
GPUカーネルを書く際、開発者はあるスペクトラム上のどこかに位置しています。一端にはTritonがあります。記述は迅速ですが、レイアウトや共有メモリに関する判断のほとんどはコンパイラに委ねられます。もう一方の端にはCUTLASS / CuTeがあります。膨大なテンプレートコードを記述する代償として、完全な制御が可能です。その中間に位置するのがTileLangです。Pythonで記述しますが、何が共有メモリに入るか、パイプラインがどうステージングされるか、ワープがどう作業を分担するかを明示的に指定します。残りの部分は、レイアウト推論パスが埋めてくれます。
本稿では、メンタルモデルの解説から始め、GEMM(行列積)を実装し、最終的にDeepSeekのMLA(Multi-Head Latent Attention)デコードという、興味深い判断が実際に現れる実戦的な本番カーネルへとビルドアップしていきます。網羅的な解説が目的ではありません。タイルについてどのように考えればよいか、そしてTileLangがどこで静かに面倒な作業を代行してくれるかを示すのが目的です。最後には、パフォーマンスそのものではなく、別の価値が求められた本番環境での事例をご紹介します。
メンタルモデル
全容を3つのポイントで説明します。
- タイルは第一級オブジェクトです。 形状を持つデータの塊(例えば block_M × block_K)は、スレッドブロック、ワープ、あるいはスレッドによって所有され、操作されます。Tritonのようにスレッドブロックレベルだけで考えることは止め、CUDAのように個々のスレッドを手動で管理することも止めます。
- バッファのメモリ階層配置は自分で行います。 何を共有メモリへ送るか(T.alloc_shared)、何をレジスタへ送るか(T.alloc_fragment)、何がスレッドローカルかを宣言します。これはTritonとの最大の相違点であり、Tritonでは共有メモリの割り当てやステージングがコンパイラ内に隠蔽されています。
- コンパイラがスレッドマッピングを推論します。 タイルがどこに存在し、どのような操作(コピー、gemm、リダクション)を行うかを指定すれば、レイアウト推論パスがスレッド全体で並列化し、レジスタや共有メモリのレイアウトを決定します。必要に応じてオーバーライドすることも可能ですが、ほとんどの場合は不要です。このパスこそが核心的な機能であり、MLAの解説に入ればその理由がわかるはずです。
Tritonから移行する場合の概略は以下の通りです。
| Triton | TileLang | |
|---|---|---|
| 粒度 | スレッドブロック + 暗黙的なベクトル化 | タイル (ブロック / ワープ / スレッド) |
| 共有メモリ | コンパイラが管理 | 明示的な alloc_shared + copy |
| レイアウト | コンパイラが決定 | 推論されるが、注釈で指定可能 |
| パイプライン | tl.range + コンパイラ | 明示的な T.Pipelined(num_stages=) |
| Tensor Core | tl.dot | Warpポリシー選択可能な T.gemm |
| バックエンド | NVIDIA (主要) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL, および Ascend & MUSA フォーク |
一言で言えば、CUTLASSを書かずにブロッキング、パイプライン深度、ワープ分割を細かく制御したいなら、TileLangが最適な選択肢です。単純な要素ごとの計算や軽いフュージョンであれば、Tritonの方が手軽です。
セットアップ
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # 事前構築済みホイール、最も簡単
コンパイラのパスに触れる場合は、ソースからビルドしてください(ローカルのLLVM/CUDAツールチェーンが必要です):
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
GEMMを書いてみる
