Gemini Omni Flash API for Conversational Video Editing
Gemini Omni API wprowadza do Twojego stacku multimodalny model generowania i edycji wideo od Google DeepMind, zaprezentowany na Google I/O 2026. Gemini Omni łączy silnik rozumowania Gemini z mediami generatywnymi, przyjmując dowolną kombinację tekstu, obrazów, wideo i dźwięku, aby tworzyć spójne, oparte na wiedzy wyniki. Dopracowuj rezultaty w naturalnej rozmowie — podmieniaj obiekty, przepisuj sceny i zmieniaj style, podczas gdy fizyka, postacie i ciągłość pozostają nienaruszone. Atlas Cloud udostępnia pełną gamę Gemini Omni Flash — tekst na wideo, obraz na wideo z maksymalnie 7 obrazami referencyjnymi oraz referencję na wideo — poprzez jedno ujednolicone API z przejrzystym rozliczaniem za sekundę już od $0.112 i bez subskrypcji. Zacznij tworzyć już dziś.
Poznaj Wiodące Modele
Atlas Cloud zapewnia najnowsze, wiodące w branży modele kreatywne.







Cztery sposoby generowania za pomocą Gemini Omni Flash API
Wybierz punkt końcowy API Gemini Omni Flash odpowiedni do danego zadania, od generowania wideo z tekstu i obrazu, po generowanie oparte na referencjach i edycję konwersacyjną.
| Modalność | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | Masz tylko prompt tekstowy? Gemini Omni Flash Text-to-Video API przekształca go w klip 720p z zsynchronizowanym dźwiękiem w jednym przejściu, podążając za opartym na wnioskowaniu kierowaniem sceną, ruchem i kamerą dla klipów o długości do 10 sekund. |
| Gemini Omni Flash Image-to-Video API (I2V) | API Image-to-Video Gemini Omni Flash animuje nieruchomy obraz, wprawiając go w ruch i osadzając źródło jako klatkę początkową. Dzięki naturalnym ruchom i zsynchronizowanemu dźwiękowi ożywia zdjęcia produktów, portrety i koncepcje w rozdzielczości 720p. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Kieruj procesem generacji za pomocą maksymalnie siedmiu obrazów referencyjnych i trzech krótkich klipów wideo, korzystając z Gemini Omni Flash Reference-to-Video API. Utrzymuje spójność postaci, stylu i sceny w całym klipie, co czyni ją idealną do tworzenia treści markowych i seryjnych. |
| Gemini Omni Flash Video Edit API | Gdy klip wymaga zmian, Gemini Omni Flash Video Edit API stosuje instrukcje w języku naturalnym za pośrednictwem stanowego Interactions API. Zamienia elementy, dostosowuje oświetlenie i zmienia styl scen, zachowując nienaruszoną resztę materiału filmowego w trakcie kolejnych tur interakcji. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
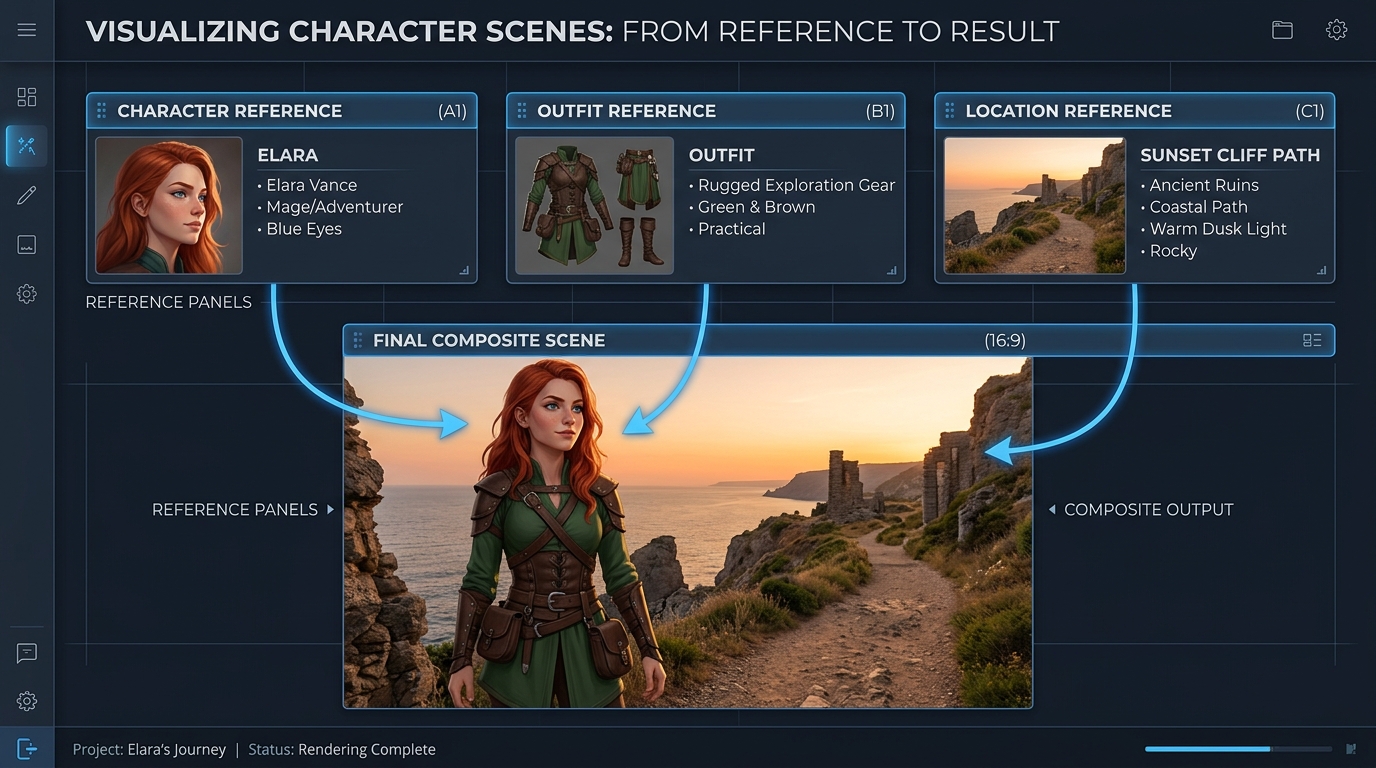
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Jak wypada Gemini Omni Flash API w porównaniu
