
ChatGPT API for Frontier GPT 5.6 Reasoning
ChatGPT API w Atlas Cloud udostępnia najnowszą rodzinę modeli GPT 5.6 od OpenAI w ramach jednej integracji, obejmującej Sol do zaawansowanego rozumowania na granicy możliwości, Terra do ugruntowanych obciążeń produkcyjnych oraz Luna do naturalnych konwersacji i generowania treści. Kieruj wszystkie modele przez jeden klucz zgodny z OpenAI, korzystaj z niezawodności klasy produkcyjnej i płać przejrzyste stawki pay-as-you-go zaczynające się od $1 za milion tokenów wejściowych. Zacznij tworzyć już dziś.
Poznaj Wiodące Modele
Atlas Cloud zapewnia najnowsze, wiodące w branży modele kreatywne.
Wybierz odpowiedni model ChatGPT API: porównanie wszystkich endpointów
Pięć endpointów generowania tekstu, od zaawansowanego rozumowania po ekonomiczne konwersacje, dostępnych przez jeden klucz zgodny z OpenAI i z przejrzystym cennikiem pay-as-you-go.
| Modalność | Opis |
|---|---|
| GPT 5.6 Sol API (Text to Text) | Stworzony z myślą o najbardziej zaawansowanych obciążeniach AI, GPT 5.6 Sol przekształca złożone prompty tekstowe w dogłębne, wieloetapowe wyniki rozumowania do ambitnego rozwiązywania problemów. Standardowa cena wynosi $5 za milion tokenów wejściowych i $30 za milion tokenów wyjściowych, co czyni go flagowym wyborem, gdy jakość odpowiedzi jest ważniejsza niż koszt. |
| GPT 5.6 Terra API (Text to Text) | Potrzebujesz niezawodnego domyślnego modelu produkcyjnego? GPT 5.6 Terra przekształca prompty w osadzony w kontekście, praktyczny tekst do rzeczywistych przepływów pracy i potoków analitycznych w cenie $2.50 za wejście i $15 za wyjście za milion tokenów. Zespoły wdrażają go w aplikacjach skierowanych do klientów, gdzie spójność jest ważniejsza niż eksperymentalna głębia. |
| GPT 5.6 Luna API (Text to Text) | Kieruj ruch konwersacyjny i kreatywny do GPT 5.6 Luna — modelu tekstowego dostrojonego do naturalnego dialogu, generowania treści i spersonalizowanych doświadczeń AI. Przy cenie $1 za wejście i $6 za wyjście za milion tokenów jest to najbardziej ekonomiczny punkt wejścia w tej ofercie ChatGPT API, dobrze dopasowany do produktów czatowych i masowego generowania tekstów marketingowych. |
| GPT 5.4 API (Text to Text) | GPT 5.4 przetwarza instrukcje tekstowe na niezawodny kod, długie formy treści i uporządkowane wyniki rozwiązywania problemów z wysoką dokładnością. Zaprojektowany jako zaawansowany model multimodalny, plasuje się w średnim poziomie cenowym: $2.50 za wejście i $15 za wyjście za milion tokenów, co czyni go praktycznym wyborem dla asystentów programowania i platform treści. |
| GPT 5.5 API (Text to Text) | Gdy trudne problemy uzasadniają wyższe wydatki, GPT 5.5 zapewnia zaawansowane rozumowanie, kodowanie i generowanie treści z jednego endpointu tekstowego. Wyceniony na $5 za wejście i $30 za wyjście za milion tokenów, jest przeznaczony do złożonych obciążeń krytycznych pod względem niezawodności, takich jak orkiestracja agentów i analiza techniczna. |
ChatGPT API: poziomy GPT 5.x i otwarte wagi
Uzyskaj dostęp do pełnej linii GPT 5.x oraz modelu z otwartymi wagami GPT OSS 120B przez jedno ChatGPT API, dostrajaj wysiłek rozumowania od low do xhigh, łącz tekst, obrazy i pliki w jednym wywołaniu oraz korzystaj z natywnych narzędzi z wyszukiwaniem w sieci na żywo przy użyciu jednego klucza zgodnego z OpenAI.
Tekst, obrazy i pliki w jednym wywołaniu ChatGPT API
Pojedyncze żądanie ChatGPT API może połączyć zwykły tekst, adresy URL obrazów i pliki dokumentów w jednej wiadomości. Eliminuje to potrzebę korzystania z osobnych usług OCR lub wizji komputerowej, dzięki czemu możesz podsumowywać zeskanowane umowy albo odczytywać zrzuty ekranu w jednym przebiegu.
Wierność instrukcjom w ChatGPT API
GPT OSS 120B trzyma się warstwowych promptów systemowych, utrzymując stabilne formaty, ograniczenia i ton w kolejnych odpowiedziach bez dryfu. Ta niezawodność sprawdza się w autonomicznych agentach, ekstrakcji strukturalnej i potokach produkcyjnych, w których wynik musi przestrzegać reguł.
