
ChatGPT API for Frontier GPT 5.6 Reasoning
ChatGPT API บน Atlas Cloud นำตระกูล GPT 5.6 รุ่นล่าสุดของ OpenAI มารวมไว้ในการผสานรวมเดียว ครอบคลุม Sol สำหรับการให้เหตุผลเชิงลึกระดับ frontier, Terra สำหรับเวิร์กโหลดโปรดักชันที่ยึดโยงกับข้อเท็จจริง และ Luna สำหรับการสนทนาอย่างเป็นธรรมชาติและการสร้างคอนเทนต์ เรียกใช้ทุกโมเดลผ่านคีย์เดียวที่เข้ากันได้กับ OpenAI มั่นใจได้กับ uptime ระดับโปรดักชัน และจ่ายในอัตรา pay-as-you-go ที่โปร่งใส เริ่มต้นที่ $1 ต่อหนึ่งล้าน input tokens เริ่มสร้างได้วันนี้
สำรวจโมเดลชั้นนำ
Atlas Cloud มอบโมเดลสร้างสรรค์ล่าสุดที่นำหน้าในอุตสาหกรรมให้กับคุณ
เลือกโมเดล ChatGPT API ที่เหมาะสม: เปรียบเทียบทุก Endpoint
Endpoint สำหรับการสร้างข้อความ 5 รายการ ครอบคลุมตั้งแต่การใช้เหตุผลระดับแนวหน้าไปจนถึงการสนทนาราคาประหยัด ทั้งหมดให้บริการผ่านคีย์เดียวที่เข้ากันได้กับ OpenAI พร้อมราคาจ่ายตามการใช้งานที่โปร่งใส
| รูปแบบข้อมูล | คำอธิบาย |
|---|---|
| GPT 5.6 Sol API (ข้อความเป็นข้อความ) | สร้างมาเพื่อเวิร์กโหลด AI ระดับแนวหน้า GPT 5.6 Sol เปลี่ยนพรอมป์ข้อความที่ซับซ้อนให้เป็นผลลัพธ์การให้เหตุผลเชิงลึกหลายขั้นตอน สำหรับการแก้ปัญหาที่ท้าทาย ราคามาตรฐานอยู่ที่ $5 ต่อโทเคนอินพุต 1 ล้านโทเคน และ $30 ต่อโทเคนเอาต์พุต 1 ล้านโทเคน ทำให้เป็นตัวเลือกระดับเรือธงเมื่อคุณภาพของคำตอบสำคัญกว่าต้นทุน |
| GPT 5.6 Terra API (ข้อความเป็นข้อความ) | ต้องการค่าเริ่มต้นสำหรับโปรดักชันที่วางใจได้ใช่ไหม? GPT 5.6 Terra แปลงพรอมป์ให้เป็นข้อความที่ยึดโยงกับบริบท ใช้งานได้จริง สำหรับเวิร์กโฟลว์และไปป์ไลน์การวิเคราะห์ในโลกจริง ที่ราคา $2.50 สำหรับอินพุต และ $15 สำหรับเอาต์พุตต่อ 1 ล้านโทเคน ทีมต่าง ๆ นำไปใช้ในแอปพลิเคชันที่พบลูกค้าโดยตรง ซึ่งความสม่ำเสมอสำคัญกว่าความลึกเชิงทดลอง |
| GPT 5.6 Luna API (ข้อความเป็นข้อความ) | ส่งทราฟฟิกด้านการสนทนาและงานสร้างสรรค์ไปยัง GPT 5.6 Luna โมเดลข้อความที่ปรับแต่งมาเพื่อบทสนทนาที่เป็นธรรมชาติ การสร้างคอนเทนต์ และประสบการณ์ AI แบบเฉพาะบุคคล ด้วยราคา $1 สำหรับอินพุต และ $6 สำหรับเอาต์พุตต่อ 1 ล้านโทเคน จึงเป็นจุดเริ่มต้นที่คุ้มค่าที่สุดในชุด ChatGPT API นี้ เหมาะอย่างยิ่งสำหรับผลิตภัณฑ์แชตและการสร้างข้อความโฆษณาปริมาณมาก |
| GPT 5.4 API (ข้อความเป็นข้อความ) | GPT 5.4 ประมวลผลคำสั่งข้อความให้เป็นโค้ดที่เชื่อถือได้ คอนเทนต์ขนาดยาว และผลลัพธ์การแก้ปัญหาแบบมีโครงสร้างพร้อมความแม่นยำสูง ด้วยการออกแบบให้เป็นโมเดลมัลติโหมดขั้นสูง จึงอยู่ในระดับราคากลางที่ $2.50 สำหรับอินพุต และ $15 สำหรับเอาต์พุตต่อ 1 ล้านโทเคน เหมาะสำหรับผู้ช่วยเขียนโค้ดและแพลตฟอร์มคอนเทนต์ |