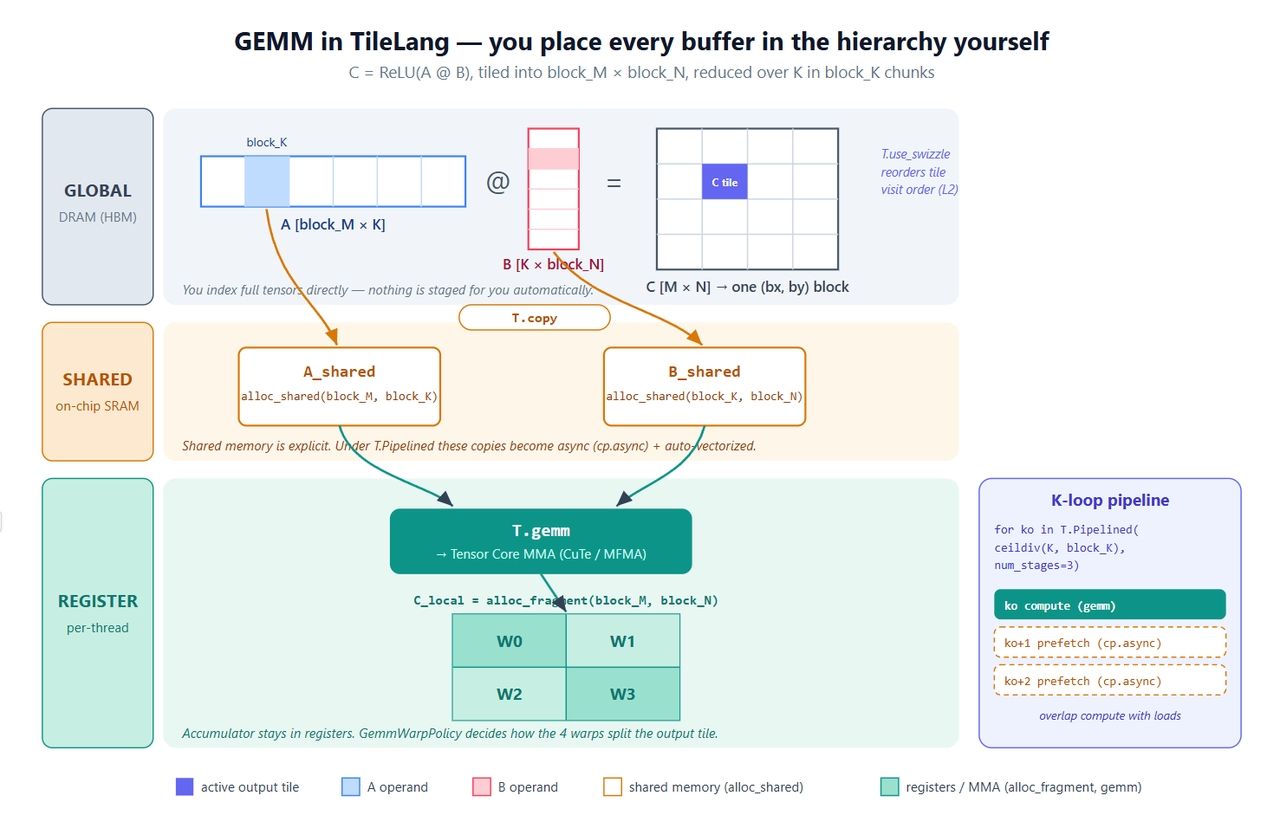
誰もが最初に書くカーネル、C = ReLU(A @ B) から始めましょう。小規模ですが、重要なプリミティブ(明示的なバッファ、並列コピー、ソフトウェアパイプライン、Tensor Core呼び出し、L2スウィズル)をすべて網羅しています。
plaintext1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # グリッドの次元: (#blocks along N, #blocks along M); 1ブロックあたり128スレッド 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # 各タイルがどこに配置されるかを明示的に記述 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # 共有メモリ 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # レジスタアキュムレータ 23 24 T.use_swizzle(panel_size=4, order="col") # オプション: L2再利用性の向上 25 T.clear(C_local) # アキュムレータのゼロ初期化 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # グローバル -> 共有 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # タイルレベルMMA 31 32 for i, j in T.Parallel(block_M, block_N): # フュージョンされたReLU 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # 書き戻し 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
各コードの役割は以下の通りです。
- 3つのバッファ、3つのレベル。 A_sharedとB_sharedは共有メモリに、C_localはレジスタに配置されます。レジスタでのアキュムレーションと共有メモリを経由したオペランドのステージングは標準的なGEMMのレシピですが、ここではそれを「記述」します。Tritonとの違いはすべてここに集約されます。
- T.copy は並列コピーのシュガー構文です。 これはT.Parallel形式の移動に展開され、コンパイラはベクトル化・コヒーレントなグローバル→共有転送を導出します。コピーがT.Pipelined内にある場合、自動的に cp.async になります。
- T.Pipelined(extent, num_stages=N) はソフトウェアパイプラインです。 num_stages=3はトリプルバッファリングを意味します。つまり、Kタイル ko を計算している間に、ko+1 と ko+2 のロードがすでに進行している状態になります。Tritonではコンパイルフラグですが、ここでは単なるループであり、推論が容易です。
- T.gemm(A, B, C) はタイルレベルの行列積です。 NVIDIA上ではCuTe/MMAに、AMD上では対応する組み込み関数に低レイヤー化されます。transpose_A / transpose_B や、ワープがどのように出力タイルを分割するかを制御する policy=T.GemmWarpPolicy.* も受け入れます。このpolicy引数は、MLAで非常に重要な役割を果たします。
- T.use_swizzle はスレッドブロックのスケジューリング順序を再配置し、L2キャッシュ上で隣接するブロックが時間的にも近く実行されるようにします。通常、数パーセントの帯域幅が解放されます。
下の図は、これらすべてをハードウェアにマッピングしたものです。ラベル付けされた箇所こそ、Tritonが隠蔽する制御権をTileLangがあなたに手渡す場所であるため、コードと照らし合わせて確認する価値があります。
頻用するプリミティブ
