概要
2026年5月中旬、Qwen3.7-MaxとQwen3.7-PlusがLM Arenaにひっそりと登場しました。 @Alibaba_Qwen は「Alibabaはテキスト部門で6位、ビジョン部門で5位」という一文でコミュニティの期待値を設定しました。6月2日、Alibaba Cloudの通義千問(Tongyi Qianwen)チームはこのマルチモーダルエージェントモデルを正式にリリースしました。すでにAlibaba Cloud Model StudioおよびQwen Chatで利用可能であり、APIアクセスは alibaba/qwen3.7-plus で、価格は入力/出力100万トークンあたり約 USD0.40 / USD1.60 となっています。
公式のポジショニングは明確です。Plusはコスト効率の高いマルチモーダルモデル、Maxはテキストフラッグシップモデルです。
私たちは午後を費やして、Qwen3.6-plus、Qwen3.7-plus、Qwen3.7-Max に対するハードなテストスイートを実行しました。これには 10の実務バグの自動修正、AIME 2025数学コンテストの15問、さらにマルチモーダル性能、速度、コストの広範な比較が含まれます。
その結果は、一般的なモデルランキングとしてではなく、5つのタスクレベルの所見として読むのが最適です:
- BugFind-10の単一実行:Plusがすべての外部pytestチェックに合格。この10タスクのスイート、公式Stirrup足場、単一実行の設定において、Plusは10/10を記録し、Maxと3.6-Plusは9/10でした。これはこの設定におけるタスク適合性を示すものであり、一般的なコーディングランキングとして一般化すべきではありません。
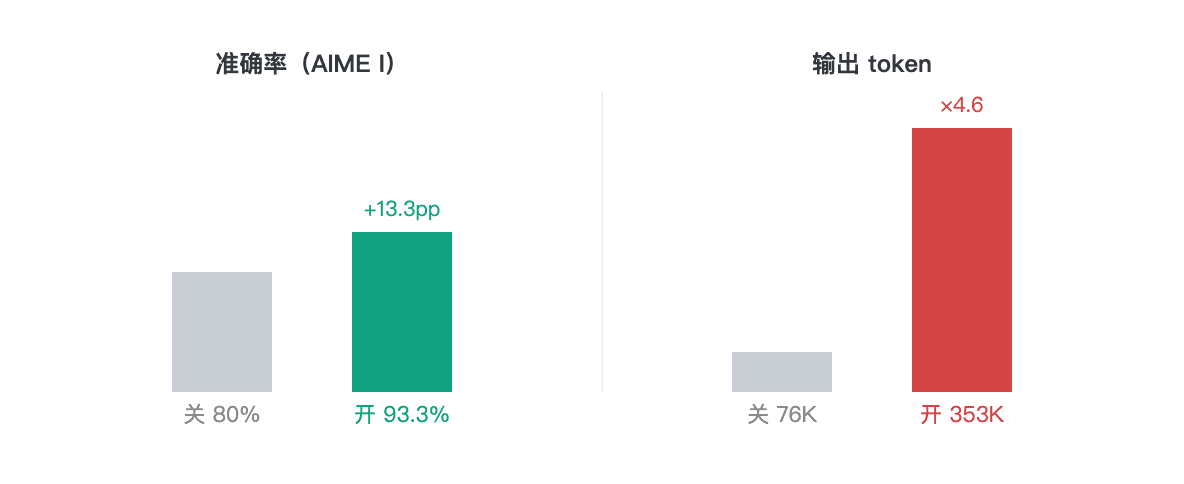
- 数学:Thinking(思考モード)を有効にしたPlusは、Maxと同じ単一実行スコアに到達。コンテスト数学15問において、PlusとMaxはどちらも14問正解しました。この実行において、Qwen3.7-plusはQwen3.7-Maxよりも大幅に短い時間で処理を完了しました(1問あたり113秒 vs 303秒)。
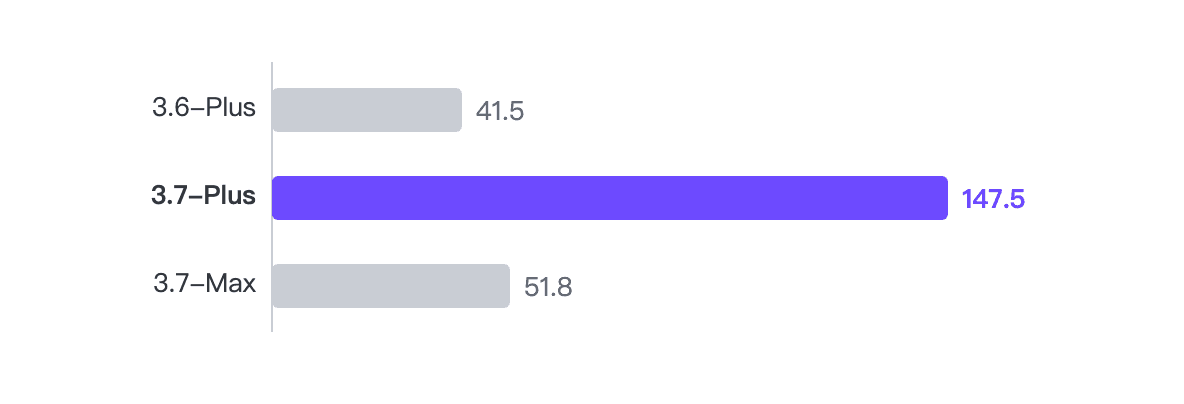
- 世代を超えた速度向上:エージェントタスクにおいて、Qwen3.7-plusのエンドツーエンドのスループットは 147.5 t/s に達し、Qwen3.6-plusの41.5 t/sから 3.55倍の向上 を記録しました。前世代では完了できなかった数学タスクも容易に完走しました。
- マルチモーダルには依然として欠陥あり:制御されたマルチモーダルテストでは、Qwen3.7-plusは単純な画像質問には正しく回答しましたが、公式のサンプル画像である
dog_and_girl.jpegについては「電車と群衆」と説明しました。 - Maxに近い能力と遅延の利点:今回の複数のテストにおいて、Qwen3.7-plusはQwen3.7-Maxに近い結果を出しながら、より低いレイテンシを示しました。これは一般的なランキング主張ではありません。
以下に、エンジニアリングリード向けの完全なテストデータ、手法、およびモデル選定の推奨事項を記載します。すべての比較はこの小規模サンプル、単一実行、固定された足場の範囲内に限定されます。
0. モデル能力とリーダーボードの背景
