
Laboratórios de IA chineses desenvolveram discretamente alguns dos modelos de programação open-source mais capazes disponíveis atualmente. Para desenvolvedores que acompanharam apenas o lado da Anthropic e da OpenAI no mercado, a amplitude do que está disponível agora na DeepSeek, Moonshot, Zhipu, MiniMax e Alibaba é genuinamente surpreendente.
A pergunta que vale a pena fazer em 2026 não é se esses modelos são bons. É qual deles se encaixa em qual carga de trabalho, quanto custa executá-los em escala e como integrá-los às ferramentas que você já usa. Este guia cobre todos os três: um perfil laboratório por laboratório, uma tabela completa de especificações e custos, um guia prático de roteamento por caso de uso e as configurações para Claude Code, Codex e OpenClaw.
![]()
Por que os Melhores LLMs de Programação Open Source Estão Recebendo Atenção Séria
O ponto de virada foi o DeepSeek V3, lançado em dezembro de 2024. Ele atingiu 89,1% no HumanEval e 42,0% no SWE-bench Verified, competindo com o Claude 3.5 Sonnet e o GPT-4o na época, apesar de ser open-source e usar uma arquitetura de Mistura de Especialistas (MoE) que ativava apenas 37 bilhões de seus 671 bilhões de parâmetros totais por passagem (Relatório Técnico do DeepSeek-V3, dezembro de 2024). A eficiência implicada por essa arquitetura explicava por que os custos de inferência eram tão drasticamente menores.
Esse resultado atraiu a atenção dos desenvolvedores para o ecossistema open-source chinês mais amplo. Descobriu-se que o DeepSeek não era uma anomalia. A série Kimi K2, da Moonshot AI, liderava silenciosamente os benchmarks de contexto longo. A série Qwen2.5-Coder, da Alibaba, liderava os rankings específicos de código. A linha GLM-5, da Zhipu, produzia resultados estruturados precisos essenciais para pipelines de agentes.
A consequência prática para os desenvolvedores: cinco laboratórios diferentes agora disponibilizam modelos capazes de lidar com cargas de trabalho de programação em produção, com pesos abertos ou acesso via API comercial, a taxas bem abaixo das alternativas proprietárias.
Os Laboratórios por Trás dos Melhores LLMs de Programação Open Source
DeepSeek: Design Focado em Código e Eficiência MoE
A DeepSeek AI, fundada em 2023 e apoiada pela High-Flyer Capital (um fundo de hedge quantitativo chinês), construiu seu foco em programação no modelo desde o início. O DeepSeek-Coder foi um dos primeiros modelos dedicados à geração de código a atrair atenção séria da comunidade open-source. As séries V3 e V4 ampliaram isso para o raciocínio geral, mantendo forte o desempenho nos benchmarks de programação.
A arquitetura MoE vale a pena ser compreendida porque explica a precificação. Ao ativar apenas uma fração dos parâmetros por token, o custo computacional por solicitação é significativamente menor do que um modelo denso de qualidade equivalente. Essa eficiência é repassada para o preço da API, razão pela qual a taxa de entrada de 0,23 créditos por mil tokens do DeepSeek V4 Flash é alcançável sem sacrificar a qualidade em tarefas mais simples.
Moonshot AI (Kimi), Zhipu AI (GLM), MiniMax e Alibaba (Qwen)
Moonshot AI (fundada em 2023, Pequim) construiu sua reputação em inferência de contexto longo. A série Kimi K2 possui uma janela de contexto de 262 mil tokens e foi projetada para tarefas com muitos documentos e códigos, onde encaixar uma base de código grande em uma única chamada é importante.
Zhipu AI (fundada em 2019, um spin-off do laboratório KEG da Universidade Tsinghua) é uma das empresas de IA chinesas mais antigas. A série GLM passou por cinco gerações, cada iteração melhorando a confiabilidade da saída estruturada e o seguimento de instruções. O GLM-5.1 reflete anos de trabalho de alinhamento em execução precisa de tarefas.
MiniMax (fundada em 2021) expandiu-se do trabalho multimodal para modelos de programação com a série M2. O MiniMax M2.5 e M2.7 cobrem uma faixa de custo-benefício que preenche bem o nível intermediário.
A equipe Qwen do Alibaba construiu o Qwen3.6-plus sobre uma forte linhagem de modelos focados em programação. A série tem sido consistentemente forte na geração de código multilíngue, e a janela de contexto de 256K+ situa-se no topo das opções disponíveis (QwenLM GitHub, 2025).
