A geração de áudio nativa em vídeos de IA mudou permanentemente o fluxo de trabalho de produção. Até pouco tempo, gerar vídeos com IA significava produzir um clipe silencioso e, em seguida, buscar, editar e sincronizar o áudio em uma etapa separada. Esse passo adicional adicionava tempo, custo e complexidade — e os resultados eram, muitas vezes, imperfeitos. Em 2026, três modelos líderes geram áudio sincronizado juntamente com a saída de vídeo em uma única passagem: Veo 3.1 do Google DeepMind, Kling 3.0 da Kuaishou e Vidu Q3 da Shengshu Technology.
Este guia comparativo detalha exatamente como cada modelo lida com o áudio — qualidade, suporte a idiomas, precisão de sincronização, preços e casos de uso práticos. Seja você um desenvolvedor criando um pipeline de conteúdo, um profissional de marketing produzindo anúncios em escala ou um cineasta explorando a pré-produção assistida por IA, este guia o ajudará a escolher o modelo com áudio ideal para o seu fluxo de trabalho.
*Última atualização: 28 de fevereiro de 2026*
Veja estes modelos comparados lado a lado:
Modelos com Capacidade de Áudio em Resumo
| Recurso | Veo 3.1 | Kling 3.0 | Vidu Q3 |
|---|---|---|---|
| Desenvolvedor | Google DeepMind | Kuaishou | Shengshu Technology |
| Áudio Nativo | Sim | Sim | Sim |
| Idiomas de Áudio | Focado em Inglês | Inglês, Chinês, Japonês, Coreano, Espanhol | Focado em Inglês |
| Sincronia Labial | Contextual | Sincronia labial multilíngue | Contextual |
| Tipo de Áudio | Ambiente + diálogo | Ambiente + diálogo multilíngue | Ambiente + diálogo |
| Duração Máxima | 8 segundos | 10 segundos | 16 segundos |
| Resolução Máxima | 720p | 1080p | 1080p |
| Preço Atlas Cloud | USD0.09/seg (Rápido) / USD0.18/seg (Std) | USD0.095/seg (Pro) | USD0.06/seg |
| Custo por clipe de 8s | USD0.72 (Rápido) / USD1.44 (Std) | USD0.76 | USD0.48 |
| Melhor Força em Áudio | Paisagens sonoras ambiente | Diálogo multilíngue | Sincronia audiovisual equilibrada |
Como o Áudio Nativo Funciona em Vídeos de IA
Antes de mergulhar em cada modelo, é importante entender o que "áudio nativo" realmente significa neste contexto. Modelos tradicionais de vídeo de IA produzem arquivos silenciosos. O áudio — seja som ambiente, música, diálogo ou efeitos sonoros — deve ser gerado separadamente usando uma ferramenta diferente ou extraído de uma biblioteca, e então sincronizado manualmente com o vídeo na pós-produção.
Modelos de áudio nativo geram a trilha de áudio como parte do mesmo processo de inferência que cria o vídeo. O modelo lê o prompt de texto, gera quadros visuais e, simultaneamente, produz uma trilha de áudio contextualmente alinhada com o conteúdo visual. Uma cena de praia ganha sons de ondas. Uma pessoa falando ganha um diálogo com sincronia labial. Uma rua da cidade recebe ruídos de tráfego. O áudio é incorporado ao arquivo de saída — sem chamadas de API adicionais, sem etapa de pós-sincronização.
Isso é importante porque:
- Elimina uma etapa de produção inteira. As equipes não precisam mais encontrar, editar e sincronizar o áudio separadamente.
- A precisão da sincronia é maior. Como o áudio e o vídeo são gerados juntos, o alinhamento temporal é mais natural do que adicionar áudio ao vídeo posteriormente.
- O custo cai. Não há necessidade de APIs de geração de áudio separadas, licenças de bancos de áudio ou ferramentas de edição de som.
- A iteração é mais rápida. Uma única chamada de API produz um ativo completo, pronto para revisão.
Veo 3.1: Áudio Ambiente Cinematográfico
Capacidades de Áudio
O Veo 3.1 aborda o áudio da mesma forma que um designer de som abordaria um set de filmagem. Seu ponto forte é o áudio ambiental que parece ter sido capturado no local junto com o vídeo. Ao pedir um fiorde norueguês ao amanhecer, a saída inclui vento, água batendo nas pedras e canto distante de pássaros. Ao pedir um cruzamento movimentado em Tóquio, a saída oferece ruído de tráfego, conversa de pedestres e sinais de travessia.
