
Se você está avaliando modelos open-source para codificação, raciocínio ou pipelines de agentes, o Kimi K2.6 e o GLM 5.1 certamente aparecerão na sua lista de opções. Ambos vêm de laboratórios de IA chineses líderes, funcionam com APIs compatíveis com a OpenAI e são capazes de realizar os tipos de tarefas complexas com as quais os desenvolvedores realmente se importam.
O problema é que eles não são intercambiáveis. Eles possuem janelas de contexto diferentes, estruturas de custo distintas e pontos fortes que se sobressaem em casos de uso específicos. Escolher o modelo errado para sua carga de trabalho significa ou subutilizar o desempenho ou pagar a mais por uma capacidade que você não precisa.
Este artigo detalha as diferenças reais entre os dois modelos: o que as especificações realmente significam na prática, onde cada modelo se destaca ou deixa a desejar, e como os números se comportam quando você está rodando qualquer um deles em escala.

Kimi K2.6 vs GLM 5.1: O Resumo Rápido
O Kimi K2.6 é o modelo mais recente da Moonshot AI em sua série K2, que representa sua linha carro-chefe atual. A Moonshot é a empresa por trás do assistente Kimi, e o K2.6 é sua aposta em raciocínio de longo contexto e preços competitivos. A janela de contexto de 262K é um de seus principais destaques.
O GLM 5.1 vem da Zhipu AI, uma das organizações de pesquisa em IA mais estabelecidas da China. A série GLM (General Language Model) vem evoluindo através de várias gerações, e o 5.1 é a oferta de topo atual da Zhipu. Ele carrega uma forte reputação na comunidade open-source por sua precisão no cumprimento de instruções e qualidade de saída estruturada.
Ambos os modelos oferecem uma API compatível com a OpenAI, o que significa que conectá-los a ferramentas como Claude Code, Codex ou OpenClaw é simples. A escolha entre eles se resume a três fatores reais: quanto contexto você precisa por solicitação, quais são os custos de token no seu volume esperado e se suas tarefas tendem a favorecer as forças relativas de cada modelo.
Os Modelos por Trás dos Nomes
Comparação das Janelas de Contexto: Kimi K2.6 vs GLM 5.1
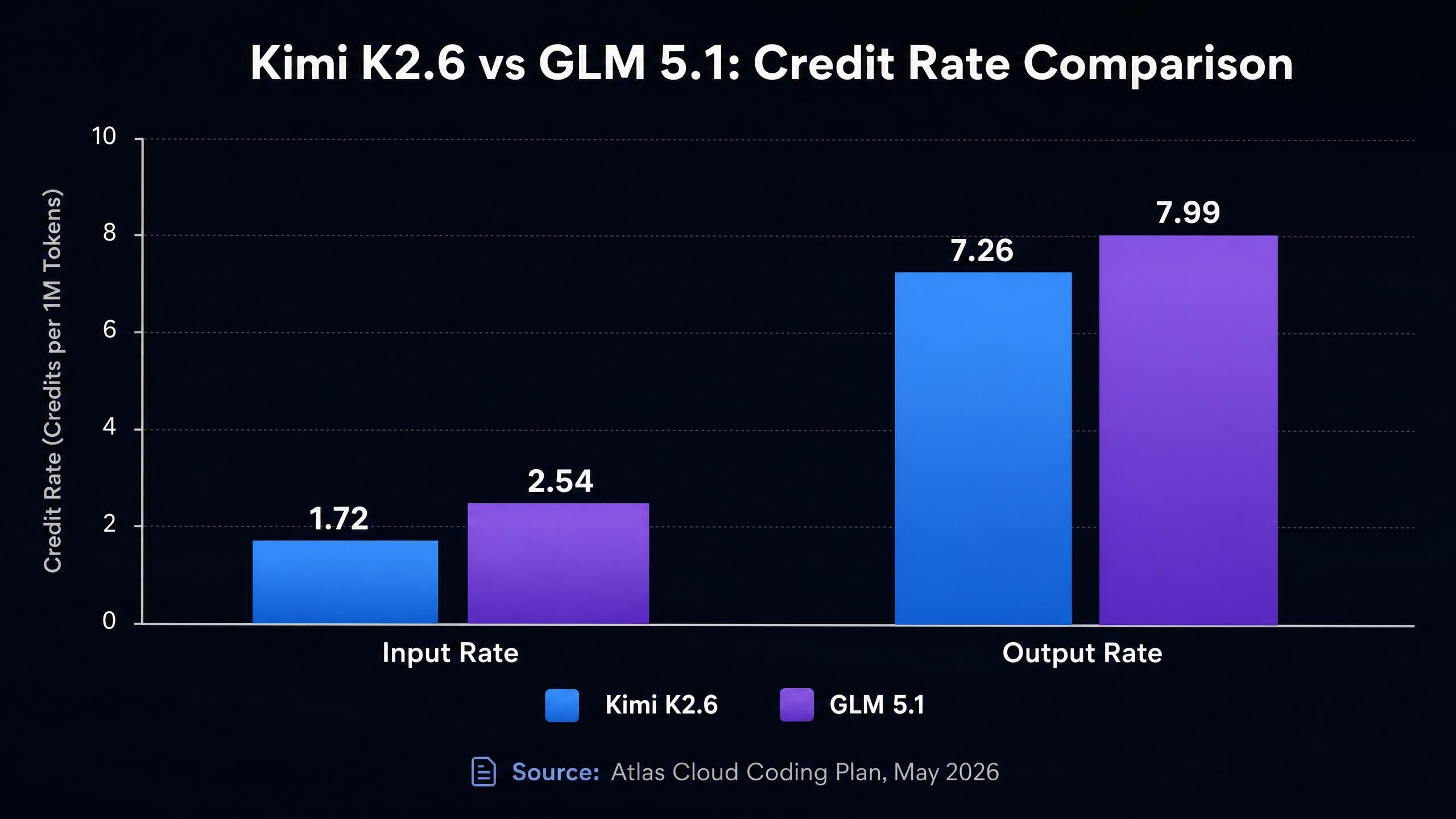
A janela de contexto é um dos diferenciais mais claros e objetivos aqui. O Kimi K2.6 suporta uma janela de contexto de 262K tokens. O GLM 5.1 suporta 200K. Isso representa uma diferença de 31% na capacidade máxima de entrada.
Para tarefas de codificação típicas, nenhum dos modelos atinge esses limites no dia a dia. Uma revisão de código padrão, uma sessão de depuração ou uma solicitação de geração de documentação caberão confortavelmente em ambas as janelas. A lacuna torna-se significativa em cenários específicos:
- Análise de grandes bases de código: Passar dezenas de milhares de linhas em uma única solicitação para refatoração ou revisão de arquitetura.
- Sessões de agentes longas: Conversas que acumulam contexto substancial ao longo de várias rodadas e chamadas de ferramentas.
- Pipelines com muitos documentos: Tarefas de pesquisa, resumo ou análise que exigem grandes blocos de texto em uma única chamada.
Se sua carga de trabalho se aproxima regularmente dos limites de contexto com outros modelos, a janela de 262K do Kimi K2.6 oferece mais margem antes que você precise implementar lógica de fragmentação (chunking) ou sumarização de contexto. Se suas solicitações típicas ficam abaixo de 50K tokens, ambos os modelos oferecem capacidade mais do que suficiente e a diferença na janela deixa de ser um fator relevante.

Pontos Fortes em Codificação e Raciocínio
Ambos os modelos são capazes em tarefas de codificação, embora suas prioridades de design criem comportamentos diferentes na prática.
O Kimi K2.6 foi construído para compreensão de longo contexto. Isso o torna bem adequado para refatoração de múltiplos arquivos, compreensão de como as mudanças em uma parte da base de código afetam outras, e cadeias de raciocínio estendidas onde o modelo precisa manter muito estado ao longo de vários passos. A Moonshot AI posicionou o K2.6 especificamente para esses casos de uso.
O GLM 5.1 carrega o foco da Zhipu AI em seguir instruções com precisão e gerar saídas estruturadas. Tarefas como gerar código a partir de uma especificação detalhada, produzir formatos estruturados a partir de linguagem natural ou gerenciar esquemas complexos de chamadas de ferramentas favorecem seus pontos fortes. A taxa de saída ligeiramente maior em seu preço (7,99 vs 7,26) também sugere a tendência do modelo para conclusões mais completas e detalhadas.
Para a maioria dos desenvolvedores que comparam os dois, a diferença de desempenho em tarefas típicas de codificação é menor do que se esperaria pelas diferentes marcas. Os diferenciais mais claros estão nas especificações e no custo, onde os números são concretos.
Kimi K2.6 vs GLM 5.1: Custos de Token e Taxas de Créditos
É aqui que a comparação se torna específica. Ambos os modelos estão disponíveis através do Atlas Cloud Coding Plan, e as taxas de crédito são as seguintes (Atlas Cloud Coding Plan, maio de 2026):
| Modelo | Contexto | Taxa Ent. | Taxa Saída | Cache Write | vs. Oficial |
|---|---|---|---|---|---|
| Kimi K2.6 | 262K | 1.72 | 7.26 | 0.290 | 45% mais barato |
| GLM 5.1 | 200K | 2.54 | 7.99 | 0.472 | 45% mais barato |
Alguns pontos se destacam.
