
厳格なID3ジャンルタグは、あなたのローカル音楽コレクションを台無しにしています。AudioMuse-AIの高度な音響解析とAtlasCloudのスケーラブルなAPIを組み合わせることで、静的なメディアファイルのディレクトリを、直感的かつセマンティックな音楽発見エンジンへと進化させることができます。そして、感情に基づいたプレイリストを、セルフホストサーバーへシームレスに配信することが可能になります。
![]()
音楽の温もりを取り戻す:AudioMuse-AIで真に直感的なローカルライブラリを構築する
深夜、デスクで過ごしているときを想像してみてください。エネルギッシュなエレクトロニック・プレイリストを聴きたいわけでも、かといって無機質なクラシック音楽を聴きたい気分でもない。あなたが求めているのは、「雨の日に心を落ち着かせてくれる、静かでアンビエントなインディーフォーク」という非常に具体的なムードです。
もし、NavidromeやJellyfinのセルフホスト環境を開いて、その文章をそのまま検索バーに入力しても、結果はゼロでしょう。
何十年もの間、私たちデジタル音楽愛好家は、ID3タグの細かな整理やアルバムアートの修正に膨大な時間を費やし、流動的な芸術形式を「ロック」「ジャズ」「ポップ」といった硬直的なジャンルの箱に押し込んできました。しかし、正直に言いましょう。ジャンルラベルは20世紀のレコード店マーケティングの遺物であり、音楽が実際に「どのように感じられるか」を理解してはいません。
プライベートな音楽ライブラリ管理の未来は、静的なメタデータにはありません。それはセマンティック(意味論的)なオーディオ解析にあります。大規模言語モデル(LLM)は単なるチャットインターフェース以上の存在であり、あなたの音楽が持つ言葉にできない感情的な重みを解読するための究極の鍵です。オープンソースの AudioMuse-AI を AtlasCloud のようなインテリジェントなLLMルーターと併用することで、ローカルファイルに命を吹き込み、ムード、音の質感、歌詞の意味に基づいたプレイリストを生成できるようになります。
AudioMuse-AIとは?
AudioMuse-AI は、既存のメディア環境とシームレスに連携するように設計された、セルフホスト可能なオープンソースのオーディオインテリジェンスエンジンです。Jellyfin、Navidrome、LMS/Lyrion、Embyといった人気のセルフホスト型音楽プラットフォームに直接統合されるAI脳として機能します。
AudioMuse-AIはテキストタグを解析するのではなく、生のオーディオファイルを処理します。ローカルで動作するニューラルネットワークモデルを実行して複雑な数学的音響ベクトル(CLAP: Contrastive Language-Audio Pretrainingを使用)を抽出し、72言語の歌詞テーマをマッピングします。
一度スキャンが完了すれば、企業のストリーミングアルゴリズムが浅く見えるほどの機能が解放されます:
- 音響クラスタリング: 音楽ライブラリを2Dのインタラクティブな「音楽マップ」上に自動配置し、ジャンルではなく実際の音の波形に基づいて楽曲をグループ化します。
