
A maioria dos desenvolvedores assume que a Codex CLI funciona como um chatbot: você envia uma mensagem, o modelo responde e pronto. Não é isso que acontece. A Codex executa um loop de agente, o que significa que cada tarefa envolve múltiplas chamadas de API, e a janela de contexto se expande a cada iteração. Quando a Codex termina uma tarefa de complexidade moderada, a contagem total de tokens costuma ser de três a cinco vezes o que você esperaria de uma chamada única.
Essa é a causa raiz por trás de quase todas as histórias de "atingi meu limite". Você não está lutando contra uma política de limites de taxa (rate limit). Você está lidando com a economia natural de um fluxo de trabalho com agentes, e essa economia se acumula rapidamente.
Depois que você entende de onde o custo realmente vem, as soluções alternativas tornam-se óbvias, em vez de um jogo de adivinhação.
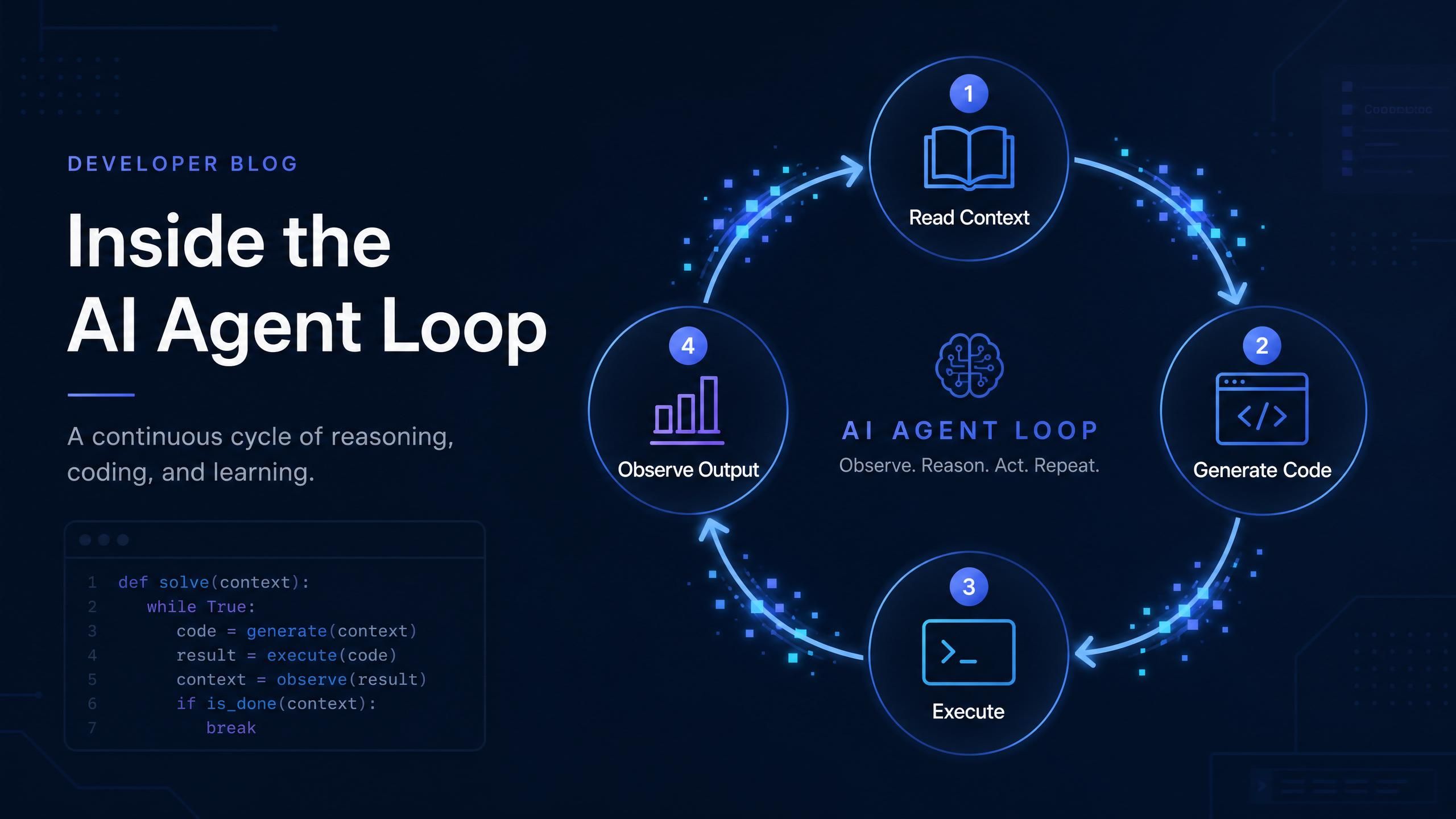
Como a Codex CLI realmente acumula custos durante uma sessão
Uma tarefa típica da Codex que leva quatro iterações não custa 4x o preço de uma chamada. Custa consideravelmente mais, porque o contexto aumenta a cada turno.
