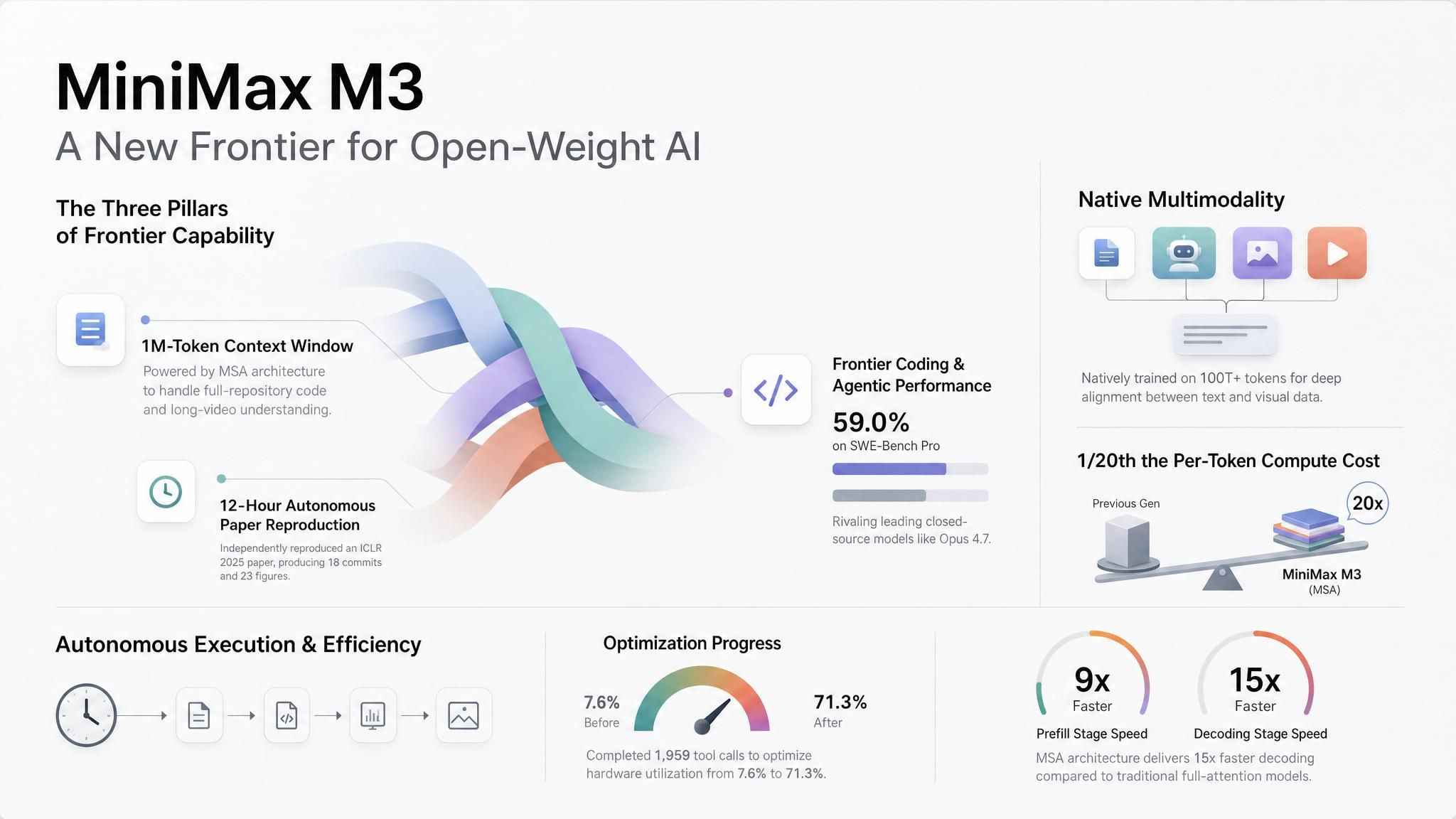
MiniMax M3がリリースされました。要点をまとめると、**「画像と動画をネイティブで扱え、100万トークンのコンテキストを安価に保持でき、長時間のコーディングやエージェントのループ処理を中断せずに実行できるオープンウェイトモデルが必要なら、これを使うべき」**ということです。これがM3の採用ケースであり、就寝中もエージェントを自律的に動かしたいなら、ぜひテストすることをお勧めします!M3はAtlas Cloudで利用可能です。
長時間稼働するエージェントを使っていない場合でも、MiniMaxがその領域に到達するためにとったアプローチを知っておく価値はあります。彼らは、Sparse-attentionアーキテクチャ(MiniMax Sparse Attention: MSA)を採用することで100万トークンのコンテキストを低コストで維持しました。これにより、フルコンテキスト時のトークンあたりの計算コストを前世代の約1/20に削減しています。しかも、最も奇抜な手法ではなく、現在のサービングスタックで動作する最も安価な経路を選択しました。今後、すべての主要プロバイダーがこの「疎(sparse)または圧縮されたアテンションによる安価な長コンテキスト」をデフォルトにすると予測されます。これにより、100万トークンのウィンドウは差別化要因から「あって当たり前」の機能となり、真の競争は「どの単一モデルに賭けるか」ではなく、「モデル間でいかに適切にルーティングするか」というレイヤーへ移行するでしょう。
MiniMaxは2026年6月1日にM3を発表しました。APIは現在利用可能で、同社は発表から約10日以内に技術レポートとウェイトを公開する予定です。
現在他のフロンティアモデルを利用している場合
M3は、現在のデフォルトモデルでは扱いきれない大規模な作業セット、視覚的コンテキスト、またはより長いエージェントのループ処理が必要な場合にテストする価値があります。重要なのは最後の列です。つまり、現在利用しているモデルに加えてM3が何をもたらすか、という点です。
| 現在の利用モデル | 対象タスク | M3がもたらす追加価値 |
|---|---|---|
| GPT-5.5 または GPT-5.5 Pro | エージェントによるコーディング、コンピュータ操作、調査、データ分析、知識労働の自動化 | ネイティブな動画入力とオープンウェイトでの提供 — 将来的にセルフホスト可能な、異なるコスト構造を持つ第2のエージェントルートとして利用可能。(GPT-5.5にはすでに画像認識があるため、動画と経済性を検証してください) |
