Claude Codeのコストは、開発者1人あたり1日平均約USD13ですが、高度な自動化を行うとエンジニア1人につき月額USD500〜USD2,000にまで膨れ上がることがあります(CloudZero, 2026)。50人規模のチームであれば、突如として5桁のコストが予算外に現れることになります。もし先四半期にAIコーディングの請求額が急増し、その理由が誰にも説明できないのであれば、それはあなただけではありません。そして、その解決策は「AIの使用を控える」ことではありません。
本当の問題は、AIエージェントツールがチャットウィンドウとは根本的に異なる方法でトークンを消費している点にあります。多くのチームは、もっと低コストで利用できるはずのトークンに対して定価を支払っています。本ガイドでは、AIコーディングのトークンコストを削減するための7つの具体的な戦術を、その裏付けとなる数値と正確な設定変更方法を交えて解説します。
要点
- エージェント型のコーディングツールは、ツール呼び出しのたびにコンテキスト全体を再送信するため、チャットと比較して10倍から100倍ものトークンを消費します(LeanOps, 2026)。
- プロンプトキャッシュは最もレバレッジの高い変更です。キャッシュの読み取りコストは標準入力トークンの約10%であり、あるチームはこれだけでLLM全体の利用料を59%削減しました。
- 日常的なコーディングをGLM、Kimi、DeepSeekのようなオープンウェイトモデルに切り替えることで、フロンティアモデルと比較してトークンあたりのコストを80%以上削減できます。品質の差は予想よりも小さくなっています。
- すべてのツールを1つのゲートウェイ経由でルーティングすることで、5つのベンダーに個別に支払うのではなく、1つの予算、1つのAPIキー、一貫した価格設定で管理できます。
AIコーディングのトークンコストが制御不能になる理由
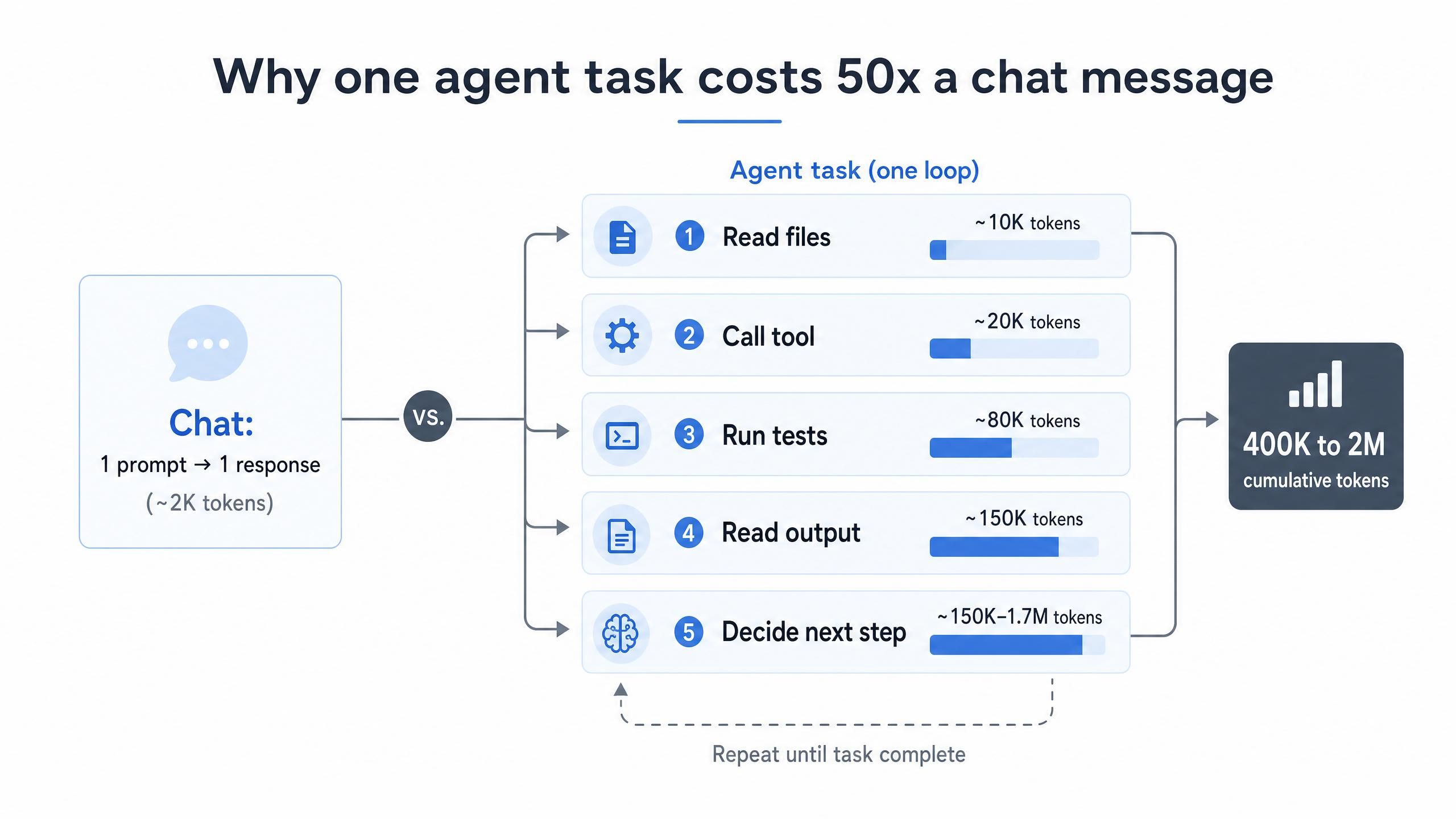
AIコーディングのトークンコストが高騰する根本的な原因は、行動ではなく構造にあります。チャットのやり取りでは、プロンプトを送信して1つの回答を得ます。一方、エージェントは全く異なる動作をします。ファイルの読み込み、ツールの呼び出し、テストの実行、出力の読み取りを行い、次のアクションを決定します。これらの推論ステップのたびに蓄積されたコンテキストが再送信されるため、ループごとにトークン使用量が増幅されます。AIエージェントがチャットボットより10〜100倍速くトークンを消費するのは、まさにこのためです(LeanOps, 2026)。
コストはすぐに膨れ上がります。単一の複雑なエージェントタスクでも、コンテキストウィンドウが埋まり再充填される過程で、APIを通じて40万から200万の累積入力トークンを消費することがあります(Morph, 2026)。これをチーム全体で1日に何十回ものタスクと掛け合わせれば、月額請求額は無視できない金額になります。
これは大企業にとって仮定の話ではありません。The Next Webが報じたレポートによると、Microsoftが社内のClaude Codeライセンスの大部分を撤回した理由の一部はコストであり、エンジニア1人あたりの請求額はUSD500〜USD2,000に達していました(The Next Web, 2026)。世界で最も潤沢なリソースを持つエンジニアリング組織の一つがコストに悲鳴を上げているのですから、削減を試みる前にトークンがどこに消えているのかを理解することが不可欠です。
コーディング速度を落とさずにトークンコストを削減する方法
幸いなことに、これらの戦術のほとんどは、コードを書く量を減らしたり、エージェントにつきっきりになったりする必要はありません。無駄を省き、同じ作業の価格を見直し、各タスクを遂行可能な最も安価なモデルに割り当てることで機能します。以下に、効果の大きい順に7つの戦術を紹介します。
戦術1:プロンプトキャッシュを使用してコストを削減する