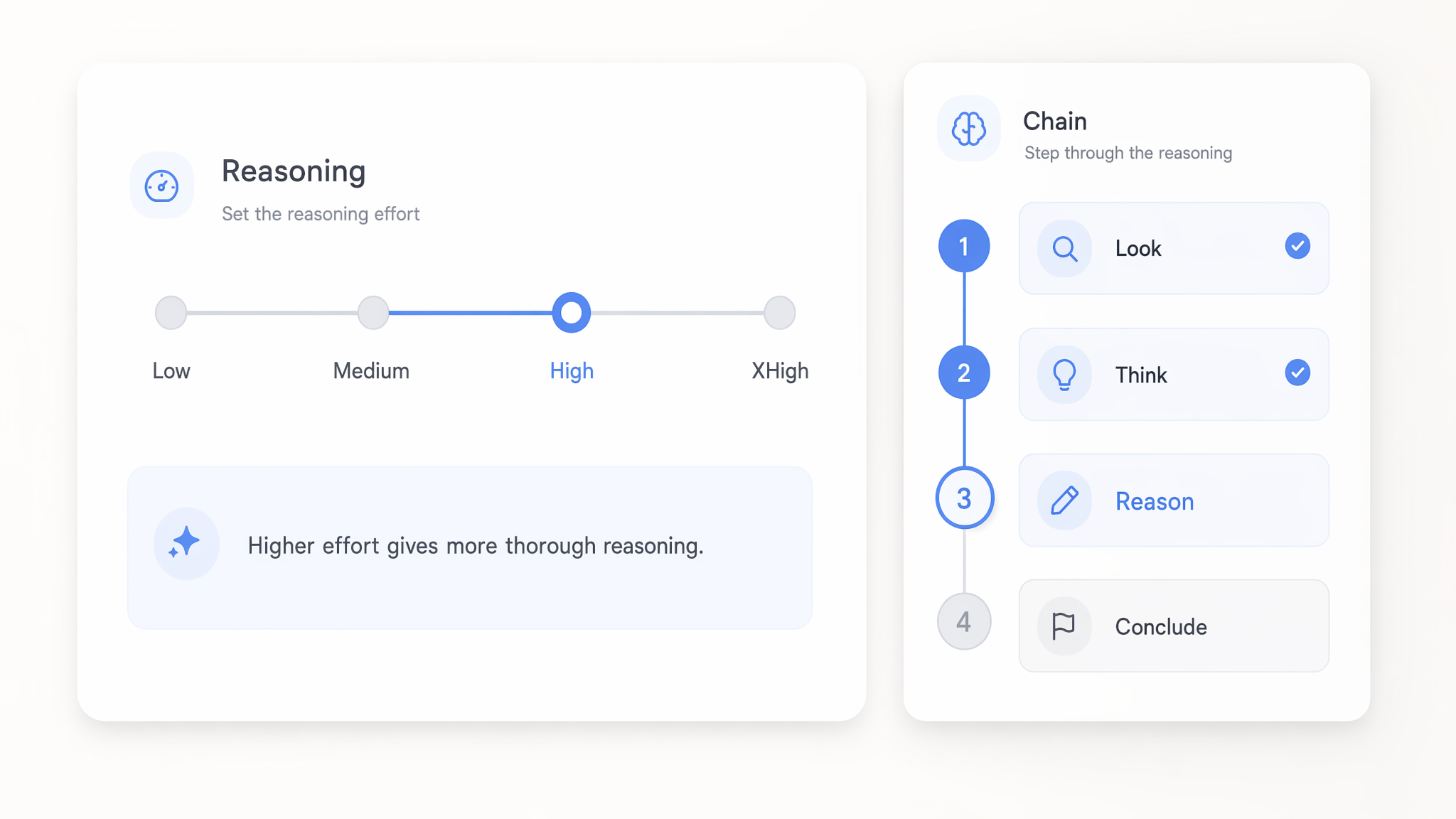
Reguluj wysiłek rozumowania od low do xhigh
Ustaw wysiłek rozumowania w modelach GPT 5.x w dowolnym zakresie od low do xhigh, aby kontrolować, jak głęboko analizują problem przed odpowiedzią. Ustawienia low szybko i tanio obsługują proste wywołania, a xhigh przeznacza więcej mocy obliczeniowej na trudną, wieloetapową logikę.