ほとんどのカーネルは、わずかな語彙で記述できます。
- 割り当て: T.alloc_shared, T.alloc_fragment (レジスタ), T.alloc_local。
- 移動と初期化: 任意の2レベル間での T.copy(src, dst); T.clear, T.fill。
- 計算: T.gemm(...); 要素ごとのループのための T.Parallel(d0, d1, ...) (これがレイアウト推論の入り口です); T.reduce_max / T.reduce_sum; T.exp, T.exp2, T.max, T.infinity などのスカラー演算。
- スケジューリング: T.Pipelined(extent, num_stages=), T.use_swizzle(...), 特定のレイアウトが必要な場合の T.annotate_layout(...)(バンク競合回避、カスタムスウィズル)。
- 動的形状: 形状ごとに再コンパイルしないための M = T.dynamic("m")(一部のバージョンではT.symbolicと呼ばれます)。
作業の確認
よく使うコマンドが2つあります。コンパイラが実際に出力したものを確認するには:
plaintext1print(kernel.get_kernel_source()) # 生成された CUDA / HIP
計測には:
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latency: {profiler.do_bench()} ms")
T.print(buf) はカーネル内からタイルを出力します。リポジトリの examples/plot_layout はメモリレイアウトを描画でき、バンク競合の追跡やスウィズルの確認に便利です。
実践例:MLAデコード
GEMMはメカニズムを示しましたが、次はなぜそれが重要かを示します。DeepSeekのMLA(Multi-Head Latent Attention)デコードカーネルを追います。これはTileLangの真価が発揮される、最もクリアな例です。このTileLangの参照実装は、約80行のPythonでFlashMLAのH100パフォーマンス(fp16のバッチ64/128でベンチマーク、TritonやFlashInferを上回る)に到達します。興味深いのは「どうやって実現したか」です。MLAの難しさは数学ではなく、レジスタ圧だからです。
周知のループを振り返ってみましょう。すべてのFlashAttentionファミリーのカーネルは同じ形状をしています。クエリブロックごとにキー/値ブロックにストリームし、最大値と分母を保持し続けることで、スコア行列全体がメモリに乗らないようにします:
plaintext1# acc_s : [block_M, block_N] 現在のKVブロックのスコア 2# acc_o : [block_M, dim] 出力アキュムレータ 3for i in range(num_kv_blocks): 4 acc_s = Q @ K[i].T 5 m_prev = scores_max 6 scores_max = max(m_prev, rowmax(acc_s)) 7 scores_scale = exp(m_prev - scores_max) 8 acc_o *= scores_scale # 以前の出力を再スケーリング 9 acc_s = exp(acc_s - scores_max) # 確率 10 acc_o += acc_s @ V[i]
acc_s と acc_o はレジスタに留まりたいと願いますが、MHAやGQAでは問題ありませんが、MLAではそうはいきません。
ここからが難関です。 MLAのヘッド次元は大きく、クエリとキーは幅576(位置エンコーディングなしの512幅「nope」部分+64幅の「rope」部分)、値は512です。つまり、acc_o は [block_M, 512] となり、KVループ全体を通じてレジスタに常駐しなければなりません。
