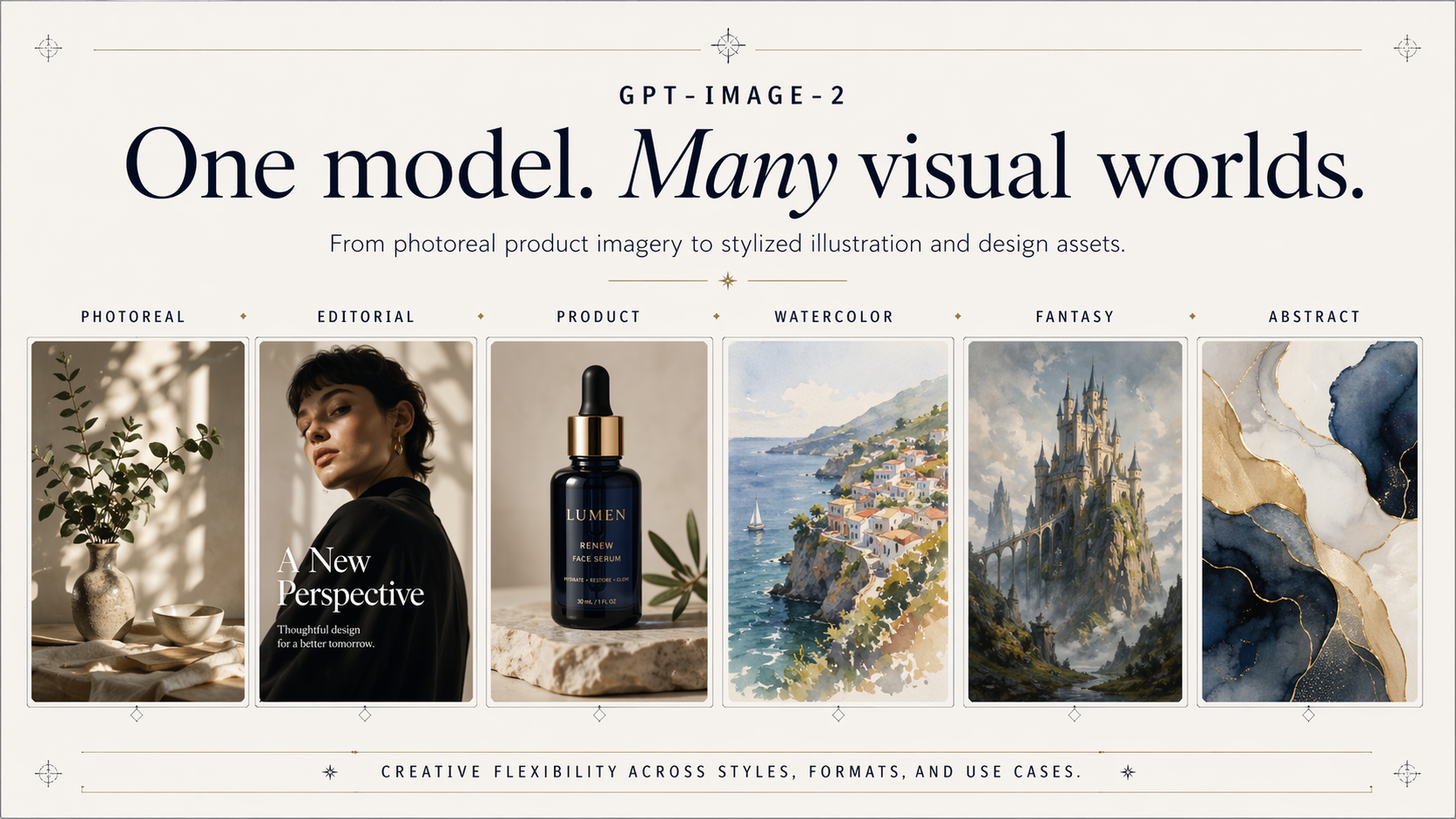

GPT Image 2 API for Accurate In-Image Text
API GPT Image 2 daje programistom dostęp do najnowszego modelu obrazów firmy OpenAI, następcy GPT Image 1.5. Generuje i edytuje on obrazy z dokładnym renderowaniem tekstu w skryptach łacińskich i CJK, a także zapewnia silną kompozycję dla plakatów, makiet i infografik. W Atlas Cloud można uzyskać do niego dostęp za pośrednictwem jednego zunifikowanego API wraz z ponad 300 modelami, z darmowymi kredytami, gwarantowanym czasem pracy (uptime) na poziomie 99,99% i bez wymogu weryfikacji organizacji OpenAI.