| GPT 5.5 API (ข้อความเป็นข้อความ) | เมื่อปัญหายากคุ้มค่ากับค่าใช้จ่ายระดับพรีเมียม GPT 5.5 มอบความสามารถด้านการให้เหตุผลขั้นสูง การเขียนโค้ด และการสร้างคอนเทนต์จาก Endpoint ข้อความเดียว ราคาอยู่ที่ $5 สำหรับอินพุต และ $30 สำหรับเอาต์พุตต่อ 1 ล้านโทเคน มุ่งเป้าไปที่เวิร์กโหลดที่ซับซ้อนและต้องการความเชื่อถือได้สูง เช่น การประสานงานเอเจนต์และการวิเคราะห์เชิงเทคนิค |
ChatGPT API: ระดับ GPT 5.x และ Open Weights
เข้าถึง GPT 5.x ครบทั้งไลน์อัปและ GPT OSS 120B แบบ open-weight ผ่าน ChatGPT API เดียว ปรับ reasoning effort ได้ตั้งแต่ low ถึง xhigh รวมข้อความ รูปภาพ และไฟล์ในคำขอเดียว และเรียกใช้เครื่องมือเนทีฟพร้อม live web search ด้วยคีย์ที่รองรับ OpenAI เพียงคีย์เดียว
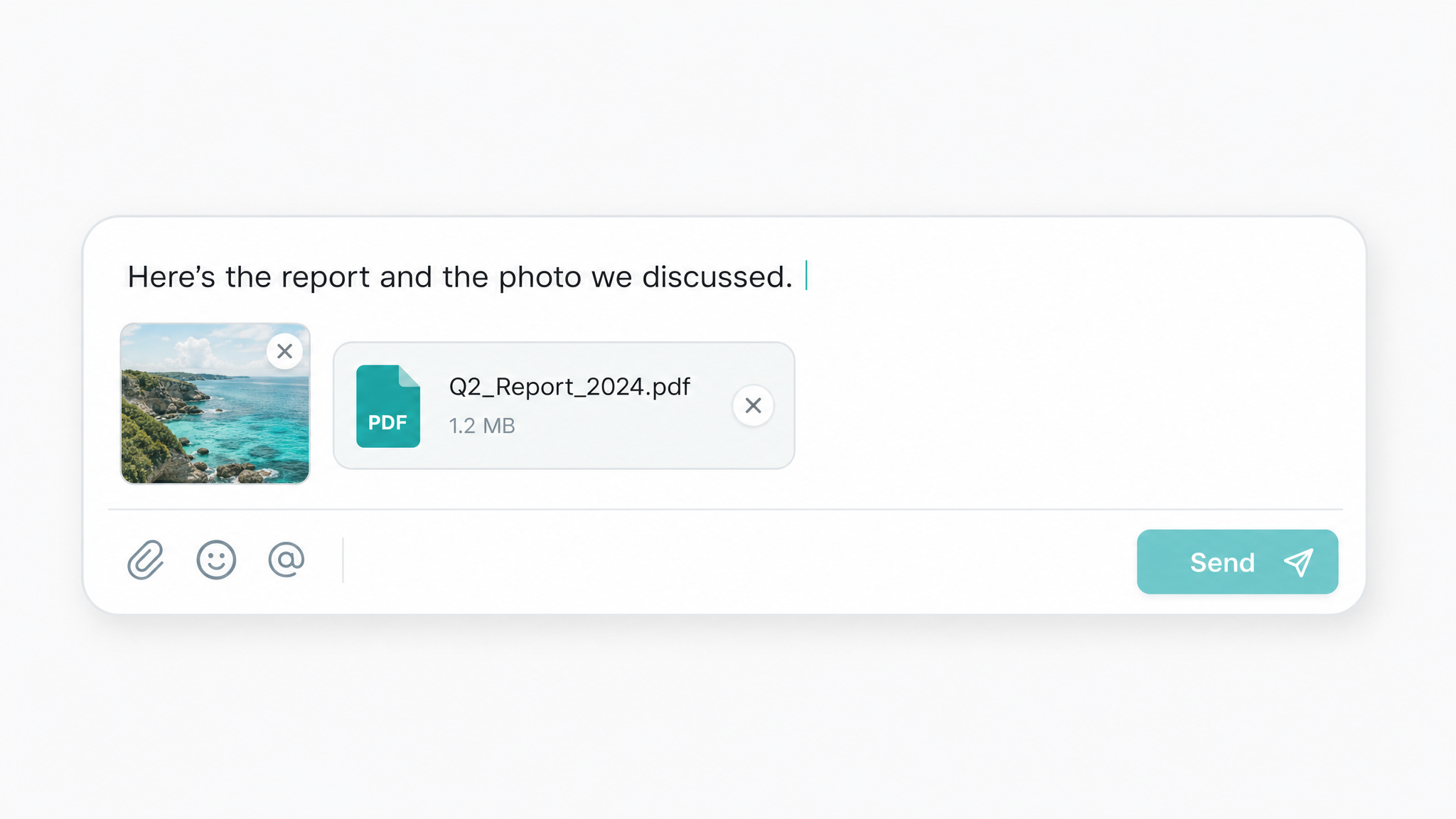
ข้อความ รูปภาพ และไฟล์ในคำขอ ChatGPT API ครั้งเดียว
คำขอ ChatGPT API เพียงครั้งเดียวสามารถรวมข้อความล้วน URL รูปภาพ และไฟล์เอกสารไว้ในข้อความเดียวได้ จึงไม่ต้องใช้บริการ OCR หรือ vision แยกต่างหาก ทำให้คุณสรุปสัญญาที่สแกนมา หรืออ่านภาพหน้าจอได้ในรอบเดียว
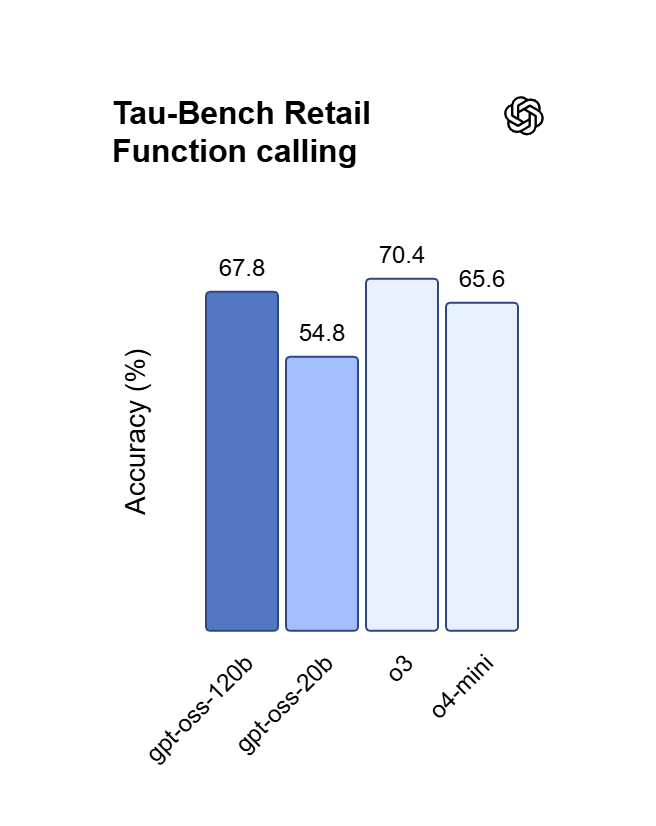
ความแม่นยำในการทำตามคำสั่งบน ChatGPT API
GPT OSS 120B ทำตาม system prompts แบบหลายชั้นได้อย่างเคร่งครัด รักษารูปแบบ ข้อจำกัด และโทนให้คงที่ในทุกผลลัพธ์โดยไม่เพี้ยน ความน่าเชื่อถือนี้เหมาะกับเอเจนต์อัตโนมัติ การสกัดข้อมูลแบบมีโครงสร้าง และไปป์ไลน์ production ที่ผลลัพธ์ต้องทำตามกฎ
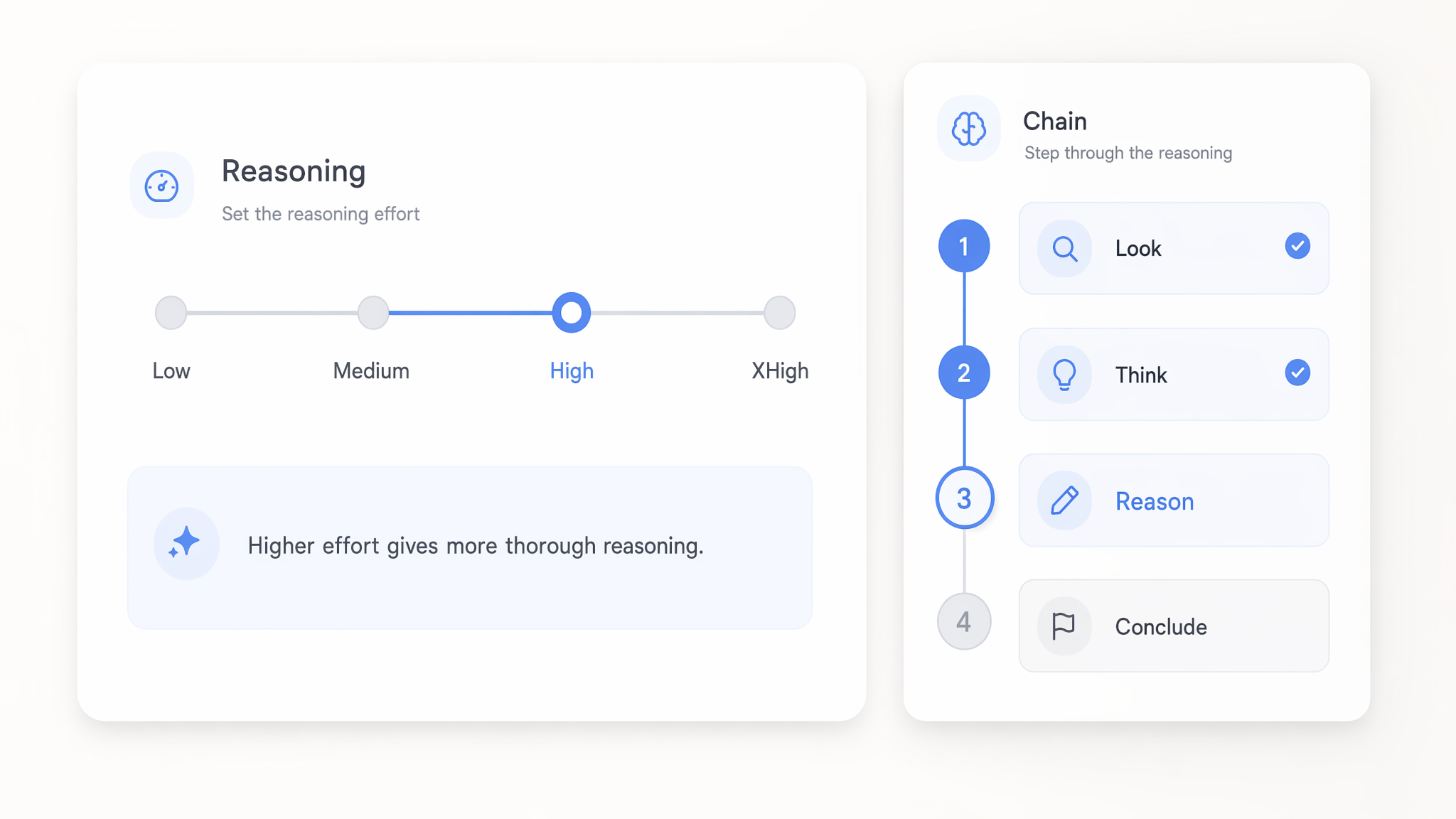
ปรับ reasoning effort ได้ตั้งแต่ low ถึง xhigh
ตั้งค่า reasoning effort ของโมเดล GPT 5.x ได้ตั้งแต่ low ไปจนถึง xhigh เพื่อควบคุมว่าก่อนตอบโมเดลจะคิดลึกแค่ไหน การตั้งค่า low ตอบคำขอเรียบง่ายได้เร็วและประหยัด ส่วน xhigh ใช้ทรัพยากรประมวลผลมากขึ้นกับตรรกะหลายขั้นตอนที่ยาก
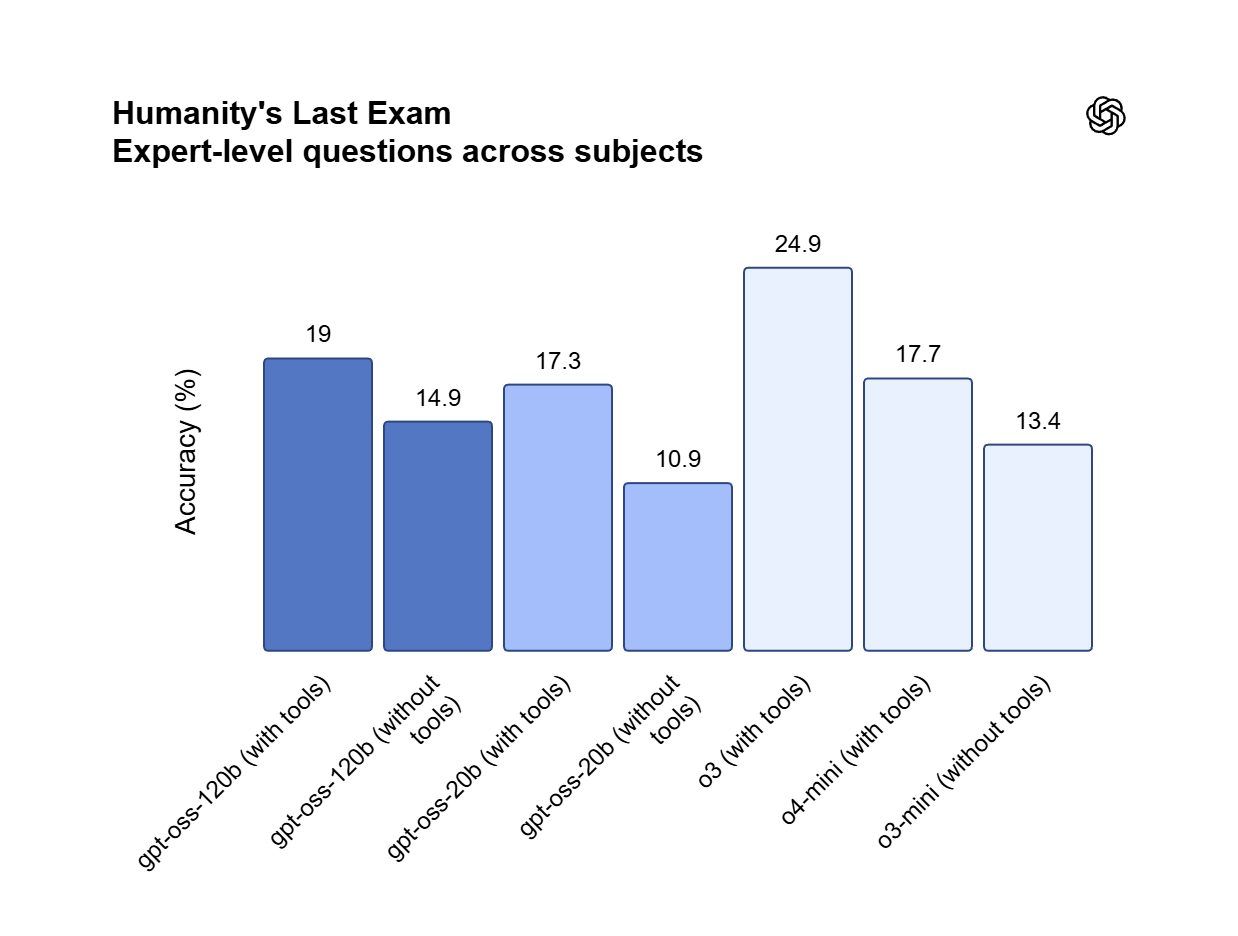
Weights ภายใต้ Apache 2.0 ที่คุณควบคุมได้เต็มที่
GPT OSS 120B เผยแพร่ภายใต้สัญญาอนุญาต Apache 2.0 จึงใช้เชิงพาณิชย์และทำ private fine-tuning บน GPU 80GB เพียงตัวเดียวได้ โฮสต์แบบ on-premises เพื่อเก็บข้อมูล proprietary ไว้ภายในองค์กร และหลีกเลี่ยงค่าธรรมเนียมแบบต่อ token ได้ทั้งหมด

GPT ห้าระดับใน ChatGPT API เดียว
ChatGPT API เดียวให้บริการ GPT 5.x ครบทั้งไลน์อัป โดยมีราคาตั้งแต่ Luna ที่ $1 ถึง Sol ที่ $5 ต่อ input tokens หนึ่งล้าน token จับคู่แต่ละคำขอกับระดับที่เหมาะกับต้นทุนและความฉลาดที่ต้องการ โดยไม่ต้องเปลี่ยน endpoint
การให้เหตุผลที่ปรับแต่งมาสำหรับ Vibecoding
ประสิทธิภาพที่ใกล้เคียง OpenAI o4-mini ทำให้ GPT OSS 120B จัดการการสังเคราะห์โค้ดหลายขั้นตอนและการพิสูจน์ทางคณิตศาสตร์ได้ เปลี่ยนไอเดียภาษาธรรมดาให้เป็นเว็บแอปที่ใช้งานได้จริง ดีบักตรรกะซ้อนกัน และประสานเวิร์กโฟลว์การจัดตารางงานที่ซับซ้อน