- ソングパス(楽曲の道のり): 出発点としてアップテンポなファンク曲を、目的地としてメランコリックなアンビエント曲を選びます。エンジンがその間の音響的な架け橋を自動計算し、ムードが段階的かつ自然に変化するプレイリストを生成します。
- セマンティックな歌詞検索: 正確な一致検索ではなく、物語のテーマや感情的なコンセプト(例:「小さな町で育つことについての歌」)でライブラリを検索できます。
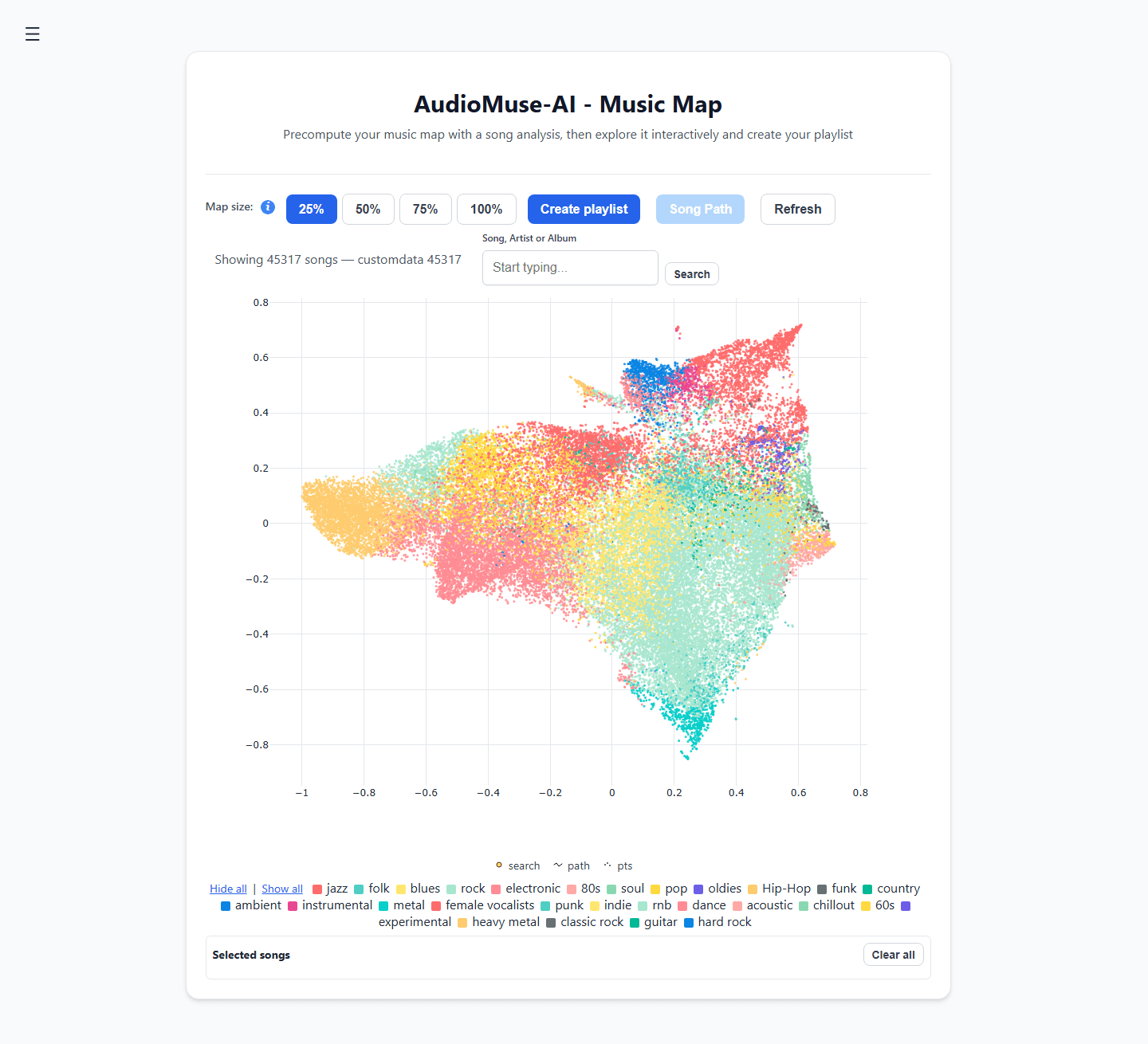
ステップバイステップガイド:セマンティック音楽発見エンジンの構築
メタデータに依存しない完全なセマンティック・プレイリストパイプラインを構築する手順を説明します。
ステップ1:環境の準備とデプロイ
AudioMuse-AIはmacOS、Linux、Windowsでネイティブ動作しますが、標準的なホームサーバーやNAS環境では、Docker Composeが最もクリーンな方法です。
サーバー上にディレクトリを作成し、デプロイメントドキュメントから公式の
1docker-compose.yamlYAML
plaintext1version: '3.8'services:audiomuse:image: neptunehub/audiomuse-ai:latestcontainer_name: audiomuse-aiports:- "8000:8000"volumes:- /path/to/your/music:/music:ro- ./data:/app/dataenvironment:- POSTGRES_PASSWORD=your_secure_password- REDIS_PASSWORD=your_secure_passwordrestart: unless-stopped
⚠️ ハードウェアの注意点: 基盤となるAIモデルは最新のCPU命令セットに大きく依存します。Proxmoxなどの仮想化環境で実行する場合は、AVX2サポートをパススルーするためにCPUタイプが "Host" に設定されていることを確認してください。汎用的なQEMU仮想CPUで実行すると、コンテナは起動直後にクラッシュします。
以下のコマンドで起動します:
Bash
plaintext1docker compose up -d
ステップ2:オーディオフレームワークのスキャン実行
ブラウザで http://YOUR-SERVER-IP:8000 にアクセスすると、初期設定ウィザードが表示されます。メディアサーバー(例:NavidromeのURLとパーソナルAPIトークン)をリンクさせます。
リンク完了後、**「Analysis and Clustering」ダッシュボードに移動し、「Start Analysis」**をクリックします。
エンジンが音響フィンガープリントの計算を開始します。Intel i5搭載のミニPCかRaspberry Pi 5かなど、ライブラリのサイズとハードウェア性能によりますが、この初回解析フェーズには数分から数時間かかる場合があります。