Alibaba Qwenの製品ラインは3.6世代ですでにパターンが確立されていました:Max = テキストフラッグシップ、Plus = マルチモーダル長文脈モデル。バージョン3.7もそのロジックを継承しています。
| 次元 | Qwen3.7-Max | Qwen3.7-Plus |
|---|---|---|
| 入力モダリティ | 主にテキスト | テキスト + 画像 |
| 主な強み | 推論の上限、長期ホライゾンエージェント | 1Mコンテキスト、ビジョン、ハイブリッド思考、低単価 |
| Arena (2026-05) | テキスト全体で約13位 | ビジョン部門で約16位 |
| ゲートウェイ価格 (06-01) | Mトークンあたり USD1.25 / USD3.75 | Mトークンあたり USD0.40 / USD1.60 |
1. 公式はPlusをどう位置づけているか?
Alibaba Qwenのローンチ投稿 のメッセージは一言に集約されています。
「One model. Sees, thinks, codes, acts. (一つのモデルで、見て、考えて、書いて、動く)」
核心となるセールスポイントは、GUIとCLIの統一操作を備えたマルチモーダル対話型ハイブリッドエージェント、多才なコーディングエージェント、およびクロスエージェントフレームワークの汎用性です。Qwenのコア開発者である shuai bai_ 氏は次のように補足しています。
私たちの目標は、マルチモーダルAIを受動的な画像キャプション生成から、能動的な問題解決者へと進化させることです。見て、推論し、コードを書き、インターフェースを操作し、結果を検証できる存在。これは真のエージェント型マルチモーダルインテリジェンスへの一歩です。
公式スレッドのパフォーマンス投稿は、以下のような重要なポジショニングを示しています:
- テキスト性能は「Maxレベルに近い」(ベンダーの主張)
- マルチモーダルの改善は 核心的なエージェント能力(複雑な視覚理解、視覚的推論、ツール使用、コード/GUI実行)に集中
| Xでの一般的な主張 | ソース | 私たちの結果 | 結論 |
|---|---|---|---|
| Plusのテキストは「Maxに近い」 | 公式 | Thinking付きAIME:同点14/15;Plusは 2.68倍高速 | 単一実行の数学スコアは同等、今回はレイテンシが低い |
| コーディング/長期作業にはMaxが優れる | Vercel docs | BugFind:Plus 10/10, Max 9/10;Plus 147.5 t/s | このタスクは盲目的な前提の適用を支持しない |
| ビジョンリーダーボードは強力 | Arena | 公式サンプル画像は失敗、制御画像は ✓ | リーダーボードの高スコアと個別の画像失敗は共存しうる |
2. 私たちの評価手法:4つのタスクタイプと1つの厳しいルール
テストの公平性を保つため、私たちは BugFind-10 という小規模スイートを維持しています。これには、価格計算、配列境界、パス処理、同時実行、JSON、SQL、キャッシュ動作、Unicode、設定などに関する10の実務バグが含まれます。各バグにはpytestテストが付属しています。モデルは公式のStirrupエージェントフレームワーク内でローカルコード実行ツールを使用して動作し、「再現→特定→本番コードの編集→テスト実行」というフルループを自力で完結させる必要があります。
なぜ独自のテストスイートを構築するのか?