Comparação dos Melhores LLMs de Programação Open Source: Contexto, Custo e Especificações
Aqui está a tabela completa dos modelos atuais ordenados por taxa de entrada, para que a estrutura de custos seja imediatamente legível:
| Modelo | Laboratório | Contexto | Taxa Ent. | Taxa Saída | Cache Write | vs Oficial |
| DeepSeek V4 Flash | DeepSeek AI | 1M | 0.23 | 0.46 | 0.046 | -50% |
| DeepSeek V3.2 | DeepSeek AI | 160K | 0.42 | 0.62 | 0.193 | -55% |
| MiniMax M2.5 | MiniMax | 200K | 0.65 | 2.18 | 0.109 | -45% |
| Kimi K2.5 | Moonshot AI | 262K | 1.09 | 5.45 | 0.182 | -45% |
| Kimi K2.6 | Moonshot AI | 262K | 1.72 | 7.26 | 0.290 | -45% |
| GLM-5 | Zhipu AI | 200K | 1.82 | 5.81 | 0.363 | -45% |
| MiniMax M2.7 | MiniMax | 200K | 2.36 | 4.00 | 0.109 | -45% |
| GLM-5.1 | Zhipu AI | 200K | 2.54 | 7.99 | 0.472 | -45% |
| DeepSeek V4 Pro | DeepSeek AI | 1M | 2.87 | 5.75 | 0.231 | -50% |
| Qwen3.6-plus | Alibaba | 256K+ | 3.30 | 9.90 | 0.660 | -50% |
As taxas são créditos por 1.000 tokens. "vs Oficial" representa a economia em comparação com a taxa de API direta de cada modelo.
Alguns pontos se destacam. Primeiro, o DeepSeek V4 Flash (0,23 de entrada) e o V4 Pro (2,87) são do mesmo laboratório, criando uma diferença de 12,5x entre o nível mais barato e o mais capaz dentro da mesma família de modelos. Segundo, o Kimi K2.5 (1,09 de entrada) oferece uma janela de contexto de 262K a um preço intermediário, tornando-o atraente para trabalhos de contexto longo sem saltar para a taxa total do V4 Pro. Terceiro, a taxa de saída do Qwen3.6-plus em 9,90 é a mais alta do grupo, sugerindo conclusões mais longas e completas como característica de design.
Onde Cada LLM de Programação Open Source Chinês Melhor se Encaixa
Esta é a seção prática. As taxas acima se traduzem em decisões reais de roteamento quando você está executando uma sessão de programação com agentes.
Tarefas leves e de segundo plano: DeepSeek V4 Flash
Docstrings, renomeação de variáveis, conclusões simples, conversões de formato e todas as chamadas utilitárias que um agente de programação faz automaticamente em segundo plano. Com 0,23 de entrada e 0,46 de saída, este é o modelo mais barato do grupo por uma margem larga. Quando o Claude Code roteia tarefas de segundo plano através do slot do modelo Haiku, apontar esse slot para o DeepSeek V4 Flash mantém o ruído de fundo barato enquanto sua sessão principal usa um modelo mais capaz.
Programação com orçamento e desempenho sólido: DeepSeek V3.2 e MiniMax M2.5
O DeepSeek V3.2 carrega a arquitetura V3 com 55% de desconto nas taxas oficiais e uma janela de contexto de 160K. Para desenvolvedores que desejam uma capacidade de codificação sólida sem pagar os preços integrais do V4 Pro, o V3.2 é uma opção prática. O MiniMax M2.5, com 0,65 de entrada, preenche um slot similar com uma janela de 200K, útil quando o contexto importa mais do que o menor preço absoluto.
Cargas de trabalho de contexto longo: Kimi K2.5 e K2.6
Ambos os modelos Kimi oferecem janelas de contexto de 262K. Para passar grandes porções de uma base de código, analisar longos históricos de conversação ou tarefas de refatoração de múltiplos arquivos onde você precisa de tudo em um único contexto, o Kimi K2.5 (1,09 de entrada) oferece a janela sem pagar preços de topo de linha. O K2.6 (1,72 de entrada) adiciona capacidade sobre a vantagem de contexto do K2.5 para casos onde a qualidade importa mais que o custo puro.
Saída estruturada e precisão de instruções: GLM-5 e GLM-5.1
Os modelos GLM da Zhipu AI têm uma força particular na adesão a instruções. Para pipelines que precisam de saída estruturada confiável (esquemas JSON específicos, artefatos de código formatados, formas de resposta de API consistentes), vale a pena testar o GLM-5 (1,82) e o GLM-5.1 (2,54) contra outros modelos nessas tarefas. Suas taxas de saída estão na faixa mais alta, o que reflete sua tendência a conclusões completas e detalhadas.