| Claude Opus 4.8 | 長時間稼働するコーディングエージェント、検索重視の知識労働、ツール使用 | フルリポジトリコーディングおよびタスクあたりのコストをA/Bテストするための、低コストかつオープンウェイトな代替手段。Opus 4.8も100万トークンウィンドウと視覚認識を持つため、真の検証ポイントはウィンドウサイズではなく、価格、動画入力、タスクあたりの経済性です。 |
| Qwen3.7-Plus (マルチモーダル) | 視覚認識およびGUIエージェント、スクリーンショットからのコーディング、ブラウザおよびデスクトップ自動化 | 同等のマルチモーダル能力に加え、より強力なコーディング/エージェント性能とオープンウェイトという選択肢。(Qwen3.7-PlusはプロプライエタリでAPIのみ) |
| Qwen3.7-Max (テキスト特化型フラッグシップ) | テキスト推論、長期間のエージェント運用、オフィス自動化 | 同一コンテキスト内でのネイティブな画像・動画入力。Qwen3.7-Maxはテキスト専用のため、視覚が必要な場合はPlusへの切り替えが必要ですが、M3ならこれ一つで対応可能です。 |
| DeepSeek-V4-Pro または DeepSeek-V4-Flash | コスト重視の推論、コーディング、ツール呼び出し、長コンテキストAPIワークロード | 長コンテキストに加え、ネイティブなマルチモーダル機能(画像および動画)をサポート。DeepSeek-V4はテキスト専用のため、視覚情報を伴うワークロードではM3がマルチモーダルな代替案となります。 |
実用的な検証方法はシンプルです。以下のいずれかを行おうとしているなら、M3を試してみてください。
- リポジトリ、タスク履歴、ログ、現在進行中の計画を一つのコンテキスト内に収める
- エージェントが会話をリセットせずに、数十回のツール呼び出し後も継続して作業できるようにする
- コード、テキスト、スクリーンショット、グラフ、PDF、動画フレームを一度のパスで推論する
- テキストモデル、視覚モデル、独立した検索レイヤー間の受け渡しを削減する
- 100万トークンあたりの価格だけでなく、タスク完了あたりの長コンテキストコストを比較する
ローンチ時のチャートが見栄えが良いからという理由で乗り換えてはいけません。現在のルーティングスタックでは処理が中断される、切り捨てられる、過払いになる、あるいは複数のモデルに分割せざるを得ないタスクを、M3が完遂できた時に乗り換えてください。
M3の強み
ゆとりのあるエージェント環境。 MiniMaxのローンチ例は、従来のチャットデモの枠を超えています。あるテストでは、M3はICLR 2025の優秀論文の主要実験を約12時間かけて再現しました。結果、18件のコミットと23件の実験図表を生成しました。別のテストでは、FP8 GEMM CUDAカーネルに対して約24時間稼働し、147件のベンチマーク提出と1,959件のツール呼び出しを行い、ハードウェア使用率を7.6%から71.3%まで向上させました。