プロンプトキャッシュは、最もレバレッジの高い単一の変更です。エージェントがステップごとに同じシステムプロンプト、ツール定義、ファイルコンテキストを再送信する場合、キャッシュを利用すればモデルはその繰り返しコンテンツをキャッシュから読み取れるため、再処理のコストを抑えられます。キャッシュの読み取りは標準入力レートの約0.10倍の価格設定となっており、リクエストごとに繰り返される部分が90%割引になります(Finout, 2026)。
知っておくべき注意点として、キャッシュの書き込みコストは通常の入力トークンよりわずかに高く、5分間のウィンドウに対して標準の約1.25倍かかります。そのため、TTL(存続期間)ウィンドウ内でコンテキストが再利用される場合にキャッシュは効果を発揮します。これはエージェント特有のパターンです。実世界でのインパクトは理論上の話ではありません。ProjectDiscoveryのチームは、パイプライン全体にプロンプトキャッシュを導入した後、LLM全体のコストを59%削減したと報告しています(ProjectDiscovery, 2026)。
Claude Codeや互換性のあるエージェントを実行している場合は、キャッシュが有効になっていること、およびシステムプロンプトや大規模なファイルコンテキストがキャッシュ可能なブロックに含まれていることを確認してください。この1つの変更だけで、請求額が最も大きく削減されることがよくあります。
戦術2:タスクに合わせてモデルを使い分け、コストを下げる
多くのチームはすべてのリクエストを最も高性能なモデルにルーティングしていますが、これは買い物に行くのに大型トラックを使うようなものです。よりスマートなパターンは、本当に必要な作業には高価なフロンティアモデルを確保し、それ以外は安価なモデルに送ることです。
実用的な使い分けは以下の通りです:
- 推論、アーキテクチャ設計、困難なデバッグ: 品質が価格を正当化するトップティアモデル。
- 日常的なコード生成と編集: 強力なミドルティアのオープンモデル。
- 大量のバックグラウンドジョブ、分類、定型文: 最も安価な能力を備えたモデル。
価格差が非常に大きいため、削減効果は劇的です。安価なモデルでは、DeepSeek V4 Flashの入力トークンは100万あたり約USD0.14ですが、フロンティアモデルはその数倍のコストがかかります(Codersera, 2026)。トークンボリュームの80%を安価なモデルに割り当て、プレミアムモデルを必要な20%に限定すれば、出力品質を損なうことなく全体予算を半分以上カットできます。
戦術3:コンテキストウィンドウをスリムに保つ
コンテキスト内のすべてのトークンはエージェントのステップごとに再送信されるため、肥大化したコンテキストウィンドウは繰り返し支払う税金のようなものです。2つの習慣が役立ちます。第一に、エージェントがリポジトリ全体ではなく必要なファイルのみを読み込むように、タスクごとにスコープを厳密に定義すること。第二に、1つの会話に何十万もの古いトークンを蓄積させず、タスクの切り替え時に新しいセッションを開始することです。
役立つメンタルモデルとして、「チャットで質問に答えるためにそのファイルを貼り付けないなら、エージェントのコンテキストにも残さない」という原則を持ちましょう。コンテキストウィンドウを200,000トークンから40,000トークンに削ることは、単発の節約ではありません。タスクの残りの全ツール呼び出しに対して節約が効くため、複利的にコストが削減されます。
戦術4:オープンウェイトモデルに切り替えてコストを削減する
これは、最も大きな節約が見込める戦術でありながら、最も古い思い込みが付きまとっている分野です。2026年に提供されているオープンウェイトのコーディングモデルは、非常に優秀です。SWE-Bench Proにおいて、主要なフロンティアモデルが約91点を記録する一方、Kimi K2.6は76.8、DeepSeek V4 Proは77に近いスコアを出しています(Codersera, 2026)。最難関のベンチマークでは確かに差がありますが、日常的な機能開発、リファクタリング、テスト作成において、品質の差は価格差ほど大きくありません。
