O Google lançou o Gemini Omni no I/O 2026 — um modelo multimodal que edita vídeos através de conversas em linguagem natural, sem a necessidade de linhas do tempo ou keyframes. As demos virais (escultura de bolhas, espelho líquido, violinista) provam a verdadeira mudança: não se trata apenas de texto para vídeo, mas de texto para editar o vídeo que você já tem. Este é o momento "câmera do iPhone" para a criação de vídeo. Fala, edição de áudio e um plano Pro estão notavelmente ausentes — e isso é proposital.
É 1 da manhã. Você está há quatro horas editando um clipe de 30 segundos. Seu arquivo de projeto tem 47 camadas. Você arrastou keyframes até seu pulso doer. O cliente acaba de enviar uma mensagem: "podemos tentar com uma iluminação mais quente?" E você, o profissional, está prestes a recomeçar.
Esse era o trabalho. Esse era o trabalho.
Em 19 de maio de 2026, o Google discretamente o aposentou.
No I/O 2026, a empresa anunciou o Gemini Omni — um modelo multimodal que transforma a edição de vídeo em algo que a maioria de nós pensava estar a uma década de distância: uma conversa normal.
A Promessa Principal: Pare de Operar o Vídeo. Comece a Conversar com Ele.
Aqui está todo o conceito em uma frase: você não opera mais o vídeo — você diz a ele o que quer.
O anúncio do Google coloca isso sem rodeios: "Cada instrução se baseia na anterior. Seus personagens permanecem consistentes, a física se mantém e a cena lembra o que veio antes."
Isso não é uma atualização do Veo. A página de produto do Google DeepMind oferece uma definição mais clara: "Pense no Gemini Omni como o Nano Banana, mas para vídeo." No ano passado, o Nano Banana tornou a edição de fotos tão fácil quanto digitar o que você queria. Agora, o Omni faz o mesmo para imagens em movimento.
O primeiro modelo da família — Gemini Omni Flash — já está disponível no aplicativo Gemini, no Google Flow e no YouTube Shorts.
E aqui está a frase que deve reformular como você pensa sobre toda essa categoria: na entrevista do TechCrunch com a equipe do DeepMind, o engenheiro de pesquisa Gabe Barth-Maron descreveu o que as pessoas estão criando com o Omni como "memes personalizados."
Essa é a tese. A criação de vídeo acaba de migrar do artesanato para a expressão — a mesma migração que a fotografia fez quando os iPhones acabaram com o domínio das DSLRs.
As Demos Que Estão Quebrando o Twitter
Você pode ler textos de marketing o dia todo. O que vendeu este lançamento foram as demos. Três estão em toda parte agora:
- A escultura de bolhas. Forneça ao Omni um clipe de uma escultura de pedra, digite "Faça a escultura de bolhas" e a renderização seguinte mantém a mesma composição, a mesma iluminação, as mesmas sombras — mas a escultura agora é de sabão translúcido, captando a luz ambiente.
- O espelho líquido. Uma mão toca um espelho; o prompt pede ao Omni para "fazer o espelho ondular lindamente como líquido, e o braço da pessoa se transforma em material espelhado refletivo."Como documentou o Windows Report, as ondulações se propagam fisicamente para fora e o cromo do braço reflete a sala real.
- As edições encadeadas. A demo do violinista do Google mostra um único sujeito em três rodadas: palco → ambiente transportado → ângulo de câmera sobre o ombro. Três edições. Uma pessoa. Rosto, postura, pegada do instrumento — tudo consistente.

Isso não é texto para vídeo. É texto para editar o vídeo que você já tem. A distinção parece pequena. Ela muda tudo.
Por Que os Criadores Estão Perdendo a Cabeça
A razão pela qual isso tem mais impacto do que outros lançamentos de modelos é simples: o Omni acaba com o pior ciclo da geração de vídeo.
Ciclo antigo: gerar → odiar → reescrever todo o prompt → esperar 90 segundos → continuar ruim → repetir.
Novo ciclo: gerar → "mude a iluminação para a hora dourada" → pronto → "agora deixe mais lento o movimento de câmera" → pronto.