Raciocínio de topo de linha: DeepSeek V4 Pro e Qwen3.6-plus
Para decisões de arquitetura complexas, depuração de interações entre múltiplos sistemas ou tarefas onde a qualidade da primeira geração importa (porque primeiros rascunhos ruins causam loops de repetição caros), o V4 Pro e o Qwen3.6-plus são o nível superior. A janela de contexto de 1M do V4 Pro é sua especificação de destaque; o Qwen3.6-plus, com 256K+, situa-se no limite superior fora da família DeepSeek.
Roteamento de Modelos: A Estratégia de LLM de Programação Open Source Mais Subutilizada
A otimização de maior alavancagem para desenvolvedores que usam qualquer um desses LLMs de programação chineses não é escolher o melhor modelo único. É rotear diferentes tipos de tarefas para diferentes níveis dentro da mesma sessão.
Considere uma sessão típica de programação com agentes: planejar a abordagem (complexa, precisa do V4 Pro), escrever um algoritmo central (complexo, V4 Pro), gerar casos de teste (nível intermediário, MiniMax M2.5 ou Kimi K2.5), escrever docstrings para novas funções (leve, V4 Flash), executar observações de leitura de arquivo (leve, V4 Flash). Se você usasse o V4 Pro para tudo, cada uma dessas etapas de nível "flash" custaria 12,5x mais do que o necessário.
A matemática torna-se concreta rapidamente. Suponha que 60% das 50 chamadas de API da sua sessão sejam tarefas simples com uma média de 2.000 tokens de entrada + 500 de saída cada. Executá-las no V4 Flash:
- Custo: 30 chamadas × (2.000 × 0,23 + 500 × 0,46) = 30 × (460 + 230) = 20.700 créditos
Executando as mesmas 30 chamadas no V4 Pro:
- Custo: 30 chamadas × (2.000 × 2,87 + 500 × 5,75) = 30 × (5.740 + 2.875) = 258.450 créditos
Isso é uma diferença de 12,5x apenas nessas 30 chamadas. O roteamento de modelos paga por si mesmo imediatamente.
Como Escolher o Melhor LLM de Programação Open Source para o Seu Fluxo de Trabalho
Uma árvore de decisão que cobre a maioria das situações dos desenvolvedores:
Você precisa de contexto máximo por solicitação: DeepSeek V4 Pro (1M) ou Qwen3.6-plus (256K+). Ambos lidam com entradas de bases de código grandes sem fragmentação.
O custo é a restrição principal: DeepSeek V4 Flash para tarefas simples, DeepSeek V3.2 ou MiniMax M2.5 para trabalho de complexidade média.
Você precisa de saída estruturada confiável: Comece com o GLM-5.1 e teste-o contra os requisitos específicos do seu esquema.
Você está construindo um pipeline de agentes de várias etapas: Roteie pela complexidade da etapa. Use o Flash para etapas utilitárias, Kimi K2.5 ou GLM-5 para raciocínio de nível intermediário, V4 Pro para planejamento e depuração.
Você quer um único modelo para testar primeiro: O DeepSeek V4 Pro é o padrão natural para desenvolvedores que avaliam LLMs chineses pela primeira vez. Ele é bem documentado, tem a cobertura comunitária mais ampla em (r/LocalLLaMA) e oferece qualidade de programação de topo de linha.
O problema prático: rotear entre modelos de forma eficiente exige que todos fiquem atrás da mesma chave de API e URL base. Manter dez contas de API separadas não é viável. É isso que um gateway unificado resolve: um endpoint, uma chave, a seleção de modelo é um parâmetro.
Executando o Melhor LLM de Programação Open Source em Suas Ferramentas de Código
O Atlas Cloud Coding Plan coloca todos os dez modelos cobertos neste guia atrás de uma única chave de API e URL base, a 45-55% abaixo de suas taxas de API diretas. A configuração para cada principal ferramenta de programação segue abaixo.
A nota sobre a URL base para economizar uma sessão de depuração: O Claude Code usa https://api.atlascloud.ai sem o sufixo /v1. Todas as outras ferramentas (Codex, OpenClaw, OpenCode, Cursor) usam https://api.atlascloud.ai/v1 com o sufixo. Errar isso gera erros de autenticação que não apontam diretamente para a causa.