そして、その価格差こそが重要です。GLM、MiniMax、Kimi、DeepSeekといったオープンウェイトモデルは、トークンあたりの価格がフロンティアモデルの数分の一です。日常的なコーディングの大半において、オープンモデルは低コストで任務を遂行します。これまで導入の障壁となっていたのは、プロバイダーごとのアカウント管理、キー管理、一貫性のない価格設定などの手間でした。
ここで統一されたコーディングゲートウェイが計算式を変えます。Atlas Cloudのようなプラットフォームは、主要なオープンウェイトモデルを単一のAPIと共通のクレジット残高で集約します。そのため、Claude Code、Codex、OpenClawの接続先を今日GLM-5.1にし、明日Kimi K2.6に変えるといった変更が、設定変更なしで可能になります。Atlas Cloudはモデルごとのクレジット乗数を公開しており、公式API料金と比較して約45%〜55%の節約になります。また、同社のクレジットレートは、同じモデルを利用する場合のOpenRouterよりも安価に設定されています。
人気のあるコーディングモデルのクレジット乗数の例:
| モデル | コンテキスト | 入力乗数 | 出力乗数 | 公式比の推定節約率 |
|---|---|---|---|---|
| deepseek-ai/deepseek-v4-flash | 1M | 0.23 | 0.46 | ~50% |
| deepseek-ai/deepseek-v3.2 | 160K | 0.42 | 0.62 | ~55% |
| minimaxai/minimax-m2.5 | 200K | 0.65 | 2.18 | ~45% |
| moonshotai/kimi-k2.6 | 262K | 1.72 | 7.26 | ~45% |
| zai-org/glm-5.1 | 200K | 2.54 | 7.99 | ~45% |
ソース: Atlas Cloud Coding Plan クレジットルール。クレジットコスト = 入力トークン × 入力乗数 + 出力トークン × 出力乗数
戦術5:バックグラウンド作業をバッチ処理する
すべてのトークンがリアルタイムの対話型料金である必要はありません。夜間の評価、大規模な分類ジョブ、ドキュメント生成、一括リファクタリングなどは人間が待機する必要がないため、安価なバッチレーンや利用可能な中で最も安価なモデルで実行できます。このような急ぎではないボリュームをプレミアムな対話型モデルから外すことは、実質的な利益です。なぜなら、これまで高い料金を払って実行していた作業において、品質面でのメリットはほとんどなかったからです。
原則はシンプルです。「自分が待機している」トークンと「夜間に完了すればよい」トークンを分け、それぞれに異なる価格を適用することです。多くのチームにとって、合計トークンボリュームの驚くべき割合が、実は後者であることが判明しています。
戦術6:すべてのツールを1つのコーディングゲートウェイ経由にする
ツールの乱立は、AIコーディングのトークンコストを静かに押し上げます。典型的な開発者は、ターミナルでClaude Code、特定のタスクでCodex、エディタでCursor、その他いくつかのエージェントを使い分けているかもしれません。それぞれにサブスクリプション、個別のキー、不透明な請求が存在します。これでは全体像が見えず、どこでも定価で支払うことになります。
OpenAI互換のエンドポイントに統合することで、これらの問題は解決します。Atlas Cloudは1つのベースURLと共通のクレジットプールを提供しており、Codex、Claude Code、OpenClaw、OpenCode、Cursor、直接のAPI呼び出しすべてに対応しています。これにより、1つの請求、1つの予算、モデルを切り替える場所を一元化できます。プランは月額USD10のStarterから重い負荷向けのプランまであり、従量課金パックには41%の割引が適用されるため、推測で契約するのではなく実際の使用量に合わせて規模を調整できます。
