摘要: GLM-5-Turbo 由智谱 AI (Z.ai) 开发,是一款专为 OpenClaw 应用场景设计的大语言模型,也是该公司首个闭源发布的模型(此前以 Pony-Alpha-2 代号进行测试),即将上线 Atlas Cloud。
该模型在工具使用、指令执行、多步工作流和长周期任务处理方面均有显著提升,并支持高达 200K token 的上下文窗口。其数据分析能力可媲美 Claude Opus 4.6,在自动化和信息处理任务中表现优于 GLM-5。依托 Atlas Cloud 的统一 API 和多模型生态,GLM-5-Turbo 能够高效部署于复杂的业务自动化、长文档分析和软件开发场景,为开发者和企业提供了一种经济高效且易于集成的 AI 解决方案。
我们非常高兴地宣布,GLM-5-Turbo 即将登陆 Atlas Cloud!
- 什么是 GLM-5-Turbo:GLM-5-Turbo 由智谱 AI (Z.ai) 开发,是一款专为 OpenClaw 用例量身定制的大语言模型。这是团队首个闭源发布的模型,在提供比 GLM-5 更高的运行效率的同时,单次调用的成本更低。此前,智谱 AI 曾以 Pony-Alpha-2 的代号对该下一代模型进行了内部测试。
- 核心功能:GLM-5-Turbo 在工具使用、指令遵循、多步工作流和持续任务执行方面实现了显著提升。它支持跨场景的动态推理模式、实时流式输出、增强的工具集成,以及高达 200K token 的长上下文处理能力。
- 发布日期:2026 年 3 月 24 日。