ステップ3:AtlasCloudによるAI脳の強化
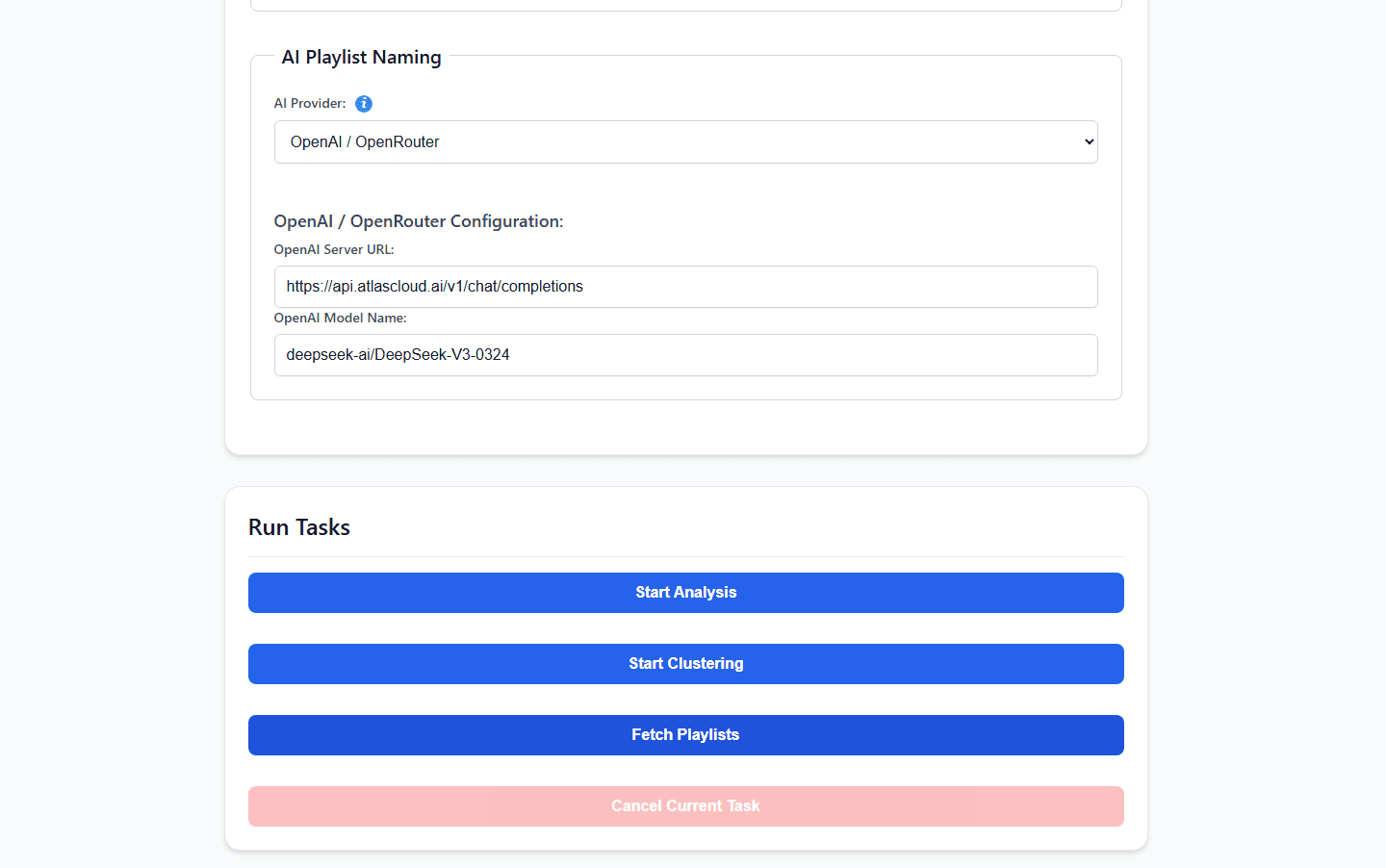
ここで、セルフホスト環境における古典的なボトルネックが発生します。AudioMuse-AIのインタラクティブなプレイリストチャット(app_chat.py)や深層歌詞埋め込みエンジンをすべてローカルで動かすと、NASのCPU負荷が100%に達し、APIタイムアウトやプレイリスト生成の遅延が発生しやすくなります。
ローカルハードウェアを軽量かつ静音に保つため、高度な推論処理を外部APIにオフロード可能です。プロジェクトの OpenAI互換AIプロバイダーガイド に記載されている通り、ネイティブのOPENAIプロバイダーを利用して、AtlasCloud経由でリクエストをルーティングできます。
以下の変数をサーバーのデプロイメント環境設定に追加してください:
Bash
plaintext1AI_MODEL_PROVIDER=OPENAI 2OPENAI_SERVER_URL=https://api.atlascloud.ai/v1/chat/completions 3OPENAI_MODEL_NAME=qwen3.5:9b 4OPENAI_API_KEY=your_secure_atlas_cloud_key
AtlasCloudを活用することで、巨大なモデルをローカルドライブに保持する必要がなくなります。一つのキーだけで、AudioMuse-AIは高性能な推論モデルに瞬時にアクセスでき、自然言語のプロンプトを秒単位のレイテンシで処理できるようになります。
ステップ4:最初のムードプレイリストを生成する
AtlasCloudがセマンティックマッピングを担当するようになったら、**「Instant Playlists」**タブに移動します。システムの境界を超えた能力をテストしてみましょう。非常に抽象的なプロンプトを入力します:
「深夜のドライブに合う雨の雰囲気のプレイリストを作って。最初はアコースティックでスローに、最後に向けてドライブ感のあるエレクトロニックなパルスを取り入れて。」
AtlasCloudがプロンプトの感情的意図を処理し、構造的な設計図をAudioMuse-AIのローカルベクトルインデックスへ返します。瞬時にキュレーションされたセレクションが返ってくるので、**「Export to Media Server」**をクリックすれば、JellyfinやNavidromeを通じてスマートフォンの音楽アプリにプレイリストが即座に同期されます。
比較:ローカルオーディオAI vs 競合製品
| 特徴 | AudioMuse-AI + AtlasCloud | Plex / Plexamp | Spotify / Apple Music |
|---|---|---|---|
| プライバシーと管理 | 完全な所有権。データはローカルに留まり、LLMクエリは安全にプロキシされます。 | 半公開。独自のプロプライエタリなアカウントとPlex Passが必要。 | プライバシーなし。視聴ログは広告追跡のために収益化されます。 |
