MiniMax LLM Models
As a premier suite of Large Language Models (LLMs) developed by MiniMax AI, MiniMax is engineered to redefine real-world productivity through cutting-edge artificial intelligence. The ecosystem features MiniMax M2.5, which is purpose-built for high-efficiency professional environments, and MiniMax M2.1, a model that offers significantly enhanced multi-language programming capabilities to master complex, large-scale technical tasks. By achieving SOTA performance in coding, agentic tool use, intelligent search, and office workflow automation, MiniMax empowers users to streamline a wide range of economically valuable operations with unparalleled precision and reliability.
Poznaj Wiodące Modele
Atlas Cloud zapewnia najnowsze, wiodące w branży modele kreatywne.
Co Wyróżnia MiniMax LLM Models
Atlas Cloud zapewnia najnowsze, wiodące w branży modele kreatywne.
Rozumowanie na skalę pionierską
Najnowocześniejsze modele językowe stworzone do głębokiego wnioskowania, rozwiązywania złożonych problemów i planowania wieloetapowego.
Rozumienie ultra-długiego kontekstu
Mechanizm uwagi w stylu Lightning i zoptymalizowana architektura umożliwiają modelom MiniMax przetwarzanie i zachowywanie długich kontekstów,
Efektywna kosztowo wydajność MoE
Architektury typu Mixture-of-Experts zapewniają wysoką inteligencję, niskie opóźnienia oraz znacznie korzystniejszy stosunek ceny do wydajności.
Wszechstronna rodzina modeli
Od potężnych modeli ogólnego przeznaczenia po warianty zoptymalizowane pod kątem kodowania i agentów.
Niezawodność klasy korporacyjnej
Stabilna, skalowalna infrastruktura z monitoringiem i zabezpieczeniami do użytku produkcyjnego.
Otwarty i przyjazny dla deweloperów
Rozbudowane interfejsy API, pakiety SDK i wydania typu open-weight zapewniają twórcom elastyczność w zakresie integracji, dostrajania (fine-tuning) lub samodzielnego hostowania.
Prędkość szczytowa
Najniższy koszt
| Model | Opis |
|---|---|
| MiniMax M2.5 | MiniMax M2.5 to flagowy model LLM zoptymalizowany pod kątem rzeczywistej produktywności, integrujący zaawansowane architektury wnioskowania z szerokimi możliwościami przetwarzania kontekstu 196,61K; szczycąc się wydajnością SOTA w automatyzacji biurowej i inteligentnym wyszukiwaniu, służy jako wysokowydajny silnik do zarządzania zadaniami o wartości ekonomicznej i złożonym wnioskowaniem ogólnym w środowiskach profesjonalnych. |
| MiniMax M2.1 | MiniMax M2.1 to wysokowydajny model LLM dostosowany do złożonych wyzwań technicznych, integrujący znacznie ulepszone programowanie wielojęzyczne z solidnym przetwarzaniem kontekstu 196.61K; szczycąc się wyjątkową precyzją w użyciu narzędzi agentowych (agentic tool use), służy jako fundament do budowania zaawansowanych Agents harmonogramowania zadań i rozwiązywania zawiłych problemów inżynieryjnych na dużą skalę. |
| MiniMax M2 | MiniMax M2 to ogólnego przeznaczenia model LLM typu SOTA, integrujący wysoce wydajne moduły wnioskowania z szerokimi możliwościami przetwarzania kontekstu 196,61K; szczycący się konkurencyjną wszechstronnością w kodowaniu, wyszukiwaniu i profesjonalnych przepływach pracy, służy jako niezawodny fundament dla codziennych operacji przedsiębiorstwa wymagających płynnej integracji wieloetapowego wykonywania zadań. |
Nowe funkcje MiniMax LLM Models + Showcase
Połączenie zaawansowanych modeli z platformą Atlas Cloud z akceleracją GPU zapewnia niezrównaną szybkość, skalowalność i kreatywną kontrolę w generowaniu obrazów i wideo.
Zaawansowane programowanie i planowanie agentów przy użyciu MiniMax M2.5
MiniMax M2.5 obsługuje ponad 10 języków programowania, w tym Rust, Go i Python, ułatwiając kompleksowy rozwój full-stack na platformach internetowych, mobilnych i desktopowych. Dzięki integracji głębokiej wiedzy branżowej w zakresie profesjonalnego formatowania dokumentów i modelowania finansowego, umożliwia płynne przejście od projektowania architektury systemu do testowania końcowych produktów. Jest to ostateczne rozwiązanie dla złożonej inżynierii oprogramowania i kluczowych przepływów pracy w zakresie produktywności biurowej.