これらの例は「一日中動くエージェントが最初からうまくいく」という証明ではありませんが、モデルが計画し、ツールを動かし、結果を検証し、修正し、試行錯誤の末に継続する必要があるワークフローにおいて、M3がショートリストに入る理由を示しています。
リポジトリおよびドキュメント規模のコンテキスト。 M3はAPIを通じて最大100万トークンをサポートしており、512Kは保証された最小値です。MiniMaxによると、100万トークンのコンテキスト長において、計算コストは前世代の1/20に抑えられ、プリフィル(入力処理)は9倍以上、デコード(出力生成)は15倍以上高速化されています。
これはプロダクト設計を変えます。コーディングエージェントはリポジトリの全容を把握でき、リサーチアシスタントはより長い根拠を保持し、契約書レビューツールはソース資料と分析結果を同一作業領域に置けます。検索機能は依然として有用ですが、モデルが問題のごく一部からしか開始できないという制約はなくなります。
同一リクエスト内での視覚コンテキスト。 MiniMaxはM3を当初からマルチモーダルデータで訓練しました。画像と動画の入力を受け入れ、テキスト、画像、動画を一つのコンテキスト内で混在させて処理できるとしています。
これにより、モデル間の受け渡しが削減されます。サポートワークフローであればユーザーのメッセージとスクリーンショットを同時に確認でき、リサーチワークフローであれば論文内のグラフを推論でき、PC操作エージェントは画面を見てから外部モデルに画像を転送することなく、次の行動を即座に決定できます。
ホスティングアクセス先行、ウェイトは近日公開。 MiniMaxはM3をオープンウェイトリリースとして扱っていますが、最初の提供形態はホスティングされたAPIアクセスです。これによりチームは、「まずはホスト版で検証し、後にウェイトが公開されたらプライベート展開やファインチューニング、社内評価に切り替える」という有益なステップを踏むことができます。
明確な料金体系。 MiniMaxによると、API呼び出しで入力512Kトークン以下は標準料金、それ以上は長コンテキスト用料金が適用されます。チームがリポジトリ全体や長時間の動画を処理する際に適用されます。また、M3は同価格で「思考(thinking)」のトグルをサポートしており、高度なエージェント作業には推論モードを、レイテンシ重視の完了処理には高速モードを使い分けることができます。
運用コストの目安
Atlas CloudでのMiniMax M3の料金は、入力100万トークンあたりUSD0.30、出力100万トークンあたりUSD1.20です。Claude Opus 4.7は入力USD5/出力USD25、GPT-5.5は入力USD5/出力USD30です。
つまりM3は:
- 入力コストにおいてOpus 4.7およびGPT-5.5より94%安価
