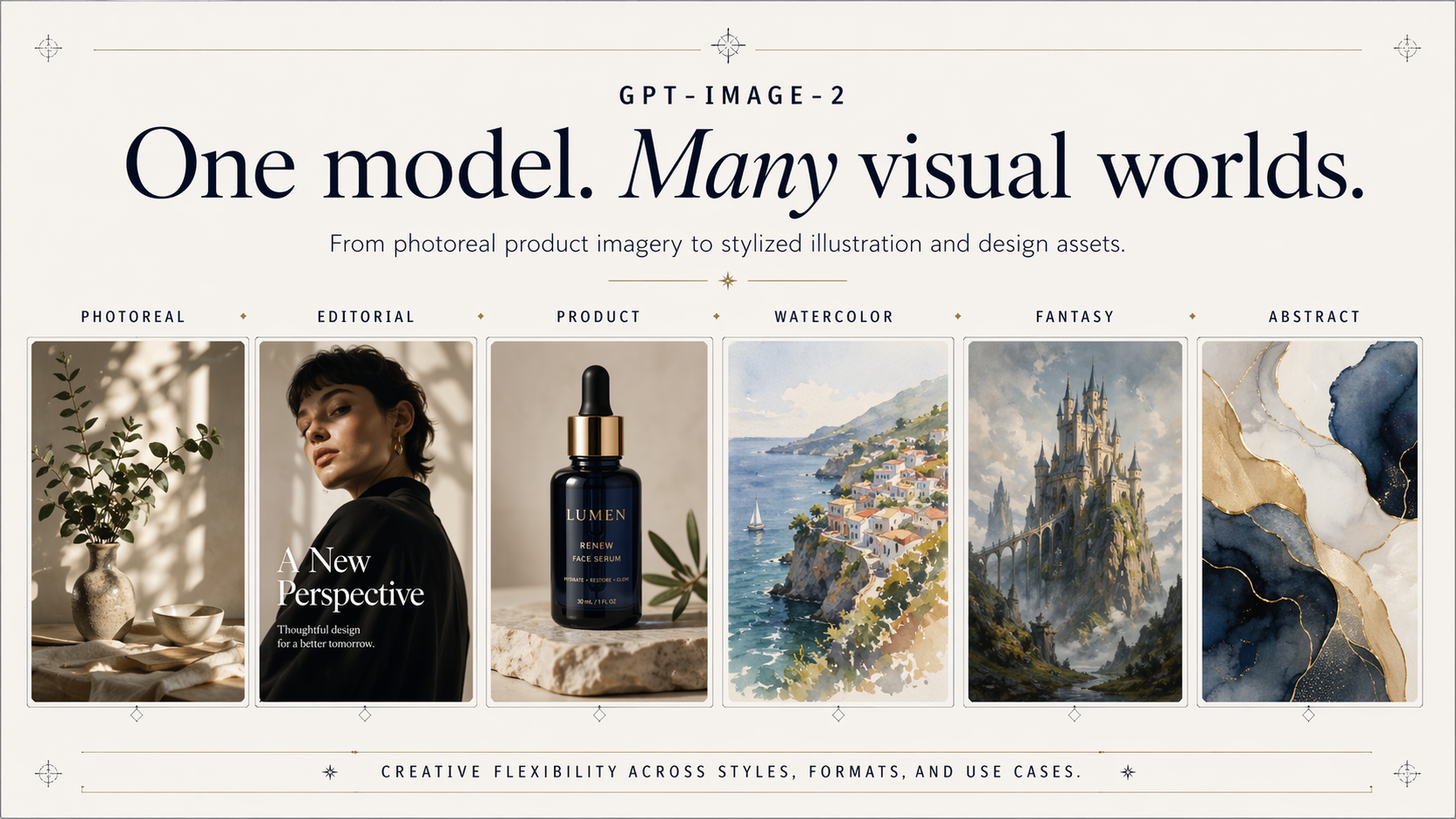

GPT Image 2 API for Accurate In-Image Text
A API do GPT Image 2 dá aos desenvolvedores acesso ao mais recente modelo de imagem da OpenAI, o sucessor do GPT Image 1.5. Ele gera e edita imagens com renderização de texto precisa em caracteres latinos e CJK, além de uma forte composição para pôsteres, mockups e infográficos. Na Atlas Cloud, você o acessa através de uma API unificada junto a mais de 300 modelos, com créditos gratuitos, 99,99% de tempo de atividade e sem a necessidade de verificação de organização da OpenAI.
Explorar Modelos Líderes
O Atlas Cloud oferece os modelos criativos mais avançados e inovadores do setor.




Velocidade de pico da GPT Image 2 API
Compare os endpoints da API do GPT Image 2 em toda a família, com conversão de texto em imagem e edição para o GPT Image 2, 1.5, 1 e Mini, para que você possa adequar custo e qualidade a cada trabalho por meio de uma única integração.
| Modalidade | Descrição |
|---|---|
| GPT Image-1 T2I API(Text to Image) | A API Text to Image do GPT Image-1 capacita os desenvolvedores a transformar prompts de texto em visuais fotorrealistas impressionantes com detalhes excepcionais. Ao combinar o raciocínio do GPT-4 Turbo com a síntese visual de classe DALL·E, ela oferece uma adesão ao prompt líder do setor e capacidades de composição complexa para a produção de imagens de nível profissional. |
| GPT Image-1 Edit API(Image to Image) | A GPT Image-1 Edit API capacita os desenvolvedores a transformar imagens existentes em obras-primas refinadas ou reimaginadas com consistência perfeita. Ao utilizar a compreensão multimodal, ela gera transferências estilísticas precisas, composições contextuais e modificações direcionadas para a iteração de ativos de nível profissional. |
| GPT Image-1.5 T2I API(Text to Image) | A API Text to Image do GPT Image-1.5 capacita os desenvolvedores a transformar prompts de texto em recursos visuais de alta qualidade com custo otimizado. Ao aproveitar a arquitetura impulsionada por GPT, ela oferece forte compreensão de prompts e fidelidade visual para fluxos de trabalho de produção equilibrados. |