Poznaj Wiodące Modele
Atlas Cloud zapewnia najnowsze, wiodące w branży modele kreatywne.




Prędkość szczytowa GPT Image 2 API
Porównaj punkty końcowe API GPT Image 2 w całej rodzinie produktów, obejmujące generowanie obrazu z tekstu i edycję dla GPT Image 2, 1.5, 1 oraz Mini, dzięki czemu przez jedną integrację dostosujesz koszt i jakość do każdego zadania.
| Modalność | Opis |
|---|---|
| GPT Image-1 T2I API(Text to Image) | API Text to Image dla GPT Image-1 umożliwia programistom przekształcanie podpowiedzi tekstowych w oszałamiające, fotorealistyczne wizualizacje o wyjątkowej szczegółowości. Łącząc wnioskowanie GPT-4 Turbo z syntezą wizualną klasy DALL·E, zapewnia wiodącą w branży wierność podpowiedziom i możliwości tworzenia złożonych kompozycji do profesjonalnej produkcji obrazów. |
| GPT Image-1 Edit API(Image to Image) | GPT Image-1 Edit API umożliwia programistom przekształcanie istniejących obrazów w dopracowane lub wymyślone na nowo arcydzieła z zachowaniem płynnej spójności. Wykorzystując multimodalne zrozumienie, generuje precyzyjne transfery stylistyczne, kompozycje kontekstowe i ukierunkowane modyfikacje na potrzeby iteracji zasobów na profesjonalnym poziomie. |
| GPT Image-1.5 T2I API(Text to Image) | API GPT Image-1.5 Text to Image umożliwia programistom przekształcanie promptów tekstowych w wysokiej jakości materiały wizualne przy zoptymalizowanych kosztach. Wykorzystując architekturę opartą na technologii GPT, zapewnia silne zrozumienie promptów i wierność wizualną dla zrównoważonych przepływów pracy produkcyjnej. |
| GPT Image-1.5 Edit API(Image to Image) | GPT Image-1.5 Edit API umożliwia programistom udoskonalanie istniejących zasobów za pomocą precyzyjnych modyfikacji. Dzięki obsłudze kontroli input_fidelity pozwala na dokonywanie drobnych korekt przy jednoczesnym zachowaniu kluczowych elementów, takich jak twarze i logo. |
| GPT Image-1 Mini T2I API(Text to Image) | GPT Image-1 Mini Text to Image API zapewnia programistom najbardziej opłacalne generowanie obrazów w całej rodzinie produktów. Wykorzystując architekturę GPT-5, dostarcza profesjonalne wyniki przy najniższym koszcie za obraz w przypadku masowej produkcji treści. |
| GPT Image-1 Mini Edit API(Image to Image) | GPT Image-1 Mini Edit API umożliwia programistom przekształcanie istniejących obrazów dzięki usprawnionym funkcjom edycji. Zapewniając podstawowe funkcje edycji przy minimalnych kosztach, ułatwia szybką iterację i przepływy pracy przy produkcji treści. |
Kluczowe cechy GPT Image 2
Odkryj, co potrafi GPT Image 2 API, od precyzyjnego tekstu na obrazach w pismach łacińskich i CJK, po fotorealistyczne renderowanie, edycję opartą na maskach i kompozycję z wieloma odniesieniami.