- 出力コストにおいてOpus 4.7より95.2%安価
- 出力コストにおいてGPT-5.5より96%安価
トークン価格は、ワークロードの形状と照らし合わせて初めて意味を持ちます。大きなリポジトリをコンテキストに持つコーディングエージェントは入力にコストがかかり、長い説明を伴う調査やドラフト作成は出力にコストがかかります。マルチモーダルGUIエージェントは視覚コンテキスト分のコストもかかります。
以下の表は、USD価格、キャッシュヒットなし、バッチ割引なし、地域プレミアムなし、ツール呼び出し手数料なし、再試行なしの単純計算です。GPT-5.5については、OpenAIが272K以上の入力を2倍の料金で請求しているため、長コンテキスト例ではその実効レートを使用しています。
| モデル | 使用レート | 100K入力 + 5K出力 | 500K入力 + 20K出力 | 評価 |
|---|---|---|---|---|
| MiniMax M3 on Atlas Cloud | $0.30 / $1.20 | $0.04 | $0.17 | 低コストなマルチモーダル経路。DeepSeek Flashよりは高いが、フロンティアモデルより圧倒的に安価。 |
| DeepSeek V4 Flash | $0.14 / $0.28 | $0.02 | $0.08 | テキスト専用の大量ワークロード向け。視覚入力が不要な場合に。 |
| DeepSeek V4 Pro | $0.435 / $0.87 | $0.05 | $0.23 | トークンコストはM3に近いがテキスト専用。視覚情報なしの推論・コーディング比較に。 |
| Qwen3.7-Plus | 256Kまで$0.40/$1.60、以上$1.20/$4.80 | $0.05 | $0.70 | 短いマルチモーダル呼び出しに競争力がある。256K以上の経済性に注意。 |
| Qwen3.7-Max | $2.50 / $7.50 | $0.29 | $1.40 | GPTやClaudeより安いが、タスクを勝ち取らない限り大量利用には向かない。 |
| Claude Opus 4.8 | $5 / $25 | $0.63 | $3.00 | 高難易度のコーディングや信頼性を求める際のプレミアムな選択肢。 |
| GPT-5.5 | 標準$5 / $30、272K超$10 / $45 | $0.65 | $5.90 | モデルのツール使用能力や効率がプレミアム分を補える場合に使用。 |
| GPT-5.5 Pro | $30 / $180 | $3.90 | $18.60 | 予算が別枠の最難関タスクに限定。 |