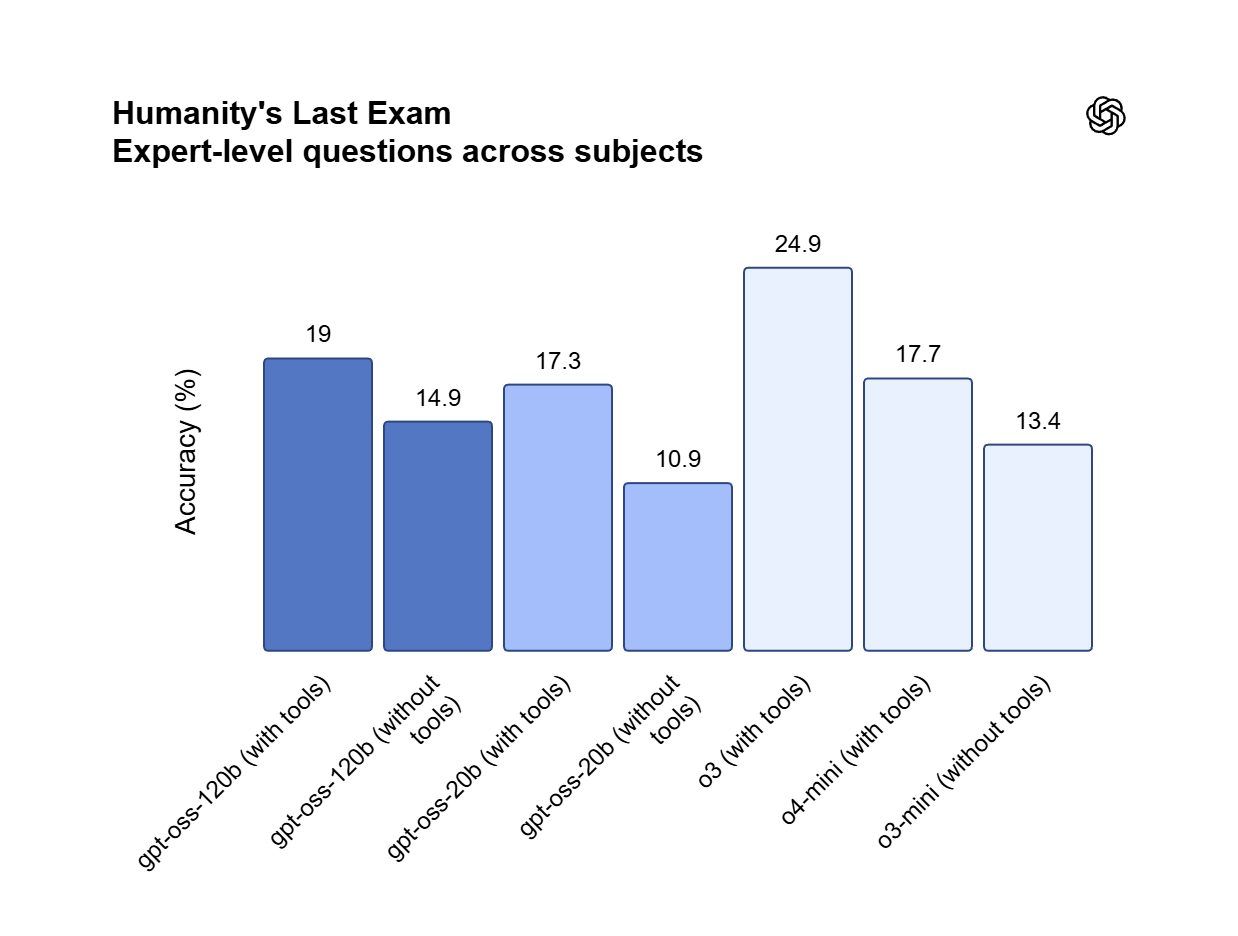
Wagi Apache 2.0, które w pełni kontrolujesz
Udostępniany na licencji Apache 2.0, GPT OSS 120B pozwala na użycie komercyjne i prywatne dostrajanie na pojedynczym GPU 80GB. Uruchom go lokalnie, aby zachować dane własnościowe wewnątrz organizacji i całkowicie uniknąć opłat za tokeny.

Pięć poziomów GPT, jedno ChatGPT API
Jedno ChatGPT API obsługuje pełną linię GPT 5.x, z cenami od Luna za $1 do Sol za $5 za milion tokenów wejściowych. Dopasuj każde wywołanie do poziomu wymaganego kosztu i inteligencji, bez zmiany endpointu.