Renderowanie fotorealistyczne
GPT Image 2 zapewnia fotorealistyczne wyniki w grafikach marketingowych, wizualizacjach produktów, treściach społecznościowych i makietach, gdzie dokładność jest równie ważna co jakość wizualna. Wykazuje prawdziwe zrozumienie fizyki, oświetlenia i właściwości materiałów, z neutralnymi, dokładnymi kolorami we wszystkich typach scen.

Niemal doskonały tekst na obrazie
GPT Image 2 renderuje poprawnie napisany, naturalnie umieszczony tekst na obrazach, od oznakowań i etykiet interfejsu użytkownika po plakaty. Niezawodnie i na dużą skalę tworzy grafiki marketingowe, kreacje reklamowe i nagłówki wiadomości e-mail z precyzyjnym tekstem.

Zaawansowana kontrola kompozycji
GPT Image 2 radzi sobie ze złożonymi scenami z wieloma obiektami bez błędów okluzji i rozmieszczenia znanych z wcześniejszych modeli. Podąża za długimi, wieloczęściowymi promptami, zachowując przy tym kompozycję, oświetlenie i drobne detale.

Spójność Postaci
GPT Image 2 zachowuje spójność tożsamości postaci, rekwizytów i oświetlenia podczas wielu generacji. Ta spójność obiektu utrzymuje się w kompozycjach wieloelementowych, co czyni model niezawodnym przy tworzeniu zestawów wariantów i prac seryjnych.

Obsługa tekstu wielojęzycznego
GPT Image 2 renderuje znaki CJK z dokładnymi glifami i wyraźnymi pociągnięciami, co stanowi wyraźną poprawę w stosunku do słabości wcześniejszych modeli wobec pism nielacińskich. Obsługuje zaawansowane renderowanie tekstu zarówno w językach łacińskich, jak i CJK.

Edycja obrazów z obsługą masek
Interfejs Edit API obsługuje precyzyjne inpainting i outpainting za pomocą obrazów masek, umożliwiając modyfikację określonych obszarów, podczas gdy każdy niepowiązany piksel pozostaje nienaruszony. Dzięki temu interfejs GPT Image 2 API jest niezawodny w zakresie retuszu, usuwania obiektów i kontrolowanego czyszczenia kompozycji.

Kompozycja wieloreferencyjna
GPT Image 2 API potrafi połączyć kilka obrazów wejściowych w jeden spójny wynik, kierując się promptem w języku naturalnym. Obsługuje to lokowanie produktu, transfer stylu i spójne postacie w zestawie wygenerowanych materiałów wizualnych.

Makiety UI i Interfejsu
GPT Image 2 generuje makiety UI i interfejsy aplikacji z poprawnie napisanym tekstem na przyciskach i przejrzystą strukturą układu. Idealnie nadaje się do szybkich ekranów koncepcyjnych i podglądów projektów, w których liczy się czytelność tekstu na ekranie.

Ścisłe Przestrzeganie Promptów
API GPT Image 2 realizuje długie i wieloczęściowe prompty z niezawodnym przestrzeganiem instrukcji, zachowując kompozycję, wybór oświetlenia i drobne szczegóły. Rezultatem jest mniejsza liczba ponownych prób i niezawodne wyniki dla produkcyjnych przepływów pracy.
Porównanie GPT Image 2 z innymi modelami SOTA
Create a Japanese-language infographic titled "うちの部署のメンバー スペック分析" (Our Department Member Spec Analysis) with subtitle "個性豊かなプロ集団(たぶん)". Layout as a 2x3 grid of six member cards on a clean white background with pastel accents and star decorations. Each card features a cute chibi-style cartoon avatar and includes: member name and role in Japanese, a radar chart or bar chart showing their stats, bullet-point strengths and weaknesses in Japanese. Add a summary section at the bottom with overall team evaluation, a team compatibility graph placeholder, and a final takeaway note. Cheerful office illustration style, soft rounded UI elements, kawaii aesthetic, highly legible Japanese typography, no watermark.