評価のポイント:M3はリストの中で最も安いテキストモデルではありません。テキストのみで大量処理を行うならDeepSeek V4 Flashが勝利します。しかしM3のコスト優位性は、画像・動画入力と長コンテキスト、エージェント能力を、GPT-5.5やClaude Opus 4.8を遥かに下回る価格帯で提供する点にあります。
500K入力・20K出力のエージェントタスクにおいて、M3はClaude Opus 4.8より約17倍、GPT-5.5(長コンテキスト適用時)より約34倍安価です。月次規模で見ると、1,000万入力・100万出力のコストは、M3で約USD4.20、DeepSeek V4 Flashで約USD1.68、Claude Opus 4.8で約USD75となります。
我々の推奨: 高価なモデルは「その対価に見合うだけの成果を出せるか」を基準に選んでください。GPT-5.5やOpusが1回で完了するタスクにM3が3回の再試行と人間による修正を要するなら、安い呼び出しは結局高くつきます。長コンテキスト・マルチモーダル分析、リポジトリ単位のトリアージ、スクリーンショットを伴うサポート自動化などでM3が品質要件を満たせるなら、単なる物珍しいモデルではなく、重要なルーティング候補になります。
ベンチマークはベンダーのデータとして読む
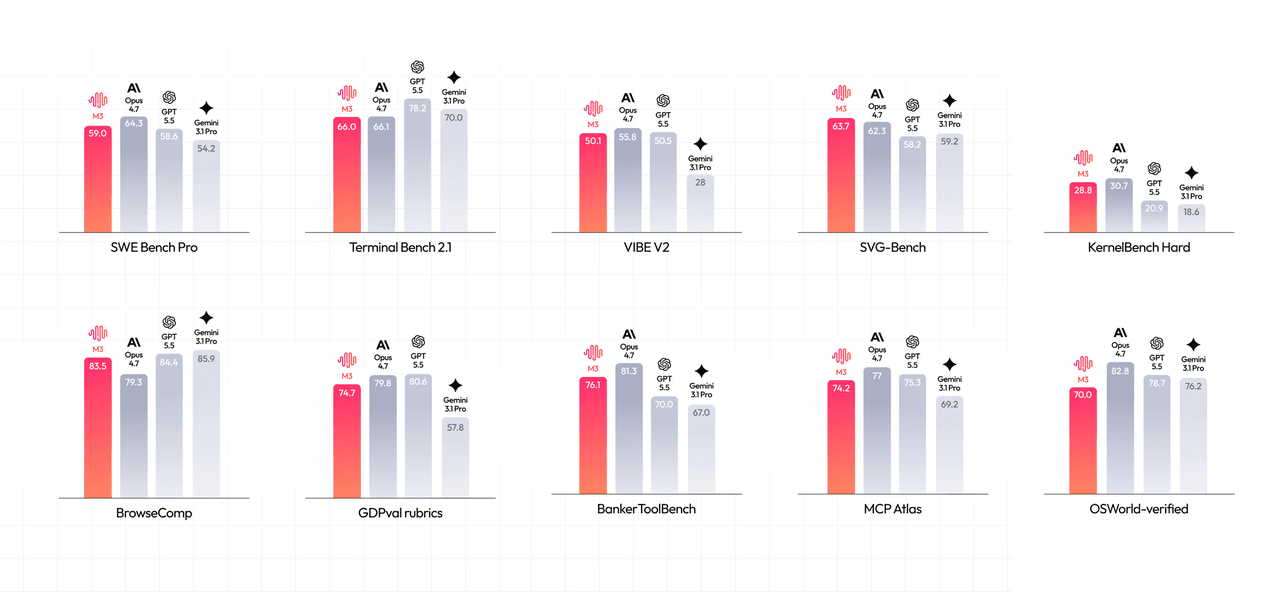
MiniMaxはコーディングおよびエージェントタスクで強力なスコアを報告しています:
- SWE-Bench Pro: 59.0%
- Terminal-Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8%
- MCP-Atlas: 74.2%
- BrowseComp: 83.5 (Opus 4.7は79.3)
注意点として、上記比較でMiniMaxはOpus 4.7を対象にしていますが、M3発表の4日前にOpus 4.8がリリースされています。ローンチ時点で既に旧バージョンと比較されている点は、今後の大きな論点(後述)を先取りしています。
MiniMaxは、自社のベンチマークにおいて多くのタスクで特定の足場(scaffolding)を利用しています。スコアをそのまま採用する前に、必ず自社のコード、ドキュメント、プロンプト、レイテンシ目標、予算で再検証してください。
M3を既存モデルと比較評価する方法
M3は「デフォルト」ではなく「評価候補」として扱ってください。100万トークンのウィンドウは、不要なファイルや古いログで埋め尽くされると、モデルのアーキテクチャの悪さを隠してしまう可能性があります。
GPT-5.5、Claude Opus 4.8、Qwen3.7、DeepSeek-V4、そしてM3に対して同じテストセットを実行してください。プロバイダーの評判ではなく、タスク単位で結果を比較します。
以下の6項目から開始してください:
- フルリポジトリコーディング: 同じイシュー、リポジトリ範囲、ツールアクセス、タイムアウトを設定する。パッチの品質、テスト通過率、変更量をスコアリング。