O modelo processa pistas contextuais de áudio no prompt e gera paisagens sonoras que correspondem ao ambiente visual. Não se trata de ruído aleatório aplicado ao vídeo — é uma geração com consciência contextual que responde a elementos específicos na cena.
Manipulação de diálogo: O Veo 3.1 pode gerar áudio falado quando solicitado, mas seu ponto forte reside claramente em sons ambientais, não em diálogos multilíngues. O modelo lida razoavelmente bem com a fala em inglês, mas não possui a capacidade explícita de sincronia labial multilíngue do Kling 3.0.
Qualidade do áudio: A saída de áudio do Veo 3.1 é limpa, sem artefatos óbvios ou ruído digital. A faixa de frequência soa natural e os elementos ambientais se misturam suavemente. Em nossos testes, a qualidade do áudio acompanhou consistentemente a alta qualidade cinematográfica do vídeo.
Pontos Fortes em Áudio do Veo 3.1
- Paisagens sonoras ambientais de primeira linha que parecem gravações de campo
- Saída de áudio limpa e sem artefatos
- Forte consciência contextual — elementos de áudio correspondem precisamente aos visuais
- Qualidade cinematográfica profissional a USD0.09/seg (Rápido) ou USD0.18/seg (Padrão)
- Excelente para conteúdo de marca, filmagens da natureza e peças atmosféricas
Limitações de Áudio do Veo 3.1
- Focado em inglês — capacidade de diálogo multilíngue limitada
- Sem parâmetro explícito de seleção de idioma
- O máximo de 8 segundos limita a complexidade de narrativas de áudio
- Som ambiente é o ponto forte — diálogo e fala são secundários
Exemplo de Código para Veo 3.1
plaintext1```python 2import requests 3import time 4 5 6API_KEY = "your-atlas-cloud-api-key" 7BASE_URL = "https://api.atlascloud.ai/api/v1" 8 9 10# Veo 3.1 com prompt rico em áudio 11response = requests.post( 12 f"{BASE_URL}/model/generateVideo", 13 headers={ 14 "Authorization": f"Bearer {API_KEY}", 15 "Content-Type": "application/json" 16 }, 17 json={ 18 "model": "google/veo3.1/text-to-video", 19 "prompt": "Close-up of a barista pouring steamed milk into a latte, " 20 "espresso machine hissing in the background, soft jazz " 21 "playing in a cozy cafe, warm morning light through windows", 22 "duration": 8, 23 "resolution": "1080p" 24 } 25) 26 27 28result = response.json() 29 30 31while True: 32 status = requests.get( 33 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 34 headers={"Authorization": f"Bearer {API_KEY}"} 35 ).json() 36 if status["status"] == "completed": 37 print(f"Video with audio: {status['output']['video_url']}") 38 break 39 time.sleep(5) 40```
Kling 3.0: Líder em Diálogos Multilíngues
Capacidades de Áudio
O Kling 3.0 adota uma abordagem fundamentalmente diferente para o áudio. Onde o Veo 3.1 se destaca em paisagens sonoras ambientais, o Kling 3.0 foi construído em torno da geração de diálogo multilíngue com sincronia labial. O modelo oferece suporte nativo à geração de áudio em cinco idiomas — inglês, chinês, japonês, coreano e espanhol — com movimentos labiais precisos que correspondem à fala gerada.
Isso não é uma camada simples de texto-para-fala sobreposta ao vídeo. O modelo gera os movimentos faciais do personagem, formas de boca e timing simultaneamente com a trilha de áudio. O resultado é um personagem que parece genuinamente falar o idioma especificado no prompt.
Manipulação de diálogo: Este é o recurso de áudio definidor do Kling 3.0. Especifique um idioma no prompt e o modelo gera um personagem falando esse idioma com sincronia labial apropriada. Nos testes, prompts em espanhol produziram resultados convincentes com movimentos naturais de boca e cadência. As saídas em japonês e coreano foram igualmente impressionantes, com linguagem corporal culturalmente apropriada acompanhando a fala.
Áudio ambiente: O Kling 3.0 também gera áudio ambiental, embora isso seja secundário às suas capacidades de diálogo. Sons de fundo estão presentes e são contextualmente apropriados, mas carecem da profundidade cinematográfica das paisagens sonoras do Veo 3.1.