GPT Image 2

Grok Imagine
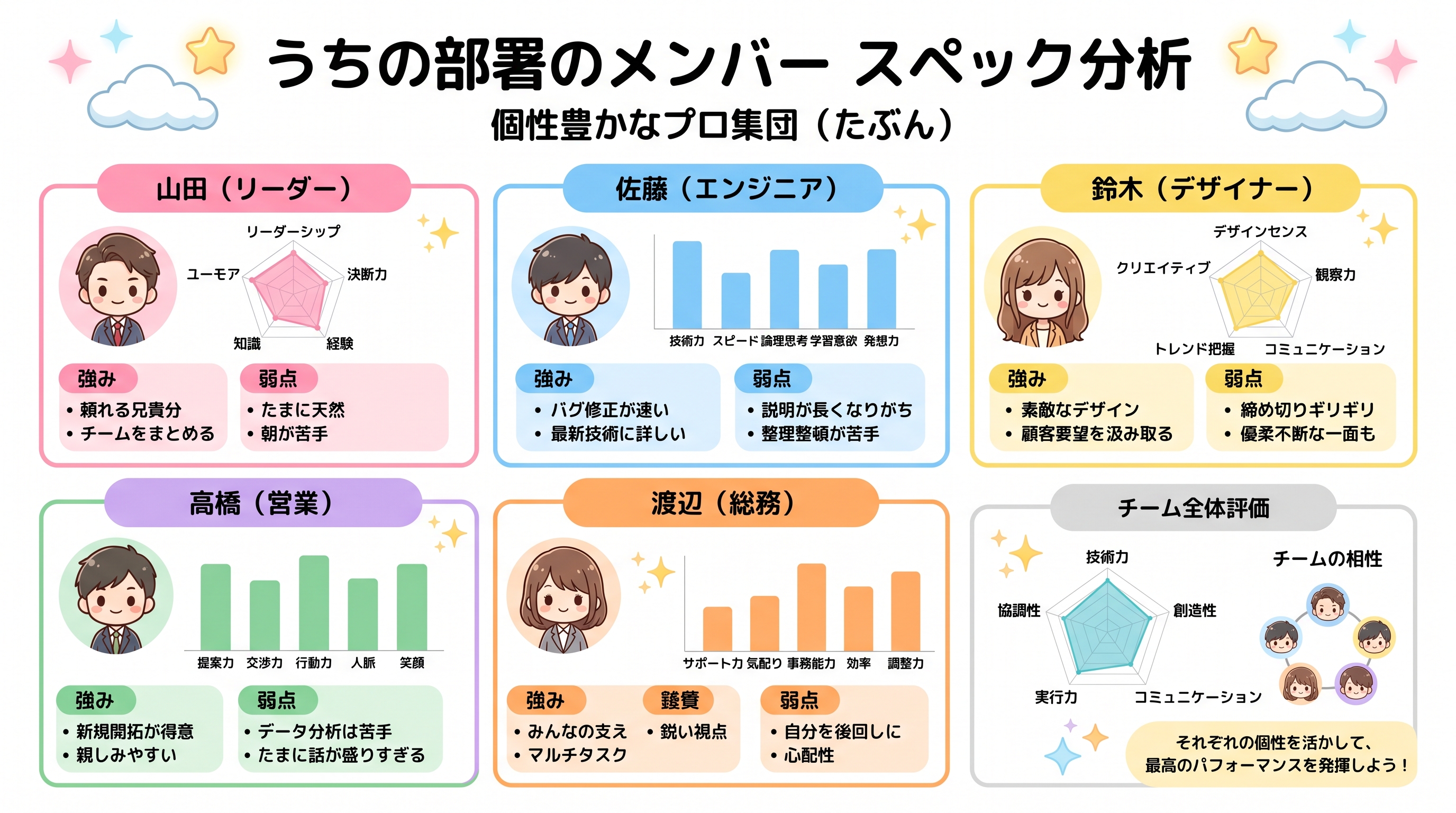
Nano Banana 2
Co możesz zrobić za pomocą GPT Image 2 API
Od kreacji reklamowych i wizualizacji produktów po makiety UI, zlokalizowane treści i redakcyjne infografiki – sprawdź, co potrafi stworzyć GPT Image 2 API.