- 長コンテキスト検索: コンテキストの最初・中盤・最後に重要な詳細を配置。似たようなダミーデータも混ぜる。単なるフレーズ一致ではなく、正しいインスタンスを取得できるか確認。
- ツールループの持続性: 30回、60回、100回以上のツール呼び出しが必要なタスクを実行。計画の安定性、繰り返し、制約の忘却、タスク完了前に止まらないかを確認。
- 視覚エージェントワーク: サポートチケットとスクリーンショット、論文とグラフ、製品スペックとUIキャプチャを与える。視覚能力が低い経路については、別モデルへの受け渡しコストを測定。
- 実際のコンテキストでのレイテンシ: 128K、512K、1Mトークンでの最初のトークン生成時間および合計時間を比較。レイテンシデータなしで100万ウィンドウを信用しないこと。
- タスク完了あたりのコスト: 再試行やツール呼び出しを含めた総コストを測定。
これが多くのチームがモデル選定で失敗する箇所です。彼らは「どのモデルが最高のローンチベンチマークを持っているか」を尋ねますが、生産上の問いは「どのモデルが製品の品質・レイテンシ・コスト許容範囲内でこのワークフローを完了できるか」という狭いものです。
MSAがいかに長コンテキストを利用可能にしているか
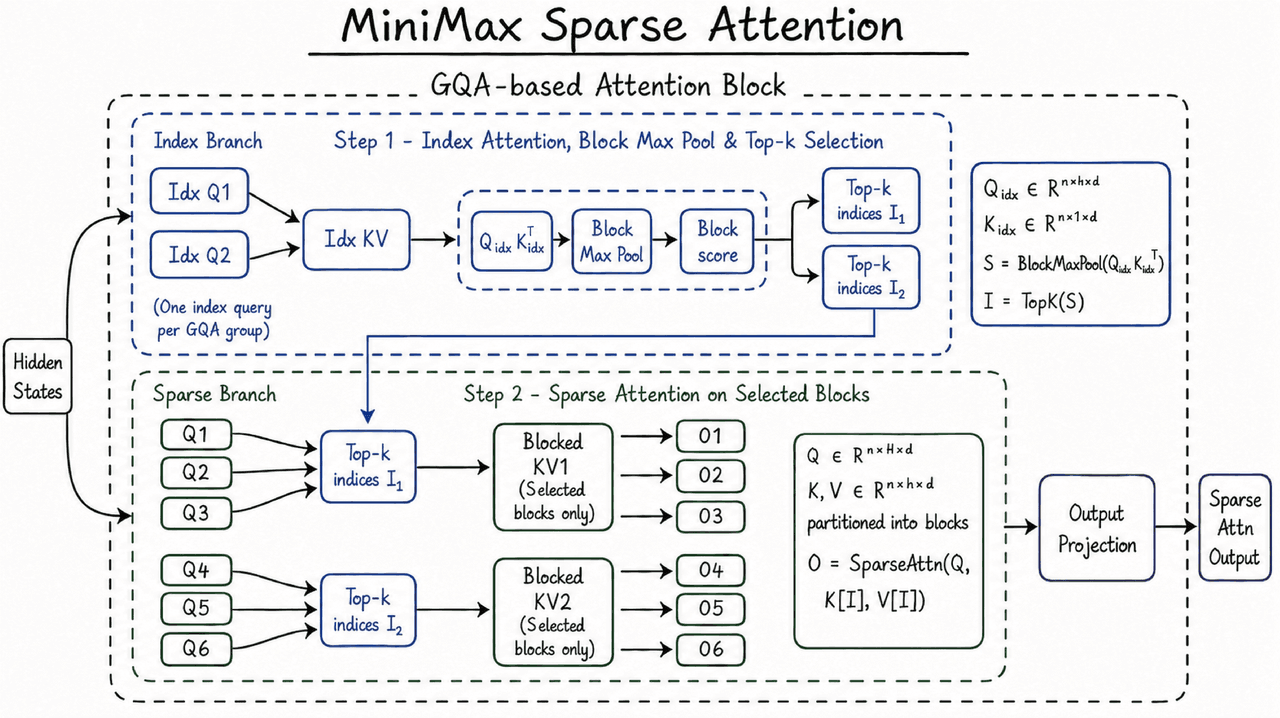
M3のコンテキストウィンドウはMiniMax Sparse Attention (MSA) に依存しています。
通常のアテンションは各トークンが他の全トークンにアテンションを向けますが、計算量はシーケンス長の2乗で増加します。Sparse attentionは選択ステップを追加し、前のコンテキストの中で重要な部分のみにアテンションを集中させます。
MiniMaxによれば、MSAはKVキャッシュをブロック単位でパーティション化し、ブロックレベルで選択を行います。KVキャッシュは以前のトークンのキーと値のベクトルを保持しており、長コンテキスト推論においてメモリ帯域を最も消費します。「KV outer gather Q」という演算設計により、メモリへのアクセスは連続的に保たれます。
MiniMaxはこの設計が従来のFlash-Sparse-Attentionよりも4倍以上高速であり、アブレーションの大部分でフルアテンションと同等の性能を維持したと述べています。これは重要な主張です。なぜなら100万トークンのウィンドウも、チームがコスト的に使えなければ無価値だからです。DeepSeek V4も同様の理由でハイブリッドアテンションを採用しており、安価な長コンテキストはアーキテクチャ上のデフォルトになりつつあります。
大きなトレンド:モデルローンチはルーティングイベント化している