Qualidade do áudio: O áudio da fala é claro e soa natural. Ocasionalmente, há artefatos em cenas complexas com diálogo e som ambiente pesado, mas para conteúdo focado em diálogos, a qualidade está pronta para produção.
Pontos Fortes em Áudio do Kling 3.0
- Diálogo multilíngue em 5 idiomas com sincronia labial precisa
- Cadência de fala e linguagem corporal culturalmente apropriadas
- Áudio forte focado em personagens — ideal para conteúdo de "cabeça falante"
- Maior duração entre os três, com 10 segundos
- Excelente para marketing multilíngue e conteúdo global
Limitações de Áudio do Kling 3.0
- Preço premium a USD0.095/seg (Pro)
- Qualidade do áudio ambiente abaixo do padrão cinematográfico do Veo 3.1
- Moderação de conteúdo muito rigorosa pode bloquear prompts inocentes
- A qualidade do idioma varia — Inglês e Chinês são os mais fortes
Exemplo de Código para Kling 3.0
plaintext1```python 2import requests 3import time 4 5 6API_KEY = "your-atlas-cloud-api-key" 7BASE_URL = "https://api.atlascloud.ai/api/v1" 8 9 10# Kling 3.0 com prompt de diálogo multilíngue 11response = requests.post( 12 f"{BASE_URL}/model/generateVideo", 13 headers={ 14 "Authorization": f"Bearer {API_KEY}", 15 "Content-Type": "application/json" 16 }, 17 json={ 18 "model": "kwaivgi/kling-v3.0-pro/text-to-video", 19 "prompt": "A professional female presenter speaking in Spanish, " 20 "looking directly at camera, modern office background, " 21 "warm studio lighting, corporate presentation style", 22 "duration": 10, 23 "resolution": "1080p" 24 } 25) 26 27 28result = response.json() 29 30 31while True: 32 status = requests.get( 33 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 34 headers={"Authorization": f"Bearer {API_KEY}"} 35 ).json() 36 if status["status"] == "completed": 37 print(f"Video with audio: {status['output']['video_url']}") 38 break 39 time.sleep(5) 40```
Vidu Q3: Geração Audiovisual Equilibrada
Capacidades de Áudio
O Vidu Q3 da Shengshu Technology se posiciona entre o foco ambiental do Veo 3.1 e a especialização em diálogos do Kling 3.0. O modelo gera áudio sincronizado que cobre tanto paisagens sonoras ambientais quanto fala básica, oferecendo uma abordagem equilibrada.
Manipulação de diálogo: O Vidu Q3 gera áudio de fala com uma precisão de sincronia labial razoável. É primariamente focado em inglês, sem as capacidades multilíngues do Kling 3.0. A saída de fala é clara e natural, embora não alcance a sofisticação linguística do suporte de cinco idiomas do Kling 3.0.
Áudio ambiente: A geração de sons ambientais é competente e contextualmente consciente. O modelo lê descrições de cena em prompts e gera áudio de fundo apropriado. A qualidade fica entre o áudio ambiente funcional do Kling 3.0 e as paisagens sonoras cinematográficas do Veo 3.1.
Qualidade do áudio: A saída de áudio geral é limpa e utilizável para produção. O ponto forte do Vidu Q3 é a consistência — a qualidade do áudio é confiável em diferentes tipos de prompt, sem o brilho ocasional ou a inconsistência que podem caracterizar modelos mais especializados.