Aqui está o que acontece nos bastidores. Na primeira iteração, a Codex lê os arquivos do seu projeto mais a descrição da tarefa, envia cerca de 5.000 a 7.000 tokens de entrada para o modelo e recebe uma resposta. Na segunda iteração, ela inclui o histórico da conversa anterior, além de novas observações da execução do código gerado. A contagem de tokens de entrada para essa chamada pode saltar para 8.000 ou 10.000. Na quarta iteração, o contexto acumulado pode chegar a 14.000 tokens de entrada para o que, teoricamente, ainda é a mesma tarefa.
Crescimento do contexto em uma tarefa de 4 iterações da Codex
| Iteração | Tokens de entrada |
|---|---|
| Iteração 1 | ~5.000 |
| Iteração 2 | ~7.000 |
| Iteração 3 | ~9.500 |
| Iteração 4 | ~14.000 |
| Total | ~35.500 |
O tamanho do contexto se acumula ao longo das iterações em uma sessão com agentes. Uma tarefa de 4 iterações pode consumir 35.500 tokens de entrada totais em comparação com 5.000 de uma chamada de turno único. As contagens reais variam de acordo com o tamanho do projeto e o contexto dos arquivos.
A implicação prática: uma tarefa de quatro iterações não custa 4x uma chamada de turno único. O crescimento do contexto significa que ela custa perto de 7x ou 8x mais. Para este exemplo, são aproximadamente 35.500 tokens de entrada e 4.000 tokens de saída ao longo da tarefa completa. O modelo que você escolhe determina se essa tarefa custará 9.000 créditos ou 120.000 créditos, na mesma Codex CLI com a mesma descrição de tarefa.
Essa diferença de 13x é onde reside a verdadeira solução para os limites de uso da Codex: não no controle de solicitações (throttling), mas na escolha do modelo que executa o loop.
Solução para limites de uso da Codex: Escopo de arquivos antes de tudo
Esta é a otimização que não custa nada e tem o maior efeito imediato.
A Codex lê os arquivos do seu projeto para construir o contexto antes de fazer qualquer chamada de API. Ela respeita seu .gitignore, mas a maioria das bases de código tem grandes quantidades de conteúdo que o .gitignore não exclui: arquivos de declaração de tipo, documentação de fornecedores, diretórios de saída compilados, fixtures de teste, dados de seed, CSS ou SVGs gerados. Tudo isso entra na janela de contexto da primeira iteração e aumenta o custo base de cada chamada subsequente.
A correção é a exclusão deliberada. Adicione um arquivo .codexignore à raiz do seu projeto, usando a mesma sintaxe do .gitignore. Padrões comuns que vale a pena adicionar:
plaintext1dist/ 2.next/ 3build/ 4node_modules/ # caso o .gitignore tenha lacunas 5*.d.ts # arquivos de declaração TypeScript 6*.min.js 7*.min.css 8test/fixtures/ 9test/snapshots/ 10docs/vendor/
Alternativamente, quando a tarefa estiver restrita a um módulo específico, execute a Codex de dentro desse diretório em vez da raiz do projeto. O agente lê a partir do seu diretório de trabalho, então uma sessão cd packages/auth && codex vê apenas os arquivos daquele pacote, em vez de todo o monorepo.
Desenvolvedores discutindo isso no r/LocalLLaMA relatam consistentemente que o contexto de arquivos não controlado é o principal motor de gastos inesperados com API em ferramentas de agentes. Fazer isso corretamente antes de tocar em qualquer outra configuração geralmente reduz as contagens de tokens por sessão de 30 a 60 por cento em projetos de médio porte.