M3は孤立したリリースではなく、市場全体のパターンに沿ったものです。過去6週間で4つの100万トークンモデルがリリースされました:
- DeepSeek V4-Pro/Flash(4月24日)
- Qwen3.7-Max(5月20日)
- Claude Opus 4.8(5月28日)
- MiniMax M3(6月1日)
100万トークンはもはや差別化要因ではなく、必須条件となりました。モデルページに並ぶ headline feature(目玉機能)は今後も収束し続けるでしょう。
開発者が最適化すべきはモデルの優位性ではなく、それを取り巻く統合作業です。特定のプロバイダーに依存すると、メジャーリリースごとに移行プロジェクトが発生します。タスク、価格、レイテンシ、モダリティ、評価結果に応じてルーティングを行えば、メジャーリリースは単なるルーティングのアップデートになります。
勝者は1つのモデルを守り続けるチームではなく、M3を今日テストし、GPT-5.5や他のモデルと明日比較し、数字が示す通りにトラフィックを流せるチームです。
他のプロバイダーが模倣できないもの
プロバイダーは表面的な機能(長いコンテキスト、Sparse-attention、思考モード、ベンチマークページなど)を模倣できます。しかし、以下の部分は時間を要します:
- 実際の並行処理下での安定した長コンテキストサービング
- ノイズがある中での高い品質維持
- 多重ツール呼び出し後のエージェントの信頼性
- テキスト、画像、グラフ、動画を跨いだマルチモーダル整合性
- 顧客がウィンドウ全体を使った時の経済性
- プロダクション環境で信頼できる明確なモデルID、バージョン管理、フォールバック
ビルダーはこのギャップにこそ時間を割くべきです。「100万ウィンドウを宣伝できるか」だけでなく、「トークン75万番目の指示に従えるか」「レイテンシが許容範囲内か」を問うてください。
なぜAtlas Cloudで実行するのか
Atlas Cloudを使えば、300以上のLLM、画像、動画、音声モデルに単一のAPIキーでアクセスできます。モデルの性能差が収束し、目玉機能が似通ってくるほど、この利便性は重要になります。
M3を既存のスタックと対照して検証し、性能が出る場所にルーティングし、リリースが重なってもインフラの表面を安定させることができます。コンピュータ操作に長けたGPT-5.5、コーディングエージェントに強いClaude Opus 4.8、GUI操作に勝るQwen3.7-Plus、価格性能比の良いDeepSeek-V4を使い分け、M3が結果を変えるポイントで追加してください。
評価(evals)に基づき、常に最適解を選択しましょう。
[CTA - ビルダー向け: Atlas CloudでM3を実行 -> atlascloud.ai/models | APIキーを取得 -> console.atlascloud.ai]