| GPT Image-1.5 Edit API(Image to Image) | A GPT Image-1.5 Edit API capacita os desenvolvedores a aprimorar os ativos existentes com modificações precisas. Ao suportar o controle de input_fidelity, ela permite ajustes finos enquanto preserva elementos essenciais, como rostos e logotipos. |
| GPT Image-1 Mini T2I API(Text to Image) | A GPT Image-1 Mini Text to Image API capacita os desenvolvedores com a geração de imagens mais econômica da família. Ao aproveitar a arquitetura GPT-5, ela oferece resultados de nível profissional com o menor custo por imagem para a produção de conteúdo em alto volume. |
| GPT Image-1 Mini Edit API(Image to Image) | A GPT Image-1 Mini Edit API capacita os desenvolvedores a transformar imagens existentes com recursos de edição otimizados. Ao fornecer funções essenciais de edição com custo mínimo, ela permite iteração rápida e fluxos de trabalho de produção de conteúdo. |
Principais recursos do GPT Image 2
Explore o que a GPT Image 2 API pode fazer, desde texto preciso em imagens nos alfabetos latino e CJK até renderização fotorrealista, edição baseada em máscaras e composição de múltiplas referências.

Renderização fotorrealista
O GPT Image 2 oferece resultados fotorrealistas em gráficos de marketing, recursos visuais de produtos, conteúdo social e maquetes, onde a precisão é tão importante quanto a qualidade visual. Ele demonstra uma verdadeira compreensão de física, iluminação e propriedades de materiais, com cores neutras e precisas em diversos tipos de cenas.

Texto em imagem quase perfeito
O GPT Image 2 renderiza texto com ortografia correta e posicionado de forma natural dentro das imagens, desde sinalizações e rótulos de UI até pôsteres. Ele produz com confiabilidade gráficos de marketing, criativos de anúncios e cabeçalhos de e-mail com texto preciso em larga escala.

