AIビデオAPIにおけるキャラクターの一貫性とは、顔の特徴、服装、プロポーションといったキャラクターの視覚的アイデンティティを、異なるショット間でも維持する能力を指します。いわゆる「プロンプトによるガチャ」に頼る時代は終わり、リファレンスアンカー(Reference Anchors)やファインチューニング済みのLoRAといった構造化されたAPI制約を活用することで、クリエイターは95%の視覚的連続性を保ったエピソードコンテンツを制作できるようになり、制作コストを最大80%削減しています。
長年にわたり、主人公の顔立ちや服装がフレームごとに不自然に変化する「キャラクターのドリフト(Character Drift)」現象は、AI動画を「不気味なミーム」の領域に留めてきました。この視覚的安定性の欠如こそが、AIを単なる短いクリップからプロフェッショナルなストーリーテリングへと昇華させるための最大の障壁でした。
現在、この問題は「永続性(Persistence)」によって解決されつつあります。業界は「プロンプトを投げて祈る」段階から、構造化された制作体制へと移行しました。Atlas Cloudのような統合プラットフォームは、高い一貫性を誇るAIビデオAPIへのゲートウェイを提供することで、ついにこの「アイデンティティの危機」を解消しました。
| 指標 | 2024年のパフォーマンス | 2026年のパフォーマンス |
|---|---|---|
| キャラクターのドリフト | 高い(顔の50%が変化) | 最小限(視覚的な変化が5%未満) |
| アイデンティティ設定 | 手動プロンプト | 自動リファレンスアンカリング |
| レンダリングモード | フレーム単位 | ステートフルな時間的整合性 |
これらのAIビデオAPIを習得することで、クリエイターは単に「プロンプトを入力する」だけでなく、デジタルシネマの新時代を演出(監督)する存在となりました。以下の技術が、AIを実験的なおもちゃからプロ仕様の映像エンジンへと変貌させました。
- Atlas Cloud:Seedance 2.0やKling 3.0といった最先端モデルを統合・管理できるプラットフォーム。単一のエンドポイントを通じて、シリーズ全体でキャラクターのアイデンティティを固定することが可能です。
- LTX Studio: マルチショットの一貫性とナラティブ(物語)制御のために特別に設計された統合プラットフォーム。
- カスタムComfyUIエンドポイント: クリエイターが特定のキャラクターアイデンティティ(LoRA)を潜在空間(latent space)に埋め込むことを可能にするモジュール式ワークフロー。
2026年のAPIはいかにして時間的整合性を解決しているか
チカチカと動く「夢の中のような」クリップから、安定したエピソードコンテンツへの移行は、AIビデオAPIがデータを処理する方法の根本的な変化によって支えられています。2026年現在、業界は単純なテキストプロンプトを超え、キャラクターのアイデンティティをランダムな生成物ではなく「永続的な変数」として扱う「ステートフル(Stateful)」なアーキテクチャを採用しています。
プロンプトを超えて:アイデンティティ・アンカリング
最新のAPIは、アイデンティティ・アンカリングを利用してキャラクターのドリフトを排除しています。「髭を生やした男性」といった基本的なテキストプロンプトを使用する代わりに、開発者は「ベースアイデンティティ」を使用します。これは通常、厳格なルールとして機能するシャープな写真や3Dヘッドモデルです。これにより、光やカメラアングルが変わっても、顔や骨格を維持したまま、すべてのフレームでオリジナルのキャラクターを再現することが可能です。