A taxa de entrada do GLM 5.1 (2.54) é cerca de 48% maior que a do Kimi K2.6 (1.72). Em contextos de codificação onde você está passando conteúdos de arquivos, grandes históricos de código ou longas acumulações de conversa, os tokens de entrada costumam ser a maior parte do seu custo. Um pipeline rodando 1.000 solicitações por dia com 10K tokens de entrada por solicitação custaria cerca de 48% a mais apenas na entrada com o GLM 5.1 do que com o Kimi K2.6.
As taxas de saída são mais próximas, mas ainda favorecem o Kimi K2.6 (7.26 vs 7.99, uma diferença de cerca de 10%). As taxas de cache write também favorecem o Kimi K2.6 (0.290 vs 0.472), o que se soma em fluxos de trabalho que usam cache de prompt para prompts de sistema repetidos ou contexto estático.
Somando tudo: para uma solicitação com 5.000 tokens de entrada e 1.000 tokens de saída, os custos em créditos são:
- Kimi K2.6: (5.000 × 1.72) + (1.000 × 7.26) = 8.600 + 7.260 = 15.860 créditos
- GLM 5.1: (5.000 × 2.54) + (1.000 × 7.99) = 12.700 + 7.990 = 20.690 créditos
O Kimi K2.6 é cerca de 23% mais barato por solicitação nesta proporção de entrada/saída. Em alto volume, isso se traduz em uma diferença real no orçamento.
Ambos os modelos têm preços 45% abaixo de suas taxas oficiais de API através do gateway, o que é consistente nesta categoria de modelo.
Kimi K2.6 vs GLM 5.1 em Fluxos de Trabalho de Agentes
Ferramentas de agentes amplificam cada diferença de custo e capacidade entre os modelos.
Em um agente de codificação de várias etapas, cada chamada de ferramenta é uma solicitação de API separada. Cada solicitação carrega o contexto de entrada da conversa acumulada, gera uma saída que alimenta o próximo passo e aumenta sua conta total de processamento. Um fluxo de trabalho que executa 40 chamadas de API em uma sessão não custa apenas 40x o preço de uma solicitação única; ele também acumula contexto rapidamente, o que empurra as solicitações para contagens de tokens de entrada mais altas conforme a sessão avança.
Onde o Kimi K2.6 tende a se sair melhor em agentes: Sessões longas onde o contexto acumulado cresce bastante, tarefas que envolvem leitura e modificação de arquivos de código grandes, e pipelines onde manter os custos razoáveis ao longo de muitas chamadas é importante. A janela de contexto maior também significa menos reinicializações de sessão, o que interrompe menos a memória de trabalho do agente.
Onde o GLM 5.1 tende a se sair melhor: Pipelines onde cada etapa exige uma saída precisa e bem estruturada, e onde a precisão da instrução em cada chamada individual importa mais do que a profundidade do contexto ao longo da sessão. Se o seu agente precisa gerar código com base em esquemas de tipos rigorosos, gerenciar assinaturas de funções complexas ou produzir saídas formatadas consistentes a cada turno, os pontos fortes de seguimento de instruções do GLM 5.1 são mais diretamente relevantes.
Ambos os modelos funcionam perfeitamente com Claude Code, Codex, OpenClaw e Cursor através de configurações padrão compatíveis com OpenAI. A integração é idêntica entre os dois; apenas o ID do modelo muda.
Como Executar Ambos e Escolher o Que Realmente Funciona para Você
Kimi K2.6 vs GLM 5.1: Escolhendo o Modelo Certo Sem Suposições
A maneira mais confiável de decidir entre esses dois modelos não é lendo artigos comparativos (incluindo este). É rodar ambos em suas tarefas reais e comparar a qualidade da saída por si mesmo. A boa notícia é que isso é fácil de fazer quando ambos os modelos estão sob a mesma chave de API e URL base.
O Atlas Cloud Coding Plan coloca o Kimi K2.6 e o GLM 5.1 no mesmo endpoint sob uma única chave de API. Alternar entre eles é uma mudança de configuração de uma linha, o que significa que você pode rodar sua carga de trabalho real em ambos os modelos sucessivamente sem precisar reconstruir qualquer integração.