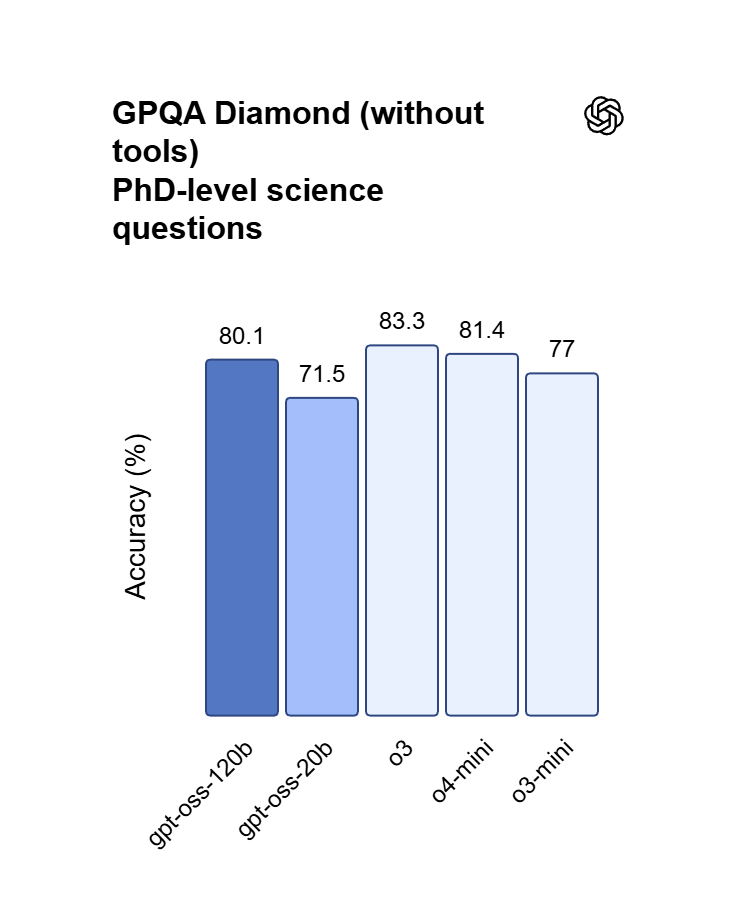
Rozumowanie dostrojone do vibecodingu
Prawie pełna zgodność z OpenAI o4-mini pozwala GPT OSS 120B obsługiwać wieloetapową syntezę kodu i dowody matematyczne. Zamieniaj pomysły opisane naturalnym językiem w działające aplikacje webowe, debuguj zagnieżdżoną logikę i orkiestruj złożone przepływy planowania zadań.

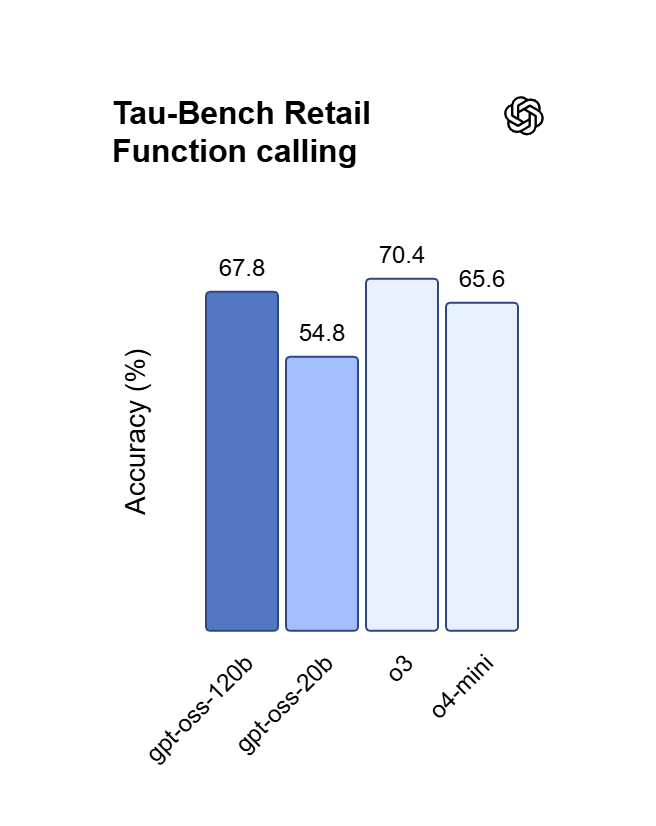
Wywołania funkcji z wyszukiwaniem w sieci na żywo
Modele GPT 5.x obsługują wywoływanie funkcji z automatycznym wyborem narzędzi oraz wbudowane wyszukiwanie w sieci, które pobiera aktualne wyniki. Strumieniuj odpowiedzi jako server-sent events, a cache promptów obniża koszt buforowanego wejścia GPT 5.6 Sol do $0.5 za milion tokenów.
Jeden prompt, trzech rywali: bezpośrednie starcie ChatGPT API
Przekazaliśmy dokładnie tę samą instrukcję budowania modelom przez ChatGPT API oraz dwóm konkurencyjnym flagowcom, a następnie wyrenderowaliśmy każdą surową odpowiedź HTML bez zmian, aby można było porównać obok siebie głębię rozumowania, jakość kodu i wyczucie designu.