Controle avançado de composição
GPT Image 2 lida com cenas complexas de vários objetos sem os erros de oclusão e posicionamento dos modelos anteriores. Ele segue prompts longos e compostos por várias partes, preservando a composição, a iluminação e os detalhes finos.

Consistência de Personagem
O GPT Image 2 mantém a identidade do personagem, os acessórios e a iluminação consistentes em múltiplas gerações. Essa consistência do sujeito se mantém em composições de vários elementos, tornando-o confiável para conjuntos de variantes e trabalhos em série.

Suporte a texto multilíngue
O GPT Image 2 renderiza caracteres CJK com glifos precisos e traços claros, uma melhoria evidente em relação à fraqueza dos modelos anteriores com escrituras não latinas. Ele suporta renderização robusta de texto tanto em idiomas latinos quanto CJK.

Edição de imagens com suporte a máscaras
A Edit API suporta inpainting e outpainting precisos através de imagens de máscara, permitindo que você modifique regiões específicas enquanto todos os pixels não relacionados permanecem intactos. Isso torna a GPT Image 2 API confiável para retoques, remoção de objetos e limpeza de composição controlada.

Composição Multirreferência
A GPT Image 2 API pode combinar várias imagens de entrada em um resultado coerente, guiado por um prompt em linguagem natural. Isso suporta a colocação de produtos, transferência de estilo e personagens consistentes em um conjunto de visuais gerados.

Mockups de UI e Interface
O GPT Image 2 gera mockups de UI e interfaces de aplicativos com texto de botão escrito corretamente e uma estrutura de layout limpa. É ideal para telas de conceito rápido e visualizações de design onde a legibilidade do texto na tela é importante.

Forte Adesão ao Prompt
A API do GPT Image 2 segue prompts longos e compostos por várias partes com um cumprimento confiável de instruções, preservando a composição, as escolhas de iluminação e os detalhes finos. O resultado é um número menor de repetições e saídas confiáveis para fluxos de trabalho de produção.
Comparação entre GPT Image 2 e outros SOTA
Create a Japanese-language infographic titled "うちの部署のメンバー スペック分析" (Our Department Member Spec Analysis) with subtitle "個性豊かなプロ集団(たぶん)". Layout as a 2x3 grid of six member cards on a clean white background with pastel accents and star decorations. Each card features a cute chibi-style cartoon avatar and includes: member name and role in Japanese, a radar chart or bar chart showing their stats, bullet-point strengths and weaknesses in Japanese. Add a summary section at the bottom with overall team evaluation, a team compatibility graph placeholder, and a final takeaway note. Cheerful office illustration style, soft rounded UI elements, kawaii aesthetic, highly legible Japanese typography, no watermark.