ここでハードウェアを考慮します。Hopperにおいて、高速パスは wgmma.mma_async であり、4ワープ(128スレッド)を1つのワープグループにまとめ、Mの最小値として64を要求します。つまり、1つのワープグループが所有できる最小のMは64となり、結果として64 × 512のアキュムレータを保持することになります。これは単一ワープグループのレジスタファイルには大きすぎます。スピルが発生し、パフォーマンスは劇的に低下します。
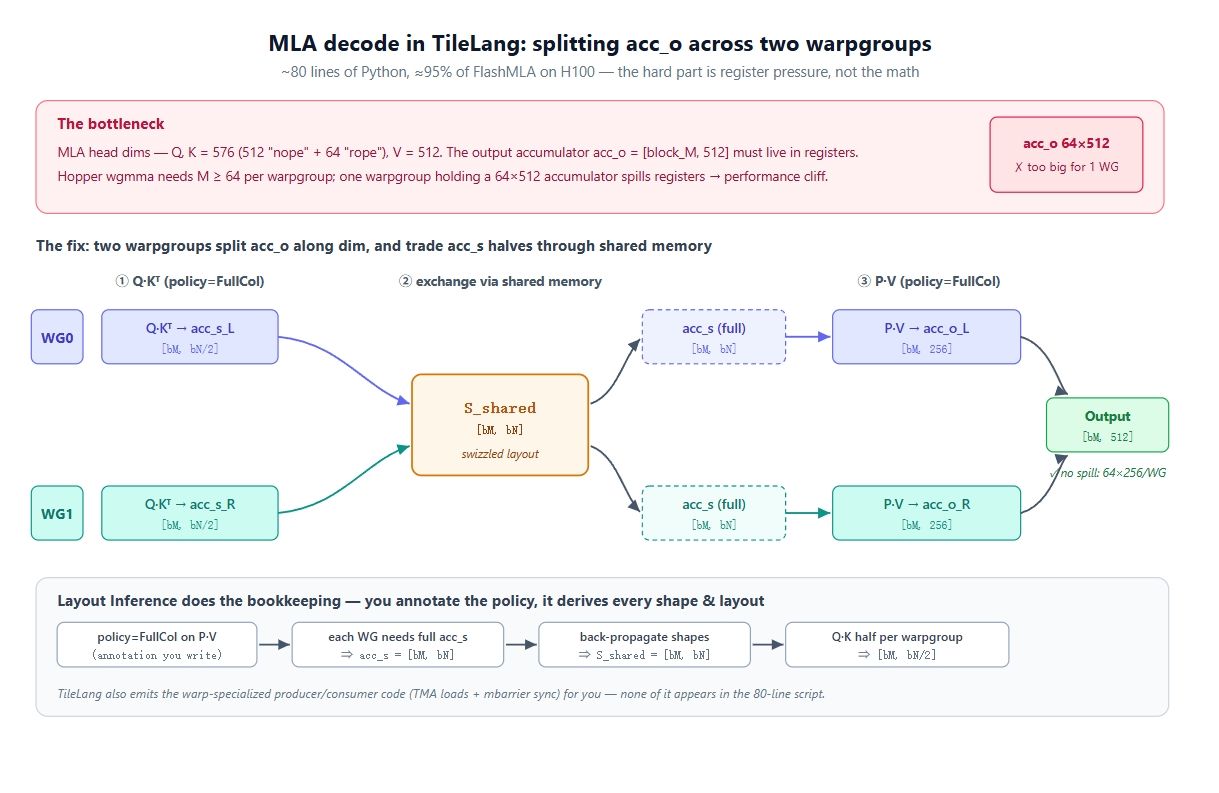
解決策は、出力を2つのワープグループに分割することです。 Mを64未満に縮小できないため、唯一残された軸は次元(dim)です。2つのワープグループを使用します:WG0が acc_o[:, :256] を、WG1が acc_o[:, 256:] を所有します。これで各々は64 × 256のアキュムレータを保持でき、レジスタに収まります。ただし、これで第2の問題が発生します。P @ Vステップ(policy=FullColの場合、各ワープグループが出力の1列スラブを生成)では「完全な」 acc_s が必要ですが、Q @ Kでは各ワープグループが自然にその半分しか計算していません。解決策は共有メモリ内でのスワップです。Q @ Kの間、各ワープグループは acc_s の半分を共有メモリに書き込み、もう一方の半分を読み戻すことで、両者とも全 acc_s を保持でき、それぞれが acc_o のスラブを計算可能になります。上記の図はまさにそれ、つまり「スコアを分割し、S_sharedでスワップし、出力を分割する」というプロセスです。
CuTeであれば、これらすべてを実現するために、レイアウト、スウィズル、Tensor Coreの配置、プロデューサー/コンシューマーの同期を手書きする必要があったでしょう。ここでのコードが約80行に凝縮される理由は「レイアウト推論」にあります。
レイアウト推論の仕組みを分解しましょう。 T.gemm の呼び出しに意図を注釈すると、コンパイラが制約をプログラム全体に伝播させます:
- P @ V で policy=FullCol と指定すれば、各ワープグループには完全な acc_s が必要であるため、acc_s = [block_M, block_N] となる。
- それがステージングバッファに伝播し、T.copy(S_shared, acc_s) の S_shared も [block_M, block_N] となる。
- そして Q @ K に伝播する:FullColであれば、各ワープグループのスコアスラブは [block_M, block_N/2] となる。
重要な洞察は、これらの形状を一度も記述していないことです。ワープポリシーを選んで計算式を書くだけで、形状、スウィズルされたレイアウト、ワープ専門化されたプロデューサー/コンシューマーコードがすべて推論から導き出されます。
カーネルのスケルトン。 MLAデコードでは、クエリは「nope」部分(Q, dim 512)と「rope」部分(Q_pe, dim 64)に分割され、圧縮された潜在変数がKとVの両方の役割を果たします。そのためスコアは2つのGEMMの和であり、出力はさらにもう1つのGEMMとなります。内側のループは以下のようになります( representative なスケルトンであり、正確な行ではありません — example_mla_decode.py を参照してください):
plaintext1# acc_s = Q_nope @ KV^T + Q_rope @ K_pe^T 2T.gemm(Q_shared, KV_shared, acc_s, transpose_B=True, 3 policy=T.GemmWarpPolicy.FullCol, clear_accum=True) 4T.gemm(Q_pe_shared, K_pe_shared, acc_s, transpose_B=True, 5 policy=T.GemmWarpPolicy.FullCol) 6 7# オンラインソフトマックス 8T.copy(scores_max, scores_max_prev) 9T.fill(scores_max, -T.infinity(accum_dtype)) 10T.reduce_max(acc_s, scores_max, dim=1, clear=False) 11# ... exp, rescale acc_o by scores_scale, reduce_sum into logsum ... 