Zbuduj pojedynczy, samowystarczalny plik HTML (wyłącznie inline CSS i JavaScript — absolutnie bez zewnętrznych bibliotek, CDN-ów, frameworków, fontów ani adresów URL obrazów), który otwiera się bezpośrednio w dowolnej nowoczesnej przeglądarce i uruchamia żywy, samorozrastający się symulator ekosystemu szklanej szklarni, renderowany w całości jako płaska ilustracja wektorowa Canvas/SVG. Scena na cały viewport przedstawia kopułową wiktoriańską szklarnię: zakrzywiona szklana kopuła łukiem przecina górę jako element ramujący, jej tafle są narysowane jako półprzezroczyste jadeitowozielone wielokąty z miękkimi refleksami i cienkimi obrysami szczeblin, a wzdłuż dołu biegnie pas ciemnej ziemi uprawnej. Kierunek artystyczny to czysta ilustracja wektorowa — liście i łodygi rysowane ostrymi liniami żyłek oraz półprzezroczystymi, warstwowymi wypełnieniami, paleta oparta na mglistym szałwiowym zielonym i mchowym brązie z bursztynowym światłem słonecznym oraz akcentami jadeitowego szkła; bez fotorealizmu, bez gradientów używanych jako tekstury, zachowaj graficzny, ręcznie ilustrowany charakter. Główna interakcja: kliknięcie w dowolnym miejscu ziemi sadzi w tym punkcie nasiono, a roślina rośnie w czasie rzeczywistym z użyciem rzeczywistego L-system — zaimplementuj rekurencyjną gramatykę przepisywania (aksjomat plus reguły produkcji z nawiasami rozgałęzień oraz losowym odchyleniem kąta/długości dla każdej instancji, tak aby żadne dwie rośliny nie były identyczne) i animuj wyprowadzanie, aby gałęzie wydłużały się, rozdwajały i stopniowo rozwijały liście przez kilka sekund, zamiast pojawiać się od razu w pełnej formie. Tropikalne paprocie i pnącza powinny fototropicznie wyginać się i zawijać w stronę przeciąganego słońca: wyrenderuj świecący bursztynowy dysk słońca, który użytkownik może chwycić i przeciągnąć w dowolne miejsce na niebie, a każdy rosnący wierzchołek musi stale przeorientowywać kierunek wzrostu ku aktualnej pozycji słońca, aby przeciąganie słońca wyraźnie sterowało tym, jak cały ogród pochyla się i wspina. Siewki rozwijają się z animacją easing, a krople kondensacji tworzą się na szkle i powoli zsuwają w pętli. Steruj całością cyklem dnia i nocy powiązanym z pozycją słońca: oświetlenie otoczenia i poświata nieba płynnie przechodzą po gradiencie od ciepłego złota do chłodnego błękitu, położenie słońca wyznacza kierunek i długość miękkich cieni roślin rzucanych na podłogę oraz dryfujących plam światła na szkle, a o zmierzchu świetliki łagodnie pojawiają się jako małe, pulsujące punkty światła unoszące się wśród listowia. Kompozycja promieniuje wzrostem roślin od podstawy ku górze, w stronę środka, zamknięta łukiem kopuły. Użyj requestAnimationFrame do ciągłej, spokojnie oddychającej pętli animacji; utrzymaj płynną wydajność przy wielu roślinach widocznych jednocześnie. Dodaj subtelne, nienachalne kontrolki (np. suwak lub automatycznie przesuwany przełącznik pory dnia oraz przycisk resetowania/czyszczenia) stylizowane zgodnie z ilustracyjną estetyką, a także jednowierszową podpowiedź informującą użytkownika, by kliknął ziemię, aby posadzić roślinę, i przeciągnął słońce, aby kierować wzrostem. Dopasuj widok responsywnie do dowolnego rozmiaru okna i nadaj mu spokojny, nieruchomy, a zarazem żywy nastrój — pierwsze poranne światło wpada pod skosem, gdy delikatne pędy otwierają się razem. To symulacja generatywna, nie gra ani dashboard: priorytetem są prawdziwy rekurencyjny algorytm wzrostu, pętla animacji oraz fizyka światła/cienia/fototropizmu.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Zbuduj kompletną, jednoplikową stronę HTML zawierającą interaktywny dashboard globalnego finansowania startupów z fikcyjnymi, lecz wewnętrznie spójnymi danymi dla 8 sektorów branżowych na przestrzeni 5 lat. Cały CSS i JavaScript muszą być inline, bez żadnych zewnętrznych zależności, bez bibliotek wykresów, CDN-ów ani obrazów. Wyrenderuj trzy ręcznie zakodowane wizualizacje na canvas lub SVG: animowany wykres słupkowy, który sortuje się ponownie z easingiem, gdy użytkownik wybierze rok na suwaku, wykres liniowy z tooltipami po najechaniu pokazującymi dokładne wartości i pionową prowadnicą śledzącą, oraz wykres donut, którego segmenty rozszerzają się po najechaniu z animacją sprężynową. Dodaj ciemny, nowoczesny UI z paletą akcentów od fioletu do turkusu, animowane liczniki liczb w czterech kartach statystyk KPI, wiersz filtrów sektorów w formie przełączanych chipów, który natychmiast aktualizuje wszystkie wykresy, oraz przełącznik motywu jasny/ciemny z płynnymi przejściami kolorów. Układ musi być responsywny i poniżej 768px zwijać się do jednej kolumny, a każda interakcja musi reagować w czasie rzeczywistym bez przeładowania strony.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
Każde obciążenie, które może obsłużyć ChatGPT API
Od agentowego kodowania i ekstrakcji strukturalnej po czat wsparcia oparty na źródłach i treści na dużą skalę — ChatGPT API w Atlas Cloud kieruje każde zadanie do odpowiedniej warstwy GPT 5.6 za pomocą jednego klucza zgodnego z OpenAI.

