result["data"]["outputs"][0] 30 elif result["data"]["status"] == "failed": 31 raise Exception(result["data"]["error"] or "Generation failed") 32 else: 33 # 処理中、2秒待機 34 time.sleep(2) 35image_url = check_status()
本番ワークフロー – 統合の進め方
GPT‑Image‑1.5を活用するチームは、通常以下のようなパターンに従います。
- ステップ1: プロンプトの標準化。GPTテキストモデルを使用して、構造化されたプロンプトを自動生成するチームもあります。
- ステップ2: APIの呼び出し。画像を生成します。
- ステップ3: 自動品質保証(QA)。スタイルの整合性をチェックし、不良品をフラグ立てします。
- ステップ4: 反復ループ。プロンプトを通じて画像を編集し、バリエーションを作成します。
- ステップ5: デプロイメント。アセットを保存し、フロントエンドやユーザーに提供します。
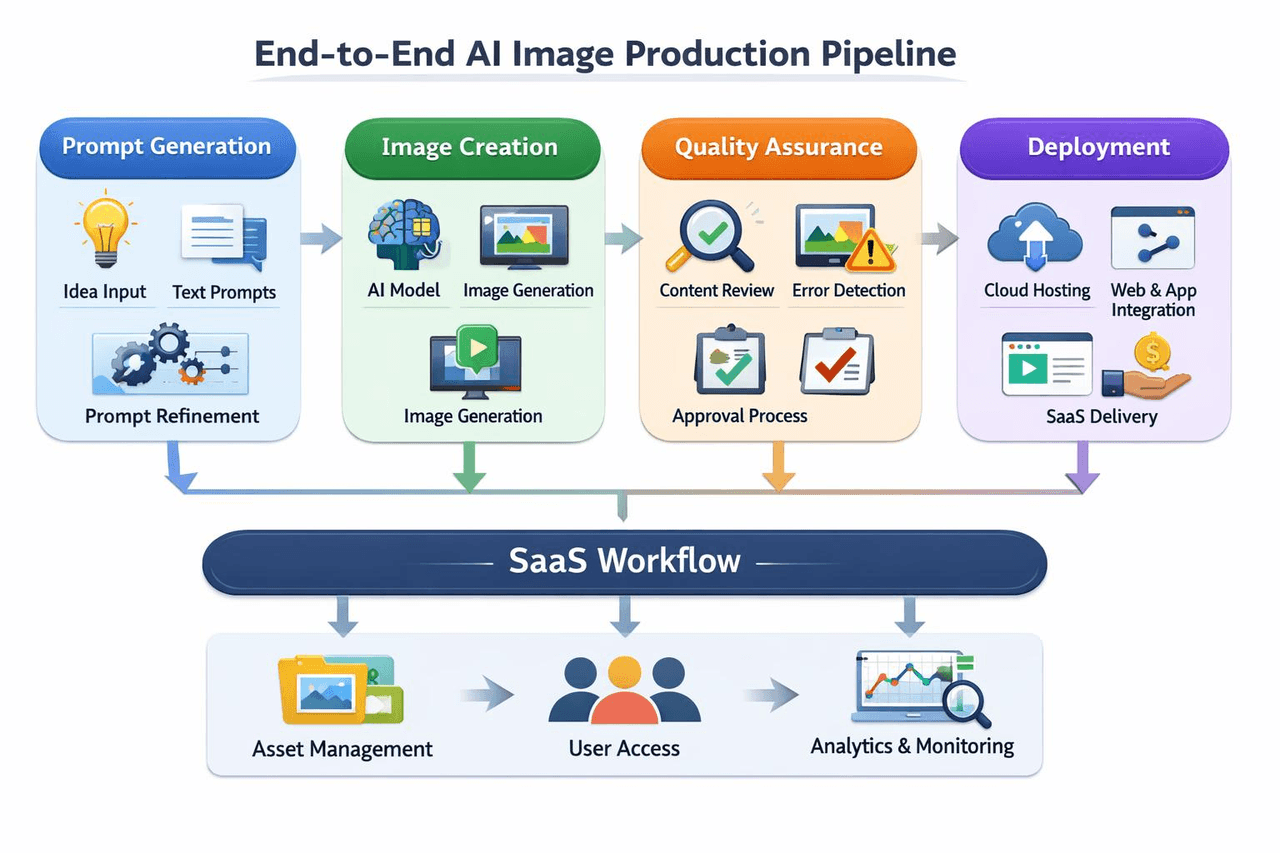
よくある質問(FAQ)
1. GPT-Image-1.5と他のAI商品撮影ジェネレーターの違いは何ですか?
いわゆるAI商品撮影ツールのほとんどは、オープンソースモデルをテンプレートで包んだだけのものです。白い背景の画像をアップロードしてシーンを選ぶと、合成される仕組みです。確かに速いですが、細部を調整できません。「照明がいまいち」「影のつき方がおかしい」といった場合、修正は困難です。
GPT‑Image‑1.5はそのような仕組みではありません。既存のテンプレートを提供するのではなく、あなた自身が制御できるように設計されています。「サイドからの光」「右側に落ちる影」「背景を少しぼかす」といった指示を出すことで、正確に反映されます。短所としては、プロンプトの記述方法を学ぶ必要がある点ですが、一度コツを掴めば、同じプロンプトを何百枚もの画像に適用できます。これが、本格的な製品画像パイプラインを構築するチームが、ワンクリックツールではなく、OpenAIのAPIを使って独自のシステムを構築する理由です。
2. Text-to-ImageのOpenAI APIには、どのようなプロンプトが最適ですか?
短すぎるのも、小説のように長すぎるのも適していません。ベストな構成は、「何が写っているか」「どこにあるか」「どのような照明か」「どんなスタイルか」を分解して伝えることです。
例えば、「モダンな椅子」とだけ書くと、モデルはランダムな椅子を生成します。しかし、「ウォールナット材のラウンジチェア、大きな窓のある明るいリビングルーム、左からの柔らかな日光、ミッドセンチュリーモダンなスタイル、クリーンな構図」と書けば、結果の信頼性は劇的に向上します。
モデルはあなたの心を読み取ることはできません。シーンを要素に分けて伝える必要があります。商品画像であれ何であれ、そうすることで確実な違いが生まれます。
3. 従来の撮影に比べて、AI商品撮影ジェネレーターを使う利点は何ですか?
最大の利点はスピードです。プロンプトを最適化すれば、数分で数十枚の商品画像を作成できます。従来の撮影であれば、その時間はまだ照明をセッティングしている段階でしょう。
もう一つの大きな利点は柔軟性です。従来の撮影では、背景や照明を変えるには撮り直しが必要です。GPT‑Image‑1.5なら、「背景をレンガに変えて」「光を暖色にして」「赤いスニーカーを青にして」とタイプするだけです。たった一行の指示で、静止画像が即座に編集可能なアセットに変わります。
そして一貫性です。従来の撮影では光の加減や色が撮影ごとに微妙にズレるため、同じ商品を撮影してもまるで別の人が撮ったように見えてしまいます。モデルを使えば、プロンプトを維持することで10枚の写真を一貫したセットとして生成できます。ECやブランディングにおいては、一枚の綺麗な写真よりも、この「一貫性」の方がはるかに重要です。