Function Calls พร้อม Live Web Search
โมเดล GPT 5.x รองรับ function calling พร้อมการเลือกเครื่องมืออัตโนมัติ รวมถึง web search ในตัวที่ดึงผลลัพธ์ล่าสุดได้ สตรีมคำตอบเป็น server-sent events ขณะที่ prompt caching ช่วยลด cached input ของ GPT 5.6 Sol เหลือ $0.5 ต่อหนึ่งล้าน tokens
หนึ่งพรอมต์ สามคู่แข่ง: ChatGPT API ประชันแบบ Head to Head
เราป้อนคำสั่งสร้างเดียวกันทุกประการให้โมเดลผ่าน ChatGPT API และเรือธงคู่แข่งอีกสองราย จากนั้นเรนเดอร์คำตอบ HTML ดิบทั้งหมดโดยไม่แก้ไข เพื่อให้คุณตัดสินความลึกของการให้เหตุผล คุณภาพโค้ด และรสนิยมด้านดีไซน์ได้แบบเทียบกันข้างต่อข้าง
สร้างไฟล์ HTML แบบ single self-contained หนึ่งไฟล์ (ใช้เฉพาะ inline CSS และ JavaScript — ห้ามใช้ไลบรารีภายนอก, CDNs, frameworks, fonts หรือ image URLs โดยเด็ดขาด) ที่เปิดได้โดยตรงในเบราว์เซอร์สมัยใหม่ใดก็ได้ และรันซิมูเลเตอร์ระบบนิเวศเรือนกระจกแก้วที่มีชีวิตและเติบโตต่อเนื่องด้วยตัวเอง โดยเรนเดอร์ทั้งหมดเป็นภาพประกอบเวกเตอร์แบบแบนบน Canvas/SVG ฉากเต็ม viewport คือเรือนกระจกวิกตอเรียทรงโดม: โดมกระจกโค้งพาดผ่านด้านบนเป็นองค์ประกอบกรอบภาพ บานกระจกวาดเป็นโพลิกอนโปร่งแสงสีเขียวหยก พร้อมไฮไลต์เงาวาวนุ่ม ๆ และเส้นกรอบ muntin บาง ๆ ส่วนด้านล่างมีแถบดินเพาะปลูกสีเข้ม แนวทางศิลป์คือภาพประกอบเวกเตอร์สะอาดตา — ใบและลำต้นวาดด้วยเส้นลายเส้นใบที่คมชัดร่วมกับชั้นสีเติมแบบกึ่งโปร่งแสง ใช้พาเลตที่ตั้งอยู่บนเขียวเซจหมอก ๆ และน้ำตาลมอส พร้อมแสงอาทิตย์สีอำพันและจุดเน้นกระจกหยก; ห้ามทำ photorealism, ห้ามใช้ gradient-as-textures, คงความเป็นกราฟิกและให้ความรู้สึกเหมือนภาพวาดมือ ปฏิสัมพันธ์หลัก: เมื่อคลิกที่ใดก็ได้บนดิน ให้ปลูกเมล็ด ณ จุดนั้น และให้ต้นไม้เติบโตแบบ real time โดยใช้ L-system จริง — implement ไวยากรณ์แบบ recursive rewriting (มี axiom พร้อม production rules ที่ใช้ branching brackets และสุ่ม jitter ของมุม/ความยาวต่อแต่ละ instance เพื่อให้ไม่มีต้นไม้สองต้นเหมือนกัน) และ animate กระบวนการ derivation เพื่อให้กิ่งค่อย ๆ ยืด แยกแขนง และคลี่ใบออกอย่างต่อเนื่องภายในไม่กี่วินาที แทนที่จะโผล่มาเป็นรูปเต็มทันที เฟิร์นเขตร้อนและเถาวัลย์เลื้อยควรโค้งและม้วนเข้าหาดวงอาทิตย์ที่ลากได้ตามหลัก phototropism: เรนเดอร์แผ่นดวงอาทิตย์เรืองแสงสีอำพันที่ผู้ใช้จับลากไปที่ใดก็ได้บนท้องฟ้า และปลายยอดที่กำลังเติบโตทุกจุดต้องปรับทิศทางการเติบโตเข้าหาตำแหน่งปัจจุบันของดวงอาทิตย์อย่างต่อเนื่อง เพื่อให้เมื่อขยับดวงอาทิตย์แล้วเห็นได้ชัดว่าทั้งสวนเอนและไต่ไปตามทิศนั้น ต้นกล้าแผ่ใบด้วย