図: Image_0.pngは、単一の中立的な参照ポートレート(アンカー)が、どのようにAI APIに対し同一のアイデンティティ(特徴的な傷やイヤリングに注目)を維持させるかを示しています。これにより、パースペクティブ、照明、環境の変化を伴う多様かつ動的なシーンでも一貫性が保たれます。
LoRAとIP-Adapterの役割
「最先端(State-of-the-Art)」の一貫性を実現するために、技術パイプラインは以下の2つの重要なコンポーネントを活用しています。
- LoRA (Low-Rank Adaptation): 特殊な肌の質感や服装のパターンなど、キャラクター固有の美学を「ロック」する小規模なファインチューニング済みの重み付けレイヤーです。
- IP-Adapter: トレーニングを必要とするLoRAとは異なり、即座に「ゼロショット」でアイデンティティを注入できる技術です。
現在、最も安定したプロ向けワークフローでは「ハイブリッドスタック」が採用されています。
| コンポーネント | 技術的機能 | 一貫性の目標 |
|---|---|---|
| アイデンティティLoRA | 全体的な体型と雰囲気 | 70% |
| PuLID / IP-Adapter | 正確な顔立ちの固定 | 90% |
| ControlNet | 空間およびポーズの規制 | 95%+ |
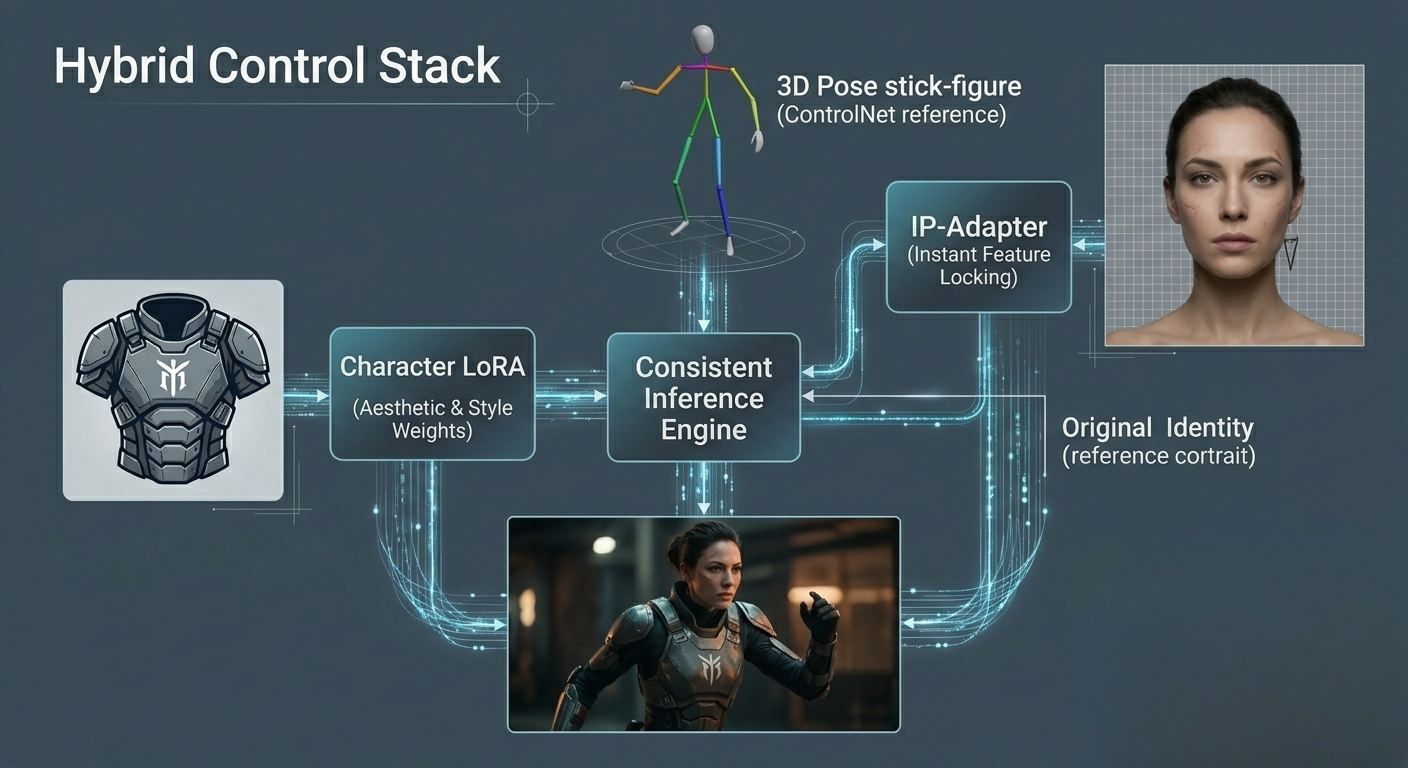
image_1.pngは、複数の制約がどのように適用されるかを視覚的に示しています。空間制御(ControlNet/ポーズ)、特定のキャラクター機能(画像をリファレンスにしたIP-Adapter)、専門的な美的重み付け(アーマー用のLoRA)が組み合わさり、新しい文脈の中で一貫性のあるキャラクターが生成されています。
シードの軌跡と潜在空間のロック
高付加価値な技術的ブレイクスルーとして、**潜在空間のロック(Latent Space Locking)**があります。すべてのAI生成は「シード(ランダムなノイズ)」から始まります。このノイズパターン、つまり「シードの軌跡」をフレーム間で一貫させることで、APIは顔が崩れるような変化を防ぎます。この手法により、ピクセルの背後にある数学的な処理がスムーズに進化し、キャラクターが視覚的な整合性を失うことなく複雑な環境の中を移動できるようになります。
これら3つの要素を組み合わせることで、クリエイターはついに、全エピソードを通じてメインキャラクターの顔立ちをシーズン終了まで完璧に維持した作品を制作できるようになりました。

Image_2.pngは比較画像です。上のタイムライン(標準のノイズ)では、顔の特徴や表情、アイデンティティが変化し、顔が「溶けて」います。下のタイムライン(ロックされたノイズ)では、APIが適用した数学的な制約のおかげで、顔がほぼ95%同一に保たれ、自然な動作(首の振りなど)のみが表現されています。
エピソード制作パイプラインの変革
キャラクターの一貫性を維持するAIビデオAPIの統合は、エピソードメディアの経済的状況を根本から変えました。ここでの最大の利点は、単なる「スピード」ではありません。誰もが質の高い物語を作れるようになったことです。これらのツールが視覚的な一貫性を保つという困難な作業を肩代わりすることで、個人クリエイターや小規模スタジオでも、ハリウッド映画に匹敵するクオリティの作品制作が可能になりました。
新しい制作のパラダイム
かつて、アニメーションシリーズで一貫性のあるキャラクターを作成するには、3Dモデリング、リギング、テクスチャマッピングに多大な初期投資が必要でした。制作途中でキャラクターのデザインが変更された場合、「技術的負債」が制作全体を停滞させることもありました。