Executar a Codex a partir do subdiretório do pacote relevante em vez da raiz do monorepo em um projeto com múltiplos pacotes reduziu o contexto por tarefa de ~18.000 tokens para ~5.000 tokens na primeira chamada. Essa diferença se acumula a cada iteração.
A solução para limites de uso da Codex que muda a conta a longo prazo
Depois de restringir o contexto de arquivos, a próxima correção estrutural é o modelo que você está executando.
A Codex CLI suporta provedores de API personalizados através de seu config.toml. Qualquer provedor que implemente o formato de chat completions da OpenAI funciona como uma substituição direta. Isso significa que você pode executar exatamente o mesmo fluxo de trabalho da Codex CLI, mas alimentado por um modelo diferente, com um custo por token substancialmente diferente.
Por que isso importa? Porque o multiplicador de créditos (ou taxa por token) é multiplicado por cada token em cada iteração. Em uma tarefa de 4 iterações consumindo 35.500 tokens de entrada e 4.000 tokens de saída, mudar de um modelo de multiplicador alto para um de multiplicador baixo não é um ajuste pequeno. É a diferença entre consumir 9.545 créditos e 119.145 créditos para a mesma tarefa.
O Coding Plan da Atlas Cloud oferece um conjunto de modelos de código aberto com 45 a 55 por cento de desconto sobre as taxas oficiais da API, todos acessíveis através de uma única chave de API em um endpoint compatível com OpenAI. Você aponta a Codex para https://api.atlascloud.ai/v1, define seu ID de modelo, e nada mais muda no seu fluxo de trabalho.
Lendo os multiplicadores: Qual solução de limites de uso da Codex se adapta a cada tarefa
Aqui está o cálculo que torna a seleção do modelo algo concreto. Usando nossa tarefa de 4 iterações (35.500 tokens de entrada, 4.000 tokens de saída no total), aqui está o custo em créditos por tarefa entre os modelos disponíveis:
Créditos por tarefa de 4 iterações da Codex por modelo
| Modelo | Créditos / Tarefa | vs. Mais barato |
|---|---|---|
| deepseek-v4-flash | 9.545 | 🟢 base |
| deepseek-v3.2 | 17.390 | 1.8x |
| minimax-m2.5 | 31.845 | 3.3x |
| kimi-k2.5 | 60.695 | 6.4x |
| deepseek-v4-pro | 119.145 | 12.5x |
| glm-5.1 | 122.025 | 12.8x |
Fonte: Calculado usando multiplicadores publicados pela Atlas Cloud, junho de 2026. O DeepSeek V4-Flash a 9.545 é 12,5x mais barato por tarefa do que o DeepSeek V4-Pro a 119.145 para sessões onde qualquer um dos modelos concluiria a tarefa.
Com 800.000 créditos diários no plano Starter ($10/mês), você pode executar:
- DeepSeek V4-Flash: 800.000 / 9.545 = 83 tarefas de quatro iterações por dia
- DeepSeek V4-Pro: 800.000 / 119.145 = 6,7 tarefas por dia
No plano Lite ($20/mês, 2,2 milhões de créditos por dia baseados na configuração atual de níveis):
- DeepSeek V4-Flash: 2.200.000 / 9.545 = 230 tarefas por dia
- DeepSeek V4-Pro: 2.200.000 / 119.145 = 18 tarefas por dia
A estrutura prática é a seguinte: o DeepSeek V4-Flash lida bem com a vasta maioria das tarefas da Codex. Escrever funções utilitárias, gerar testes, corrigir erros de lint, renomear variáveis, estruturar boilerplate — nada disso exige capacidade de raciocínio de ponta. O V4-Flash suporta uma janela de contexto de 1 milhão de tokens e completa essas tarefas com competência. O V4-Pro e o Kimi K2 valem a pena para problemas genuinamente difíceis: refatoração complexa de vários arquivos, depuração de problemas obscuros em produção, trabalho com frameworks desconhecidos.
Usar o modelo certo para a tarefa certa não é um compromisso na qualidade. É não usar uma marreta para pregar um prego de acabamento.
A diferença entre o V4-Flash e o V4-Pro não é apenas "barato vs. qualidade". Em tarefas rotineiras da Codex, a diferença de qualidade é marginal. A diferença de custo é de 12,5x. Reservar o V4-Pro para sessões genuinamente complexas é a otimização de maior alavancagem após o escopo de arquivos.