GPT Image 2

Grok Imagine
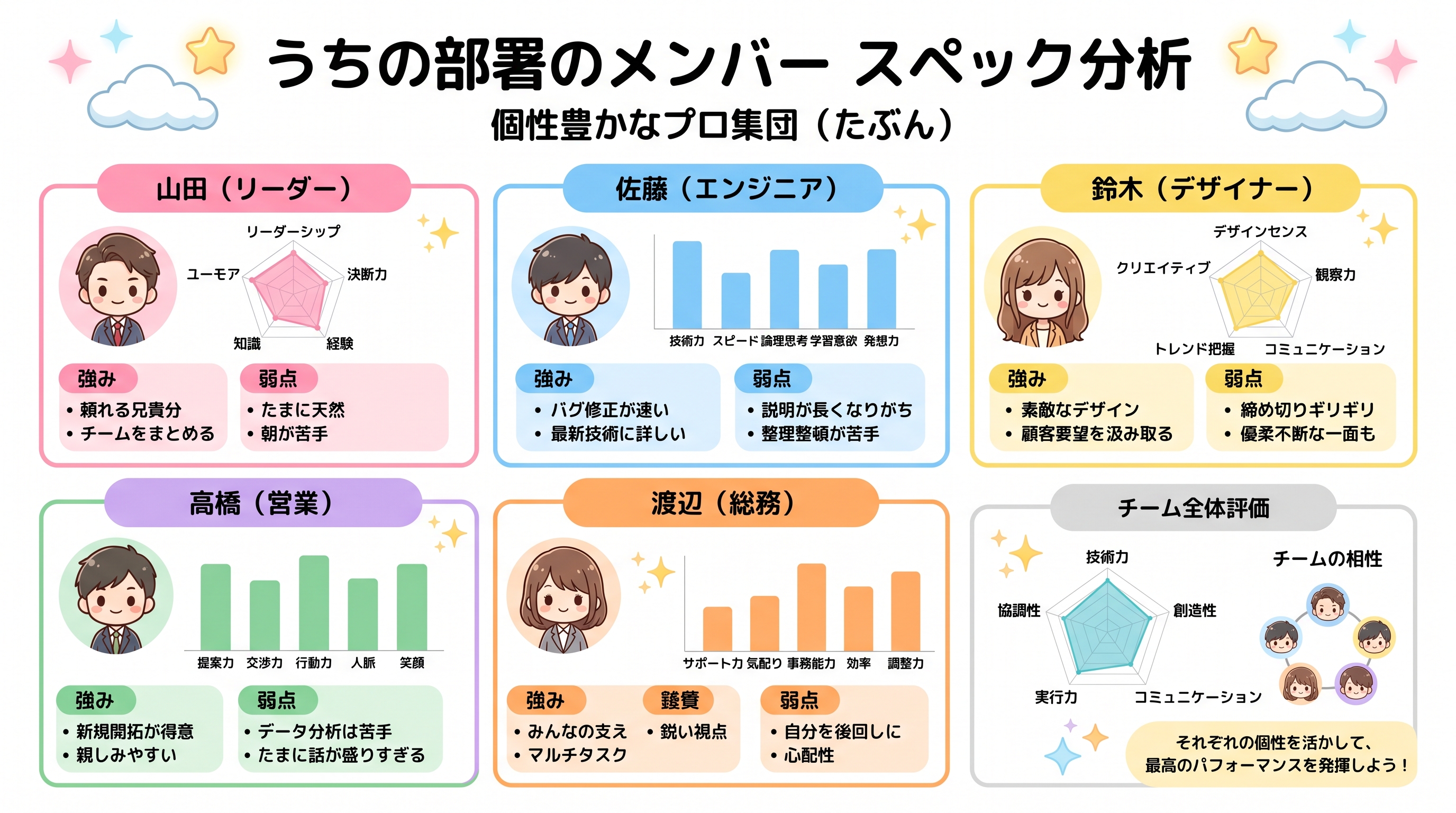
Nano Banana 2
O que você pode fazer com a GPT Image 2 API
De criativos de anúncios e recursos visuais de produtos a mockups de UI, conteúdo localizado e infográficos editoriais, veja o que a GPT Image 2 API pode construir.
Publicidade e Marketing Profissional
Espera-se que o GPT Image 2 seja particularmente forte para a automação de marketing — gerando gráficos para redes sociais, criativos de anúncios e cabeçalhos de e-mail com texto preciso, em grande escala. Combinado com o MindStudio, através de uma adesão quase perfeita aos prompts e fotorrealismo aprimorado, ele tem como alvo ativos de campanha prontos para produção sem a necessidade de sessões de fotos.
Comércio Eletrônico e Visualização de Produtos
O GPT Image 2 está a ser amplamente discutido no contexto dos elementos visuais de produtos e conteúdos sociais, onde a precisão é tão importante como a qualidade visual. Dreamina As melhorias na consistência das personagens e na preservação da imagem tornam-no bastante adequado para expandir catálogos de produtos, gerar imagens de estilo de vida e produzir conjuntos de variantes consistentes.
Mockups de UI e Design de Produto
Mockups de UI e interfaces de aplicativos — com texto de botão escrito corretamente e estrutura de layout limpa — estão entre os casos de uso que os primeiros testadores destacaram especificamente. As equipes de produto e designers da Dzine podem usar o GPT Image 2 para mockups de conceitos rápidos, visuais de landing pages e recursos de apresentação.
Visualização Arquitetônica e de Interiores
Renderizações arquitetônicas e de interiores com profundidade e realismo de materiais aprimorados estão entre os pontos fortes esperados do GPT Image 2. As melhorias de fotorrealismo e composição do Dzine tornam-no uma ferramenta prática para apresentações de design e marketing imobiliário.
Conteúdo Multilíngue e Localizado
A API do GPT Image 2 renderiza texto preciso em chinês, japonês, coreano e outros alfabetos, permitindo produzir sinalizações, publicações para redes sociais e materiais de marca que antes exigiam a sobreposição manual de texto. Isso torna prático localizar campanhas e criar recursos visuais específicos para cada região em grande escala.
Publicação, Edição e Infográficos
A GPT Image 2 API produz capas de livros, artigos ilustrados, infográficos e recursos visuais educativos onde o texto legível na imagem é um requisito fundamental. Com tipografia precisa e geração estruturada para gráficos, diagramas e materiais explicativos, ela transforma informações complexas em gráficos claros e fáceis de compartilhar.
Comparação de Modelos
Veja como os modelos de diferentes provedores se comparam — compare desempenho, preços e pontos fortes exclusivos para tomar uma decisão informada.
| Modelo | Limite de imagens de referência | Número de saídas | Resolução | Proporção de aspecto |
|---|---|---|---|---|
| GPT Image-2 | 16 | 1-10 | Up to 2048×2048 (2K) native;4K via scaling | 1:1, 2:3, 3:2 |