Profesjonalna Reklama i Marketing
Oczekuje się, że GPT Image 2 będzie szczególnie silny w automatyzacji marketingu – generując grafiki do mediów społecznościowych, kreacje reklamowe i nagłówki e-maili z dokładnym tekstem na dużą skalę. W połączeniu z MindStudio, dzięki niemal perfekcyjnemu przestrzeganiu promptów i ulepszonemu fotorealizmowi, celuje w gotowe do produkcji zasoby kampanii bez sesji zdjęciowych.
E-commerce i wizualizacja produktów
GPT Image 2 jest szeroko dyskutowany w kontekście wizualizacji produktów i treści społecznościowych, gdzie dokładność ma takie samo znaczenie jak jakość wizualna. Dreamina Poprawa spójności postaci i zachowania obrazu sprawia, że idealnie nadaje się do skalowania katalogów produktów, generowania obrazów lifestylowych i tworzenia spójnych zestawów wariantów.
Makiety UI i Projektowanie Produktu
Makiety interfejsu użytkownika (UI) i interfejsy aplikacji – z poprawnie napisanym tekstem na przyciskach i przejrzystą strukturą układu – należą do przypadków użycia, które wczesne osoby testujące szczególnie podkreślały. Zespoły produktowe i projektanci Dzine mogą używać GPT Image 2 do szybkich makiet koncepcyjnych, elementów wizualnych stron docelowych i materiałów do prezentacji.
Wizualizacja architektoniczna i wnętrz
Rendery architektoniczne i wnętrz z poprawioną głębią oraz realizmem materiałów należą do oczekiwanych mocnych stron GPT Image 2. Ulepszenia Dzine w zakresie fotorealizmu i kompozycji czynią go praktycznym narzędziem do prezentacji projektów i marketingu nieruchomości.
Wielojęzyczne i zlokalizowane treści
API GPT Image 2 renderuje dokładny tekst w języku chińskim, japońskim, koreańskim i innych systemach pisma, co pozwala na tworzenie szyldów, postów w mediach społecznościowych i materiałów reklamowych, które kiedyś wymagały ręcznego nakładania tekstu. Sprawia to, że lokalizowanie kampanii i tworzenie grafik dla konkretnych regionów na dużą skalę staje się praktyczne.
Publikacje, Redakcja i Infografiki
Interfejs GPT Image 2 API generuje okładki książek, ilustrowane artykuły, infografiki oraz edukacyjne materiały wizualne, w których czytelny tekst na obrazie jest absolutnym wymogiem. Dzięki precyzyjnej typografii i ustrukturyzowanemu generowaniu wykresów, diagramów oraz materiałów objaśniających, przekształca złożone informacje w wyraźne grafiki, którymi łatwo się dzielić.
Porównanie Modeli
Zobacz, jak wypadają modele różnych dostawców — porównaj wydajność, ceny i unikalne mocne strony, aby podjąć świadomą decyzję.
| Model | Limit obrazów referencyjnych | Liczba danych wyjściowych | Rozdzielczość | Proporcje obrazu |
|---|---|---|---|---|
| GPT Image-2 | 16 | 1-10 | Up to 2048×2048 (2K) native;4K via scaling | 1:1, 2:3, 3:2 |
| GPT Image-1.5 | 10 | 1 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| GPT Image-1 | 4 | 1~10 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| GPT Image-1 Mini | 4 | 1~10 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| Nano Banana 2 | 14 | 1 | 512×512, 1024×1024, 2048×2048, 4096×4096 (0.5K/1K/2K/4K) | 1:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9, 1:4, 4:1, 1:8, 8:1 |
| Grok Imagine | 1 | 1-10 | 1024×1024 (1K), 2048×2048 (2K) | 1:1, 3:2, 2:3, 16:9, 9:16 |
Jak używać GPT Image 2 na Atlas Cloud
Zacznij w kilka minut — wykonaj te proste kroki, aby zintegrować i wdrożyć modele za pośrednictwem platformy Atlas Cloud.