Twórz agentowe narzędzia programistyczne z ChatGPT API
Kieruj złożone refaktoryzacje i syntezę kodu obejmującą wiele plików do GPT 5.6 Sol — warstwy tej rodziny przeznaczonej do głębokiego rozumowania i zaprojektowanej z myślą o najbardziej zaawansowanych obciążeniach inżynieryjnych. Zespoły tworzące copilots do kodowania, automatyczne boty do review i generatory testów otrzymują logikę gotową do produkcji.

Generowanie treści zgodnych z marką na dużą skalę
GPT 5.6 Luna, kreatywna warstwa tej rodziny, tworzy szkice wpisów blogowych, opisy produktów i zlokalizowane teksty z naturalnym tonem oraz spersonalizowanym wynikiem. Zespoły contentowe i platformy ecommerce produkują duże wolumeny tekstów bez utraty spójności głosu marki.

Zasil asystentów wsparcia przez ChatGPT API
Potrzebujesz chatbota, który trzyma się scenariusza? GPT 5.6 Terra dostarcza niezawodne, ugruntowane odpowiedzi stworzone do rozmów produkcyjnych, dzięki czemu zespoły wsparcia i produkty SaaS mogą automatyzować zgłoszenia i skutecznie ograniczać powtarzalne zapytania.

Systemy wiedzy wspomagane wyszukiwaniem
Przekaż pełne podręczniki procedur lub archiwa badawcze do modelu z długim kontekstem i uzyskaj ugruntowane odpowiedzi wierne źródłom. Zespoły prawne, medyczne i zajmujące się wyszukiwaniem wewnętrznym zyskują niezawodny silnik do odpowiadania na pytania wspomaganego wyszukiwaniem.

Ekstrakcja danych strukturalnych przez ChatGPT API
Chaotyczne faktury, e-maile i pliki PDF zamieniają się w czysty JSON, któremu mogą zaufać systemy downstream. Niezawodne wykonywanie instrukcji utrzymuje schematy w nienaruszonym stanie, obsługując potoki danych, automatyzację CRM i przepływy analityczne, które nie tolerują odchyleń.

Dopasuj każde zadanie do właściwej warstwy modelu
Gdy liczą się budżet i opóźnienia, przełączaj się między Sol, Terra i Luna za pomocą jednego klucza zgodnego z OpenAI. Startupy i niezależni deweloperzy szybko prototypują w modelu pay-as-you-go, a następnie skalują tę samą integrację do produkcji.
| Model | Kontekst | Maks. wynik | Wejście | Pozycjonowanie |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Tekst | Wysokowydajny LLM do rozumowania |
| GLM-5 | 202.75K | 202.75K | Tekst | Flagowy model bazowy |
| DeepSeek V3.2 | 163.84K | 163.84K | Tekst | Flagowy model ogólnego zastosowania |
| MiniMax-M2.5 | 204.8K | 196.6K | Tekst | Najnowocześniejsze agentowe kodowanie |
Jak używać ChatGPT na Atlas Cloud
Zacznij w kilka minut — wykonaj te proste kroki, aby zintegrować i wdrożyć modele za pośrednictwem platformy Atlas Cloud.
Utwórz konto Atlas Cloud
Zarejestruj się na atlascloud.ai i ukończ weryfikację. Nowi użytkownicy otrzymują bezpłatne kredyty do eksploracji platformy i testowania modeli.
Dlaczego Używać ChatGPT na Atlas Cloud
Połączenie zaawansowanych modeli ChatGPT z platformą GPU-akcelerowaną Atlas Cloud zapewnia niezrównaną wydajność, skalowalność i doświadczenie deweloperskie.
Wydajność i Elastyczność
Niska Latencja:
Inferencja zoptymalizowana pod GPU dla rozumowania w czasie rzeczywistym.
Zunifikowane API:
Uruchamiaj ChatGPT, GPT, Gemini i DeepSeek za pomocą jednej integracji.
Przejrzysta Wycena:
Przewidywalne rozliczenia za token z opcjami serverless.
Przedsiębiorstwo i Skala
Doświadczenie Dewelopera:
SDK, analityka, narzędzia dostrajania i szablony.
Niezawodność:
99,99% dostępności, RBAC i logowanie gotowe na zgodność.
Bezpieczeństwo i Zgodność:
SOC 2 Type II, zgodność z HIPAA, suwerenność danych w USA.
ChatGPT API: odpowiedzi na pytania deweloperów
ChatGPT API pozwala deweloperom wysyłać prompty do modeli GPT firmy OpenAI i programowo odbierać uzupełnienia, zamiast korzystać z interfejsu czatu. W Atlas Cloud uzyskujesz dostęp do pełnej linii GPT 5.6, wraz z GPT 5.4 i GPT 5.5, przez jeden endpoint zgodny z OpenAI. Każde wywołanie jest rozliczane za token według przejrzystego cennika pay-as-you-go, więc płacisz tylko za to, co wygenerujesz.
