OpenAI LLM Models
OpenAI’s premier GPT model family leads the industry, highlighted by the GPT OSS 120B which achieves near-parity with OpenAI o4-mini on core reasoning benchmarks while running efficiently on a single 80GB GPU. Perfectly optimized for vibecoding and complex logic operations, this model balances top-tier intelligence with hardware accessibility for modern developers and AI-driven web development.
Models Launching Soon
We're putting the finishing touches on this collection — meanwhile, explore similar collections below.
Explore More Families
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
Grok-Imagine Models
Grok Imagine Image Quality is xAI's latest AI image generation model, delivering studio-grade visuals with up to 2K resolution and razor-sharp detail. It offers best-in-class text rendering across multiple languages, photorealistic outputs with natural lighting, rich textures, and believable physics, plus tighter prompt following and image editing with reference inputs for precise creative control. Ideal for hero images, ad creatives, product renders, and brand-grade visuals.
Gemini Omni
Gemini Omni (by Google DeepMind) is a video generation and editing model launched on May 20, 2026 at Google I/O that redefines the standard for "reasoning-driven creation," built specifically to solve the core challenge of AI video: making output that actually understands what you mean, not just what you type. It fuses Gemini's reasoning engine with generative capability, accepting any mix of images, text, video, and audio to produce consistent, knowledge-grounded output. Unlike models that start from scratch each time, Omni lets you edit through natural conversation — swapping objects, rewriting scenes, shifting styles — while keeping physics, characters, and continuity intact across every turn.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Google Models on Atlas Cloud | Gemini, Nano Bananas & Veo
Google's most powerful creative models are all available on Atlas Cloud. Veo 3.1 delivers cinematic video generation, Nano Banana 2 powers high-fidelity image creation, and Gemini brings multimodal intelligence to every workflow. Access the full Google model suite through one API key with Day-0 availability and pay-as-you-go pricing.
ByteDance Models on Atlas Cloud | Seedance & Seedream
From cinematic video generation to high-fidelity image creation, ByteDance's most powerful models are live on Atlas Cloud. Run Seedance and Seedream at scale with the lowest inference pricing and zero infrastructure overhead.
Alibaba Models on Atlas Cloud | Wan & Qwen
Atlas Cloud brings together Alibaba's full model lineup under one API: Qwen for language and image tasks, Wan for video generation up to 1080p. Access every model pay-as-you-go with no subscriptions. The Alibaba API is available via a single base URL using your existing OpenAI-compatible client.
MAI Image 2.5 Models
MAI-Image-2.5 is Microsoft's latest photorealistic image generation and editing model family, built for commercial design, product photography, and brand-ready content creation. Available in standard and Flash variants for both text-to-image and image editing, it delivers best-in-class Arena ELO scores at competitive pricing — starting from $0.03 per image. With precise text rendering, surgical editing capability, and natural portrait generation, MAI-Image-2.5 is designed for teams that need production-quality visuals without post-processing overhead.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Midjourney Models
Midjourney is a proprietary AI image and video generation platform developed by Midjourney, Inc. (San Francisco). Founded in 2021 by David Holz, it has become the aesthetic gold standard in generative AI — transforming text prompts into cinematic, painterly visuals at native 2K resolution. The latest V8.1 architecture, rebuilt from scratch on GPU-native PyTorch, delivers 4–5× faster generation, true 2048×2048 output without upscaling artifacts, and a signature visual style that remains unmatched by competitors. With the addition of Video V1, Midjourney extends its aesthetic into motion — animating still images into atmospheric 5-second cinematic clips. From brand campaigns to film pre-visualization to game concept art, Midjourney is the premier AI creative tool for professionals who demand both speed and artistry.
PixVerse Models
PixVerse, developed by AISphere, is a video generation model series built around one idea: giving creators director-level control over every frame. V6 is the flagship generation model, covering text-to-video, image-to-video, reference-to-video, start-and-end frame control, and video extension in a single cohesive pipeline. C1 takes a different approach — it is a storyboard-native model designed for multi-shot narrative production, where scene continuity and visual consistency across clips matter as much as individual frame quality. Both series are available on Atlas Cloud, starting from $0.025 per second, with no infrastructure setup required.
What Makes OpenAI LLM Models Stand Out
Atlas Cloud provides you with the latest industry-leading creative models.

Frontier Research
Cutting-edge models that set global benchmarks in reasoning, multimodality, and AI safety.

Cost-Efficient Performance
Optimized families like GPT-4.1 mini and GPT-5 nano balance accuracy, speed, and cost.

