AI 영상의 진짜 병목 현상은 결과물이 어색해 보이는 것이 아니라, _느리게 느껴진다_는 점입니다.
1. AI 액션 15초가 여전히 임팩트가 부족한 이유
Seedance 2.0을 진지하게 사용해 본 사람이라면 누구나 똑같은 한계에 부딪혔을 것입니다. 15초짜리 클립을 요청하면 모델은 3~4개의 샷만 보여주고 끝납니다.
전투 장면을 입력하면 돌아오는 결과물은 "전사가 걸어 들어온다 → 무기를 든다 → 멈춘다"가 전부입니다. 설정, 액션, 그리고 끝. 크레딧이 올라갑니다.
하지만 실제 화면 속의 전투는 그렇게 흘러가지 않습니다. 주먹이 닿기 전 어깨가 먼저 돌아가고, 공격을 피한 후 바로 반격이 이어집니다. 와이드 샷에서 극단적인 클로즈업으로 전환되고, 슬로우 모션으로 임팩트를 줍니다. 긴장감은 특정 샷을 예쁘게 만드는 것에서 오는 것이 아니라, 컷의 밀도에서 나옵니다.
모델은 프롬프트를 어떻게 작성하든 스스로 16개의 샷을 만들어내지 않습니다.
이것이 문제입니다. 우리가 이 문제를 어떻게 해결했는지 알려드리겠습니다.
2. 워크플로우를 바꾼 세 가지 전환점
단일 캐릭터 액션 데모를 처음부터 끝까지 실행해 본 결과, 우리는 중요한 세 가지 사실을 깨달았습니다:
① 액션의 긴장감은 컷의 밀도에서 온다, 단일 샷의 퀄리티가 아니다. 하나의 샷을 완벽하게 만들려 하지 마십시오. 15초를 먼저 16개의 셀로 구성된 스토리보드로 나눈 다음, 그것을 영상 모델에 전달하십시오.
② GPT Image 2의 진짜 강점은 스타일 일관성이 아니라 대본 이해와 샷 배치입니다. 초기에는 GPT Image 2가 전체 체인에서 하나의 스타일을 유지하도록 하고 싶었습니다. 테스트 결과, 레퍼런스 투 비디오는 자연스럽게 CG로 흐르는 경향이 있으며 이를 강제로 고정할 깔끔한 방법은 없다는 것을 인정하게 되었습니다. 하지만 GPT Image 2는 대본을 읽고, 샷을 계획하며, 16개 셀 스토리보드를 구성하는 능력이 타 모델과는 비교할 수 없을 정도로 뛰어납니다.
③ 전체 파이프라인은 하나의 AtlasCloud API 키로 작동합니다. GPT Image 2, Nano Banana 2, Seedance 2.0은 모두 AtlasCloud의 동일한 모델 풀에 있습니다. 키 하나, 엔드포인트 하나, 요금 청구서 하나, 할당량 하나면 충분합니다. 여러 공급업체를 연결할 필요가 없습니다.
3. 단일 캐릭터 스트레스 테스트
GPT Image 2를 제대로 테스트하기 위해 가장 까다로운 캐릭터를 설정했습니다.
**란스(Ranx)**를 소개합니다. 사이버 전술 요원이며, 모래색 트윈 번 헤어에 완벽한 비대칭 장비 4종을 착용하고 있습니다:
- 오른쪽 다리에만 검은색 허벅지 높이 양말
- 오른쪽 허벅지에만 빨간색 하드쉘 홀스터
- 오른쪽 무릎에만 시안색 파이핑
- 벨트 오른쪽 뒤에서 시작해 왼쪽 종아리까지 이어지는 두꺼운 검은색 코일
모델에 제공한 유일한 레퍼런스 이미지는 뒤에서 본 3/4 샷이었습니다. 모델은 이를 바탕으로 앞모습, 옆모습, 표정, 무기 디테일을 역설계해야 했으며, 네 가지 비대칭 요소 중 단 하나도 반전시키지 않아야 했습니다.