GLM-5 此前因在 Artificial Analysis Intelligence Index 上表现出色(超越 Gemini 3 Pro)而备受关注。作为其继任者,GLM-5-Turbo 带来了系列迭代升级,详见下文。
核心定位:针对 ClawBench 优化的模型
强劲的基准测试表现
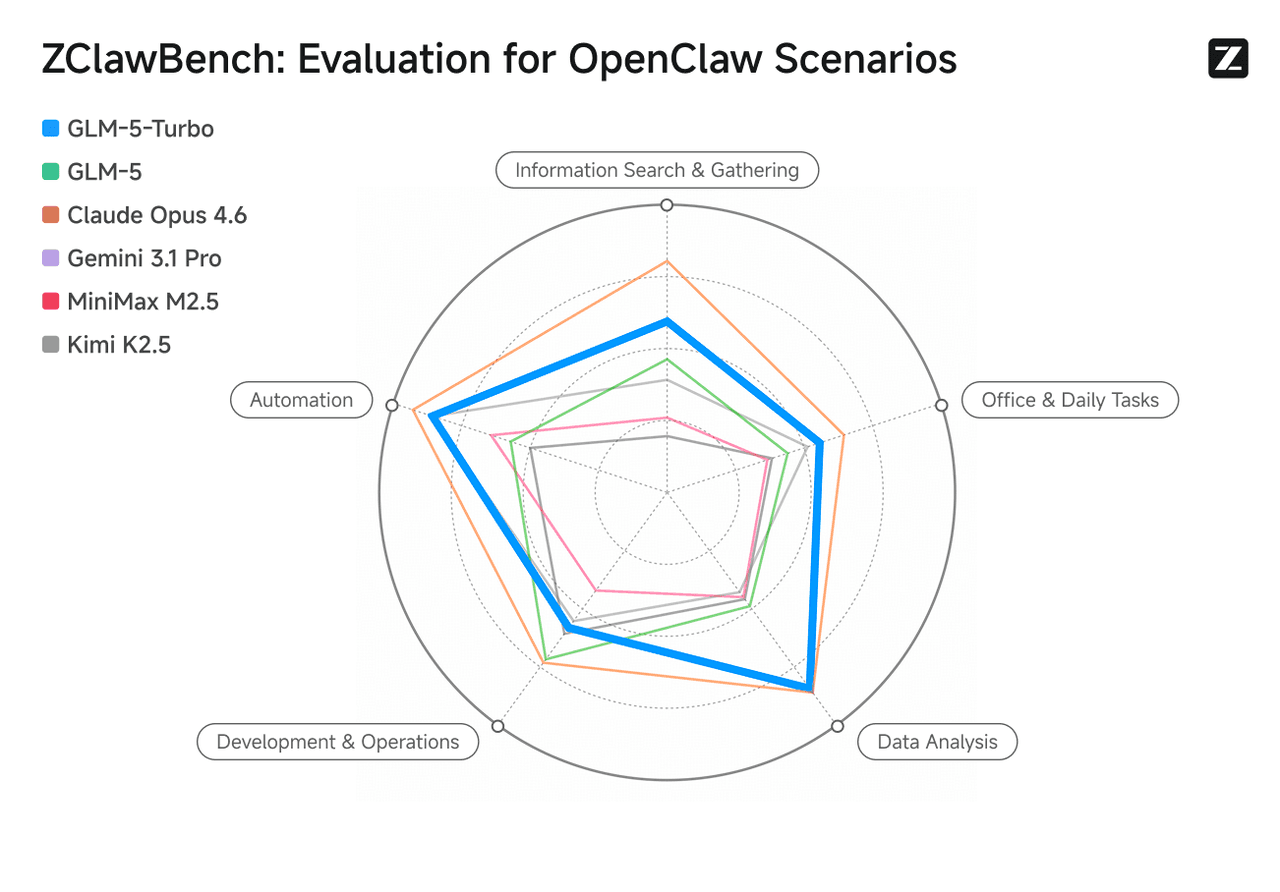
针对 OpenClaw 场景进行了优化,GLM-5-Turbo 在工具调用、指令执行和复杂任务编排方面的能力得到了显著增强。其数据分析性能与 Claude Opus 4.6 持平,并在自动化、信息检索、办公生产力和分析任务中表现优于 GLM-5。
图片来源:智谱 AI (Z.ai) 官网。
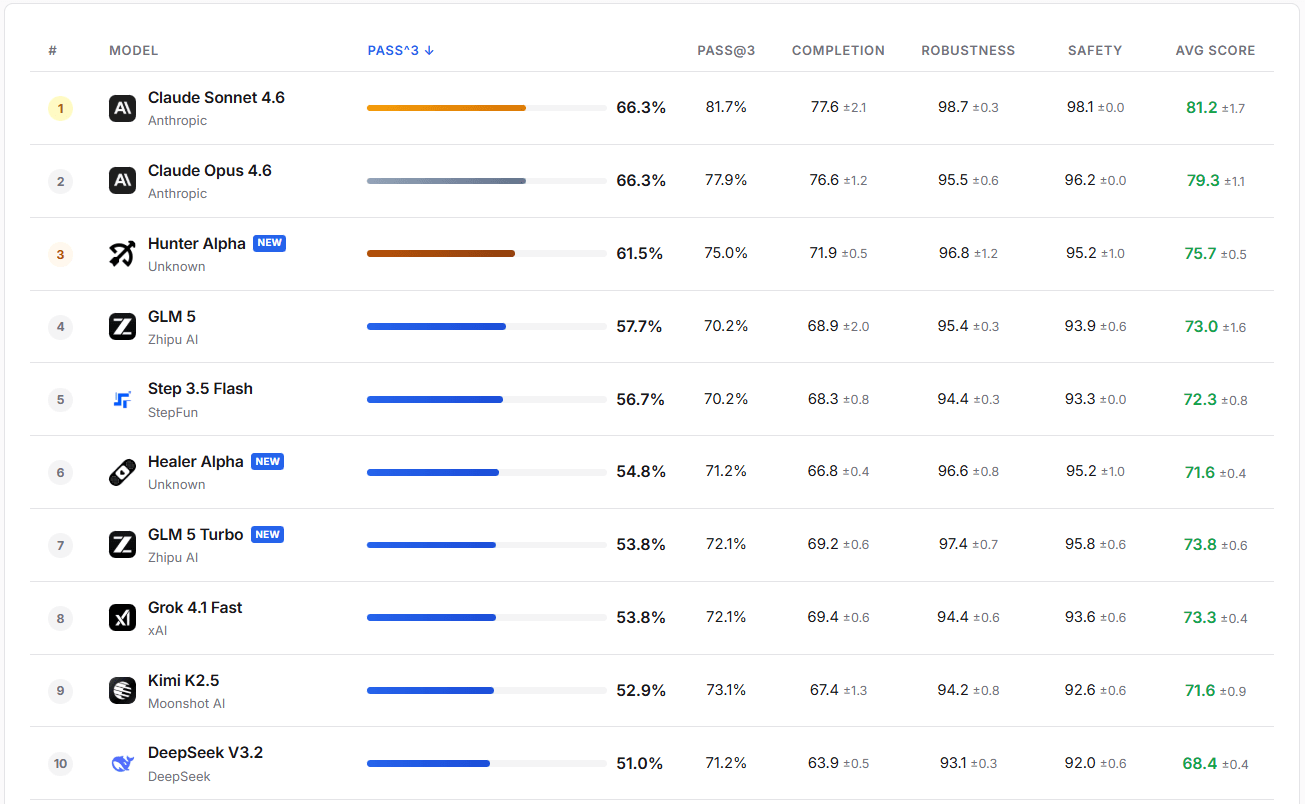
在实际评估中,GLM-5-Turbo 展现出了极高的鲁棒性和安全性。其 PASS@3 成功率超过了 GLM-5、Step 3.5 Flash 和 Kimi K2.5。
图片来源:https://claw-eval.github.io/
增强的工具使用与外部集成
Z.ai 在训练过程中强化了 GLM-5-Turbo 的智能体(Agent)能力,实现了与外部工具的无缝交互。这种“执行优先”的导向也带来了一些权衡:一些用户反馈,在角色扮演场景中,相比 GLM-5,其语气显得略微生硬。
为了平衡各模型的优势,Atlas Cloud 提供了统一的接口,支持用户同时查询多个模型,进行对比和筛选。
此外,用户还可以自定义技能,或允许 GLM-5-Turbo 自主发现并安装这些技能。
图片来源:Atlas Cloud

长周期自主执行