公開リーダーボードには3つの一般的な失敗モードがあります。
- 暗記とリーク:フラッグシップモデルは古い問題ですでに飽和しています。私たちは、モデルのトレーニングカットオフ後に公開されたコンテストであるAIME 2025を選択しました。
- ベンダーの自己申告は独立した再テストから乖離する可能性がある:データセットのバージョン、Thinkingが有効か、ツールが許可されているかによって、同じメトリクスでも大きく変化します。
- エージェントのベンチマークは足場(scaffolding)に依存する:エージェントフレームワークが異なれば、スコアが2〜3ポイント変動します。私たちはフレームワークを公式のStirrupに固定し、外部検証を追加しました。
4つのテストタスク
| タスク | 測定するもの | 核心メトリクス |
|---|---|---|
| Gate check | アイデンティティ確認、思考支援、ビジョン能力 | 合格 / 不合格 |
| BugFind-10 | 10の実務コードバグの自動修正 | 外部pytest合格率、モデル呼び出し回数、壁時計時間 |
| AIME 2025 I | 15問のコンテスト数学問題 | 正解率、1問あたりの時間、Thinkingのアブレーション |
| Quick Eval | 8問の小学校レベルの文章題 | 速度のベースライン、TTFT、単純タスクでのThinkingの利益 |
私たちの厳しいルール:コードスコアは外部Pytestでのみカウントする
これはレビュー全体の基盤です。また、「テストに合格した」と言うだけのエージェントでは不十分であるというHacker Newsの懸念にも直接対応しています。
プロセス:
- エージェントがワークスペース内のコードを編集し、自身でpytestを実行し、CHANGELOGを書く。
- 変更された本番コードを隔離された環境にコピーし、独立してpytestを実行する。
- ステップ2の終了コードと失敗スタックのみを公開する。
例え: エージェントは試験を受ける学生です。提出された回答を読むだけでなく、その回答を別の部屋に持ち込み、再採点することで、エージェント自身の成功したという主張を信用しないようにしています。
3. コードとエージェントの能力
3モデルの概要
| モデル | pytest結果 | 修正率 | LLM呼び出し | 壁時計時間 | エンドツーエンド t/s |
|---|---|---|---|---|---|
| Qwen3.6-Plus | 1失敗, 26合格 | 9/10 | 63 | 334s | 41.5 |
| Qwen3.7-Plus | 27合格 | 10/10 | 52 | 205s | 147.5 |
| Qwen3.7-Max | 1失敗, 26合格 | 9/10 | 20 | 249s | 51.8 |
PlusがBugFindの単一実行でより良い結果を得たことは予想外でした:
- このテストで10/10を達成したのはPlusだけでした。
- Maxは呼び出し回数が最も少なかったが、満点には至りませんでした。 3.7-Maxはわずか 20回 のモデル呼び出しで停止しました。これは3モデル中で最小です。「長時間考え、1つの大きな変更を行う」傾向があり、反復回数が少なくなりました。対照的に3.7-Plusは52回の呼び出しを行い、編集・実行・フィードバックの確認・再編集を厭いませんでした。
- Plusは壁時計時間が最短で、スループットが最高でした。 IDEエージェント体験においては、リーダーボードの数ポイントのEloレーティングよりも、これがはるかに重要です。
1つのタスク、3つの修正哲学:task05の深掘り
このタスクは「不正なJSONを黙って無視してはいけない」というルールをテストします。解析中に不正なデータを見つけた場合、成功したふりをして空のオブジェクトを返してはならず、明確にエラーを報告する必要があります。元のバグ:
python1def safe_parse(data: str): 2 try: 3 return json.loads(data) 4 except Exception: 5 return {} # バグ:例外を飲み込んでいる
テストの要件:
- 「これはJSONではない {」のような入力に対し、空の辞書 {} を返さないこと。
- 「bad」のような括弧のない無効な入力に対し、例外を発生させること。
Maxのアプローチ(外部テスト ✗):カスタムの JSONParseError を発生させる。
クリーンな解決策に見えますが、「これはJSONではない {」に対して即座に発生したため、最初のテストすら実行できず失敗しました。しかし、MaxのCHANGELOGは自信満々に「27合格」と述べました。これが外部検証を必須とする理由です。エージェントの自己評価と外部監査はしばしば乖離します。