Zobacz, jak wypadają modele różnych dostawców — porównaj wydajność, ceny i unikalne mocne strony, aby podjąć świadomą decyzję.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Edycja gotowego wideo poprzez konwersację | Yes | Tak, stanowy | Tekst, obraz, wideo, audio |
| Veo 3.1 | Klipy filmowe z rozszerzeniem sceny | Yes | No | Tekst, obraz, referencja |
| Seedance 2.0 | Wideo sterowane referencyjnie o najwyższej jakości | Yes | No | Tekst, obraz, wideo, audio |
| Kling 3.0 | Wieloujęciowa narracja w reżyserii AI | Yes | No | Tekst, obraz, referencja |
Jak używać Gemini Omni Flash na Atlas Cloud
Zacznij w kilka minut — wykonaj te proste kroki, aby zintegrować i wdrożyć modele za pośrednictwem platformy Atlas Cloud.
Utwórz konto Atlas Cloud
Zarejestruj się na atlascloud.ai i ukończ weryfikację. Nowi użytkownicy otrzymują bezpłatne kredyty do eksploracji platformy i testowania modeli.
Dlaczego Używać Gemini Omni Flash na Atlas Cloud
Połączenie zaawansowanych modeli Gemini Omni Flash z platformą GPU-akcelerowaną Atlas Cloud zapewnia niezrównaną wydajność, skalowalność i doświadczenie deweloperskie.
Wydajność i Elastyczność
Niska Latencja:
Inferencja zoptymalizowana pod GPU dla rozumowania w czasie rzeczywistym.
Zunifikowane API:
Uruchamiaj Gemini Omni Flash, GPT, Gemini i DeepSeek za pomocą jednej integracji.
Przejrzysta Wycena:
Przewidywalne rozliczenia za token z opcjami serverless.
Przedsiębiorstwo i Skala
Doświadczenie Dewelopera:
SDK, analityka, narzędzia dostrajania i szablony.
Niezawodność:
99,99% dostępności, RBAC i logowanie gotowe na zgodność.
Bezpieczeństwo i Zgodność:
SOC 2 Type II, zgodność z HIPAA, suwerenność danych w USA.
FAQ dotyczące Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Poznaj Więcej Rodzin
Seedance 2.0
API Seedance 2.0 zapewnia produkcyjny dostęp do multimodalnego modelu wideo ByteDance — czteromodalne dane wejściowe (tekst, obraz, wideo, dźwięk) oraz wiodący w branży system „Universal Reference”, który blokuje kompozycję, ruchy kamery i działania postaci w różnych ujęciach. Zintegruj kontrolę na poziomie reżysera za pomocą jednego wywołania API, stałej stawki 0,09 USD/s, natychmiastowego klucza i braku listy oczekujących — wszystko to przy wsparciu czasu sprawności i zgodności klasy korporacyjnej. Seedance 2.0 Native 4K jest już dostępne!
Grok Imagine
Grok Imagine API zapewnia programistom możliwość generowania obrazów, wideo i dźwięku od xAI w jednym pakiecie. Tworzy obrazy w rozdzielczości do 2K z wielojęzycznym renderowaniem tekstu, a także filmy do 15 sekund z natywnym, zsynchronizowanym dźwiękiem i edycją opartą na referencjach. W Atlas Cloud jeden klucz uruchamia każdy tryb Grok Imagine, dzięki czemu można przełączać się między obrazem, wideo i dźwiękiem bez osobnych konfiguracji, już od 0,02 USD za obraz i 0,05 USD za sekundę.