| GPT Image-1.5 | 10 | 1 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| GPT Image-1 | 4 | 1~10 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| GPT Image-1 Mini | 4 | 1~10 | 1024×1024, 1024×1536, 1536×1024 | 1:1, 3:2, 2:3 |
| Nano Banana 2 | 14 | 1 | 512×512, 1024×1024, 2048×2048, 4096×4096 (0.5K/1K/2K/4K) | 1:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9, 1:4, 4:1, 1:8, 8:1 |
| Grok Imagine | 1 | 1-10 | 1024×1024 (1K), 2048×2048 (2K) | 1:1, 3:2, 2:3, 16:9, 9:16 |
Como Usar GPT Image 2 no Atlas Cloud
Comece em minutos — siga estes passos simples para integrar e implantar modelos pela plataforma da Atlas Cloud.
Crie uma Conta no Atlas Cloud
Cadastre-se em atlascloud.ai e conclua a verificação. Novos usuários recebem créditos gratuitos para explorar a plataforma e testar modelos.
Por Que Usar GPT Image 2 no Atlas Cloud
Combine modelos avançados de GPT Image 2 com a plataforma acelerada por GPU do Atlas Cloud, fornecendo desempenho, escalabilidade e experiência de desenvolvimento incomparáveis.
Desempenho e Flexibilidade
Baixa Latência:
Inferência otimizada por GPU para respostas em tempo real.
API Unificada:
Uma única integração para acessar GPT Image 2, GPT, Gemini e DeepSeek.
Preços Transparentes:
Faturamento por Token, suporta modo Serverless.
Empresa e Escala
Experiência do Desenvolvedor:
SDK, análise de dados, ferramentas de ajuste fino e modelos tudo em um.
Confiabilidade:
99.99% de disponibilidade, controle de permissões RBAC, logs de conformidade.
Segurança e Conformidade:
Certificação SOC 2 Type II, conformidade HIPAA, soberania de dados nos EUA.
Perguntas frequentes dos usuários sobre a GPT Image 2 API
A API do GPT Image 2 oferece aos desenvolvedores acesso programático ao GPT Image 2 da OpenAI, o modelo de imagens lançado em abril de 2026 como sucessor do GPT Image 1.5 e substituto do DALL-E 3. Ele gera e edita imagens a partir de entradas de texto e imagem, com texto na imagem preciso, suporte multilíngue e forte fotorrealismo. No Atlas Cloud, você pode chamá-lo por meio de uma API unificada junto com mais de 300 outros modelos.
Sim. A API do GPT Image 2 suporta tanto a geração de texto para imagem quanto a edição de imagens em um único modelo. A edição inclui inpainting e outpainting precisos com imagens de máscara, além de composição de múltiplas referências que combina várias entradas em um resultado coerente.
Não. O GPT Image 2 é o sucessor do GPT Image 1.5, não do DALL-E. A OpenAI abandonou totalmente a marca DALL-E — tanto o DALL-E 2 quanto o DALL-E 3 serão encerrados em 12 de maio de 2026. A família GPT Image usa uma arquitetura autorregressiva construída nativamente dentro do modelo de linguagem, o que é fundamentalmente diferente da abordagem baseada em difusão que o DALL-E usava.
Sim. A GPT Image 2 API suporta tanto a geração de texto para imagem quanto a edição de imagens em um único modelo. A edição inclui inpainting e outpainting precisos com imagens de máscara, além de composição multirreferência que combina várias entradas em um resultado coerente.
Sim. A API do GPT Image 2 renderiza texto em sistemas de escrita latinos e CJK (chinês, japonês, coreano), incluindo chinês, japonês e coreano, com glifos precisos e traços claros. Isso permite produzir sinalização localizada, postagens em redes sociais e materiais de marca que anteriormente exigiam sobreposição manual de texto.