결과: 단 한 번의 생성으로 6개의 회전 뷰, 4개의 헤드 스터디, 4개의 표정, 무기 패널, 손, 발이 모두 한 페이지에 나왔습니다. 네 가지 비대칭 요소 모두 완벽하게 고정되었으며, 좌우 반전은 없었습니다.


환경은 완성된 디자인 레퍼런스로 처리했습니다 (사이버펑크 습한 뒷골목, 'Stray' 게임 미학):

4. 방법을 증명하는 A/B 테스트
이 실험이 전체 워크플로우의 핵심입니다. 동일한 대본, 동일한 캐릭터 시트, 동일한 배경 레퍼런스. 유일한 변수는 스토리보드 존재 여부입니다.
대조군: 스토리보드 없이 텍스트 프롬프트만 사용
Seedance 2.0 레퍼런스 투 비디오 입력값:
- 캐릭터 시트 1장
- 배경 레퍼런스 1장
- 네 번의 하드 컷을 설명하는 15초 분량의 상세한 서술형 프롬프트
영상을 읽을 수 있고 기술적으로도 괜찮지만, 전체 클립은 골목으로 걸어 들어가서 무기를 들고 멈추는 약 세 번의 느린 비트로 연출됩니다. 전투가 아니라 캐릭터 데모처럼 느껴집니다.
실험군: 16개 셀 스토리보드 사용
GPT Image 2를 사용해 동일한 대본을 4×4=16개 셀의 스토리보드로 나누고, 각 셀에 다음 정보를 태깅했습니다:
- 샷 번호 (① ② ③ … ⑯)
- 샷 사이즈 (WIDE / MS / CU / ECU)
- 카메라 이동 화살표 (→ ↘ ↙ ↑ ↓ ↗)