Utwórz konto Atlas Cloud
Zarejestruj się na atlascloud.ai i ukończ weryfikację. Nowi użytkownicy otrzymują bezpłatne kredyty do eksploracji platformy i testowania modeli.
Dlaczego Używać GPT Image 2 na Atlas Cloud
Połączenie zaawansowanych modeli GPT Image 2 z platformą GPU-akcelerowaną Atlas Cloud zapewnia niezrównaną wydajność, skalowalność i doświadczenie deweloperskie.
Wydajność i Elastyczność
Niska Latencja:
Inferencja zoptymalizowana pod GPU dla rozumowania w czasie rzeczywistym.
Zunifikowane API:
Uruchamiaj GPT Image 2, GPT, Gemini i DeepSeek za pomocą jednej integracji.
Przejrzysta Wycena:
Przewidywalne rozliczenia za token z opcjami serverless.
Przedsiębiorstwo i Skala
Doświadczenie Dewelopera:
SDK, analityka, narzędzia dostrajania i szablony.
Niezawodność:
99,99% dostępności, RBAC i logowanie gotowe na zgodność.
Bezpieczeństwo i Zgodność:
SOC 2 Type II, zgodność z HIPAA, suwerenność danych w USA.
Często zadawane pytania (FAQ) użytkowników dotyczące GPT Image 2 API
API GPT Image 2 zapewnia programistom programatyczny dostęp do modelu GPT Image 2 od OpenAI, modelu obrazu wydanego w kwietniu 2026 roku jako następca GPT Image 1.5 i zamiennik dla DALL-E 3. Generuje i edytuje obrazy na podstawie danych wejściowych w postaci tekstu i obrazu, oferując dokładny tekst na obrazie, obsługę wielu języków i silny fotorealizm. W Atlas Cloud można go wywołać za pomocą jednego, ujednoliconego API wraz z ponad 300 innymi modelami.
Tak. API GPT Image 2 obsługuje zarówno generowanie obrazu z tekstu, jak i edycję obrazu w ramach jednego modelu. Edycja obejmuje precyzyjne inpainting i outpainting przy użyciu masek, a także kompozycję wieloreferencyjną, która łączy kilka danych wejściowych w jeden spójny rezultat.
Nie. GPT Image 2 jest następcą GPT Image 1.5, a nie DALL-E. OpenAI całkowicie odchodzi od marki DALL-E — zarówno DALL-E 2, jak i DALL-E 3 zostaną wyłączone 12 maja 2026 r. Rodzina GPT Image wykorzystuje architekturę autoregresyjną wbudowaną natywnie w model językowy, co zasadniczo różni się od podejścia opartego na dyfuzji, które stosowało DALL-E.
Tak. GPT Image 2 API obsługuje zarówno generowanie obrazu z tekstu, jak i edycję obrazu w jednym modelu. Edycja obejmuje precyzyjne inpainting i outpainting za pomocą masek, a także komponowanie z wieloma referencjami, które łączy kilka wejść w jeden spójny wynik.
Tak. API GPT Image 2 renderuje tekst w systemach pisma łacińskiego i CJK (chiński, japoński, koreański), w tym chińskim, japońskim i koreańskim, z dokładnymi glifami i wyraźnymi pociągnięciami. Pozwala to na tworzenie zlokalizowanych oznakowań, postów w mediach społecznościowych i materiałów firmowych, które wcześniej wymagały ręcznego nakładania tekstu.