Solução para limites de uso da Codex via limites de sessão
Uma mudança de comportamento que se acumula significativamente ao longo de uma semana: seja deliberado sobre quando iniciar uma nova sessão da Codex em vez de continuar uma existente.
Cada sessão acumula histórico de conversas. Quanto mais longa a sessão, maior o contexto base para cada chamada subsequente. Uma sessão que começa com um primeiro turno de 5.000 tokens e executa seis trocas pode ter um contexto de 18.000 tokens no final. Se você mudar para uma nova tarefa não relacionada dentro da mesma sessão, estará pagando para incluir todo aquele contexto anterior irrelevante em cada nova chamada.
Iniciar uma sessão nova não custa nada. A Codex inicializa de forma limpa e lê apenas os arquivos relevantes para o seu diretório de trabalho atual. A regra de ouro aproximada:
- Tarefa concluída de forma limpa e a próxima tarefa é independente? Comece uma nova.
- Mudando de um módulo para outro sem código compartilhado? Comece uma nova.
- Continuando a iterar no mesmo arquivo com o mesmo objetivo? Continue.
- Fazendo a transição da implementação para a documentação? Comece uma nova.
Isso é menos dramático do que o escopo de arquivos ou a seleção de modelo, mas soma uma economia significativa ao longo de uma semana de trabalho, especialmente durante sprints intensivos.
Solução para limites de uso da Codex: Como funcionam os créditos com renovação diária na prática
Entender o modelo de faturamento ajuda você a planejar o uso de forma realista.
Um pool de créditos de API padrão oferece X tokens por mês para você gastar como quiser. O problema estrutural: dias de codificação pesada esgotam o pool rapidamente, deixando o resto do mês com menos margem do que o planejado. Se você queimar 40 por cento do seu orçamento mensal em dois dias intensivos de sprint, você estará gerenciando esse déficit pelas próximas três semanas.
O modelo de renovação diária funciona de forma diferente. Você recebe um número fixo de créditos por dia, e eles são renovados à meia-noite, independentemente de quanto você usou no dia anterior. Uma terça-feira leve não penaliza uma quinta-feira pesada. Cada dia começa com o mesmo orçamento diário completo.
Alocação diária de créditos por nível de plano
Todos os níveis são renovados diariamente à meia-noite · Pacotes pré-pagos (pay-as-you-go) se acumulam como excedente
| Plano | Preço | Créditos Diários |
|---|---|---|
| Starter | $10 / mês | 800K / dia |
| Lite | $20 / mês | 2,2M / dia |
| Plus | $50 / mês | 4,8M / dia |
| Max | $100 / mês | 9,8M / dia |
Fonte: Coding Plan da Atlas Cloud, junho de 2026 · Créditos não utilizados não se acumulam para o dia seguinte, mas você também nunca começa um dia com um orçamento esgotado de sessões pesadas anteriores.
Quando seus créditos diários acabam em uma sessão particularmente intensa, pacotes de recarga pré-pagos preenchem a lacuna automaticamente. Esses pacotes são válidos por 90 dias, você pode acumular múltiplos pacotes simultaneamente e eles só são utilizados após o esgotamento dos créditos da sua assinatura diária. A assinatura cobre sua base; os pacotes cobrem o excedente.
O upgrade entre níveis é calculado proporcionalmente se você mudar de ideia no meio do ciclo. A fórmula é simples: (novo preço - preço atual) × (dias restantes / 30). Mudar do Starter para o Lite com 14 dias restantes custa ($20 - $10) × (14 / 30) = $4,67. O limite maior de créditos diários é aplicado imediatamente após o upgrade.
Configurando sua solução para limites de uso da Codex: Configuração completa
A configuração para apontar a Codex CLI para um provedor personalizado consiste em dois arquivos. No macOS ou Linux:
Passo 1: Crie ou edite ~/.codex/config.toml
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-flash" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
Passo 2: Crie ou edite ~/.codex/auth.json
plaintext1{ 2 "OPENAI_API_KEY": "sua-chave-api-atlas" 3}
A flag requires_openai_auth = true diz à Codex para ler a chave de API do campo OPENAI_API_KEY no auth.json. Sua chave de API vem do painel de gerenciamento de plano na Atlas Cloud após a compra de um Coding Plan.
Para mudar de modelo em uma sessão específica, altere a linha model no config.toml. Se você quiser usar um modelo mais pesado para uma tarefa complexa, mude para deepseek-ai/deepseek-v4-pro ou moonshotai/kimi-k2.6 e volte para o modelo mais leve depois. É uma edição de uma única linha.