- 리듬 노트 ("static rise" / "hard cut" / "impact" / "kill shot" / "outro")
- 한자로 직접 적은 짧은 연출 노트 — 연출적 의도를 작은 스토리보드 셀에 담기 위해 선택함 (GPT Image 2와 Seedance 2.0 모두 한자를 아주 잘 이해함)
그런 다음 Seedance 2.0 레퍼런스 투 비디오에 한 줄 프롬프트를 입력했습니다:
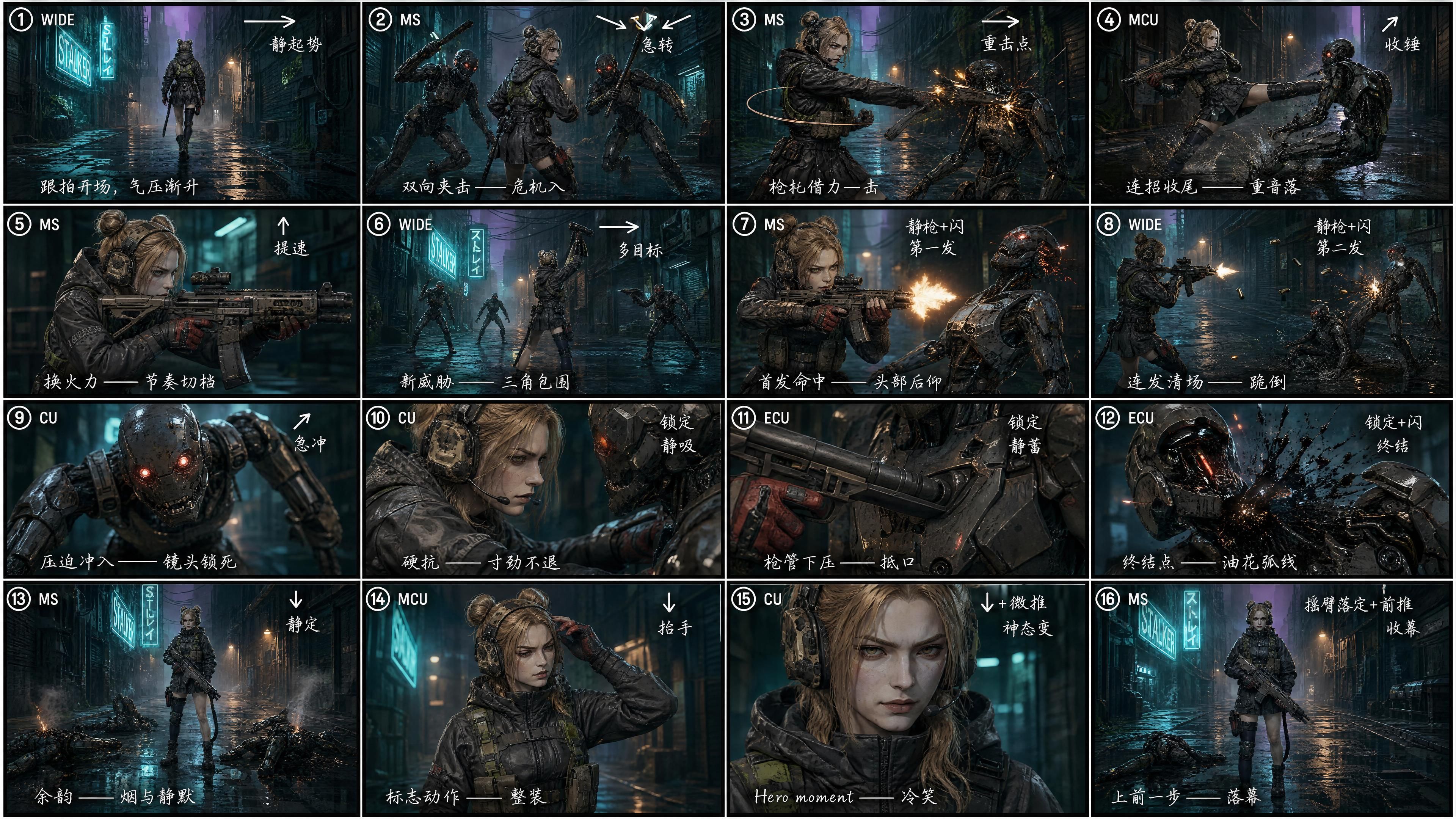
"스토리보드로서 레퍼런스 이미지 3을 엄격하게 따르는 영상을 생성하라. 강력한 영화적 느낌과 샷 언어, 과장된 역동성, 강력한 타격감을 구현할 것."
측정하지 않아도 차이가 명확합니다. 컷의 밀도가 약 4배 정도 높아졌습니다. 와이드 추격전에서 어깨너머 미들샷, 총구 극단 클로즈업, 영웅적 포즈로 마무리되는 15초의 꽉 찬 영상이 완성되었습니다. 같은 대본, 다른 페이싱. 첫 번째 버전은 데모처럼 보였지만, 두 번째 버전은 예고편처럼 보입니다.
이것이 이 워크플로우의 핵심 테제입니다: GPT Image 2는 스타일을 고정하기 위한 것이 아니라, 대본을 밀도 높은 샷 시퀀스로 나누기 위한 것입니다.
5. 확장: 두 명의 격투
단일 캐릭터 버전이 완성된 후, 결투 장면으로 확장했습니다. 2인 전투에서 가장 어려운 점은 캐릭터 A, 캐릭터 B, 환경, 액션 리듬이라는 네 가지 요소를 동시에 고정하는 것입니다.