Developer Ecosystem
APIs powering millions of daily requests across diverse platforms and industries.

Flexible Model Sizes
Choice of flagship, mini, and nano models for every workload and budget.

Enterprise Reliability
SLAs, monitoring, and compliance-ready logging trusted by Fortune 500 companies.

Open Model Options
Access to open-source models (gpt-oss-20b, gpt-oss-120b) for transparency and customization.
Peak speed
Lowest cost
| Model | Description |
|---|---|
| GPT OSS 120B | GPT OSS 120B is a high-performance reasoning-centric LLM, integrating optimized architecture with robust 131.07K context processing capabilities; attaining near-parity with OpenAI o4-mini on a single 80 GB GPU, it serves as the engine for rapid iterative development, including vibecoding and executing complex logic-driven workflows. |
New features of OpenAI LLM Models + Showcase
Combining advanced models with Atlas Cloud's GPU-accelerated platform delivers unmatched speed, scalability, and creative control for image and video generation.
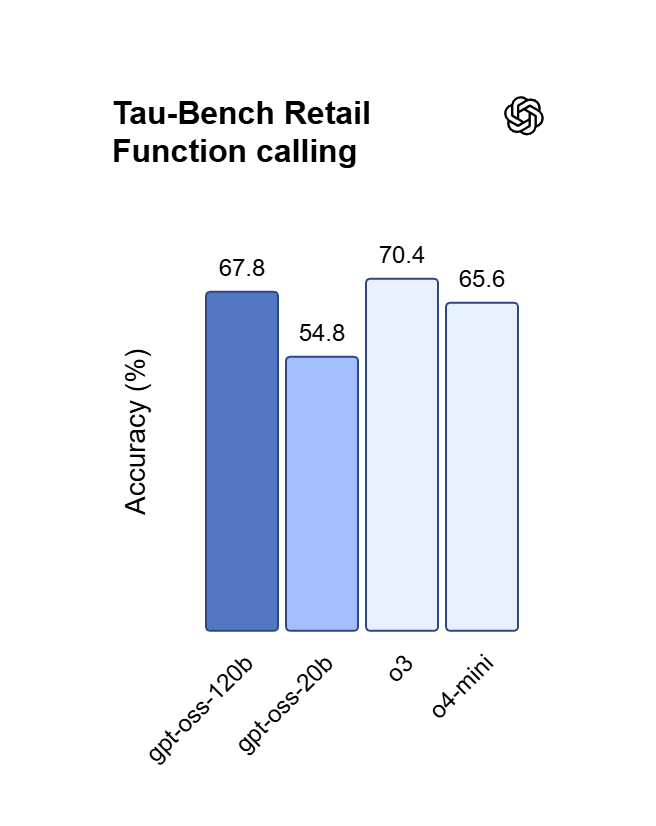
Precise Instruction Compliance via GPT OSS 120B
GPT OSS 120B exhibits exceptional steerability, strictly adhering to complex system prompts to ensure absolute output reliability. By leveraging its fine-tuned alignment architecture, users can enforce specific formats, constraints, and stylistic nuances with zero character drift. It is the definitive choice for autonomous agents, structured data extraction, and mission-critical production environments.