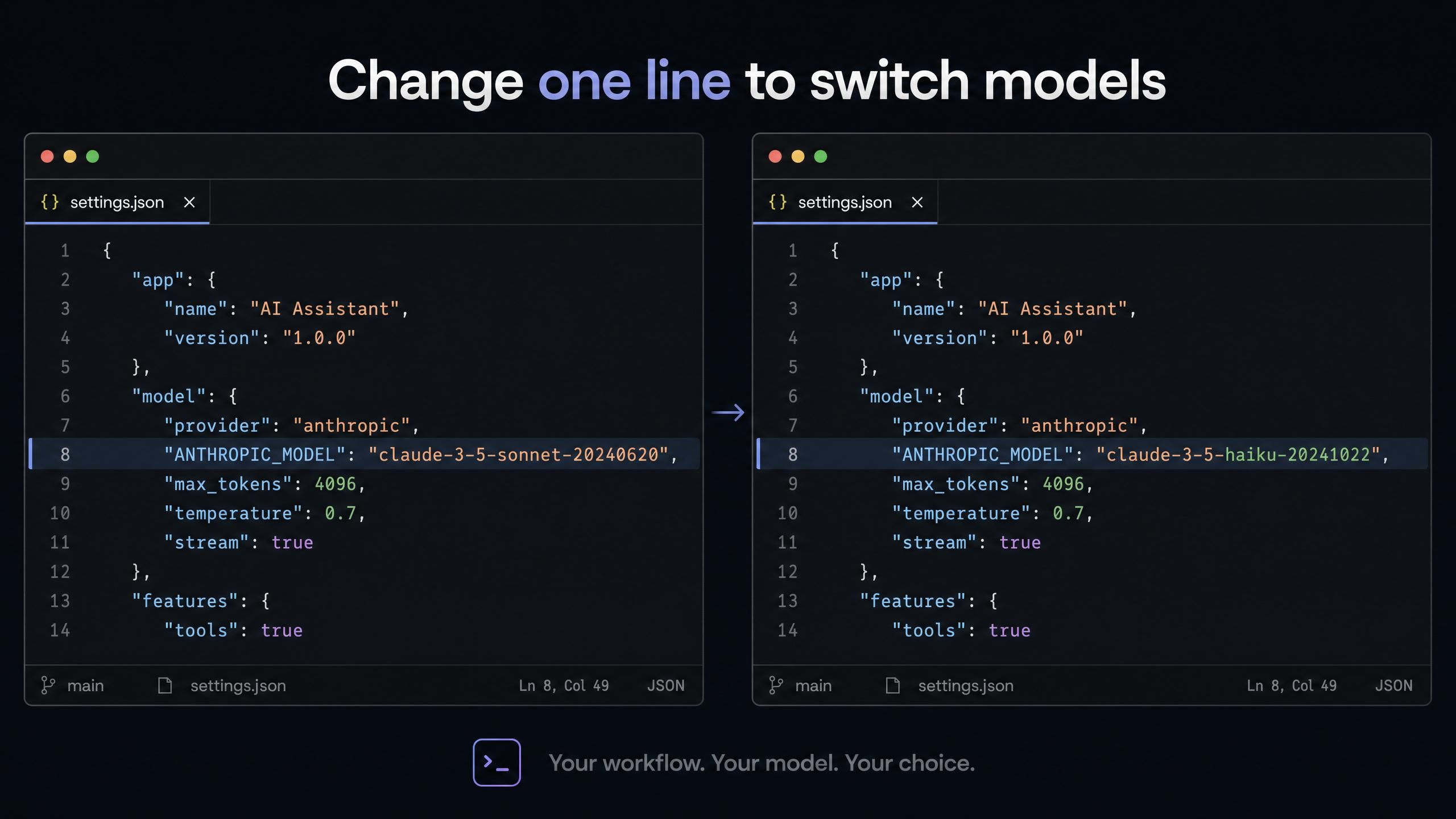
Claude Code (~/.claude/settings.json no macOS/Linux):
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "sua-chave-api-atlas", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "deepseek-ai/deepseek-v4-pro", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-ai/deepseek-v4-flash", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-ai/deepseek-v4-pro", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
O campo ANTHROPIC_DEFAULT_HAIKU_MODEL mapeia para o slot de tarefas de segundo plano do Claude Code. Colocar o DeepSeek V4 Flash lá significa que todas as chamadas utilitárias automáticas (leituras de arquivos, verificações de status, observações) usam o modelo disponível mais barato. Seus prompts principais usam o V4 Pro. Você obtém roteamento de modelo automático sem qualquer lógica de roteamento.
Para trocar para o GLM-5.1 em vez do V4 Pro, altere deepseek-ai/deepseek-v4-pro para zai-org/glm-5.1 nos dois campos Sonnet/principal.