Interfejs API GPT Image 2 obsługuje elastyczne rozmiary obrazów i proporcje, z natywną rozdzielczością wyjściową do 2K i 4K dostępną poprzez skalowanie. Możesz zażądać wstępnie zdefiniowanych rozmiarów lub niestandardowych wymiarów, aby dopasować je do postów w mediach społecznościowych, banerów i materiałów gotowych do druku.
Nie. OpenAI ogranicza rodzinę GPT Image wymogiem weryfikacji organizacji we własnej konsoli programisty, co może blokować indywidualnych deweloperów. Dzięki API GPT Image 2 w Atlas Cloud potrzebujesz tylko konta Atlas Cloud, aby uzyskać klucz i rozpocząć generowanie bez weryfikacji OpenAI.
OpenAI rozlicza GPT Image 2 za token, dlatego koszt pojedynczego obrazu zmienia się wraz z rozdzielczością, jakością oraz obrazami referencyjnymi i jest trudny do przewidzenia. W Atlas Cloud API GPT Image 2 stosuje zryczałtowane ceny za obraz: generowanie obrazu z tekstu (text to image) zaczyna się od 0,009 USD za obraz, a edycja od 0,01 USD za obraz, spadając do 0,004 USD i 0,005 USD w planie dla programistów (developer tier). Nowi użytkownicy otrzymują również darmowe kredyty na testowanie przed poniesieniem kosztów.
Poznaj Więcej Rodzin
Seedance 2.0
API Seedance 2.0 zapewnia produkcyjny dostęp do multimodalnego modelu wideo ByteDance — czteromodalne dane wejściowe (tekst, obraz, wideo, dźwięk) oraz wiodący w branży system „Universal Reference”, który blokuje kompozycję, ruchy kamery i działania postaci w różnych ujęciach. Zintegruj kontrolę na poziomie reżysera za pomocą jednego wywołania API, stałej stawki 0,09 USD/s, natychmiastowego klucza i braku listy oczekujących — wszystko to przy wsparciu czasu sprawności i zgodności klasy korporacyjnej. Seedance 2.0 Native 4K jest już dostępne!
Grok Imagine
Grok Imagine API zapewnia programistom możliwość generowania obrazów, wideo i dźwięku od xAI w jednym pakiecie. Tworzy obrazy w rozdzielczości do 2K z wielojęzycznym renderowaniem tekstu, a także filmy do 15 sekund z natywnym, zsynchronizowanym dźwiękiem i edycją opartą na referencjach. W Atlas Cloud jeden klucz uruchamia każdy tryb Grok Imagine, dzięki czemu można przełączać się między obrazem, wideo i dźwiękiem bez osobnych konfiguracji, już od 0,02 USD za obraz i 0,05 USD za sekundę.
Gemini Omni Flash
Gemini Omni API wprowadza do Twojego stacku multimodalny model generowania i edycji wideo od Google DeepMind, zaprezentowany na Google I/O 2026. Gemini Omni łączy silnik rozumowania Gemini z mediami generatywnymi, przyjmując dowolną kombinację tekstu, obrazów, wideo i dźwięku, aby tworzyć spójne, oparte na wiedzy wyniki. Dopracowuj rezultaty w naturalnej rozmowie — podmieniaj obiekty, przepisuj sceny i zmieniaj style, podczas gdy fizyka, postacie i ciągłość pozostają nienaruszone. Atlas Cloud udostępnia pełną gamę Gemini Omni Flash — tekst na wideo, obraz na wideo z maksymalnie 7 obrazami referencyjnymi oraz referencję na wideo — poprzez jedno ujednolicone API z przejrzystym rozliczaniem za sekundę już od $0.112 i bez subskrypcji. Zacznij tworzyć już dziś.