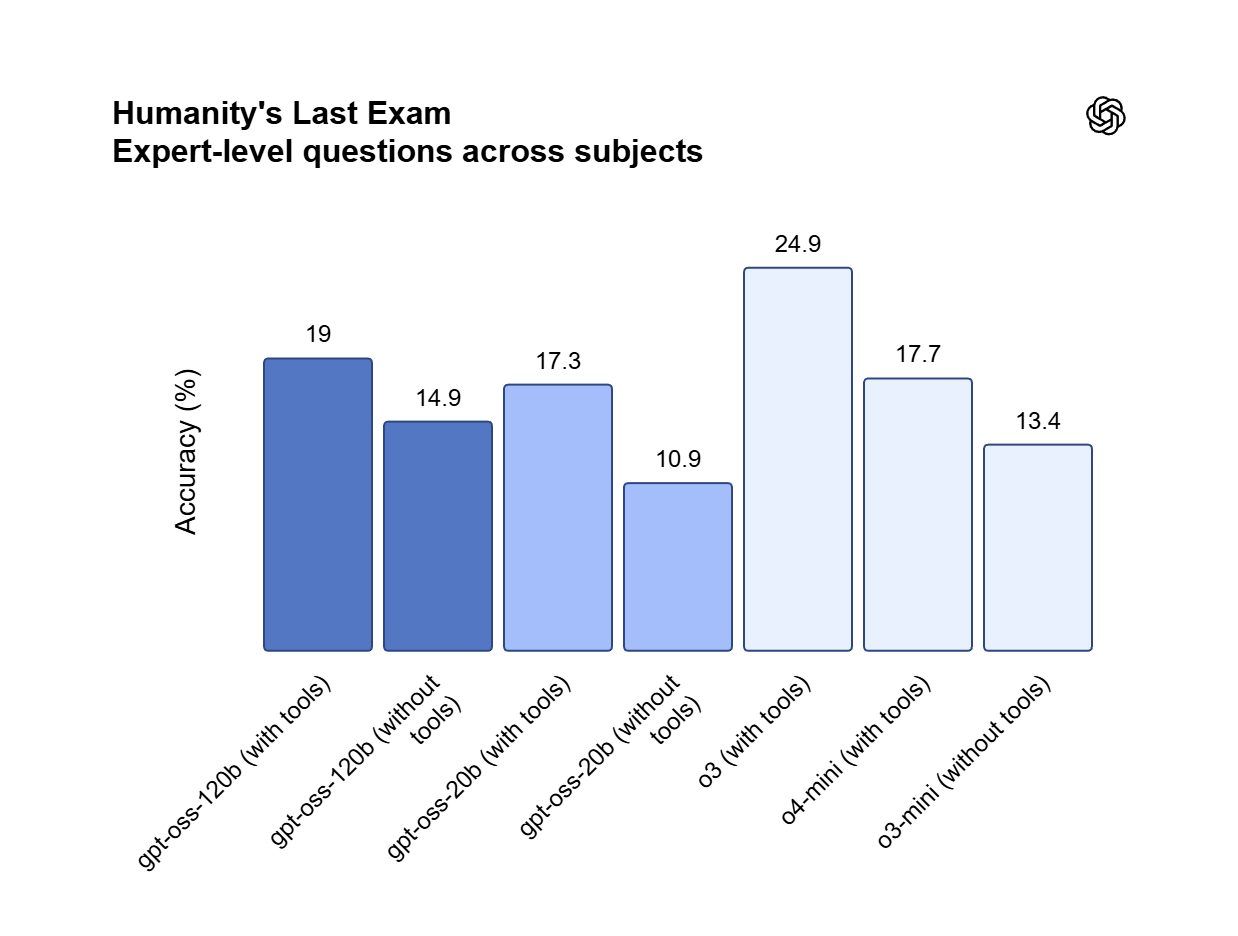
Commercial Sovereignty under Apache 2.0 License
GPT OSS 120B is distributed under the Apache 2.0 license, permitting unrestricted commercial usage and private fine-tuning without per-token fees. Unlike closed-source APIs, it allows for local hosting on a single 80 GB GPU to keep sensitive proprietary data fully on-premises. This framework provides the legal and technical freedom to build, modify, and scale AI-driven software stacks.
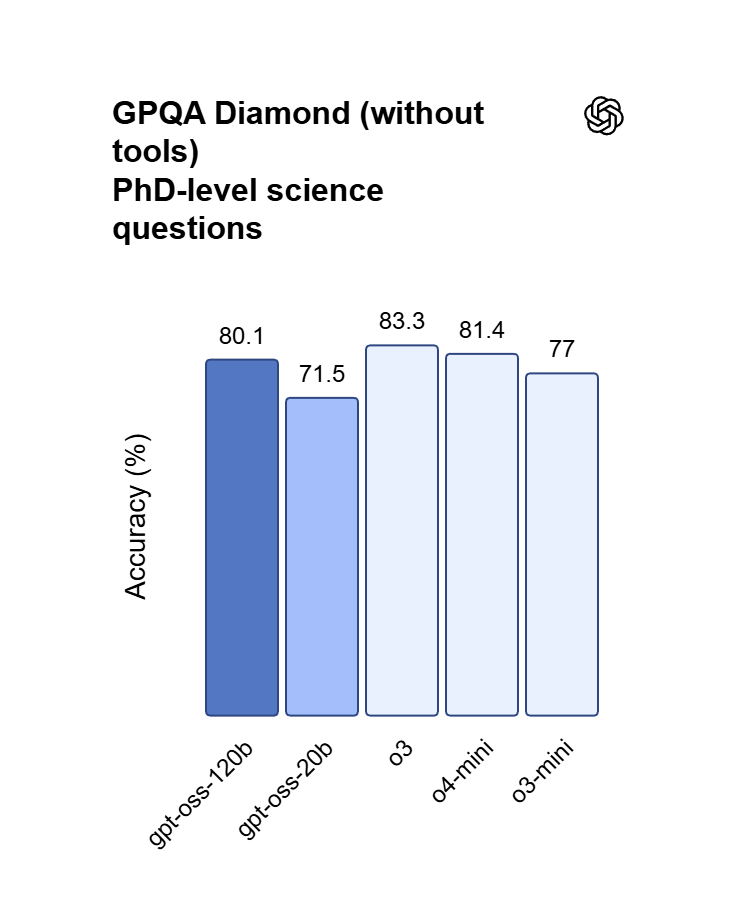
High-Efficiency Logic and Vibecoding using GPT OSS 120B
Achieving near-parity with OpenAI o4-mini, this 120B parameter model excels at handling complex code synthesis and mathematical proofs. Developers can leverage its reasoning engine for "vibe coding"—translating natural language ideas directly into functional web applications through iterative prompting. It is a high-speed solution for debugging nested logic and orchestrating sophisticated task-scheduling workflows.