現代のAIワークフローでは、こうした硬直的なアセットが、動的でファインチューニングされた重み付けデータに置き換わります。AIネイティブなパイプラインを利用する制作チームは、全体のオーバーヘッドを70〜90%削減できたと報告しています。
効率のベンチマーク:従来型 vs AIネイティブ
以下の表は、標準的な22分のエピソード制作における主要なパフォーマンス指標の比較です。
| 機能 | 従来型アニメ/CGI | AIビデオAPIワークフロー |
|---|---|---|
| キャラ設定 | 数ヶ月のモデリング/リギング | 2〜4時間のLoRAトレーニング |
| エピソード単価 | $100,000 – $1M+ | $500 – $5,000 |
| 反復速度 | 数週間(レンダリング時間) | 数分(推論時間) |
| 一貫性 | 完璧(手作業) | 高い(API制約により95%+) |
従来の手法はピクセル単位の精度では依然として優位ですが、「レンダリングより推論」を優先するモデルにより、クリエイターは数分で初稿を生成できます。この「時間の圧縮」により、スタジオは月ごとのコンテンツ公開数を42%増加させ、エピソードコンテンツをスローペースな贅沢品から、機敏で反応性の高いメディアへと変革しています。
ケーススタディ:「マイクロシリーズ」とバーチャルインフルエンサーの台頭
ランダムなクリップから本格的なストーリーテリングへの移行は、「AIマイクロシリーズ」という新しいトレンドを生み出しました。キャラクターを一貫して見せられる賢い動画ツールを使うことで、人々は従来のアニメに匹敵するクオリティの作品を作り出しています。しかも、それははるかに短い時間と少ない予算で実現可能です。

インディーズの革命:20日で20エピソードを制作
TikTokやYouTubeショートなどのプラットフォームで活躍するインディーズクリエイターは、もはやAI生成動画につきものだった「アイデンティティのドリフト」に縛られていません。Atlas Cloudのような統合プラットフォームを使ってSeedance 2.0やKling 3.0といったモデルを駆使し、クリエイターは「キャラクターID」を一度定義するだけで、それをシーズン全体で再利用できます。
この技術的飛躍により、以下のような連載形式の物語制作が可能になりました。
- 制作スピード: 従来CGIで12〜18ヶ月かかっていたものを、数週間で20エピソードのマイクロシリーズとしてリリースしています。
- エンゲージメント: バーチャルインフルエンサーは現在4.2%の市場シェアを獲得しており、平均エンゲージメント率は**5.67%**に達しています。これは人間のインフルエンサーの約3倍の数値です。
グローバルブランドの一貫性とAIスポークスパーソン
グローバル企業にとって、「アイデンティティの危機」はかつてブランド毀損のリスクでした。今日、企業はAIビデオAPIを活用し、多様な市場において一貫した「バーチャルスポークスパーソン」を維持しています。APIを通じて一元管理されたキャラクターを呼び出すことで、ブランドはスポークスパーソンの視覚的な同一性を保ちながら、多言語で話させたり、文化的に特定の環境に登場させたりといったコンテンツを生成できます。
| メリット | グローバルブランドへのインパクト |
|---|---|
| 視覚的忠実度 | 全地域でアイデンティティを95%+同一に維持。 |
| ローカライズ | ローカライズされたAPIコールによるリアルタイムのリップシンクと翻訳。 |
| リスク管理 | 人間の有名人アンバサダーと比較して、炎上リスクを0%に低減。 |
市場成長トレンド
この一貫性がもたらす経済的インパクトは非常に大きなものです。業界データは、ブランド支出がこれらの永続的なデジタルアセットへと根本的にシフトしていることを示しています。
- 市場規模: バーチャルインフルエンサー市場は2026年初頭に46億ドルに達しました。