GLM-5-Turbo 针对需要定时触发或延长运行时间的任务进行了优化。它能够处理持续、多阶段和跨时间段的工作流,并具备极强的任务连续性。
该模型会根据任务复杂度主动建议执行策略。在代码优化的对比测试中,GLM-5-Turbo 给出的建议在约 10% 的案例中优于竞品模型。
200K Token 上下文窗口
支持高达 200K token(约 13.3 万个英文单词),GLM-5-Turbo 可以在单次会话中保留并利用大量上下文信息。这使得即便在对话后期,模型也能准确检索到早期的信息。
图片来源:Jim Allen Wallace (Redis)
应用场景
自动化复杂工作流
凭借增强的 OpenClaw 能力,GLM-5-Turbo 可以拆解复杂的业务流程,识别底层逻辑,并自主定位或生成执行任务所需的技能。
例如,在短视频制作中,该模型可以搜索、安装并编排写作、图像生成和视频制作工具——从头到尾规划并执行整个工作流。
长文档问答与深度分析
该模型在单次会话中可完整保留超长文档的上下文,实现准确的多轮问答。其高 token 效率确保了在较低计算成本下实现快速响应。
在大型代码库中,GLM-5-Turbo 可以分析架构设计、映射组件间的依赖关系,并预警底层代码变更可能带来的连锁反应。
“Vibe Coding”(氛围编码)
在软件开发生命周期中,GLM-5-Turbo 更像是一名嵌入在复杂工作流中的全栈工程师。开发者只需勾勒高层逻辑,模型即可实时增量构建应用程序架构。
结合多模态技能,用户上传 UI 截图、屏幕录制或手绘草图,模型即可直接将其转化为功能性的前端组件。
为什么选择在 Atlas Cloud 上使用 GLM-5-Turbo?