3.6-Plus(外部 ✗):最初のハードルで失敗。
3.7-Plus(外部 ✓):
python1if re.search(r'[\{\[\]\}]', data): 2 return {"error": str(e), "raw": data} 3raise ValueError(f"Invalid JSON: {e}") from e
括弧を含む不正な入力に対しては、{} と区別できるエラーオブジェクトを返し、括弧がない場合は例外を発生させます。テスト契約の両面を正確に満たしました。
なぜMaxはこのタスクで満点を逃したのか?呼び出し回数から始めましょう。
[  ]{width="64%"}
]{width="64%"}
3.7-Maxはわずか 20回 のモデル呼び出しで停止しました。3.7-Plusは52回呼び出し、反復を厭いませんでした。環境との繰り返しの相互作用が必要なエージェントコーディングタスクでは、今回のMaxのように反復回数が少ないことは、エッジケースをカバーできない可能性につながります。これは見過ごされがちな事実を示しています:エージェントタスクにおいて「より深い推論」が必ずしも「より安定したデリバリー」を意味するわけではありません。ツールのフィードバックをうまく使うことも同等に重要です。
エンジニアリングの教訓:
- エージェントタスクでは、環境と格闘する意欲(Plusは52の対話ターンと98のコード実行)が、最小限の反復よりも重要。
- インタラクティブなバグ修正において、「例外を投げる」というクリーンな解決策が、汚いデータを区別可能な形で返すことよりも常に優れているとは限らない。
4. 推論と数学:Thinkingモードはコストの決断
Qwen3.7シリーズは enable_thinking スイッチで制御される「ハイブリッド思考」を強調しています。このスイッチを有効にする価値はあるでしょうか?難易度の異なる2つのタスクグループでアブレーションを実行しました。ハードセットは AIME 2025 I であり、モデルのトレーニングカットオフ後に公開されたため、汚染に対してより耐性があります。
[  ]{width="64%"}
]{width="64%"}
Thinking(思考モード)スイッチの限界利益
推論を有効にすると、PlusはMaxと同じ単一実行のAIMEスコアに到達しました。 3.7-Plus(Thinking On)と3.7-Maxはどちらも14/15でしたが、Plusは1問あたり113秒、Maxは303秒でした。今回の実行では、Maxのレイテンシの長さがより高いスコアを生み出すことはありませんでした。
8問の小学校レベルの文章題では、どちらのモードも正解率は100%でした。Thinkingを有効にすると、トークン消費が24%増加しただけでした。両方のセットを合わせると、結論は明白です:
単純なタスクではお金を節約するためにThinkingをオフにし、難しいタスクで精度を買うためにオンにする。 推論をグローバルに有効にしておくと、単純なリクエストでも4倍以上のコストを支払い続けることになります。スイッチの価値は、タスクの難易度に応じて動的にルーティングできる点にあります。
Max vs Plus:今回の実行でレイテンシはどこから来たのか
Maxも14/15のスコアで、同じくI-14を落としました(予測69、正解60)。同じテスト、同じミス、同じ失敗パターンであり、「Maxの方が賢く、異なるハードケースで失敗した」わけではありません。MaxはI-15を解きましたが、Plusは逃したため、超難問にはばらつきがあり、一度の実行で一方のモデルが全体的に強いと断言することはできません。
しかし、速度の差は顕著でした。I-2の問題において、Maxは 261秒、Plusはわずか 108秒 でした。全体として、Maxの平均は68.3 tps、Plusは205.4 tpsで、約 3倍の高速化 を実現しました。
結論: Thinkingが有効になれば、Plusはこのコンテスト数学セットにおいてMaxと同じ単一実行スコアに到達し、明確なレイテンシとコストの利点を維持しました。
5. 速度、世代間のギャップ
[  ]{width="64%"}
]{width="64%"}
エージェントのスループット比較
BugFind runner_summary.json から抽出した実際のエンドツーエンド速度:
- 3.7-Plus: 147.5 t/s
- 3.7-Max: 51.8 t/s
- 3.6-Plus: 41.5 t/s
世代間の改善(3.6 → 3.7 Plus)は約 3.55倍 です。同世代のPlusとMaxの比較では約 2.85倍 です。