Pięć modeli obejmuje zakres od zaawansowanego rozumowania po codzienny czat. GPT 5.6 Sol jest przeznaczony do ambitnego rozwiązywania problemów i zadań frontier, GPT 5.6 Terra obsługuje niezawodne przepływy produkcyjne, a GPT 5.6 Luna jest dostrojony do naturalnej rozmowy i generowania treści. GPT 5.4 i GPT 5.5 dodają rozumowanie multimodalne oraz kodowanie dla zespołów, które chcą sprawdzonej, uniwersalnej wydajności.
Wygeneruj jeden klucz API, ustaw bazowy URL na https://api.atlascloud.ai/v1 i wybierz identyfikator modelu, taki jak openai/gpt-5.6-terra. Ponieważ tutejsze ChatGPT API jest w pełni zgodne z OpenAI, istniejący kod oparty na OpenAI SDK działa po zmianie tylko bazowego URL-a i klucza. Nie ma listy oczekujących ani subskrypcji, a nowe wydania są dostępne w Day-0 access, więc pierwsze żądanie możesz wysłać tego samego dnia.
Ceny zależą od wybranego modelu. GPT 5.6 Luna jest najbardziej ekonomiczny: $1 za milion tokenów wejściowych i $6 za milion tokenów wyjściowych, GPT 5.6 Terra kosztuje $2.5 i $15, a GPT 5.6 Sol — $5 i $30. Buforowanie promptów obniża koszt powtarzanego wejścia, a rozliczenia pozostają w modelu pay-as-you-go, więc płacisz tylko za użyte tokeny.
Tak. Endpoint używa formatu OpenAI Chat Completions, więc oficjalne OpenAI SDK, LangChain i większość bibliotek zgodnych z OpenAI działają po podmianie bazowego URL-a i klucza. Oznacza to, że istniejącą integrację z ChatGPT API można przenieść bez przepisywania logiki żądań.
Streaming i function calling działają tak samo jak w implementacji OpenAI, więc ustawiasz stream na true, aby otrzymywać dane token po tokenie, i przekazujesz tablicę tools, aby wywoływać funkcje. Strukturyzowane odpowiedzi JSON korzystają z tego samego formatu żądań zgodnego z OpenAI, co zapewnia przewidywalność orkiestracji agentów i pipeline'ów ekstrakcji danych.
Te modele przyjmują duże prompty do pracy z długimi dokumentami i pełnymi repozytoriami. Cennik jest warstwowy od progu 272,000 tokenów: standardowa stawka obowiązuje dla promptów poniżej tej wartości, a druga stawka dla promptów przekraczających 272,000 tokenów. Możesz więc przekazać rozległy kontekst w jednym żądaniu i dokładnie wiedzieć, jak zmienia się stawka wraz ze wzrostem promptu.
Dopasuj model do zadania. Wybierz GPT 5.6 Sol, gdy potrzebujesz rozumowania frontier i ambitnego rozwiązywania problemów, GPT 5.6 Terra do ugruntowanej analizy klasy produkcyjnej, a GPT 5.6 Luna do pracy konwersacyjnej lub kreatywnej, gdy koszt ma największe znaczenie. GPT 5.4 i GPT 5.5 pozostają mocnymi opcjami multimodalnymi do kodowania i ogólnego rozumowania.
Atlas Cloud uruchamia ChatGPT API na zarządzanej infrastrukturze, która skaluje się wraz z ruchem, dzięki czemu unikasz provisioningu GPU i orkiestracji węzłów typowych dla self-hostingu. Nowe wersje modeli trafiają do usługi z Day-0 access, więc pozostajesz na bieżąco bez prac migracyjnych. Gdy Twoje potrzeby wzrosną, ten sam klucz zgodny z OpenAI obejmuje każdy model w rodzinie, więc skalowanie nigdy nie oznacza nowej integracji.
Poznaj Więcej Rodzin
Seedance 2.0
API Seedance 2.0 zapewnia produkcyjny dostęp do multimodalnego modelu wideo ByteDance — czteromodalne dane wejściowe (tekst, obraz, wideo, dźwięk) oraz wiodący w branży system „Universal Reference”, który blokuje kompozycję, ruchy kamery i działania postaci w różnych ujęciach. Zintegruj kontrolę na poziomie reżysera za pomocą jednego wywołania API, stałej stawki 0,09 USD/s, natychmiastowego klucza i braku listy oczekujących — wszystko to przy wsparciu czasu sprawności i zgodności klasy korporacyjnej. Seedance 2.0 Native 4K jest już dostępne!
Grok Imagine
Grok Imagine API zapewnia programistom możliwość generowania obrazów, wideo i dźwięku od xAI w jednym pakiecie. Tworzy obrazy w rozdzielczości do 2K z wielojęzycznym renderowaniem tekstu, a także filmy do 15 sekund z natywnym, zsynchronizowanym dźwiękiem i edycją opartą na referencjach. W Atlas Cloud jeden klucz uruchamia każdy tryb Grok Imagine, dzięki czemu można przełączać się między obrazem, wideo i dźwiękiem bez osobnych konfiguracji, już od 0,02 USD za obraz i 0,05 USD za sekundę.