作为全模态 AI 基础设施平台,Atlas Cloud 为用户提供了统一的 API 接口。接入后,用户即可轻松解锁包括文本、图像、视频或多模态在内的 300 多种高级 AI 模型。
目标用户
- 独立开发者:寻求以低成本、简便的方式调用各类 AI 模型。
- 企业用户:需要稳定、安全且可扩展的基础设施来支持核心业务。
- 开发团队:需要高效地将多个跨模态模型集成到项目中。
- 工作流用户:注重工具链兼容性,使用 ComfyUI 或 n8n 的用户。
产品特色
- 大幅简化集成:平台提供兼容 OpenAI 的 API,即刻减轻开发者负担。无需再处理繁琐的多供应商密钥管理或承担各平台的维护成本。
- 成本优势:相比竞品,Atlas Cloud 的部署成本更低。Nano Banana 2 仅需 USD0.056/图(竞品:USD0.07/图);Veo 3.1 定价为 USD0.09/秒(竞品:USD0.1/秒)。此外,Playground 界面提供完整的价格透明度,在“运行”按钮上直接标注每张图片或每秒视频的扣费金额。
- 企业级稳定性与支持:Atlas Cloud 确保数据保护符合严格的隐私标准,并能应对敏感信息处理。
- 即插即用友好:专为与 ComfyUI 和 n8n 等工具无缝协作而设计,助力企业降低迁移成本并快速投入使用。
与同类产品的对比
- Fal.ai:虽然他们也提供部分模型,但 Atlas Cloud 提供更广泛的模型选择(300+)、更具竞争力的价格,且新注册用户可获得 USD1 试用金。
- Wavespeed:定价显著更高。Atlas Cloud 提供额外的企业合规支持和专家技术指导,这是 Wavespeed 未强调的。
- Kie.ai:使用不透明的积分系统。Atlas Cloud 在界面上直接展示每次运行的确切成本。模型数量也多于 Kie.ai。
- Replicate:专注于模型托管。Atlas Cloud 的优势在于 API 的统一性、模型部署的响应速度以及更友好的开发者支持政策。
- OpenAI 或 Google:这些供应商仅提供自家的模型。有跨模态需求的用户通常需要集成多个服务。Atlas Cloud 将闭源和开源模型整合在一个 API 下,降低了系统复杂性。
如何在 Atlas Cloud 上使用 GLM-5-Turbo?
方法一:直接在平台使用
方法二:通过 API 集成使用
第一步:获取 API Key。在控制台创建并复制您的 API key:


第二步:查阅 API 文档。查看请求参数、身份验证方法等。
第三步:发起您的第一个请求(Python 示例)
以 GLM-5 为例。
plaintext1{ 2 "model": "zai-org/glm-5", 3 "messages": [ 4 { 5 "role": "user", 6 "content": "Hello" 7 } 8 ], 9 "max_tokens": 1024, 10 "temperature": 0.7, 11 "stream": false 12}
常见问题解答
GLM-5-Turbo 与 GLM-5 有什么区别? GLM-5-Turbo 速度更快、成本效益更高,token 效率显著提升——据报道是 GLM-5 的三倍。它还专门针对 OpenClaw 场景进行了优化。
GLM-5-Turbo 与 MiniMax M2.7 相比如何? 两款模型都针对智能体工具使用进行了优化,且相比 GLM-5 具有更高的 token 效率。两者均支持约 200K token 的上下文窗口(MiniMax M2.7 支持 196,608 token)。我们正在准备一篇详细对比测评的博文,敬请期待!
OpenClaw 部署推荐使用哪款 GLM 模型? 推荐使用 GLM-5-Turbo,因为它专为 OpenClaw 场景进行了优化,且其数据分析性能可媲美 Claude Opus 4.6。