Codex (~/.codex/config.toml + ~/.codex/auth.json):
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-pro" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
plaintext1{ 2 "OPENAI_API_KEY": "sua-chave-api-atlas" 3}
OpenClaw: Execute openclaw onboard, selecione QuickStart, depois Custom Provider. Insira https://api.atlascloud.ai/v1 como a URL base, cole sua chave, depois insira o ID do modelo (ex: moonshotai/kimi-k2.5) e escolha o protocolo compatível com OpenAI.
Trocar de modelo em qualquer uma dessas configurações é uma alteração de uma linha. A chave de API e a URL base permanecem as mesmas independentemente do modelo que você selecionar.
Melhor LLM de Programação Open Source: Perguntas Comuns
O DeepSeek é realmente o melhor LLM de programação open source?
Para a maioria dos desenvolvedores iniciantes, o DeepSeek V4 Pro é a escolha natural baseada na cobertura da comunidade, histórico de benchmarks e a combinação de uma janela de contexto de 1M com preços competitivos. Mas "melhor" depende muito do seu tipo de tarefa. Para trabalho de contexto longo, o Kimi K2.5 ou K2.6 oferece 262K tokens a uma taxa menor. Para tarefas de saída estruturada, o GLM-5.1 merece testes. O ponto é que o "melhor" muda dependendo do que você está construindo.
Como esses modelos se comparam ao Claude Sonnet ou GPT-4o na programação?
Nos benchmarks de programação padrão, a diferença entre os melhores modelos open-source e os modelos proprietários dos EUA diminuiu consideravelmente desde 2024. O DeepSeek V3 igualou o Claude 3.5 Sonnet em vários benchmarks em seu lançamento. Onde os modelos proprietários ainda mantêm uma vantagem é na interpretação nuançada de instruções e em tarefas que se beneficiam de ajuste fino extensivo via RLHF. Para a grande maioria das tarefas de geração de código, refatoração e depuração, a diferença prática para a maioria dos desenvolvedores é pequena.
Posso usar vários LLMs de programação open source no mesmo pipeline?
Sim. Quando todos os modelos compartilham uma URL base e uma chave de API através de um gateway, você pode especificar um ID de modelo diferente por solicitação. Na prática, isso significa que você pode usar o DeepSeek V4 Flash para uma etapa, o Kimi K2.5 para outra e o V4 Pro para uma terceira, tudo dentro de um único fluxo de trabalho automatizado, sem gerenciar múltiplas contas ou contextos de autenticação.
Qual modelo devo testar primeiro se nunca usei um LLM open source?
Comece com o DeepSeek V4 Pro. Ele tem a maior documentação, a discussão comunitária mais ampla e o perfil de desempenho mais claro. Uma vez que você tenha estabelecido uma base em suas tarefas reais, teste o Kimi K2.5 em etapas pesadas de contexto e o DeepSeek V4 Flash em chamadas utilitárias de segundo plano. A diferença de custo entre esses dois testes mostrará se o roteamento de modelos faz sentido para o seu fluxo de trabalho.
Os LLMs open source são seguros para usar com código empresarial?
Isso depende do seu modelo de implantação. Para acesso via API através de um gateway de terceiros, aplicam-se as políticas de manuseio de dados desse gateway. Modelos de pesos abertos que podem ser auto-hospedados dão a você controle total sobre para onde o código vai. Desenvolvedores no r/LocalLLaMA discutiram isso extensivamente, e o consenso é que o uso via API precisa do mesmo rigor de manuseio de dados que você aplicaria a qualquer API de terceiros, não uma categoria especial de preocupação.
O Veredito sobre os Melhores LLMs de Programação Open Source
Cinco laboratórios agora disponibilizam modelos capazes de lidar com trabalho sério de programação em produção, e eles cobrem uma faixa de custo e capacidade larga o suficiente para que a seleção de modelo "tamanho único" signifique desperdício de dinheiro.
O manual prático: escolha um gateway que lhe dê acesso a todos eles sob uma única chave, estabeleça sua base no DeepSeek V4 Pro e, em seguida, use o guia de roteamento acima para mudar tarefas mais simples para níveis mais baratos. Para a maioria dos desenvolvedores que executam sessões de programação com agentes, apenas esse roteamento reduz custos significativamente sem alterar a qualidade da saída nas tarefas que importam.
Especificações e taxas de modelos baseadas na documentação do Atlas Cloud Coding Plan em maio de 2026. Valores de benchmark do DeepSeek V3 do Relatório Técnico do DeepSeek-V3, dezembro de 2024. As taxas estão sujeitas a alterações; verifique os números atuais com cada provedor antes de tomar uma decisão de faturamento.