Pontos Fortes em Áudio do Vidu Q3
- Abordagem equilibrada que cobre diálogo e áudio ambiente
- Qualidade consistente em diferentes tipos de conteúdo
- Preço intermediário a USD0.06/seg
- Bom custo-benefício para equipes que precisam tanto de fala quanto de áudio ambiental
- Saída limpa, sem artefatos, adequada para uso em produção
Limitações de Áudio do Vidu Q3
- Focado em inglês — carece de capacidade de diálogo multilíngue
- Qualidade de áudio não atinge os níveis cinematográficos do Veo 3.1
- Precisão de sincronia labial abaixo do padrão multilíngue do Kling 3.0
- Duração máxima de 16 segundos
- Ecossistema menos estabelecido em comparação com Veo e Kling
Exemplo de Código para Vidu Q3
plaintext1```python 2import requests 3import time 4 5 6API_KEY = "your-atlas-cloud-api-key" 7BASE_URL = "https://api.atlascloud.ai/api/v1" 8 9 10# Vidu Q3 com prompt de áudio equilibrado 11response = requests.post( 12 f"{BASE_URL}/model/generateVideo", 13 headers={ 14 "Authorization": f"Bearer {API_KEY}", 15 "Content-Type": "application/json" 16 }, 17 json={ 18 "model": "shengshu/vidu-q3/text-to-video", 19 "prompt": "A young man unboxing a new smartphone at a desk, " 20 "speaking excitedly about the features, natural room " 21 "lighting, casual vlog style, ambient room sounds", 22 "duration": 8, 23 "resolution": "1080p" 24 } 25) 26 27 28result = response.json() 29 30 31while True: 32 status = requests.get( 33 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 34 headers={"Authorization": f"Bearer {API_KEY}"} 35 ).json() 36 if status["status"] == "completed": 37 print(f"Video with audio: {status['output']['video_url']}") 38 break 39 time.sleep(5) 40```
Comparação Direta de Áudio
Classificação de Qualidade de Áudio por Categoria
| Categoria | 1º Lugar | 2º Lugar | 3º Lugar |
|---|---|---|---|
| Ambiente/Natural | Veo 3.1 | Vidu Q3 | Kling 3.0 |
| Diálogo (Inglês) | Kling 3.0 | Vidu Q3 | Veo 3.1 |
| Fala Multilíngue | Kling 3.0 | -- | -- |
| Precisão de Sincronia Labial | Kling 3.0 | Vidu Q3 | Veo 3.1 |
| Efeitos Sonoros | Veo 3.1 | Vidu Q3 | Kling 3.0 |
| Sincronia Audiovisual Geral | Veo 3.1 | Kling 3.0 | Vidu Q3 |
| Consistência de Áudio | Vidu Q3 | Veo 3.1 | Kling 3.0 |
Comparação de Preços
| Modelo | Custo/Segundo | Clipe 8s | Clipe 10s | 100 Clipes (8s) |
|---|---|---|---|---|
| Vidu Q3 | USD0.06 | USD0.48 | USD0.60 | USD48.00 |
| Veo 3.1 Rápido | USD0.09 | USD0.72 | N/A (máx 8s) | USD72.00 |
| Kling 3.0 Pro | USD0.095 | USD0.76 | USD0.95 | USD76.00 |
Em escala, as diferenças de preço tornam-se significativas. Uma equipe que produz 500 clipes por mês gastaria USD240 com o Vidu Q3, USD360 com o Veo 3.1 Rápido ou USD380 com o Kling 3.0 Pro. A questão é se o diálogo multilíngue do Kling 3.0 justifica o prêmio sobre o áudio ambiente cinematográfico do Veo 3.1 ou a abordagem equilibrada do Vidu Q3.
Duração e Resolução
| Modelo | Duração Máxima | Resolução Máxima | Taxa de Quadros |
|---|---|---|---|
| Vidu Q3 | 16 segundos | 1080p | 24fps |
| Kling 3.0 | 10 segundos | 1080p | 30fps |
| Veo 3.1 | 8 segundos | 720p | 24fps |
O Vidu Q3 lidera na duração com 16 segundos, enquanto o Kling 3.0 tem uma clara vantagem na resolução. Para conteúdos ricos em diálogos, esses segundos adicionais permitem sentenças mais completas e um ritmo mais natural.
Como Acessar Esses Modelos via API Atlas Cloud
Todos os três modelos de vídeo com áudio estão disponíveis através de uma única chave de API da Atlas Cloud. Não há necessidade de manter contas separadas no Google, Kuaishou e Shengshu.