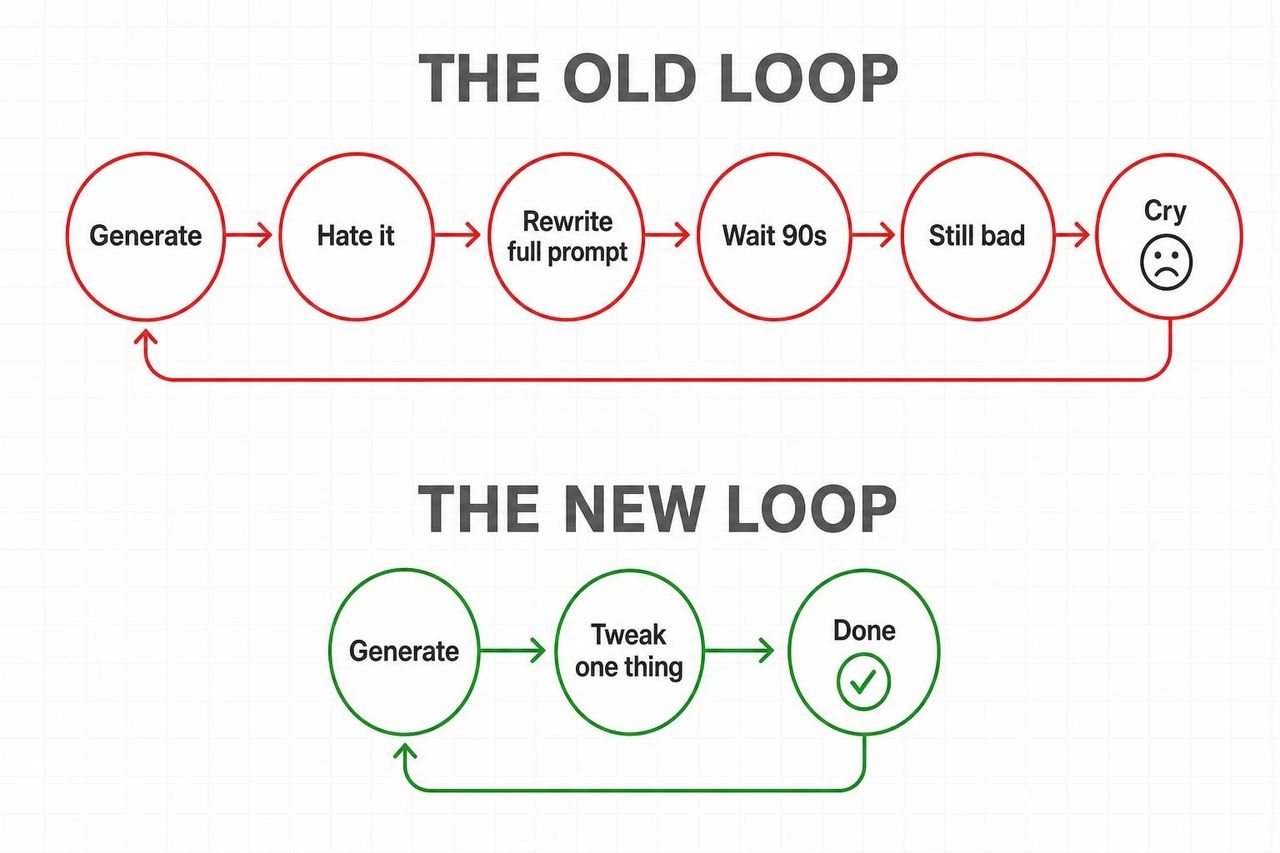
O Android Central não suavizou o veredito: "O Gemini Omni pode fazer os aplicativos tradicionais de edição de vídeo parecerem antigos." O TechRadar destacou o mesmo ponto com mais nuances, observando que o movimento agora permanece coerente entre as edições, em vez de resetar a cada prompt.
Os desenvolvedores já estão se movimentando. No fórum V2EX, um desenvolvedor chinês testou no dia do lançamento e postou: "modificação de objetos dentro de um vídeo baseada em chat — esse tipo de interação é claramente a direção futura. Velocidade e consistência superaram minhas expectativas." No X, o imunologista e comentarista de IA Dr. Derya Unutmaz tuitou poucos minutos após a apresentação: "Uau! O Google DeepMind acaba de lançar uma nova IA multimodal incrível chamada Gemini Omni. Os vídeos parecem muito bons! Preciso testar ASAP!"
Quando a intelligentsia de IA do Twitter e os fóruns de desenvolvimento chineses chegam à mesma conclusão em poucas horas, você está diante de uma verdadeira inflexão.
Onde o Google Está Contendo o Jogo
Seria irresponsável escrever uma carta de amor sem os asteriscos.

O Engadget apontou o elefante na sala: "o principal problema com o Veo 3.1 e outros aplicativos geradores de vídeo é que o vídeo tem um visual de 'vale da estranheza' (uncanny valley) e muitas vezes é detestado pelos usuários finais. Será interessante ver se a qualidade da saída corresponde às promessas entusiasmadas do Google."