Após a configuração, inicie a Codex normalmente:
plaintext1codex
Selecione a opção para pular a verificação de atualização, e você estará executando a Codex com os modelos da Atlas Cloud. A interface e os comandos são idênticos à experiência padrão da Codex.
Perguntas frequentes sobre soluções para limites de uso da Codex
Por que a Codex usa mais tokens do que o esperado por tarefa?
A Codex executa um loop de agente em vez de uma única chamada de API. Cada iteração inclui o histórico acumulado da conversa mais novas observações da execução do código. Em uma tarefa de quatro iterações, a janela de contexto na quarta iteração pode ser duas vezes maior que a da primeira. O consumo total de tokens em todas as iterações costuma ser de três a cinco vezes o que uma chamada única custaria para a mesma tarefa.
Qual é a melhor solução de limites de uso da Codex para quem está começando?
Comece com o escopo de arquivos: adicione um arquivo .codexignore para excluir diretórios dist/, build/, arquivos *.d.ts, fixtures de teste e outro conteúdo não essencial. Isso é gratuito e costuma reduzir o tamanho do contexto de 30 a 60 por cento em projetos de médio porte. Feito isso, a próxima mudança com maior impacto é mudar para um modelo de multiplicador baixo, como o DeepSeek V4-Flash, para tarefas rotineiras, o que reduz o consumo de créditos por tarefa em até 12x em comparação com modelos mais pesados nas mesmas sessões.
Posso executar a Codex com a Atlas Cloud no Windows?
Sim. No Windows, coloque seus arquivos de configuração em %USERPROFILE%\.codex\config.toml e %USERPROFILE%\.codex\auth.json. O formato do arquivo e os nomes dos campos são idênticos às versões de macOS/Linux. A URL base, a chave de API e o ID do modelo funcionam da mesma forma em todas as plataformas.
O que acontece quando minha alocação diária de créditos acaba?
Se você tiver pacotes de créditos pré-pagos ativos, o uso continuará automaticamente, consumindo esses pacotes assim que seus créditos de assinatura diária forem esgotados. Se você não tiver pacotes, novas solicitações serão recusadas até que seus créditos diários sejam renovados à meia-noite. Você pode comprar pacotes de recarga a qualquer momento no painel do plano; eles são ativados imediatamente e são válidos por 90 dias.
Preciso mudar meu fluxo de trabalho da Codex após apontá-la para um provedor personalizado?
Não. Os comandos, flags e comportamento da Codex CLI são idênticos, independentemente do provedor subjacente. A única diferença visível é o modelo respondendo às suas tarefas. Se você configurou um modelo no qual a Codex não foi treinada nativamente, as respostas podem parecer ligeiramente diferentes em estilo, mas a operação da ferramenta permanece a mesma. A maioria dos desenvolvedores não percebe nenhuma interrupção no fluxo de trabalho após a alteração inicial na configuração.
Conclusão
O insight central deste artigo é que os custos da Codex CLI não são misteriosos. Eles vêm de um lugar previsível: contexto que cresce ao longo das iterações, multiplicado pela taxa por token que seu modelo cobra. Depois que você vê isso claramente, as intervenções tornam-se mecânicas:
- Reduza o que a Codex lê através de escopo de arquivos (grátis, alto impacto)
- Combine o modelo com a complexidade da tarefa (altera o custo em até 12x por tarefa)
- Inicie sessões novas quando as tarefas forem independentes (evita o inchaço do contexto acumulado)
- Use um plano de créditos com renovação diária para evitar o problema de esgotamento no meio do mês
Qualquer uma dessas ações ajuda. Todas as quatro juntas tornam a Codex sustentável para uso diário intenso, sem atingir limites ou ver sua conta de API subir de forma imprevisível.
Se você quiser testar a rota de provedor personalizado, o Coding Plan da Atlas Cloud suporta a Codex junto com Claude Code, OpenCode, Cursor e chamadas diretas de API. O nível Starter a $10/mês e 800K créditos diários é um ponto de partida razoável; você pode fazer upgrade no meio do ciclo de forma proporcional se precisar de mais.
Escolher entre DeepSeek V4-Flash e V4-Pro para diferentes tipos de tarefa na Codex → guia de seleção de modelo para fluxos de trabalho de codificação com agentes