| メタデータ依存度 | なし。生のオーディオ波形と歌詞テーマを直接解析。 | 高い。解析前に正確な基本タグが必須。 | 絶対。商用のラベルタグとデータベースIDに完全に依存。 |
| コールドスタート性能 | 完璧。マイナーなローカル楽曲も即座に解析しマッピング。 | 低い。Plexデータベースに一致しない楽曲の文脈化は不可。 | 最悪。世界的な再生数が少ない曲はアルゴリズムから無視されます。 |
| セマンティック検索 | 高度。LLMを介して複雑な自然言語プロンプトを理解。 | なし。基本的なフィルタ(年、ジャンル、ムードタグ)のみ。 | 中程度。テキスト解析は得意だが、カタログ内の楽曲に限定。 |
技術的な注意点とトラブルシューティング
- VNNI歌詞再解析バグ: コンテナスタックを最新のAudioMuse-AIビルドに更新した場合、CPUアーキテクチャに注意してください。GTE多言語埋め込みモデルの古いリビジョンは、VNNI命令セット(2019年以前のハードウェア)を欠く古いCPUでベクトルマッピングの劣化を引き起こす可能性があります。Linuxホストで を実行して出力がない場合は、PostgreSQL CLIを使用してレガシーなデータベーステーブルを削除し、歌詞のスキャンをやり直してクリーンな検索結果を取得してください。text
1grep -oE 'avx512_vnni\|avx_vnni' /proc/cpuinfo - メディアサーバーのタイムアウト調整: 500曲を超える巨大なプレイリストをNavidromeに同期する際、初回同期のハンドシェイクがデフォルトのプロキシ制限を超えることがあります。ログにハンドシェイク切断のメッセージが表示される場合は、公式のパラメータガイドを確認し、サーバーのタイムアウトフラグを調整してください。
よくある質問
セットアップ中にJellyfinの接続テストが失敗するのはなぜですか?
多くの場合、ベースURLの書式が不適切であるか、APIトークンのスコープが無効であることが原因です。ポート番号を含む完全なHTTP/HTTPSアドレス(例:
1http://192.168.1.50:8096AVX2命令セットを持たない古いサーバーでAudioMuse-AIを動かせますか?
可能です。ただし、標準のDockerイメージは使用できません。
1-noavx21neptunehub/audiomuse-ai:latest-noavx2AtlasCloud APIはapp_chat.pyの応答速度をどう改善しますか?
会話型プレイリストウィザードと対話する際、システムは会話内容を構造化されたJSONスキーマに変換する必要があります。このテキスト処理をローカルサーバーのCPUで行うと、メッセージごとに10〜30秒かかる場合があります。これらの特定のリクエストをAtlasCloudのような最適化されたクラウドパートナー経由でルーティングすることで、数ミリ秒で回答が得られ、ローカルサーバーのメモリをハイビットレートのFLAC再生のために確保し続けることができます。