What You Can Do with OpenAI LLM Models
Discover practical use cases and workflows you can build with this model family — from content creation and automation to production-grade applications.
Deep Logic Debugging and Prototyping with the GPT OSS 120B
The GPT OSS 120B enables engineers to solve "vibecoding" challenges by translating high-level architectural ideas into production-ready Python or React components. Its reasoning engine handles the nested dependencies and edge cases that often trip up mini-models, ensuring multi-step code synthesis remains functional. Supporting algorithmic proofs and complex task scheduling, it is the perfect tool for building technical MVPs, automated QA scripts, and data-intensive web applications.
Offline Proprietary Tooling Using the GPT OSS 120B
Under the Apache 2.0 license, teams can host GPT OSS 120B on a single 80 GB GPU to process sensitive internal data without cloud-leakage risks. This setup allows for permanent local fine-tuning on niche internal codebases or medical logs without recurring per-token API costs. Ideal for high-security internal tools and offline AI assistance, the model provides full weight sovereignty—supporting private RAG systems and customized proprietary software stacks.
Schema-Perfect Data Extraction with the GPT OSS 120B
The GPT OSS 120B enables developers to convert messy, unstructured documents into strictly formatted JSON or Markdown without "instruction drift." By anchoring the 131.07K context window with rigid system rules, the model ensures fields are never hallucinated or skipped during long-form processing. Ideal for CRM automation and automated content tagging, it maintains logical guardrails across massive datasets—supporting reliable API integrations and database population.
Model Comparison
See how models from different providers stack up — compare performance, pricing, and unique strengths to make an informed decision.
| Model | Context | Max Output | Input | Positioning |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Text | High-Efficiency Reasoning LLM |
| GLM-5 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flagship General |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA Agentic Coding |
How to Use OpenAI LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud's platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Why Use OpenAI LLM Models on Atlas Cloud
Combining the advanced OpenAI LLM Models models with Atlas Cloud's GPU-accelerated platform provides unmatched performance, scalability, and developer experience.
Performance & flexibility
Low Latency:
GPU-optimized inference for real-time reasoning.
Unified API:
Run OpenAI LLM Models, GPT, Gemini, and DeepSeek with one integration.
Transparent Pricing:
Predictable per-token billing with serverless options.
Enterprise & Scale
Developer Experience:
SDKs, analytics, fine-tuning tools, and templates.
Reliability:
99.99% uptime, RBAC, and compliance-ready logging.
Security & Compliance:
SOC 2 Type II, HIPAA alignment, data sovereignty in US.
Frequently Asked Questions about OpenAI LLM Models
It achieves near-parity with OpenAI o4-mini on core reasoning and math benchmarks. While o4-mini is a closed API, OSS 120B offers comparable logic depth with the added benefit of full model weight access.
The model is optimized for a single 80 GB GPU, avoiding multi-node complexity. However, for instant scalability and zero maintenance, we recommend accessing it via API on Atlas Cloud.
Yes. It is released under the Apache 2.0 license, which permits unrestricted commercial usage, modification, and distribution without per-token licensing fees or vendor lock-in.
The 131.07K context window is designed for "needle-in-a-haystack" retrieval accuracy. It can ingest entire project directories or 100+ page technical manuals while maintaining logical consistency across the entire input.
Extremely. Its reasoning engine is fine-tuned for iterative code synthesis. It handles nested React components and complex Python backends more reliably than standard 70B-class models, making it ideal for natural-language-to-app workflows.