Szybka reakcja i efektywność podejmowania decyzji o zadaniach przy użyciu MiniMax M2.5
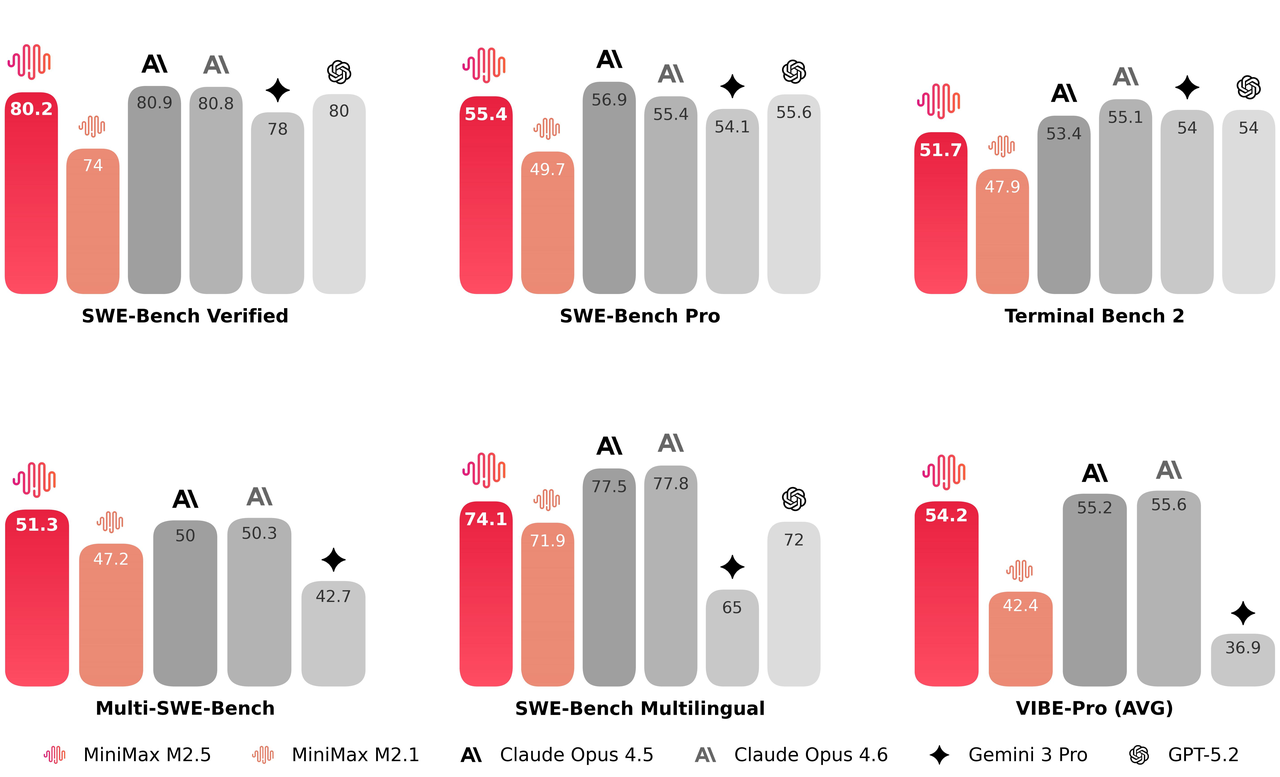
Architektura M2.5 osiąga 37% wzrost prędkości w wykonywaniu zadań typu end-to-end, znacząco skracając czas trwania złożonych zadań z 31,3 do 22,8 minut w teście SWE-bench. Dzięki optymalizacji logiki dekompozycji zadań, model wymaga o 20% mniej tokenów i rund wyszukiwania, aby osiągnąć cele w benchmarkach takich jak BrowseComp. Oferuje usprawnione rozwiązanie do szybkiego podejmowania decyzji, eliminując jednocześnie zbędny narzut obliczeniowy.