- 効率: AIによる一貫性のあるキャラクターを採用した場合、投稿ごとの制作コストは人間のインフルエンサーを起用するより38%低く抑えられます。
- 採用率: **ブランドの92%**が、エピソードマーケティングのためにAIワークフローを導入、または積極的にテストしています。
キャラクターのアイデンティティを拡張可能なデジタル資産として扱うことで、AIビデオAPIは「おもちゃ」の段階を卒業し、効率的で新しいエピソード経済のバックボーンとなっています。
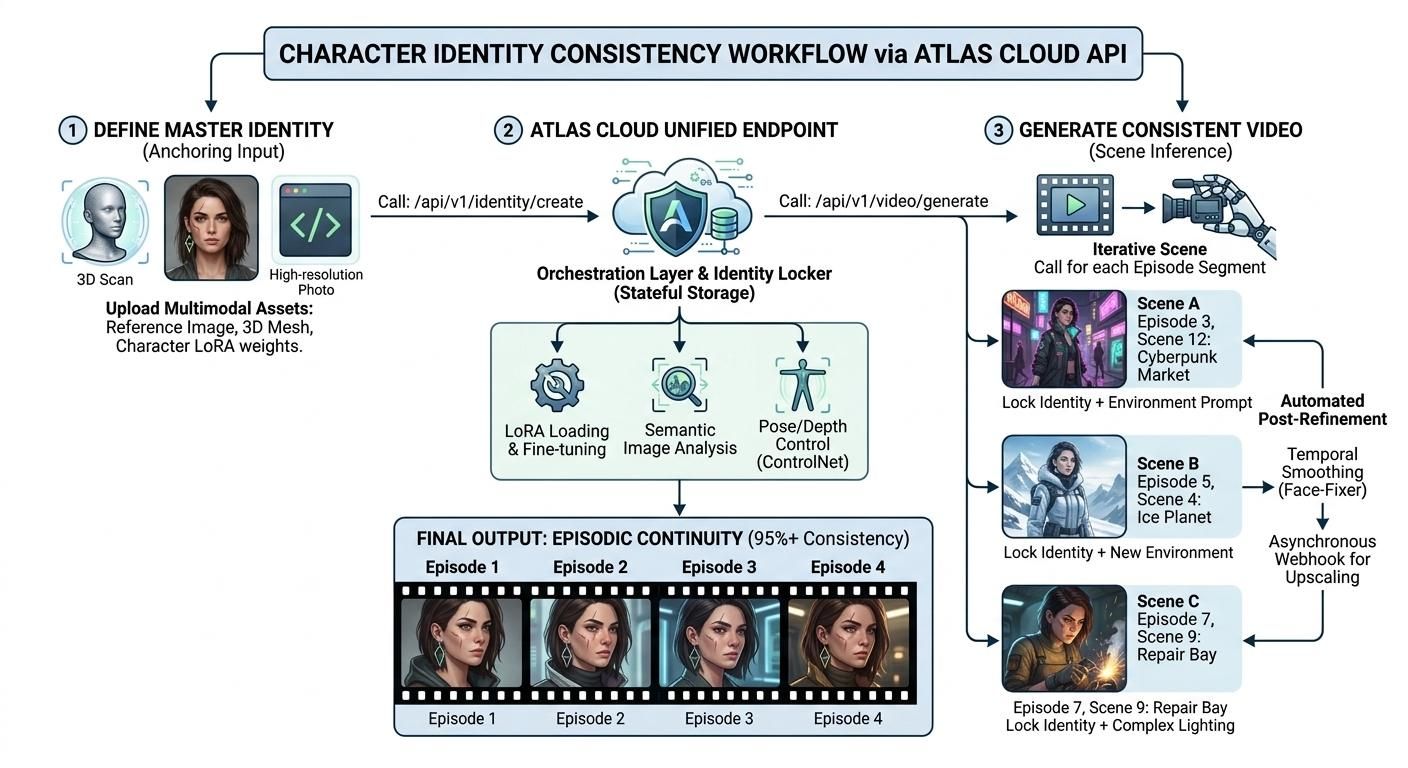
ワークフローに一貫性を持たせる方法
AI動画で遊ぶ段階から本格的な作品制作へ移行するには、新しいプランが必要です。整理され、拡張が容易なワークフローが必要です。業界標準は、マルチモーダル入力を使用して視覚的アイデンティティを固定する「ワンキーアクセス」アーキテクチャへと移行しています。統合されたAIビデオAPIを活用することで、クリエイターは手作業によるフレーム単位の編集なしで、多様なシーン間でもキャラクターの連続性を維持できます。
ステップ1:マスターアイデンティティの定義
一貫性のあるシリーズの基盤は「マスターアイデンティティ」です。単にテキストの説明を入力するのではなく、クリエイターは複数のファイルを組み合わせます。通常、鮮明な参照写真に、3DマップやキャラクターLoRAをペアリングします。この「アイデンティティアンカー」が事態を安定させ、顔、小さな傷、あるいはシャツの模様まで、あらゆるショットで全く同じ状態に保ちます。
ステップ2:Atlas Cloudによるオーケストレーション
モデルごとに別々のAPIキーや非互換なデータ形式を扱うのではなく、プロ向けのパイプラインではAtlas Cloudの統合APIが利用されています。このオーケストレーションレイヤーにより、同一のコードベースを維持したまま、モデルをシームレスに切り替えることが可能です。
例えば、クリエイターはAtlas Cloudを通じてSeedance 2.0の「ユニバーサルリファレンス」システムを呼び出し、15秒間の複雑なアクションシーケンスでキャラクターの顔を固定できます。もし特定のショットでKling 3.0の優れた流体モーションや、Veo 3.1のフォトリアルな映画的ライティングが必要な場合でも、開発者はAtlas Cloud環境内でモデルパラメータを切り替えるだけで済みます。
| ワークフローの段階 | ツール例 | 主な利点 |
|---|---|---|
| モデルの切り替え | Kling 3.0 ↔ Veo 3.1 | ショットの種類ごとにパフォーマンスを最適化 |
| アイデンティティ固定 | Seedance 2.0 Ref | 顔と服装の永続的な維持 |
| 統合 | Atlas Cloud SDK | 統合されたエンドポイント、キーの断片化なし |
seedance-2.0 image-to-video コード例:
plaintext1import requests 2import time 3 4# Step 1: Start video generation 5generate_url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6headers = { 7 "Content-Type": "application/json", 8 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 9} 10data = { 11 "model": "bytedance/seedance-2.0/image-to-video", # 必須。