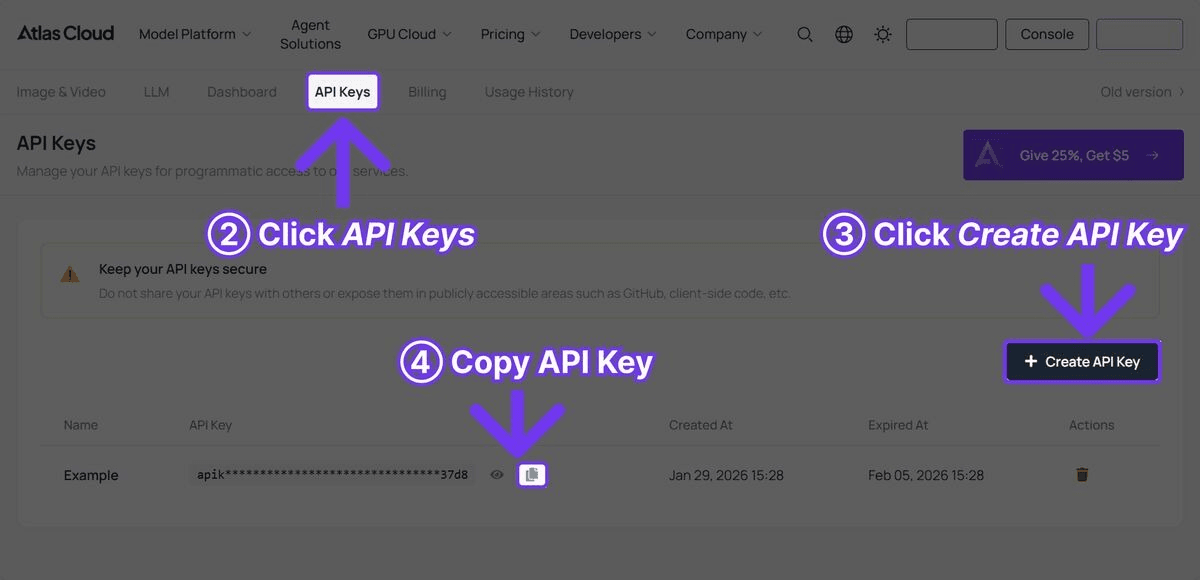
Passo 1: Obtenha sua chave de API
Registre-se em Atlas Cloud e navegue até a aba API Keys.
Passo 2: Compare todos os três modelos
Aqui está um script Python completo que gera vídeo com áudio de todos os três modelos usando o mesmo prompt, facilitando a comparação dos resultados:
plaintext1```python 2import requests 3import time 4 5 6API_KEY = "your-atlas-cloud-api-key" 7BASE_URL = "https://api.atlascloud.ai/api/v1" 8HEADERS = { 9 "Authorization": f"Bearer {API_KEY}", 10 "Content-Type": "application/json" 11} 12 13 14PROMPT = ("A street musician playing acoustic guitar on a cobblestone " 15 "sidewalk at golden hour, passersby dropping coins, warm natural " 16 "lighting, documentary style") 17 18 19models = { 20 "Veo 3.1": { 21 "model": "google/veo3.1/text-to-video", 22 "duration": 8 23 }, 24 "Kling 3.0": { 25 "model": "kwaivgi/kling-v3.0-pro/text-to-video", 26 "duration": 10 27 }, 28 "Vidu Q3": { 29 "model": "shengshu/vidu-q3/text-to-video", 30 "duration": 8 31 } 32} 33 34 35request_ids = {} 36 37 38for name, config in models.items(): 39 response = requests.post( 40 f"{BASE_URL}/model/generateVideo", 41 headers=HEADERS, 42 json={ 43 "model": config["model"], 44 "prompt": PROMPT, 45 "duration": config["duration"], 46 "resolution": "1080p" 47 } 48 ) 49 result = response.json() 50 request_ids[name] = result["request_id"] 51 print(f"Submitted {name}: {result['request_id']}") 52 53 54# Polling para os três 55completed = {} 56while len(completed) < len(request_ids): 57 for name, rid in request_ids.items(): 58 if name in completed: 59 continue 60 status = requests.get( 61 f"{BASE_URL}/model/prediction/{rid}/get", 62 headers={"Authorization": f"Bearer {API_KEY}"} 63 ).json() 64 if status["status"] == "completed": 65 completed[name] = status["output"]["video_url"] 66 print(f"{name} done: {status['output']['video_url']}") 67 time.sleep(5) 68 69 70print("\nAll videos generated. Compare the audio quality:") 71for name, url in completed.items(): 72 print(f" {name}: {url}") 73```
Quando escolher cada modelo
Escolha o Veo 3.1 para áudio quando:
- O conteúdo for atmosférico ou ambiental. Documentários de natureza, conteúdo de viagem, filmes de marca, tours imobiliários — qualquer cenário onde a paisagem sonora ambiente for mais importante que o diálogo.
- O orçamento for a principal restrição. A USD0.09/seg (Rápido), o Veo 3.1 é uma opção acessível com qualidade cinematográfica. Equipes produzindo centenas de clipes mensalmente terão economias significativas.
- A qualidade cinematográfica for a prioridade. A combinação do polimento visual do Veo 3.1 com sua qualidade de áudio ambiente produz conteúdo que parece profissionalmente produzido.