Claude Codeをゲートウェイに向けるのは、設定ファイル1つです。macOSまたはLinuxの場合、~/.claude/settings.jsonを以下のように編集します:
JSON1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "zai-org/glm-5.1", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "zai-org/glm-5.1", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "zai-org/glm-5.1", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Codexユーザーの場合、同様の設定は~/.codex/config.tomlに記述し、base_urlをhttps://api.atlascloud.ai/v1に向け、auth.jsonにキーを格納します。同じベースURLがOpenClaw、OpenCode、Cursor、Copilot形式のクライアントで機能するため、チーム全体で1つのエンドポイントに標準化できます。
戦術7:予算を設定し、トークンコストを監視する
見えないものを削減することはできません。多額の請求に直面したチームのほぼ全員が、「支出管理がなく、開発者ごとの可視性もなかった」という共通点を持っていました。解決策は、請求書が届いてからではなく、月が始まる前に消費の上限を設定することです。
クレジットベースのプランで1日の利用上限を設けることは、構造的にこれを可能にします。上限のないメーター課金ではなく、毎日深夜に固定のクレジットが補充される月額サブスクリプションであれば、暴走するエージェントループによる被害を最小限に抑えられます。上限を超えた場合は従量課金パックが使用されます。規模を拡大する必要がある場合は、日割り計算のアップグレードにより差額のみを支払えば済みます。Atlas Cloudのアップグレードフローは残りの価値を新しいプランに充当するため、サイクル途中の変更でも少額で済みます。
実質的なコスト比較:モデル別のAIコーディングトークンコスト
節約を具体的にイメージするために、忙しい日にエージェントを通じて約150万入力トークン、30万出力トークンを消費する開発者を例にとります。単一のタスクが累積入力で7桁に達することを考えれば、これは現実的な数値です。入力100万トークンあたりUSD5、出力100万トークンあたりUSD25のフロンティアモデルであれば、入力で約USD7.50、出力でUSD7.50、合計で1日約USD15となります。これは広く引用されている「1日USD13」という数値と一致します(CloudZero, 2026)。
同じボリュームを、割引ゲートウェイ経由でGLMやKimiのようなオープンウェイトモデルで実行すれば、入力部分は70%以上低下し、出力もそれに続きます。さらにプロンプトキャッシュを適用すれば、エージェントのワークロードを支配する繰り返しコンテキストは、その10分の1の料金で請求されます。「キャッシュ+安価なモデル+スリムなコンテキスト」という3つの戦術を組み合わせることで、1日USD15のコストは、誰のコーディングスタイルを変えることもなく、USD3〜USD5の範囲に収めることが現実的に可能です。

正確な数値はワークロードによって異なりますが、構図は同じです。AIコーディングコストの大部分は、過剰な価格のモデルを通る繰り返しのコンテキストであり、そのどちらも修正可能です。
まとめ:AIコーディングのコストを低く抑えるセットアップ