Gemini Omni Flash
Gemini Omni API wprowadza do Twojego stacku multimodalny model generowania i edycji wideo od Google DeepMind, zaprezentowany na Google I/O 2026. Gemini Omni łączy silnik rozumowania Gemini z mediami generatywnymi, przyjmując dowolną kombinację tekstu, obrazów, wideo i dźwięku, aby tworzyć spójne, oparte na wiedzy wyniki. Dopracowuj rezultaty w naturalnej rozmowie — podmieniaj obiekty, przepisuj sceny i zmieniaj style, podczas gdy fizyka, postacie i ciągłość pozostają nienaruszone. Atlas Cloud udostępnia pełną gamę Gemini Omni Flash — tekst na wideo, obraz na wideo z maksymalnie 7 obrazami referencyjnymi oraz referencję na wideo — poprzez jedno ujednolicone API z przejrzystym rozliczaniem za sekundę już od $0.112 i bez subskrypcji. Zacznij tworzyć już dziś.
GPT Image 2
API GPT Image 2 daje programistom dostęp do najnowszego modelu obrazów firmy OpenAI, następcy GPT Image 1.5. Generuje i edytuje on obrazy z dokładnym renderowaniem tekstu w skryptach łacińskich i CJK, a także zapewnia silną kompozycję dla plakatów, makiet i infografik. W Atlas Cloud można uzyskać do niego dostęp za pośrednictwem jednego zunifikowanego API wraz z ponad 300 modelami, z darmowymi kredytami, gwarantowanym czasem pracy (uptime) na poziomie 99,99% i bez wymogu weryfikacji organizacji OpenAI.
Najpotężniejsze modele kreatywne Google są w pełni dostępne na platformie Atlas Cloud. Veo 3.1 zapewnia kinową generację wideo, Nano Banana 2 umożliwia tworzenie obrazów o wysokiej wierności, a Gemini wprowadza wielomodalną inteligencję do każdego przepływu pracy. Uzyskaj dostęp do pełnego pakietu modeli Google za pomocą jednego klucza API key z dostępnością Day-0 i cennikiem pay-as-you-go.
Seedance 2.0 Mini
Seedance 2.0 Mini wprowadza multimodalne generowanie wideo firmy ByteDance do przepływów pracy, w których szybkość i koszty mają największe znaczenie. Zapewnia podstawowe możliwości Seedance 2.0 przy mniejszym zużyciu zasobów — szybsze generowanie, niższy koszt na wideo i tę samą integrację API, z której już korzystasz. Dla zespołów obsługujących potoki o dużej objętości lub tworzących prototypy na dużą skalę, Mini jest praktycznym wyborem domyślnym.
ByteDance
Od generowania kinowych filmów po tworzenie obrazów o wysokiej wierności, najpotężniejsze modele ByteDance są dostępne w Atlas Cloud. Uruchamiaj Seedance i Seedream na dużą skalę z najniższymi cenami wnioskowania i zerowymi kosztami ogólnymi infrastruktury.
Alibaba
Atlas Cloud łączy pełną gamę modeli Alibaba w ramach jednego API: Qwen do zadań związanych z językiem i obrazem oraz Wan do generowania wideo w rozdzielczości do 1080p. Uzyskaj dostęp do każdego modelu w modelu płatności zgodnie z rzeczywistym użyciem (pay-as-you-go) bez subskrypcji. Alibaba API jest dostępne poprzez pojedynczy bazowy adres URL (base URL) przy użyciu istniejącego klienta kompatybilnego z OpenAI.
OpenAI
Atlas Cloud zapewnia dostęp do pełnej linii API OpenAI, od GPT Image 2 do generowania obrazów po Sora 2 do wideo. Każdy model jest dostępny w modelu płatności za użycie (pay-as-you-go) bez miesięcznych zobowiązań. Zintegruj się za pomocą jednej zmiany bazowego adresu URL, korzystając z API kompatybilnego z OpenAI.
xAI
Zbuduj kompletne potoki przetwarzania obrazów i wideo za pomocą xAI API w Atlas Cloud. Generuj w rozdzielczości 2K, edytuj za pomocą obrazów referencyjnych i animuj obrazy w klipy zsynchronizowane z dźwiękiem.
Kwaivgi
API Kwaivgi o 15% poniżej standardowej ceny. Atlas Cloud zapewnia dostęp od pierwszego dnia (Day-0) do nowych wydań Kling z modelem płatności zgodnie z użyciem (pay-as-you-go) i bez limitów stanowisk. Jedno konto, jeden klucz, każdy model Kling od poziomu standardowego po poziom master.
Seedream 5.0 Pro
Seedream 5.0 Pro API udostępnia programistom sterowalny model edycji obrazów firmy ByteDance w Atlas Cloud. Precyzyjnie rozmieszcza edycje za pomocą kotwic i współrzędnych, dzieli obrazy na edytowalne warstwy, łączy wiele odniesień oraz dopasowuje dokładne kolory i materiały, z wielojęzycznym tekstem w rozdzielczościach 2K i 3K. W Atlas Cloud można uzyskać do niego dostęp za pomocą jednego klucza!