A API do GPT Image 2 suporta tamanhos de imagem e proporções flexíveis, com resolução de saída nativa de até 2K e 4K disponível por meio de dimensionamento. Você pode solicitar tamanhos predefinidos ou dimensões personalizadas para se adequar a postagens sociais, banners e ativos prontos para impressão.
Não. A OpenAI restringe a família GPT Image através de verificação de organização no seu próprio console de desenvolvedor, o que pode bloquear desenvolvedores individuais. Com a API do GPT Image 2 na Atlas Cloud, você só precisa de uma conta da Atlas Cloud, para que possa obter uma chave e começar a gerar sem a verificação da OpenAI.
A OpenAI cobra o GPT Image 2 por token, portanto, o custo por imagem varia de acordo com a resolução, qualidade e imagens de referência, e é difícil de prever. No Atlas Cloud, a API do GPT Image 2 utiliza um preço fixo por imagem: o text to image começa em US$ 0,009 por imagem e a edição em US$ 0,01 por imagem, caindo para US$ 0,004 e US$ 0,005 no nível de desenvolvedor. Novos usuários também ganham créditos gratuitos para testar antes de gastar.
Explorar Mais Séries
Seedance 2.0
A API do Seedance 2.0 oferece acesso de produção ao modelo de vídeo multimodal da ByteDance — entradas quadrimodais (texto, imagem, vídeo, áudio) e um sistema "Universal Reference" líder do setor que fixa a composição, o movimento da câmera e as ações dos personagens entre as cenas. Integre um controle de nível de diretor com uma única chamada de API, uma taxa fixa de $0,09/s, chave instantânea e sem lista de espera — respaldado por tempo de atividade e conformidade de nível corporativo. O Seedance 2.0 Native 4K já está no ar!
Grok Imagine
A Grok Imagine API oferece aos desenvolvedores a geração de imagens, vídeos e áudio da xAI em um único pacote. Ela produz imagens de até 2K com renderização de texto multilíngue, além de vídeos de até 15 segundos com áudio nativo sincronizado e edição baseada em referências. Na Atlas Cloud, uma única chave executa todos os modos do Grok Imagine, permitindo que você alterne entre imagem, vídeo e áudio sem configurações separadas, a partir de US$ 0,02 por imagem e US$ 0,05 por segundo.
Gemini Omni Flash
A Gemini Omni API traz para o seu stack o modelo multimodal de geração e edição de vídeo do Google DeepMind, apresentado no Google I/O 2026. O Gemini Omni funde o motor de raciocínio do Gemini com mídia generativa, aceitando qualquer combinação de texto, imagens, vídeo e áudio para produzir resultados consistentes e fundamentados em conhecimento. Refine os resultados por meio de conversas naturais — troque objetos, reescreva cenas e mude estilos, enquanto a física, os personagens e a continuidade permanecem intactos. A Atlas Cloud oferece toda a linha Gemini Omni Flash — texto para vídeo, imagem para vídeo com até 7 imagens de referência e referência para vídeo — por meio de uma única API unificada, com preços transparentes por segundo a partir de $0.112 e sem assinatura. Comece a construir hoje mesmo.
GPT Image 2