最小限の手間で最大限の節約を実現するための初期設定は以下の通りです。デフォルトのコーディングモデルとしてGLM-5.1やKimi K2.6のようなオープンウェイトモデルを使用し、困難な推論のためにフロンティアモデルを残し、あらゆる場所でプロンプトキャッシュを有効にし、コンテキストをスリムに保つためにタスクの範囲を絞り込み、すべてのツールを固定日次予算を持つ単一のOpenAI互換エンドポイントへルーティングします。
この組み合わせにより、トークンの再価格設定、繰り返されるコンテキストへの支払い停止、そしてダウンサイドリスクの抑制という、コストの主要要因すべてに対処できます。これを1つのキーと予算で統合したいチームは、Atlas Cloud Coding Planコンソールから利用を開始できます。設定には数分しかかかりませんが、節約は毎日繰り返されます。
AIコーディングのトークンコストに関するよくある質問
なぜAIコーディングのトークンコストはチャット利用よりはるかに高いのですか?
エージェントは推論ステップごとに累積されたコンテキスト全体を再送信しますが、チャットはプロンプトを一度だけ送信するからです。この構造的な違いにより、エージェントは同等の作業に対してチャットよりも10〜100倍のトークンを消費します(LeanOps, 2026)。そのため、数十のエージェントタスクが数ヶ月分のカジュアルなチャット利用を上回ってしまうのです。
AIコーディングのトークンコストを削減する最も速い方法は?
プロンプトキャッシュを有効にすることです。エージェントのワークロード内の繰り返しコンテキストは、キャッシュされると標準入力レートの約10%で請求されます(Finout, 2026)。あるエンジニアリングチームは、キャッシュだけでLLMの総コストを59%削減したと報告しています。仕事の進め方を変える必要がないため、最も手間がかからずリターンが大きい方法です。
安価なオープンウェイトモデルは実際のコーディング業務で十分に使えますか?
日常的なタスクのほとんどで十分です。最難関のベンチマークであるSWE-Bench Proでは、トップのオープンモデルは70点台後半で、フロンティアモデルの約91点には及びませんが(Codersera, 2026)、日常的な機能開発、リファクタリング、テスト作成でその差が問題になることはほとんどありません。真に困難な推論のためにフロンティアモデルを待機させ、残りをオープンモデルに送るのが賢明です。
実際にどれくらいのコストを削減できますか?
プロンプトキャッシュ、安価なデフォルトモデル、スリムなコンテキストという主な戦術を組み合わせれば、開発者1日あたりのコストをUSD15からUSD3〜USD5程度まで削減するのが一般的です。この節約はチーム全体で積み重なるため、5桁の月額請求額であっても、2桁パーセントの削減で十分に合理的な範囲に収まります。
トークンコストを下げるためにツールを変える必要がありますか?
いいえ。節約のほとんどはトークンの価格設定と再利用方法によるもので、使用するクライアントによるものではありません。既存のツール(Claude Code、Codex、OpenClawなど)を割引価格のOpenAI互換エンドポイントに向けることは設定変更であり、移行ではありません。したがって、ワークフローを変えずに請求額を下げることができます。
結論
AIコーディングのトークンコストは、メカニズムを知るまでは謎に包まれています。エージェントは同じコンテキストを何度も再送信し、多くのチームはそのすべてにフロンティアモデルの価格を支払っています。プロンプトキャッシュ、賢いモデルルーティング、スリムなコンテキスト、割引された単一ゲートウェイによって、その2つの問題を解決すれば、誰もコードの書き方を変えることなく、請求額を半分以下に抑えることができます。まずは今週中にキャッシュを導入し、どのタスクに最も高価なモデルが必要かを精査し、ツールを1つの予算に統合してください。セットアップは午後だけで終わりますが、その節約は永久に続きます。