easing animation และหยดน้ำควบแน่นก่อตัวบนกระจกแล้วค่อย ๆ ไหลลงวนซ้ำ ขับเคลื่อนทุกอย่างด้วยวงจรกลางวัน-กลางคืนที่ผูกกับตำแหน่งของดวงอาทิตย์: แสงแวดล้อมและสี wash ของท้องฟ้าเลื่อนอย่างนุ่มนวลไปตาม gradient จากทองอุ่นไปสู่น้ำเงินเย็น ตำแหน่งดวงอาทิตย์กำหนดทิศทางและความยาวของเงาต้นไม้นุ่ม ๆ ที่ทอดบนพื้น รวมถึงจุดแสงลอยบนกระจก และเมื่อพลบค่ำ หิ่งห้อยจะค่อย ๆ ปรากฏเป็นจุดแสงเล็ก ๆ เต้นเป็นจังหวะลอยอยู่ท่ามกลางใบไม้ องค์ประกอบภาพให้การเติบโตของพืชแผ่ออกจากฐานขึ้นสู่ศูนย์กลาง โดยถูกโอบไว้ด้วยส่วนโค้งของโดม ใช้ requestAnimationFrame สำหรับลูปแอนิเมชันต่อเนื่องที่หายใจเบา ๆ; รักษาประสิทธิภาพให้ลื่นไหลแม้มีต้นไม้จำนวนมากบนหน้าจอ ใส่ controls ที่ละเอียดและไม่รบกวน (เช่น slider หรือ toggle แบบ auto-advancing สำหรับเวลาของวัน และปุ่ม reset/clear) โดยจัดสไตล์ให้เข้ากับสุนทรียะของภาพประกอบ พร้อมคำใบ้บรรทัดเดียวบอกผู้ใช้ให้คลิกดินเพื่อปลูกและลากดวงอาทิตย์เพื่อชี้นำการเติบโต ทำให้ responsive กับทุกขนาดหน้าต่าง และให้โทนอารมณ์สงบ นิ่ง และมีชีวิต — แสงเช้าแรกสาดเฉียงเข้ามาขณะยอดอ่อนค่อย ๆ เปิดพร้อมกัน นี่คือ generative simulation ไม่ใช่เกมหรือ dashboard: ให้ความสำคัญกับอัลกอริทึมการเติบโตแบบ recursive ที่แท้จริง ลูปแอนิเมชัน และฟิสิกส์ของแสง/เงา/phototropism เป็นหลัก
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
สร้างหน้า HTML แบบ single-file ที่สมบูรณ์ ซึ่งมี dashboard เงินทุนสตาร์ทอัพระดับโลกแบบโต้ตอบ พร้อมข้อมูลสมมติที่สอดคล้องกันภายในสำหรับ 8 industry sectors ตลอด 5 ปี CSS และ JavaScript ทั้งหมดต้องเป็น inline โดยไม่มี external dependencies, ไม่มี chart libraries, ไม่มี CDNs, ไม่มีรูปภาพ เรนเดอร์ visualization ที่เขียนเอง 3 แบบบน canvas หรือ SVG: bar chart แบบ animated ที่ re-sort ด้วย easing เมื่อผู้ใช้เลือกปีจาก slider, line chart พร้อม hover tooltips ที่แสดงค่าที่แน่นอนและ vertical tracking guide, และ donut chart ที่ segment ขยายเมื่อ hover ด้วย spring animation ใส่ UI สมัยใหม่โทนมืดพร้อมพาเลต accent ม่วงถึง teal, number counters แบบ animated ใน KPI stat cards 4 ใบ, แถว sector filter เป็น toggle chips ที่อัปเดต chart ทั้งหมดทันที และ light/dark theme switch พร้อมการเปลี่ยนสีอย่างนุ่มนวล layout ต้อง responsive โดยยุบเป็นคอลัมน์เดียวเมื่อความกว้างต่ำกว่า 768px และทุก interaction ต้องตอบสนองแบบ real time โดยไม่ reload หน้า
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
ทุกเวิร์กโหลดที่ ChatGPT API ขับเคลื่อนได้