4개의 이미지를 따로 생성해 연결하려 하지 않고, GPT Image 2를 사용해 단일 이미지 내에서 네 가지를 모두 해결했습니다:
- 캐릭터 A (A-27): 란스의 미세 조정 버전 — 짧은 전투 코트를 입은 모래색 포니테일 전술 요원
- 캐릭터 B: 독창적인 남성 용병 디자인 — 검은색과 빨간색의 긴 코트, 묶은 머리, 허리에 찬 브로드소드
- 환경: '애쉬 시티(Ash City)'라는 산업 폐기물 요새 — 황혼의 호박색 빛, 멀리 보이는 화로의 불빛, 어디에나 깔린 연기
- 10개의 수작업 액션 비트: 탐색 → 돌진 → 방어 → 회피 → 훅 → 반격 → 제압 → 니킥 → 근접 → 쓰러짐

중요한 점: 캐릭터 A만 레퍼런스 이미지(앞서 언급한 란스)를 사용했습니다. 캐릭터 B, 전체 환경, 그리고 10개의 액션 비트는 GPT Image 2가 스스로 디자인했습니다. 우리는 분위기만 묘사했을 뿐, 나머지는 모델이 채웠습니다.
스타일, 두 캐릭터의 개성, 환경, 10개의 비트가 모두 단일 생성물 내에 고정되었습니다. 이미지 간의 위화감이 전혀 없으며, 중간에 의상이 바뀌는 일도 없습니다.
그런 다음 Seedance 2.0 레퍼런스 투 비디오로 바로 입력했습니다:
플랫폼 바닥의 진영 문장, 중반부의 그래플링, 마무리 던지기로 이어지는 옥상 대치 장면까지, 2인 안무 15초를 한 번에 구현했습니다.
6. 왜 이 파이프라인이 단일 API 키로 작동하는가
과거에는 캐릭터 → 장면 → 스토리보드 → 비디오로 이어지는 체인을 위해 여러 공급업체의 API 키, SDK, 문서, 청구서, 속도 제한을 저글링해야 했습니다. 어떤 상황인지 잘 아실 겁니다.
AtlasCloud에서는 이 모든 것이 하나의 엔드포인트 뒤에 있습니다:
| 단계 | 모델 | 플랫폼 |
|---|---|---|
| 캐릭터 시트 | GPT Image 2 | AtlasCloud |
| 장면 컨셉 | Nano Banana 2 | AtlasCloud |
| 스토리보드 | GPT Image 2 | AtlasCloud |
| 비디오 | Seedance 2.0 | AtlasCloud |
키 하나, 엔드포인트 하나, 할당량 하나, 청구서 하나. 통합 및 운영 오버헤드가 거의 제로에 가깝습니다.
7. 결론: 모델 간 스타일 통일에 집착하지 말고, 각 모델의 강점을 살리십시오
우리는 체인의 모든 단계에서 하나의 스타일을 고정하기 위해 많은 노력을 쏟았습니다. 하지만 레퍼런스 투 비디오 모드에서 그 싸움은 이길 수 없는 싸움입니다. 강제로 스타일을 요구할수록 결과물은 나빠집니다.
그 목표를 내려놓자 워크플로우가 훨씬 자유로워졌습니다. 각 모델이 가장 잘하는 일을 하게 하십시오.
- GPT Image 2 — 대본을 나누고 샷을 배치
- Seedance 2.0 — 시간을 펼치고 액션을 렌더링
- AtlasCloud — 키 하나, 체인 하나
AI로 액션 단편, 전투 장면, 2인 안무를 만들고 있다면, 우리가 제안하는 이 워크플로우를 활용해 보십시오.
직접 해보십시오
모든 모델은 AtlasCloud 모델 풀에 있으며, 하나의 API 키로 전체 체인을 실행할 수 있습니다:
- Seedance 2.0 (레퍼런스 투 비디오) → atlascloud.ai/collections/seedance2
- GPT Image 2 (캐릭터 시트 + 스토리보드) → atlascloud.ai/collections/gpt-image-2
- Nano Banana 2 (장면 컨셉) → atlascloud.ai/collections/nanobanana-2
전체 단계별 가이드와 이 기사에 사용된 모든 프롬프트는 YouTube 영상 설명과 함께 게시되어 있습니다.
지금 바로 무언가를 만들어 보십시오.