Gemini Omni Flash
Gemini Omni API wprowadza do Twojego stacku multimodalny model generowania i edycji wideo od Google DeepMind, zaprezentowany na Google I/O 2026. Gemini Omni łączy silnik rozumowania Gemini z mediami generatywnymi, przyjmując dowolną kombinację tekstu, obrazów, wideo i dźwięku, aby tworzyć spójne, oparte na wiedzy wyniki. Dopracowuj rezultaty w naturalnej rozmowie — podmieniaj obiekty, przepisuj sceny i zmieniaj style, podczas gdy fizyka, postacie i ciągłość pozostają nienaruszone. Atlas Cloud udostępnia pełną gamę Gemini Omni Flash — tekst na wideo, obraz na wideo z maksymalnie 7 obrazami referencyjnymi oraz referencję na wideo — poprzez jedno ujednolicone API z przejrzystym rozliczaniem za sekundę już od $0.112 i bez subskrypcji. Zacznij tworzyć już dziś.
GPT Image 2
API GPT Image 2 daje programistom dostęp do najnowszego modelu obrazów firmy OpenAI, następcy GPT Image 1.5. Generuje i edytuje on obrazy z dokładnym renderowaniem tekstu w skryptach łacińskich i CJK, a także zapewnia silną kompozycję dla plakatów, makiet i infografik. W Atlas Cloud można uzyskać do niego dostęp za pośrednictwem jednego zunifikowanego API wraz z ponad 300 modelami, z darmowymi kredytami, gwarantowanym czasem pracy (uptime) na poziomie 99,99% i bez wymogu weryfikacji organizacji OpenAI.
Najpotężniejsze modele kreatywne Google są w pełni dostępne na platformie Atlas Cloud. Veo 3.1 zapewnia kinową generację wideo, Nano Banana 2 umożliwia tworzenie obrazów o wysokiej wierności, a Gemini wprowadza wielomodalną inteligencję do każdego przepływu pracy. Uzyskaj dostęp do pełnego pakietu modeli Google za pomocą jednego klucza API key z dostępnością Day-0 i cennikiem pay-as-you-go.
Seedance 2.0 Mini
Seedance 2.0 Mini wprowadza multimodalne generowanie wideo firmy ByteDance do przepływów pracy, w których szybkość i koszty mają największe znaczenie. Zapewnia podstawowe możliwości Seedance 2.0 przy mniejszym zużyciu zasobów — szybsze generowanie, niższy koszt na wideo i tę samą integrację API, z której już korzystasz. Dla zespołów obsługujących potoki o dużej objętości lub tworzących prototypy na dużą skalę, Mini jest praktycznym wyborem domyślnym.
ByteDance
Od generowania kinowych filmów po tworzenie obrazów o wysokiej wierności, najpotężniejsze modele ByteDance są dostępne w Atlas Cloud. Uruchamiaj Seedance i Seedream na dużą skalę z najniższymi cenami wnioskowania i zerowymi kosztami ogólnymi infrastruktury.
Alibaba
Atlas Cloud łączy pełną gamę modeli Alibaba w ramach jednego API: Qwen do zadań związanych z językiem i obrazem oraz Wan do generowania wideo w rozdzielczości do 1080p. Uzyskaj dostęp do każdego modelu w modelu płatności zgodnie z rzeczywistym użyciem (pay-as-you-go) bez subskrypcji. Alibaba API jest dostępne poprzez pojedynczy bazowy adres URL (base URL) przy użyciu istniejącego klienta kompatybilnego z OpenAI.
OpenAI
Atlas Cloud zapewnia dostęp do pełnej linii API OpenAI, od GPT Image 2 do generowania obrazów po Sora 2 do wideo. Każdy model jest dostępny w modelu płatności za użycie (pay-as-you-go) bez miesięcznych zobowiązań. Zintegruj się za pomocą jednej zmiany bazowego adresu URL, korzystając z API kompatybilnego z OpenAI.
xAI
Zbuduj kompletne potoki przetwarzania obrazów i wideo za pomocą xAI API w Atlas Cloud. Generuj w rozdzielczości 2K, edytuj za pomocą obrazów referencyjnych i animuj obrazy w klipy zsynchronizowane z dźwiękiem.
Kwaivgi
API Kwaivgi o 15% poniżej standardowej ceny. Atlas Cloud zapewnia dostęp od pierwszego dnia (Day-0) do nowych wydań Kling z modelem płatności zgodnie z użyciem (pay-as-you-go) i bez limitów stanowisk. Jedno konto, jeden klucz, każdy model Kling od poziomu standardowego po poziom master.
Seedream 5.0 Pro
Seedream 5.0 Pro API udostępnia programistom sterowalny model edycji obrazów firmy ByteDance w Atlas Cloud. Precyzyjnie rozmieszcza edycje za pomocą kotwic i współrzędnych, dzieli obrazy na edytowalne warstwy, łączy wiele odniesień oraz dopasowuje dokładne kolory i materiały, z wielojęzycznym tekstem w rozdzielczościach 2K i 3K. W Atlas Cloud można uzyskać do niego dostęp za pomocą jednego klucza!