モデル名 12 "prompt": "A smooth, futuristic ship is floating slowly around a massive planet. You can see the planet’s bright clouds and glowing air from out in space. The background is full of stars and colorful gas clouds. The ship moves steadily along its path, looking like a big sci-fi movie scene. The lighting feels deep and real as the camera follows the ship.", # 動画の動きを記述するテキストプロンプト 13 "image": "https://static.atlascloud.ai/media/images/454eee7f1a05a0bf276afe2e056200ba.png", # 必須。最初のフレームの画像URL、Base64、またはアセット参照 (asset://<ASSET_ID>) 14 "last_image": "example_value", # 最後のフレームの画像URL、Base64、またはアセット参照 15 "duration": 5, # 動画の秒数 (4-15)、または -1 で自動選択 16 "resolution": "720p", # 動画解像度。オプション: 480p | 720p | 1080p 17 "ratio": "adaptive", # アスペクト比 18 "generate_audio": True, # 同期されたオーディオを生成するかどうか 19 "watermark": False, # 透かしを入れるかどうか 20 "return_last_frame": False, # 最後のフレームを別の画像として返すかどうか 21} 22 23generate_response = requests.post(generate_url, headers=headers, json=data) 24generate_result = generate_response.json() 25prediction_id = generate_result["data"]["id"] 26 27# Step 2: Poll for result 28poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 29 30def check_status(): 31 while True: 32 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 33 result = response.json() 34 35 if result["data"]["status"] in ["completed", "succeeded"]: 36 print("Generated video:", result["data"]["outputs"][0]) 37 return result["data"]["outputs"][0] 38 elif result["data"]["status"] == "failed": 39 raise Exception(result["data"]["error"] or "Generation failed") 40 else: 41 # 処理中、2秒待機 42 time.sleep(2) 43 44video_url = check_status()
ステップ3:生成後の調整