- Você não precisar de diálogo multilíngue. Se o requisito de áudio for ambiental em vez de conversacional, o Veo 3.1 é a escolha clara.
Escolha o Kling 3.0 para áudio quando:
- O conteúdo exigir personagens falando em vários idiomas. Este é o recurso definidor do Kling 3.0. Nenhum outro modelo gera diálogo multilíngue com sincronia labial neste nível.
- A precisão da sincronia labial for crítica. Para vídeos de "cabeça falante", conteúdo explicativo ou qualquer cena onde um personagem fala diretamente para a câmera, a sincronia labial do Kling 3.0 é a mais precisa disponível.
- Você precisar de clipes mais longos com áudio multilíngue. O máximo de 10 segundos do Kling 3.0 com suporte a cinco idiomas oferece uma flexibilidade que o limite de 8 segundos do Veo 3.1 não consegue igualar.
- O projeto for voltado a um público global. O suporte a cinco idiomas significa que um fluxo de trabalho único pode produzir conteúdo para mercados de língua inglesa, chinesa, japonesa, coreana e espanhola.
Escolha o Vidu Q3 para áudio quando:
- Você precisar de um equilíbrio entre diálogo e áudio ambiente. O Vidu Q3 lida com ambos de forma competente sem se destacar especificamente em nenhum, tornando-o um meio-termo versátil.
- O orçamento for intermediário com requisitos de qualidade. A USD0.06/seg, o Vidu Q3 é o mais acessível dos três modelos de áudio nativo — mais barato que o Veo 3.1 Rápido (USD0.09/seg) e abaixo do Kling 3.0 Pro (USD0.095/seg).
- A consistência for mais importante que a qualidade máxima. O Vidu Q3 produz áudio consistentemente bom em diferentes tipos de prompts, o que é valioso para pipelines automatizados onde a revisão manual é impraticável.
- O projeto for apenas em inglês com necessidades moderadas de áudio. Para diálogo em inglês com um som ambiente decente a um preço razoável, o Vidu Q3 é uma opção sólida.
Dicas para Prompts de Áudio
Obter o melhor áudio desses modelos exige técnicas específicas de escrita de prompts. Aqui estão estratégias que funcionam nos três:
1. Seja explícito sobre as fontes sonoras
Os modelos geram áudio com base em dicas sonoras no prompt. Quanto mais específico você for, melhor será o resultado.
- Eficaz: "Chuva batendo em um telhado de zinco, trovão distante roncando, um gato ronronando em um parapeito de janela"
- Menos eficaz: "Dia chuvoso com um gato"
2. Separe as descrições visuais e de áudio
Estruture os prompts para que os elementos visuais e de áudio sejam claramente descritos. Isso ajuda o modelo a dar o peso apropriado a ambos.
- Eficaz: "Um chef fatiando vegetais em uma tábua de madeira — o som crocante da faca no aipo, óleo chiando em uma panela próxima, ventilação da cozinha zumbindo"
- Menos eficaz: "Um chef cozinhando em uma cozinha"
3. Especifique o idioma do diálogo para o Kling 3.0
Ao usar o Kling 3.0 para conteúdo multilíngue, indique explicitamente o idioma e o contexto:
- "Um guia turístico japonês explicando a história de um templo em japonês, falando de forma clara e entusiasmada"
- "Um âncora de telejornal espanhol lendo manchetes em espanhol formal, cenário de estúdio profissional"
4. Use descritores de humor de áudio
Palavras que descrevem a atmosfera do áudio ajudam os três modelos:
- "Ambiente silencioso e íntimo" vs. "Atmosfera barulhenta e movimentada"
- "Sons abafados através de uma janela" vs. "Áudio nítido, em close"
- "Eco em uma catedral" vs. "Acústica de estúdio abafada"
5. Mantenha-se dentro dos limites de duração
Narrativas de áudio precisam caber no limite de tempo do modelo. Não peça por um monólogo de 30 segundos em um modelo de 8 segundos. Projete elementos de áudio que funcionem dentro da restrição:
- Uma frase curta de diálogo (Kling 3.0)
- Uma cena de som ambiente (Veo 3.1)
- Um breve momento de áudio (Vidu Q3)
Limitações de Áudio para Estar Ciente
Em todos os modelos
- A geração de música é limitada. Nenhum desses modelos gera música complexa de forma confiável. Elementos musicais de ambiente (jazz suave, rádio distante) funcionam, mas não espere uma partitura orquestral completa.