ตั้งแต่การเขียนโค้ดแบบ agentic และการสกัดข้อมูลแบบมีโครงสร้าง ไปจนถึงแชตซัพพอร์ตที่อ้างอิงข้อมูลจริงและคอนเทนต์ปริมาณมาก ChatGPT API บน Atlas Cloud จะกำหนดเส้นทางงานแต่ละงานไปยังระดับ GPT 5.6 ที่เหมาะสมผ่านคีย์เดียวที่เข้ากันได้กับ OpenAI

สร้างเครื่องมือเขียนโค้ดแบบ Agentic ด้วย ChatGPT API
ส่งงานรีแฟกเตอร์ที่ซับซ้อนและการสังเคราะห์โค้ดหลายไฟล์ไปยัง GPT 5.6 Sol ระดับ deep-reasoning ของตระกูลที่สร้างมาเพื่อเวิร์กโหลดวิศวกรรมระดับ frontier ทีมที่สร้าง coding copilots, บอตรีวิวอัตโนมัติ และตัวสร้างเทสต์จะได้ตรรกะระดับ production

สร้างคอนเทนต์ตรงแบรนด์ในระดับสเกล
GPT 5.6 Luna ระดับครีเอทีฟของตระกูล ช่วยร่างบล็อกโพสต์ คำอธิบายสินค้า และข้อความ localized ด้วยน้ำเสียงเป็นธรรมชาติและเอาต์พุตที่ปรับให้เฉพาะบุคคล ทีมคอนเทนต์และแพลตฟอร์ม ecommerce สามารถผลิตคอนเทนต์ปริมาณมากโดยไม่เสียเอกลักษณ์ของแบรนด์

ขับเคลื่อนผู้ช่วยซัพพอร์ตด้วย ChatGPT API
ต้องการแชตบอตที่ตอบตามสคริปต์หรือไม่? GPT 5.6 Terra มอบคำตอบที่เชื่อถือได้และอ้างอิงข้อมูลจริง ออกแบบมาสำหรับบทสนทนาระดับ production เพื่อให้ทีมซัพพอร์ตและผลิตภัณฑ์ SaaS สามารถทำให้การจัดการ ticket เป็นอัตโนมัติและลดคำถามซ้ำ ๆ ได้อย่างน่าเชื่อถือ

ระบบความรู้แบบ Retrieval-Augmented
ป้อนคู่มือนโยบายทั้งเล่มหรือคลังงานวิจัยเข้าสู่โมเดล long-context แล้วรับคำตอบที่อ้างอิงข้อมูลจริงพร้อมความแม่นยำต่อแหล่งที่มา ทีมกฎหมาย การแพทย์ และ internal-search จะได้เอนจินที่เชื่อถือได้สำหรับการถามตอบแบบ retrieval-augmented

สกัดข้อมูลแบบมีโครงสร้างผ่าน ChatGPT API
ใบแจ้งหนี้ อีเมล และ PDF ที่ไม่เป็นระเบียบจะถูกแปลงเป็น JSON ที่สะอาดและระบบปลายน้ำเชื่อถือได้ การทำตามคำสั่งอย่างน่าเชื่อถือช่วยคง schema ไว้ครบถ้วน รองรับ data pipelines, ระบบอัตโนมัติ CRM และเวิร์กโฟลว์ analytics ที่ยอมให้เกิด drift ไม่ได้

จับคู่งานทุกประเภทกับระดับโมเดลที่เหมาะสม
เมื่อทั้งงบประมาณและ latency มีความสำคัญ ให้สลับระหว่าง Sol, Terra และ Luna ผ่านคีย์เดียวที่เข้ากันได้กับ OpenAI สตาร์ทอัพและนักพัฒนาอินดี้สามารถทำ prototype ได้รวดเร็วด้วยราคาแบบ pay-as-you-go แล้วขยาย integration เดิมสู่ production ได้
| โมเดล | บริบท | เอาต์พุตสูงสุด | อินพุต | การวางตำแหน่ง |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | ข้อความ | LLM สำหรับการให้เหตุผลประสิทธิภาพสูง |
| GLM-5 | 202.75K | 202.75K | ข้อความ | โมเดลพื้นฐานเรือธง |
| DeepSeek V3.2 | 163.84K | 163.84K | ข้อความ | โมเดลทั่วไปเรือธง |
| MiniMax-M2.5 | 204.8K | 196.6K | ข้อความ | การเขียนโค้ดแบบ Agentic ระดับ SOTA |
วิธีใช้ ChatGPT บน Atlas Cloud
เริ่มต้นได้ในไม่กี่นาที — ทำตามขั้นตอนง่าย ๆ เหล่านี้เพื่อเชื่อมต่อและใช้งานโมเดลผ่านแพลตฟอร์ม Atlas Cloud