「4K放送品質」を実現するために、最終段階では自動ポストプロセッシングのブリッジを構築します。Atlas Cloudの非同期ウェブフックアーキテクチャを使用することで、1080pレンダリングが完了した瞬間に、システムが自動的に外部の拡張タスクをトリガーすることが可能です。
一般的な自動ポストプロセッシングのタスクには以下が含まれます:
- 時間的な平滑化: キャラクターの特徴における微細な揺らぎを排除。
- 外部4Kアップスケーリング: APIが出力した1080p映像を、特殊な超解像モデルで処理。
- オーディオビジュアル同期:Vidu Q3統合を使用し、キャラクターの動作に合わせて効果音を自動的にタイミング調整。
APIを活用したこの3ステップのプロセスにより、チームは視覚作業の85%を自動化できます。これにより、すべての一貫性を保ちながら、わずか数分で質の高い作品を制作することが可能になります。
今後の展望:「不気味の谷」は終わるのか?
2026年の後半に向けて、AIビデオAPIの進化は、事前にレンダリングされたエピソードコンテンツの枠を超え、「ライブアイデンティティ」のパラダイムへと移行しています。「不気味の谷」を生み出していた技術的障壁(微細なスタッターやライティングの不一致)は、リアルタイムのニューラルレンダリングによって解消されつつあります。
リアルタイム一貫動画への移行
次のフロンティアは、静的な生成からライブAIアバターへの移行です。これらのツールは将来的に100ms以下のレイテンシーで動作するようになり、リアルタイムの会話中でもキャラクターの容姿を完全に固定できるでしょう。これは物語の伝え方を一変させます。ライブ配信中にキャラクターと会話したり、番組内で視聴者が自分自身の選択を行ったりすることが可能になります。物語の結末が変化しても、キャラクターは常に完璧な外見を維持し続けるのです。
倫理的なレイヤー:アイデンティティ権の保護
キャラクター、あるいは人間を完璧に複製できるということは、大きな法的課題を伴います。業界は現在、無許可のデジタルクローンを防ぐための「アイデンティティ権」のフレームワークを構築中です。2026年には、以下のような取り組みが見られます。
- オンチェーン・アイデンティティ認証: ブロックチェーンを使用してキャラクター固有の重み付けプロファイルを「署名」する。
- ウォーターマーク標準: 人間の俳優と合成俳優を識別するため、すべてのAPI生成アイデンティティにSynthID形式の透かしを義務付ける。
FAQ
AI動画におけるキャラクターの一貫性とは何ですか?
キャラクターの一貫性とは、AIモデルが被写体を正確に同じ見栄えで保つ能力です。これにより、異なる角度や設定の間でも、顔、髪、服が同じ状態を維持します。本格的な番組制作において、この機能が断片的なクリップを、繋がりを持ったひとつの物語へと変える役割を果たします。
どのAIビデオAPIがキャラクターの一貫性をサポートしていますか?
多くのモデルが市場に参入していますが、APIを通じて堅牢な一貫性制御を提供する現在のリーダーは以下の通りです。
- LTX-Studio: 映画のような「シーン間」のキャラクター固定に注力。
- Magic Hour: 一貫したキャラクターアニメーションとフェイススワップに重点を置くクリエイターに人気の選択肢。
- Atlas Cloud: 単一の一貫性重視エンドポイントを通じて、複数のモデルをオーケストレーションする統合プラットフォーム。
キャラクターの一貫性に自分自身の顔を使うことはできますか?
はい、可能です。「キャラクターカメオ」機能やIP-Adapterを使用することで、あなた自身の参照ポートレートをアップロードできます。APIがあなたの「顔の潜在的な重み」を抽出し、それをデジタル主人公に適用することで、エピソード全体を通じて一貫してあなた自身が主役であり続けることを可能にします。