3.6-Plusで数学を実行すると、遅すぎて完了できない という事態になりました。推論が各問題の限界まで走り、1問あたりの出力が16K-52Kトークンに達し、それぞれ297-932秒かかりました。最初の6問だけで 46分 を要しました。ユーザーが許容できる時間内で「解ける」ことと「完了できる」ことは異なる主張であり、リーダーボードが隠し、ユーザー体験が露呈させる次元です。
エンジニアリングチームへのアドバイス: Thinkingモデルでは、従来のタイムアウトや max_tokens 戦略は失敗する可能性があります。合計トークン予算、合計壁時間制限、または推論トークン制限が必要です。
6. マルチモーダル:制御画像は合格、公式サンプルは不失敗
| テストサンプル | 入力 | モデル出力 | 判断 |
|---|---|---|---|
| 制御画像 | 赤/青ブロックPNG | 「青、オレンジ」 | ✓ 正解 |
| 公式サンプル | dog_and_girl.jpeg | 「電車のそばに立つ人々のグループ...」 | ✗ 完全に間違い |
Arena VisionはPlusを約16位(プレビュー)にランク付けしています。私たちのテストは、リーダーボードの高スコアと個別の画像失敗は共存しうることを示しています。
モデル選定へのアドバイス: MMUMやChartQAのような標準的なベンチマークは実行していないため、Plusのビジョン能力がプロダクションレディであるかについての広範な主張はしません。しかし、自社の業務ドメイン(OCR、チャート、UIスクリーンショット、領収書)から20-50枚の画像をテストする方が、リーダーボードを読むよりもはるかに信頼性が高いことは明白です。
7. コスト:今回の評価ラウンドの費用
3つのモデルを4つのタスクタイプで実行した結果、実際のQwen API利用は約 200万トークン で、プレースホルダーコストは約 2-3ドル でした。
洞察: 本格的な評価ラウンドの費用は食事代程度です。チームはそのお金を、マーケティングコピーではなく、自社のタスクを再実行することに費やすべきです。
コストの教訓: エージェントのコストは単価ではなく、**「ターン数 × ターンごとの履歴の長さ」**です。最適化は、より安いモデル価格だけでなく、履歴圧縮、サブエージェント分解、キャッシュをターゲットにすべきです。
8. 開発者向けのモデル選定アドバイス
| シナリオ | 推奨 |
|---|---|
| エージェント開発 / コーディング / バグ修正 | 3.7-Plus をデフォルトの候補セットに入れる。スループットが高く反復が多い。Maxは高難易度へのフォールバックとして保持する。 |
| 中難易度の推論・数学 / レイテンシに敏感 | Thinking有効の3.7-Plus。Maxと同等の精度で低レイテンシを実現。 |
| 単純なQ&A / 分類 / 抽出 | Thinking無効の3.7-Plus。余計な推論コストを節約。 |
| 3.6-Plusを利用中 | アップグレードする。スループットの3.5倍の向上はユーザー体験を根本から変える。 |
9. 制限事項と開示
このレビューは1日のスナップショットであり、学術論文ではありません。
- 単一実行:BugFindもAIMEもpass@kを使用していません。
- 競合他社の比較なし:Claude、GPT、Gemini、DeepSeekはテストしていません。
- 3.6-PlusはAIMEを6問しか完了していない。
- 価格はプレースホルダーの推定値:最新のゲートウェイ価格を確認してください。
- テストされたのは招待ベータ版:正式SKUでは動作が異なる場合があります。
最終的な注意点
2026年6月の公式ナラティブにおいて、Qwen3.7-Plusはビジョンリーダーボードにおける中国のフラッグシップ層であり、コスト効率の優れた選択肢です。
私たちの再現可能な宇宙においては、以下のような存在です。
- 今回の実コードバグ修正テストで唯一10/10をスコアしたモデル。
- Thinking有効の数学コンテストにおいて、Maxと同じスコアをより低いレイテンシで達成したモデル。
- 前世代から3.55倍のスループット向上をもたらし、「完了できない」を過去のものにしたモデル。
- 公式サンプル画像でハルシネーションを起こしながらも、制御画像テストには合格したモデル(スクリーンショット1枚でビジョンモデルを選んではならないことを再認識させる)。
もしあなたがプロダクション用のモデルを選択しているなら、このレビューを付随するデータ可視化版とともに読んでください。数字を第一に信頼し、私たちがこれを「再投稿」ではなく「評価」と呼んでいる理由を確認してください。
2026年のAIモデルの洪水において、再現可能な監査級の証拠のみが技術的決定を下すための硬貨です。