Architektura ewolucyjna poprzez uczenie przez wzmacnianie na dużą skalę przy użyciu MiniMax M2.5
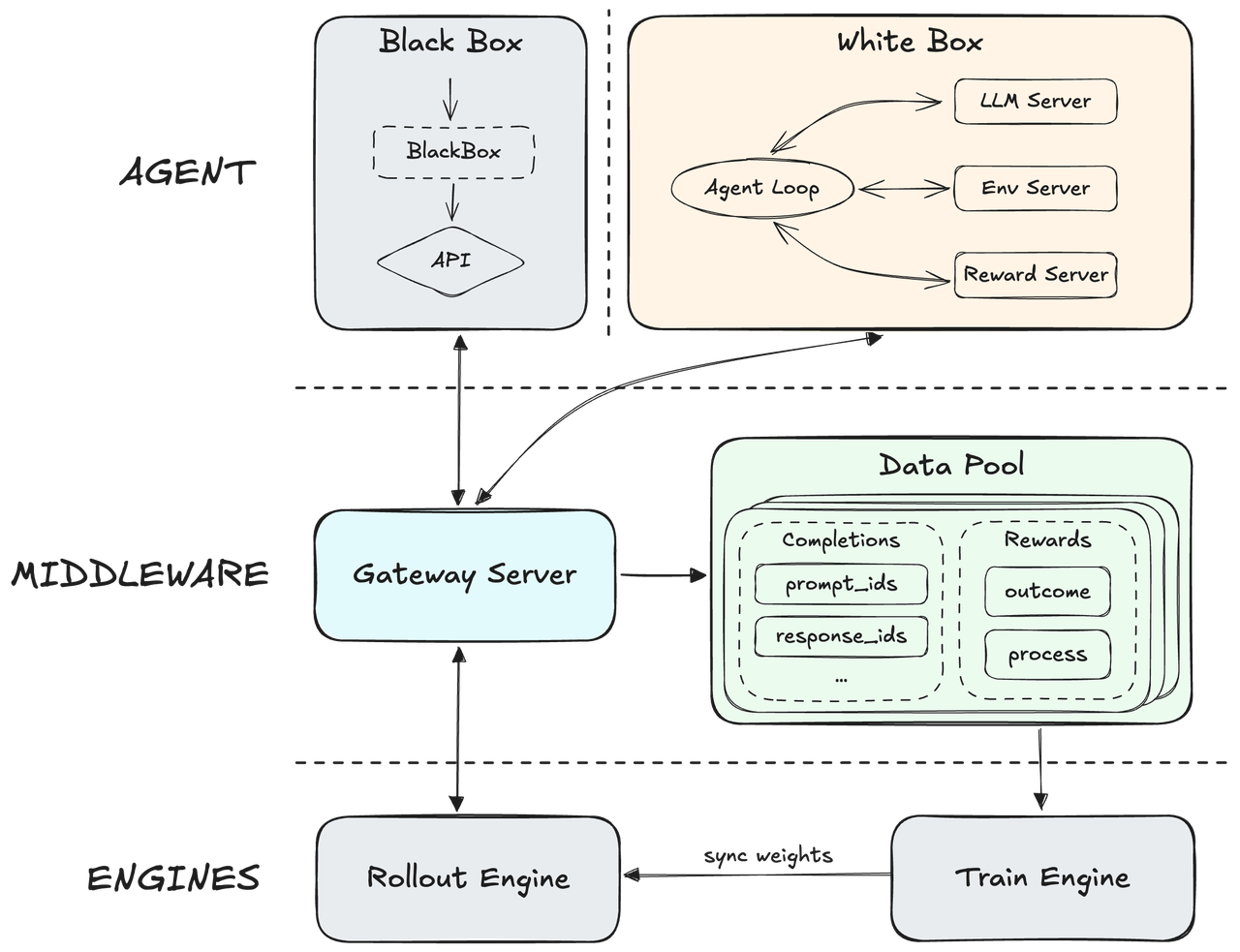
Zbudowany na natywnym szkielecie Agent RL, MiniMax oddziela swój główny silnik od rusztowania agenta, aby generalizować działanie w setkach tysięcy różnorodnych środowisk rzeczywistych. Wykorzystuje zaawansowany mechanizm nagradzania procesów, który używa informacji zwrotnych z wykonania w czasie rzeczywistym do udoskonalania ścieżek rozumowania i zapewnienia elitarnej jakości wyników. Tworzy to wysoce adaptacyjny system zdolny do utrzymania najwyższej dokładności przy jednoczesnej maksymalizacji ogólnej szybkości reakcji operacyjnej.
Co Możesz Zrobić z MiniMax LLM Models
Odkryj praktyczne przypadki użycia i przepływy pracy, które możesz zbudować z tą rodziną modeli — od tworzenia treści i automatyzacji po aplikacje klasy produkcyjnej.
Debugowanie Full-Stack gotowe do produkcji z MiniMax M2.5
MiniMax M2.5 działa jak starszy architekt techniczny, śledząc błędy logiczne w interfejsach API zaplecza, bazach danych i frameworkach frontendowych, takich jak React czy Swift. Zamiast prostych fragmentów kodu, refaktoryzuje całe moduły, aby zapewnić kompatybilność w całym systemie. Idealne do szybkiego prototypowania, API obsługuje wszystko, od konfiguracji środowiska po testowanie przypadków brzegowych i modernizację przestarzałego kodu dla systemów korporacyjnych.