12 13# acc_o += P @ V (V は同じ潜在 KV) 14T.copy(acc_s, acc_s_cast) 15T.gemm(acc_s_cast, KV_shared, acc_o, policy=T.GemmWarpPolicy.FullCol)
2つのワープグループ間での S_shared の交換は、FullColポリシーによって各ワープグループが完全な acc_s を必要とすると強制された瞬間に、推論によって挿入される部分です。
素晴らしい点は、最適化がすべて一行で済むことです。 これがTileLangの真価であり、パフォーマンスツールキット全体がワンライナーであり、面倒な低レイヤー化はすべて代行されます。
- L2再利用のためのスレッドブロック・スウィズリング: T.use_swizzle(panel_size, order="row")。
- バンク競合のための共有メモリ・スウィズリング: T.annotate_layout({S_shared: T.layout.make_swizzled_layout(S_shared)}) — 同時アクセスがシリアライズされる代わりにバンク間で分散されるようにするXORスタイルのアドレス再配置。
- ワープ専門化: 単純なスクリプトを書けば、TMAロードを行うプロデューサーワープグループとコンシューマーワープグループに分解され、mbarrier同期が自動生成されます。コード上には現れません。
- パイプライン化: T.Pipelined(range, num_stages) はロードと計算をオーバーラップさせます。ステージが多いほどオーバーラップは増えますが、共有メモリを消費するためバランス調整が必要です。
- Split-KV (FlashDecodingスタイル): バッチが小さくSMがアイドル状態のとき、KVコンテキストをSM間で分割してマージします。num_splitパラメータと結合カーネルで実現します。
つまり、レジスタ予算とM≥64という制約、ワープグループ間の所有権、共有メモリのスワップといった真に困難な推論は、ポリシーを選んで計算式を書くことで表現されます。CuTeでは何百行もの壊れやすいコードになるような内容が、すべて推論とコード生成によって解決されます。これが売りであり、MLAにおいて最も説得力があります。
AtlasCloudでの事例:RMSNormの組み込み
最後の例は、AtlasCloudにおける当社の本番環境カーネル、Wanビデオ生成VAEのH100/H200向けの実装です。これはTileLangが非常に優れているもう一つの点を示しています。手書きのカーネルが対応できない設定を、クリーンな組み込みコードでカバーする能力です。
状況。 私たちはすでに、手書き最適化されたRMSNorm + SiLUフュージョンカーネルを出荷しています。これは高速で、あるモデル構成で使用される隠れ次元 D ∈ {96, 192, 384} 向けにコンパイルされています。新しい構成では {160, 256, 320, 512, 640, 1024} といったチャンネル幅が必要になり、手書きの高速パスでは動作しません。そこで、そのギャップを埋めるためにTileLangで代用品を記述しました。
TileLangカーネル。 32の倍数である任意のCをサポートする、同じインターフェース(BTHWC入出力、同じ数学的処理、同じeps)を持つ代用品です。完全コヒーレントな2パス、FP32アキュムレータ:
plaintext1@T.prim_func 2def main(X: T.Tensor((M, C), dtype), # M = B*T*H*W 行 3 gamma: T.Tensor((C,), dtype), 4 Y: T.Tensor((M, C), dtype)): 5 with T.Kernel(T.ceildiv(M, BLOCK_M), threads=128) as bm: 6 X_chunk = T.alloc_shared((BLOCK_M, BLOCK_C), dtype) 7 ss = T.alloc_fragment((BLOCK_M,), accum_dtype) # FP32 平方和 8 # pass 1: CのBLOCK_Cチャンクでループし、平方和をFP32で累積 9 # rinv = rsqrt(ss / C + 1e-5) 10 # pass 2: Xを再ロードし、y = silu(x * gamma * rinv)、書き戻し
BLOCK_CはTMAの boxDim ≤ 256 制限を守るためにCに応じて128/64/32となり、FP32アキュムレータがFP16での平方和のオーバーフローを防ぎます。ディスパッチ機能により、手書きパスが有効な場合はそれを使用し、必要な場合にのみ代替パスにフォールバックします:
plaintext1_ATLAS_SUPPORTED_D = (96, 192, 384) 2 3def rms_silu_dispatch(x, gamma, out): 4 if x.shape[-1] in _ATLAS_SUPPORTED_D: 5 atlas_rms_norm_silu(x, gamma, out=out) # 手書きパスを維持 6 else: 7 tilelang_rms_silu_bthwc(x, gamma, out=out) # ギャップをカバー
得られた成果。 すべてがプラスであり、真の組み込み型です。インターフェース、計算式、epsが同じであるため、既存のディスパッチの背後に配置するだけで、呼び出し側の変更は一切不要でした。
| 項目 | 向上 |
|---|---|
| 以前未サポートだった構成 | 0 → 1 — 動作するようになった(最大の成果) |
| AttentionブロックのRMSNorm vs 置換対象のeager PyTorch norm | 42 μs → 20 μs (~2倍高速化) |
| 本番解像度(720×1280, 21フレーム)でのVAEエンドツーエンド | ~1.79倍 エンコード, ~1.78倍 デコード |
最初の行こそが重要です。TileLangのおかげで、他の構成のためにすでにある手書きカーネルに一切触れることなく、これまで高速パスが全くなかったモデル構成を提供できるようになりました。Pythonで書かれた1つの組み込みカーネルにより、モデルの経路全体が「実行不可」から「出荷可能」に変わったのです。
TileLangが輝く場面
- CUTLASS/CuTeを書かずに、ブロッキング、パイプラインステージ、ワープ分割を細かく制御したい場合。
- 構造的に複雑でレイアウトに敏感なカーネル:GEMMの亜種、FlashAttentionファミリー、MLA、線形Attention、デ量子化フュージョンされた量子化GEMM、MoEルーティングなど。
- 手書きカーネルがカバーしきれない演算や構成(インスタンス化されたセット外の隠れ次元、特殊なレイアウト)をカバーし、同時にeagerモードのフォールバックよりも高速に動作させたい場合。
- バックエンド(NVIDIA / AMD / ベンダーフォーク)全体で共通のカーネル本体を使用したい場合。
- T.use_swizzle, T.annotate_layout, T.Pipelined, ワープ専門化, split-KV といった最適化ツールキットを1行ずつ呼び出し、低レイヤー化を代行させたい場合。
結び
TileLangのクールな点は、困難な推論がボイラープレートではなく、あなたの頭の中に留まることです。ワープ間での作業分割、バッファの配置、パイプラインの深さを決めるだけで、レイアウト推論とワープ専門化が、本来ならCuTeで数百行必要となるレジスタレイアウト、スウィズル、プロデューサー/コンシューマーのダンスに変換してくれます。ポリシーを選び、数学を書く。それがすべてであり、80行のMLAカーネルが手書きのCUTLASSカーネルと共存できる理由です。