สร้างบัญชี Atlas Cloud
สมัครสมาชิกที่ atlascloud.ai และยืนยันตัวตน ผู้ใช้ใหม่จะได้รับเครดิตฟรีเพื่อสำรวจแพลตฟอร์มและทดสอบโมเดล
ทำไมต้องใช้ ChatGPT บน Atlas Cloud
การรวมโมเดล ChatGPT ขั้นสูงเข้ากับแพลตฟอร์มที่เร่งด้วย GPU ของ Atlas Cloud ให้ประสิทธิภาพ ความสามารถในการขยาย และประสบการณ์นักพัฒนาที่ไม่มีใครเทียบได้
ประสิทธิภาพและความยืดหยุ่น
เวลาแฝงต่ำ:
inference ที่ปรับแต่ง GPU เพื่อการตอบสนองแบบเรียลไทม์
API แบบรวมศูนย์:
รัน ChatGPT, GPT, Gemini และ DeepSeek ด้วยการเชื่อมต่อเดียว
ราคาโปร่งใส:
ชำระเงินต่อโทเค็นที่คาดเดาได้พร้อมตัวเลือก serverless
องค์กรและขนาด
ประสบการณ์นักพัฒนา:
SDK, การวิเคราะห์, เครื่องมือปรับแต่ง และเทมเพลต
ความน่าเชื่อถือ:
ความพร้อมใช้งาน 99.99%, RBAC และการบันทึกที่พร้อมสำหรับการปฏิบัติตาม
ความปลอดภัยและการปฏิบัติตาม:
SOC 2 Type II, สอดคล้อง HIPAA, อธิปไตยข้อมูลในสหรัฐอเมริกา
ChatGPT API: คำถามสำหรับนักพัฒนาพร้อมคำตอบ
ChatGPT API ช่วยให้นักพัฒนาส่งพรอมป์ไปยัง GPT models ของ OpenAI และรับ completions ผ่านโปรแกรมได้โดยไม่ต้องใช้อินเทอร์เฟซแชท บน Atlas Cloud คุณเข้าถึง GPT 5.6 lineup ได้ครบทั้งหมด รวมถึง GPT 5.4 และ GPT 5.5 ผ่าน endpoint เดียวที่เข้ากันได้กับ OpenAI ทุกการเรียกคิดค่าบริการตาม token พร้อมราคาแบบจ่ายตามการใช้งานจริงที่โปร่งใส คุณจึงจ่ายเฉพาะสิ่งที่สร้างขึ้นเท่านั้น
มี 5 models ครอบคลุมตั้งแต่การให้เหตุผลเชิงลึกไปจนถึงแชททั่วไปในชีวิตประจำวัน GPT 5.6 Sol เหมาะกับการแก้ปัญหาท้าทายและ frontier workloads, GPT 5.6 Terra รองรับ production workflows ที่เชื่อถือได้ และ GPT 5.6 Luna ปรับแต่งมาสำหรับบทสนทนาที่เป็นธรรมชาติและการสร้างคอนเทนต์ ส่วน GPT 5.4 และ GPT 5.5 เพิ่มความสามารถด้าน multimodal reasoning และ coding สำหรับทีมที่ต้องการประสิทธิภาพอเนกประสงค์ที่พิสูจน์แล้ว
สร้าง API key หนึ่งรายการ ตั้งค่า base URL เป็น https://api.atlascloud.ai/v1 และกำหนด model ID เช่น openai/gpt-5.6-terra เนื่องจาก ChatGPT API ที่นี่เข้ากันได้กับ OpenAI อย่างสมบูรณ์ โค้ด OpenAI SDK เดิมจึงทำงานได้หลังจากเปลี่ยนเพียง base URL และ key เท่านั้น ไม่มี waitlist และไม่ต้องสมัคร subscription อีกทั้งรุ่นใหม่ยังมาพร้อม Day-0 access คุณจึงส่งคำขอแรกได้ภายในวันเดียวกัน
ราคาจะปรับตาม model ที่คุณเลือก GPT 5.6 Luna ประหยัดที่สุดที่ $1 ต่อหนึ่งล้าน input tokens และ $6 ต่อหนึ่งล้าน output tokens, GPT 5.6 Terra อยู่ที่ $2.5 และ $15 ส่วน GPT 5.6 Sol อยู่ที่ $5 และ $30 Prompt caching ช่วยลดต้นทุนของ input ที่ใช้ซ้ำ และการคิดค่าบริการยังเป็นแบบจ่ายตามการใช้งานจริง คุณจึงถูกเรียกเก็บเฉพาะ token ที่ใช้เท่านั้น