Profesjonalne modelowanie finansowe i raportowanie przy użyciu MiniMax M2.5
Dla analityków wymagających absolutnej precyzji, API automatyzuje złożone modelowanie finansowe w Excelu i generuje gotowe do publikacji raporty badawcze zgodnie z profesjonalnymi ramami inwestycyjnymi. Interpretuje surowe dane, aby tworzyć logikę kontroli ryzyka i profesjonalne prezentacje ze standaryzowanym formatowaniem. Jest to rozwiązanie idealne dla środowisk doradczych i bankowych o wysokim ryzyku, gdzie dokładność i przestrzeganie formalnych standardów sprawozdawczości są nienegocjowalne.
Autonomiczne wieloetapowe badania internetowe z MiniMax M2.5
MiniMax M2.5 wykonuje złożone, wieloetapowe zadania wyszukiwania, aby syntezować różnorodne informacje internetowe w spójne streszczenia dla kadry zarządzającej. Dzięki inteligentnemu rozkładaniu szerokich zapytań i przeglądaniu z minimalną redundancją tokenów, unika błędnego koła w rozumowaniu, dostarczając zweryfikowane fakty. Jest to potężne narzędzie dla badaczy rynku i zespołów strategicznych potrzebujących dogłębnych informacji wywiadowczych bez ręcznego filtrowania setek źródeł.
Porównanie Modeli
Zobacz, jak wypadają modele różnych dostawców — porównaj wydajność, ceny i unikalne mocne strony, aby podjąć świadomą decyzję.
| Model | Kontekst | Maksymalne wyjście | Wejście | Pozycjonowanie |
|---|---|---|---|---|
| MiniMax M2.5 | 196.61K | 196.61K | Tekst | Najnowocześniejsze programowanie agentowe |
| MiniMax M2 | 196.61K | 196.61K | Tekst | Model o wysokiej wydajności |
| MiniMax M2 | 196.61K | 196.61K | Tekst | Flagowy ogólny |
| GLM-5 | 202.75K | 202.75K | Tekst | Flagowy model fundamentowy |
| DeepSeek V3.2 | 163.84K | 163.84K | Tekst | Flagowy Ogólny |
How to Use MiniMax LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Dlaczego Używać MiniMax LLM Models na Atlas Cloud
Połączenie zaawansowanych modeli MiniMax LLM Models z platformą GPU-akcelerowaną Atlas Cloud zapewnia niezrównaną wydajność, skalowalność i doświadczenie deweloperskie.
Wydajność i Elastyczność
Niska Latencja:
Inferencja zoptymalizowana pod GPU dla rozumowania w czasie rzeczywistym.
Zunifikowane API:
Uruchamiaj MiniMax LLM Models, GPT, Gemini i DeepSeek za pomocą jednej integracji.
Przejrzysta Wycena:
Przewidywalne rozliczenia za token z opcjami serverless.
Przedsiębiorstwo i Skala
Doświadczenie Dewelopera:
SDK, analityka, narzędzia dostrajania i szablony.
Niezawodność:
99,99% dostępności, RBAC i logowanie gotowe na zgodność.
Bezpieczeństwo i Zgodność:
SOC 2 Type II, zgodność z HIPAA, suwerenność danych w USA.
Często Zadawane Pytania o MiniMax LLM Models
Oferujemy trzy główne wersje: MiniMax M2.5 (flagowy model do produktywności biurowej i wyszukiwania), MiniMax M2.1 (ulepszony do kodowania i złożonej logiki) oraz MiniMax M2 (zrównoważony model ogólnego przeznaczenia).
Seria MiniMax M2 jednolicie obsługuje ultra-długi kontekst 196,61K, co pozwala na przetwarzanie setek stron dokumentacji technicznej lub ogromnych baz kodu inżynierskiego w jednym zapytaniu.
W testach typu end-to-end SWE-bench model M2.5 skrócił czas przetwarzania złożonych zadań z 31,3 minuty do 22,8 minuty, co oznacza wzrost ogólnej szybkości wykonywania zadań o 37%.
Poznaj Więcej Rodzin
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
Grok-Imagine Models
Grok Imagine Image Quality is xAI's latest AI image generation model, delivering studio-grade visuals with up to 2K resolution and razor-sharp detail. It offers best-in-class text rendering across multiple languages, photorealistic outputs with natural lighting, rich textures, and believable physics, plus tighter prompt following and image editing with reference inputs for precise creative control. Ideal for hero images, ad creatives, product renders, and brand-grade visuals.
Gemini Omni
Gemini Omni (by Google DeepMind) is a video generation and editing model launched on May 20, 2026 at Google I/O that redefines the standard for "reasoning-driven creation," built specifically to solve the core challenge of AI video: making output that actually understands what you mean, not just what you type. It fuses Gemini's reasoning engine with generative capability, accepting any mix of images, text, video, and audio to produce consistent, knowledge-grounded output. Unlike models that start from scratch each time, Omni lets you edit through natural conversation — swapping objects, rewriting scenes, shifting styles — while keeping physics, characters, and continuity intact across every turn.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.