- A mixagem de áudio é automática. Você não pode controlar o volume relativo do diálogo vs. som ambiente vs. efeitos. O modelo toma essas decisões internamente.
- Sem saída somente de áudio. Esses modelos geram vídeo com áudio. Se você precisa de geração apenas de áudio, ferramentas de IA dedicadas a áudio são uma escolha melhor.
- A duração limita a narrativa de áudio. Com 8-10 segundos, a trilha de áudio é necessariamente breve. Histórias de áudio complexas ou diálogos extensos não são viáveis em uma única geração.
Limitações específicas do modelo
- Veo 3.1: O diálogo é secundário ao som ambiente. Não conte com ele para conteúdo focado em fala.
- Kling 3.0: A moderação de conteúdo rigorosa pode bloquear prompts inesperadamente, incluindo alguns cenários de áudio inocentes.
- Vidu Q3: Nem o som ambiente nem o diálogo atingem a qualidade máxima dos outros dois modelos. É um generalista, não um especialista.
Perguntas Frequentes
Posso desativar a geração de áudio?
O áudio é gerado nativamente como parte da saída de vídeo. Se você precisar de vídeo silencioso, pode remover a trilha de áudio na pós-processamento usando qualquer ferramenta de edição de vídeo padrão ou comando FFmpeg.
Qual modelo tem a melhor sincronia audiovisual?
Em nossos testes, o Veo 3.1 produz a sincronia audiovisual geral mais precisa para conteúdo ambiental. O Kling 3.0 lidera especificamente para sincronia labial de diálogo. O Vidu Q3 é consistentemente bom, mas não lidera em nenhuma das categorias.
Posso gerar áudio em idiomas além dos cinco que o Kling 3.0 suporta?
Atualmente, apenas o Kling 3.0 oferece geração explícita de áudio multilíngue, limitada a inglês, chinês, japonês, coreano e espanhol. Outros idiomas podem produzir resultados, mas a precisão não é garantida.
Preciso de uma API separada para áudio?
Não. O áudio está incluído automaticamente na saída do vídeo. Não há endpoint de API de áudio separado, nenhum parâmetro adicional para ativar áudio e nenhum custo extra pela geração. O arquivo de vídeo produzido pela API contém ambas as trilhas.
A qualidade do áudio é boa o suficiente para uso comercial?
Sim, para a maioria das aplicações comerciais. O áudio dos três modelos é limpo, contextualmente apropriado e utilizável em produção. Para distribuição de alto nível em transmissão ou cinema, você pode querer aprimorar ou substituir o áudio na pós-produção, mas para redes sociais, conteúdo web, marketing e publicidade, o áudio nativo é suficiente.
Veredito
O "melhor" modelo de vídeo com IA capaz de áudio depende inteiramente do tipo de áudio que seu projeto exige.
O Vidu Q3 é o modelo com áudio mais acessível a USD0.06/seg e oferece os clipes mais longos, com 16 segundos. Ele lida com diálogo e áudio ambiente de forma competente, tornando-o um padrão sólido para tipos de conteúdo mistos.
O Veo 3.1 é o vencedor para áudio ambiente cinematográfico. Se seu conteúdo é ambiental, atmosférico ou focado em marca, e você não precisa de diálogos multilíngues, o Veo 3.1 oferece a maior qualidade audiovisual a partir de USD0.09/seg (Rápido) ou USD0.18/seg (Padrão).
O Kling 3.0 é a única escolha para diálogo multilíngue com sincronia labial. Se seu fluxo de trabalho exige que personagens falem em vários idiomas com movimentos de boca precisos, não há alternativa neste nível de qualidade. O preço (USD0.095/seg para Pro) justifica-se por essa capacidade específica.
A recomendação prática: use os três. Uma única chave de API da Atlas Cloud dá acesso a todos os modelos. Use o Veo 3.1 para seus conteúdos atmosféricos e de marca. Use o Kling 3.0 quando precisar de falantes multilíngues. Use o Vidu Q3 para conteúdo de propósito geral onde tanto a fala quanto o ambiente importam. Uma conta, um saldo, três modelos capazes de áudio e a flexibilidade para escolher a ferramenta certa para cada projeto.
Comece Gratuitamente na Atlas Cloud -- Compare Todos os Modelos de Áudio