ได้ endpoint นี้ทำตามรูปแบบ OpenAI Chat Completions ดังนั้น OpenAI SDKs อย่างเป็นทางการ, LangChain และไลบรารีส่วนใหญ่ที่เข้ากันได้กับ OpenAI จะทำงานได้เมื่อคุณเปลี่ยน base URL และ key นั่นหมายความว่า integration ของ ChatGPT API ที่มีอยู่สามารถย้ายมาได้โดยไม่ต้องเขียน logic ของ request ใหม่
Streaming และ function calling ทำงานเหมือน implementation ของ OpenAI ทุกประการ คุณจึงตั้งค่า stream เป็น true เพื่อรับ output ทีละ token และส่ง tools array เพื่อเรียกใช้ function calls ได้ ส่วน structured JSON responses ใช้รูปแบบ request ที่เข้ากันได้กับ OpenAI แบบเดียวกัน ทำให้ agent orchestration และ data-extraction pipelines คาดการณ์ได้
Models เหล่านี้รองรับพรอมป์ขนาดใหญ่สำหรับ workflows ที่เกี่ยวกับเอกสารยาวและ repository ทั้งหมด ราคาแบ่งเป็น tier ที่ระดับ 272,000-token โดยมีอัตรามาตรฐานสำหรับพรอมป์ที่ต่ำกว่าระดับนี้ และอัตราที่สองสำหรับพรอมป์ที่เกิน 272,000 tokens ดังนั้นคุณสามารถป้อน context จำนวนมากใน request เดียว และรู้ได้ชัดเจนว่าอัตราราคาเปลี่ยนอย่างไรเมื่อพรอมป์มีขนาดใหญ่ขึ้น
เลือก model ให้ตรงกับงาน ใช้ GPT 5.6 Sol เมื่อคุณต้องการ frontier reasoning และการแก้ปัญหาที่ท้าทาย เลือก GPT 5.6 Terra สำหรับการวิเคราะห์ที่ grounded และพร้อมใช้งานระดับ production และใช้ GPT 5.6 Luna สำหรับงานสนทนาหรืองานสร้างสรรค์ที่ให้ความสำคัญกับต้นทุนมากที่สุด ส่วน GPT 5.4 และ GPT 5.5 ยังคงเป็นตัวเลือก multimodal ที่แข็งแกร่งสำหรับ coding และ general reasoning
Atlas Cloud รัน ChatGPT API บน managed infrastructure ที่สเกลตามทราฟฟิกของคุณ คุณจึงไม่ต้องจัดการ GPU provisioning และ node orchestration แบบ self-hosting รุ่น model ใหม่มาพร้อม Day-0 access ทำให้คุณใช้งานเวอร์ชันล่าสุดได้โดยไม่ต้องทำงาน migration เมื่อความต้องการของคุณเพิ่มขึ้น key เดียวที่เข้ากันได้กับ OpenAI ก็ครอบคลุมทุก model ใน family ดังนั้นการสเกลจึงไม่จำเป็นต้องสร้าง integration ใหม่
สำรวจกลุ่มเพิ่มเติม
Seedance 2.0
Seedance 2.0 API ให้คุณเข้าถึงระดับโปรดักชันของโมเดลวิดีโอแบบมัลติโมดัลจาก ByteDance — รองรับอินพุต 4 รูปแบบ (ข้อความ, รูปภาพ, วิดีโอ, เสียง) และระบบ "Universal Reference" ชั้นนำของอุตสาหกรรมที่ล็อกองค์ประกอบภาพ การเคลื่อนไหวของกล้อง และการกระทำของตัวละครในทุกช็อต ผสานรวมการควบคุมระดับผู้กำกับด้วยการเรียกใช้ API เพียงครั้งเดียว ในราคาคงที่ $0.09/วินาที รับคีย์ได้ทันที และไม่มีคิวรอ — พร้อมการรับประกันเวลาพร้อมใช้งานและการปฏิบัติตามข้อกำหนดระดับองค์กร Seedance 2.0 Native 4K เปิดใช้งานแล้ววันนี้!