GPT Image 2
API GPT Image 2 daje programistom dostęp do najnowszego modelu obrazów firmy OpenAI, następcy GPT Image 1.5. Generuje i edytuje on obrazy z dokładnym renderowaniem tekstu w skryptach łacińskich i CJK, a także zapewnia silną kompozycję dla plakatów, makiet i infografik. W Atlas Cloud można uzyskać do niego dostęp za pośrednictwem jednego zunifikowanego API wraz z ponad 300 modelami, z darmowymi kredytami, gwarantowanym czasem pracy (uptime) na poziomie 99,99% i bez wymogu weryfikacji organizacji OpenAI.
Najpotężniejsze modele kreatywne Google są w pełni dostępne na platformie Atlas Cloud. Veo 3.1 zapewnia kinową generację wideo, Nano Banana 2 umożliwia tworzenie obrazów o wysokiej wierności, a Gemini wprowadza wielomodalną inteligencję do każdego przepływu pracy. Uzyskaj dostęp do pełnego pakietu modeli Google za pomocą jednego klucza API key z dostępnością Day-0 i cennikiem pay-as-you-go.
Seedance 2.0 Mini
Seedance 2.0 Mini wprowadza multimodalne generowanie wideo firmy ByteDance do przepływów pracy, w których szybkość i koszty mają największe znaczenie. Zapewnia podstawowe możliwości Seedance 2.0 przy mniejszym zużyciu zasobów — szybsze generowanie, niższy koszt na wideo i tę samą integrację API, z której już korzystasz. Dla zespołów obsługujących potoki o dużej objętości lub tworzących prototypy na dużą skalę, Mini jest praktycznym wyborem domyślnym.
ByteDance
Od generowania kinowych filmów po tworzenie obrazów o wysokiej wierności, najpotężniejsze modele ByteDance są dostępne w Atlas Cloud. Uruchamiaj Seedance i Seedream na dużą skalę z najniższymi cenami wnioskowania i zerowymi kosztami ogólnymi infrastruktury.
Alibaba
Atlas Cloud łączy pełną gamę modeli Alibaba w ramach jednego API: Qwen do zadań związanych z językiem i obrazem oraz Wan do generowania wideo w rozdzielczości do 1080p. Uzyskaj dostęp do każdego modelu w modelu płatności zgodnie z rzeczywistym użyciem (pay-as-you-go) bez subskrypcji. Alibaba API jest dostępne poprzez pojedynczy bazowy adres URL (base URL) przy użyciu istniejącego klienta kompatybilnego z OpenAI.
OpenAI
Atlas Cloud zapewnia dostęp do pełnej linii API OpenAI, od GPT Image 2 do generowania obrazów po Sora 2 do wideo. Każdy model jest dostępny w modelu płatności za użycie (pay-as-you-go) bez miesięcznych zobowiązań. Zintegruj się za pomocą jednej zmiany bazowego adresu URL, korzystając z API kompatybilnego z OpenAI.
xAI
Zbuduj kompletne potoki przetwarzania obrazów i wideo za pomocą xAI API w Atlas Cloud. Generuj w rozdzielczości 2K, edytuj za pomocą obrazów referencyjnych i animuj obrazy w klipy zsynchronizowane z dźwiękiem.
Kwaivgi
API Kwaivgi o 15% poniżej standardowej ceny. Atlas Cloud zapewnia dostęp od pierwszego dnia (Day-0) do nowych wydań Kling z modelem płatności zgodnie z użyciem (pay-as-you-go) i bez limitów stanowisk. Jedno konto, jeden klucz, każdy model Kling od poziomu standardowego po poziom master.
Seedream 5.0 Pro
Seedream 5.0 Pro API udostępnia programistom sterowalny model edycji obrazów firmy ByteDance w Atlas Cloud. Precyzyjnie rozmieszcza edycje za pomocą kotwic i współrzędnych, dzieli obrazy na edytowalne warstwy, łączy wiele odniesień oraz dopasowuje dokładne kolory i materiały, z wielojęzycznym tekstem w rozdzielczościach 2K i 3K. W Atlas Cloud można uzyskać do niego dostęp za pomocą jednego klucza!