E os testes práticos do DataCamp já revelaram um erro físico real — uma catapulta que lançou sua carga para trás. O avaliador observou que o modelo ainda carece de pontuações de benchmark publicadas, portanto, uma verificação independente levará semanas.
Há também uma omissão deliberada: edição de fala e áudio dentro de vídeos existentes. Como o próprio Google reconheceu, a empresa "ainda está trabalhando para testar isso e entender melhor como podemos levar essa capacidade aos usuários de forma responsável." Tradução: o risco de deepfake é real e eles estão mantendo a capacidade mais perigosa sob sigilo.
Todo clipe do Omni vem com a marca d'água invisível SynthID do Google, além das Credenciais de Conteúdo C2PA — procedência verificável dentro do aplicativo Gemini, Chrome e Search. Isso não é opcional. Isso é o básico agora.
O Que Isso Significa na Prática Para o Seu Fluxo de Trabalho
Descarte o hype e o que resta é algo genuinamente novo:
- A ferramenta é a conversa. Sem linha do tempo, sem camadas, sem keyframes. Apenas palavras.
- O ciclo de feedback colapsa. O que costumava levar 90 segundos de regeneração torna-se ajustes de 10 segundos.
- O fosso profissional diminui. Quando qualquer pessoa com bom gosto pode iterar em um vídeo tão rápido quanto em uma mensagem no Slack, o gargalo muda da execução para as ideias.
Para equipes de marketing, criadores independentes, educadores, qualquer pessoa que já precisou de "apenas um clipe rápido de 10 segundos" — este é o ponto de inflexão. Não porque o modelo é perfeito. Mas porque o padrão de interação finalmente está correto.
A futura edição de vídeo não precisará de software. Precisará de vocabulário.
Uma API Unificada para Geração de Vídeo de Produção
Enquanto o Google lança o Gemini Omni Flash dentro do aplicativo Gemini e do Google Flow para usuários finais, desenvolvedores e equipes de produto que desejam incorporar o mesmo motor de vídeo multimodal em seus próprios fluxos de trabalho precisam de uma camada de API estável e previsível.
O Atlas Cloud oferece o Gemini Omni Flash através de uma API unificada e compatível com OpenAI, juntamente com mais de 300 outros modelos de imagem, vídeo e LLM — para que você possa integrar o modelo multimodal nativo do Google sem precisar lidar com contas de fornecedores, portais de faturamento ou SDKs separados.
Ambas as variantes do Gemini Omni Flash estão disponíveis no Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Ideal Para | Entradas | Resolução | Duração | Preço Inicial |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Desenvolvedor) | Geração cinematográfica pura via prompt | Texto (até 20.000 caracteres) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
| Gemini Omni Flash Image-to-Video (Desenvolvedor) | Vídeo consistente com o sujeito a partir de referências reais | Texto + até 7 imagens de referência | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
Início Rápido — Gere um vídeo com Gemini Omni Flash em 5 linhas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
A API retorna um ID de previsão imediatamente — consulte /api/v1/model/prediction/{id} para obter a URL do MP4 renderizado. O esquema completo, amostras de código em 7 linguagens e um Playground sem código estão disponíveis nas páginas dos modelos vinculadas acima.
Uma Última Coisa — Para Quem Realmente Está Construindo Com Isso
Aqui está a realidade desconfortável por trás de cada lançamento de modelo como este: até o próximo trimestre, mais três anúncios de "melhor modelo de vídeo do mundo" vão aparecer. Cada um terá um SDK diferente, um fluxo de autenticação diferente, uma dança de limites de taxa (rate-limit) diferente, um modelo de precificação diferente. Sua equipe perderá uma semana integrando cada um. Depois, mais uma semana descontinuando o anterior.
Esse é exatamente o problema que o Atlas Cloud resolve.
Damos aos desenvolvedores um endpoint com acesso a mais de 300 modelos — todos os principais modelos de fundação, os principais lançamentos open-source e especialistas em rápido movimento em imagem, vídeo e raciocínio. Troque de modelos com uma única linha de código. Execute benchmarks lado a lado sem ter que reintegrar SDKs. Lance o modelo que está em alta hoje, mude para o que estiver em alta no próximo mês — sem ter que reescrever nada.
Porque a única coisa certa sobre IA no momento é que a tabela de classificação muda toda terça-feira. Construa para isso.