Grok Imagine
Grok Imagine API นำเสนอการสร้างภาพ วิดีโอ และเสียงของ xAI ให้นักพัฒนาในชุดเครื่องมือเดียว สามารถสร้างภาพความละเอียดสูงสุด 2K พร้อมการเรนเดอร์ข้อความหลายภาษา รวมถึงวิดีโอความยาวสูงสุด 15 วินาทีพร้อมเสียงที่ซิงโครไนซ์แบบเนทีฟและการแก้ไขตามข้อมูลอ้างอิง บน Atlas Cloud คีย์เดียวสามารถรัน Grok Imagine ได้ทุกโหมด คุณจึงสามารถสลับไปมาระหว่างภาพ วิดีโอ และเสียงได้โดยไม่ต้องตั้งค่าแยกกัน เริ่มต้นที่ $0.02 ต่อภาพ และ $0.05 ต่อวินาที
Gemini Omni Flash
Gemini Omni API นำโมเดลสร้างและแก้ไขวิดีโอแบบมัลติโมดัลของ Google DeepMind ซึ่งเปิดตัวในงาน Google I/O 2026 มาสู่สแต็กของคุณ Gemini Omni ผสานเอนจินการใช้เหตุผลของ Gemini เข้ากับสื่อเชิงสร้างสรรค์ รองรับอินพุตทุกรูปแบบทั้งข้อความ รูปภาพ วิดีโอ และเสียง เพื่อสร้างผลลัพธ์ที่สอดคล้องกันและอิงตามความรู้ ปรับแต่งผลลัพธ์ผ่านการสนทนาอย่างเป็นธรรมชาติ ไม่ว่าจะเปลี่ยนวัตถุ เขียนฉากใหม่ หรือปรับสไตล์ โดยที่ฟิสิกส์ ตัวละคร และความต่อเนื่องยังคงเดิม Atlas Cloud ให้บริการ Gemini Omni Flash ครบทั้งไลน์อัป ทั้งการสร้างวิดีโอจากข้อความ การสร้างวิดีโอจากรูปภาพพร้อมรูปอ้างอิงสูงสุด 7 รูป และการสร้างวิดีโอจากรูปอ้างอิง ผ่าน API เดียวแบบครบวงจร ด้วยราคาต่อวินาทีที่โปร่งใสเริ่มต้นที่ $0.112 โดยไม่ต้องสมัครสมาชิก เริ่มสร้างได้เลยวันนี้
GPT Image 2
GPT Image 2 API ช่วยให้นักพัฒนาสามารถเข้าถึงโมเดลรูปภาพล่าสุดของ OpenAI ซึ่งเป็นรุ่นสืบทอดจาก GPT Image 1.5 โดยสามารถสร้างและแก้ไขรูปภาพพร้อมกับการเรนเดอร์ข้อความที่แม่นยำทั้งในอักษรละตินและ CJK รวมถึงการจัดวางองค์ประกอบที่ยอดเยี่ยมสำหรับโปสเตอร์ ม็อกอัป และอินโฟกราฟิก บน Atlas Cloud คุณสามารถเข้าถึงโมเดลนี้ผ่าน API ที่เป็นหนึ่งเดียวร่วมกับโมเดลอื่นๆ อีกกว่า 300 รุ่น พร้อมเครดิตฟรี เวลาทำงาน 99.99% และไม่จำเป็นต้องมีการตรวจสอบยืนยันองค์กรจาก OpenAI
โมเดลเชิงสร้างสรรค์ที่ทรงพลังที่สุดของ Google พร้อมใช้งานแล้วบน Atlas Cloud โดย Veo 3.1 นำเสนอการสร้างวิดีโอระดับภาพยนตร์ Nano Banana 2 ขับเคลื่อนการสร้างภาพที่มีความเที่ยงตรงสูง และ Gemini นำความชาญฉลาดแบบมัลติโมดัลมาสู่ทุกเวิร์กโฟลว์ เข้าถึงชุดโมเดลของ Google เต็มรูปแบบผ่าน API key เดียวพร้อมความพร้อมใช้งานระดับ Day-0 และการกำหนดราคาแบบจ่ายตามการใช้งาน (pay-as-you-go)
Seedance 2.0 Mini
Seedance 2.0 Mini นำเสนอการสร้างวิดีโอแบบมัลติโมดัลของ ByteDance สู่เวิร์กโฟลว์ที่ความเร็วและต้นทุนมีความสำคัญสูงสุด โดยมอบความสามารถหลักของ Seedance 2.0 ในรูปแบบที่ใช้ทรัพยากรน้อยลง — สร้างได้เร็วกว่า ต้นทุนต่อวิดีโอต่ำกว่า และใช้การผสานรวม API เดิมที่คุณใช้อยู่แล้ว สำหรับทีมที่จัดการไปป์ไลน์ปริมาณมากหรือสร้างต้นแบบในสเกลขนาดใหญ่ Mini คือตัวเลือกเริ่มต้นที่ใช้งานได้จริง
ByteDance
ตั้งแต่การสร้างวิดีโอระดับภาพยนตร์ไปจนถึงการสร้างภาพที่มีความละเอียดสูง โมเดลที่ทรงพลังที่สุดของ ByteDance พร้อมใช้งานแล้วบน Atlas Cloud รัน Seedance และ Seedream ในสเกลขนาดใหญ่ด้วยราคาการอนุมานที่ต่ำที่สุด และไม่มีค่าใช้จ่ายแฝงด้านโครงสร้างพื้นฐาน
Alibaba
Atlas Cloud รวบรวมโมเดลทั้งหมดของ Alibaba ไว้ใน API เดียว: Qwen สำหรับงานด้านภาษาและรูปภาพ และ Wan สำหรับการสร้างวิดีโอความละเอียดสูงสุด 1080p เข้าถึงทุกโมเดลในรูปแบบจ่ายตามการใช้งานจริง (pay-as-you-go) โดยไม่ต้องสมัครสมาชิก Alibaba API พร้อมใช้งานผ่าน base URL เดียวโดยใช้ไคลเอนต์ที่รองรับ OpenAI ที่คุณมีอยู่แล้ว
OpenAI
Atlas Cloud ให้คุณเข้าถึงกลุ่มผลิตภัณฑ์ OpenAI API แบบครบวงจร ตั้งแต่ GPT Image 2 สำหรับการสร้างภาพถ่าย ไปจนถึง Sora 2 สำหรับวิดีโอ ทุกโมเดลพร้อมใช้งานแบบจ่ายตามการใช้งานจริง (pay-as-you-go) โดยไม่มีข้อผูกมัดรายเดือน เชื่อมต่อได้ง่ายดายด้วยการสลับ base URL เพียงจุดเดียวโดยใช้ API ที่เข้ากันได้กับ OpenAI
xAI
สร้างไปป์ไลน์ภาพและวิดีโอที่สมบูรณ์โดยใช้ xAI API บน Atlas Cloud สร้างที่ความละเอียด 2K แก้ไขด้วยภาพอ้างอิง และทำให้ภาพเคลื่อนไหวเป็นคลิปที่ซิงค์กับเสียง
Kwaivgi
Kwaivgi API ในราคาที่ถูกกว่าราคามาตรฐาน 15% Atlas Cloud มอบการเข้าถึง Day-0 สำหรับการเปิดตัว Kling ใหม่ด้วยการกำหนดราคาแบบจ่ายตามการใช้งานจริง (pay-as-you-go) และไม่จำกัดจำนวนผู้ใช้ บัญชีเดียว คีย์เดียว สำหรับโมเดล Kling ทุกรุ่นตั้งแต่ระดับมาตรฐานไปจนถึงระดับมาสเตอร์
Seedream 5.0 Pro
Seedream 5.0 Pro API มอบโมเดลการแก้ไขภาพที่ควบคุมได้ของ ByteDance บน Atlas Cloud ให้กับนักพัฒนา โดยจะวางการแก้ไขอย่างแม่นยำด้วยจุดยึดและพิกัด แยกภาพออกเป็นเลเยอร์ที่แก้ไขได้ ผสานข้อมูลอ้างอิงหลายรายการ และจับคู่สีและวัสดุที่แน่นอน พร้อมข้อความหลายภาษาที่ความละเอียด 2K และ 3K บน Atlas Cloud คุณสามารถเข้าถึงได้ผ่านคีย์เดียว!