A API do GPT Image 2 dá aos desenvolvedores acesso ao mais recente modelo de imagem da OpenAI, o sucessor do GPT Image 1.5. Ele gera e edita imagens com renderização de texto precisa em caracteres latinos e CJK, além de uma forte composição para pôsteres, mockups e infográficos. Na Atlas Cloud, você o acessa através de uma API unificada junto a mais de 300 modelos, com créditos gratuitos, 99,99% de tempo de atividade e sem a necessidade de verificação de organização da OpenAI.
Os modelos criativos mais poderosos do Google estão todos disponíveis na Atlas Cloud. O Veo 3.1 oferece geração de vídeo cinematográfico, o Nano Banana 2 impulsiona a criação de imagens de alta fidelidade e o Gemini traz inteligência multimodal para cada fluxo de trabalho. Acesse o pacote completo de modelos do Google por meio de uma única API key com disponibilidade Day-0 e preços de pagamento conforme o uso (pay-as-you-go).
Seedance 2.0 Mini
O Seedance 2.0 Mini leva a geração de vídeo multimodal da ByteDance para fluxos de trabalho onde a velocidade e o custo são essenciais. Ele oferece os principais recursos do Seedance 2.0 com menor impacto — geração mais rápida, menor custo por vídeo e a mesma integração de API que você já usa. Para equipes que executam pipelines de alto volume ou prototipagem em escala, o Mini é a opção padrão prática.
ByteDance
Da geração de vídeo cinematográfico à criação de imagens de alta fidelidade, os modelos mais poderosos da ByteDance estão disponíveis no Atlas Cloud. Execute o Seedance e o Seedream em grande escala com os preços de inferência mais baixos e zero custos indiretos de infraestrutura.
Alibaba
O Atlas Cloud reúne toda a linha de modelos da Alibaba sob uma única API: Qwen para tarefas de linguagem e imagem, e Wan para geração de vídeo em até 1080p. Acesse cada modelo no formato pré-pago (pay-as-you-go) sem necessidade de assinaturas. A API da Alibaba está disponível por meio de uma única URL base usando seu cliente compatível com OpenAI existente.
OpenAI
O Atlas Cloud oferece acesso a toda a linha da API da OpenAI, desde o GPT Image 2 para geração de imagens até o Sora 2 para vídeo. Todos os modelos estão disponíveis na modalidade de pagamento conforme o uso, sem compromisso mensal. Integre-se trocando apenas uma URL base usando a API compatível com a OpenAI.
xAI
Construa pipelines completos de imagem e vídeo usando a xAI API no Atlas Cloud. Gere em 2K, edite com imagens de referência e anime imagens em clipes sincronizados com áudio.
Kwaivgi
A API da Kwaivgi com preço 15% abaixo do padrão. A Atlas Cloud oferece acesso Day-0 a novos lançamentos da Kling com preços de pagamento conforme o uso e sem limite de assentos. Uma conta, uma chave, todos os modelos da Kling do nível padrão ao nível master.
Seedream 5.0 Pro
A API do Seedream 5.0 Pro fornece aos desenvolvedores o modelo de edição de imagens controlável da ByteDance no Atlas Cloud. Ela posiciona as edições com precisão usando âncoras e coordenadas, separa as imagens em camadas editáveis, funde múltiplas referências e combina cores e materiais exatos, com texto multilíngue em 2K e 3K. No Atlas Cloud, você pode acessá-lo por meio de uma única chave!