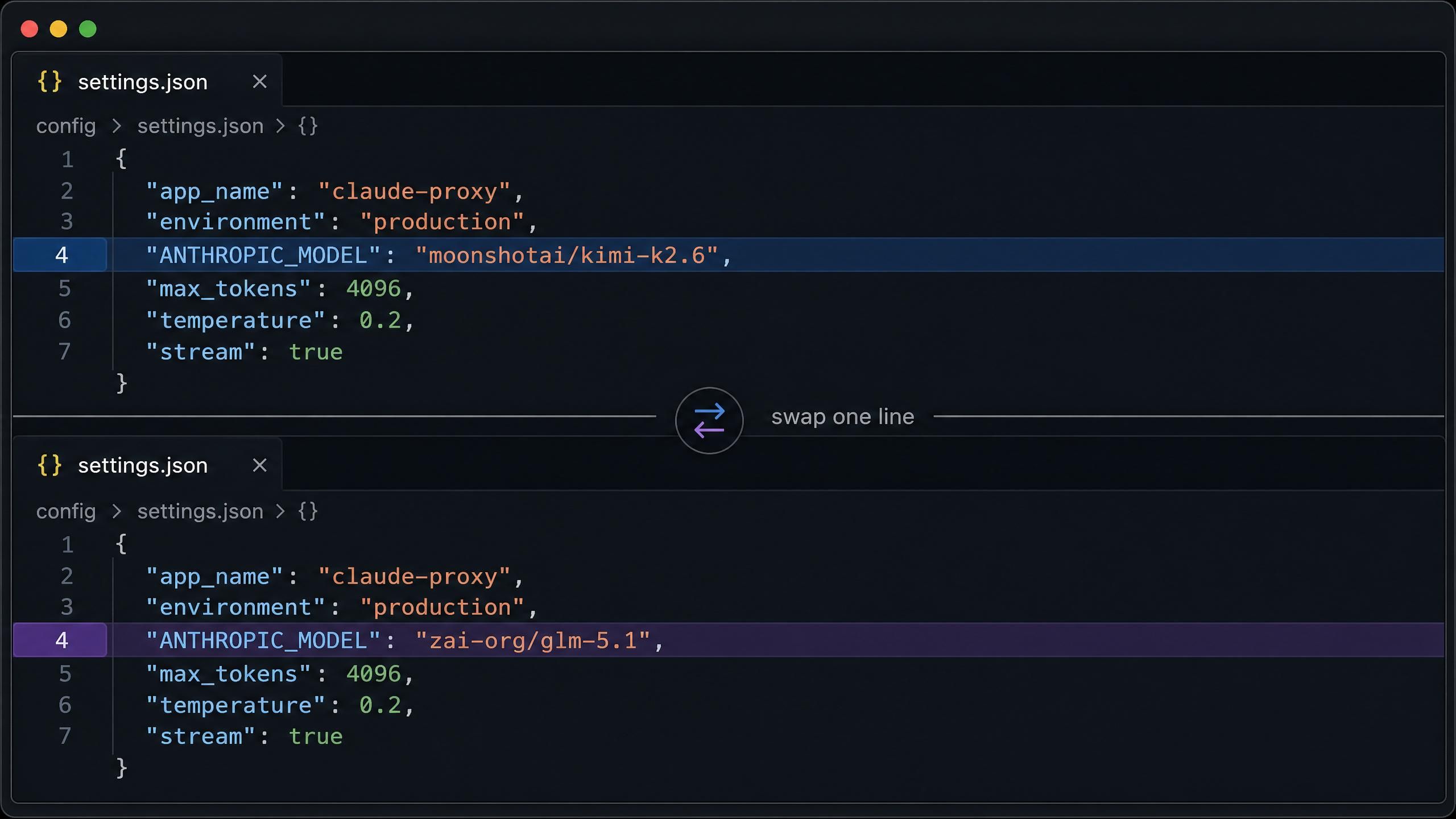
Para o Claude Code no macOS ou Linux, a configuração completa vai em ~/.claude/settings.json. Configure-o primeiro para o Kimi K2.6:
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "moonshotai/kimi-k2.6", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "moonshotai/kimi-k2.6", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "moonshotai/kimi-k2.6", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Para mudar para o GLM 5.1, altere moonshotai/kimi-k2.6 para zai-org/glm-5.1 em todos os três campos de modelo. Tudo o resto permanece igual. Observe que a URL base do Claude Code é https://api.atlascloud.ai sem o sufixo /v1.
Para o Codex, a configuração se divide em dois arquivos. ~/.codex/config.toml:
plaintext1model_provider = "atlas_coding_plan" 2model = "moonshotai/kimi-k2.6" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
~/.codex/auth.json:
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
Para o OpenClaw, execute openclaw onboard, escolha QuickStart e depois Custom Provider. Insira https://api.atlascloud.ai/v1 como a URL base, cole sua chave Atlas e selecione o ID do modelo que deseja testar.
O plano Atlas Cloud vem em duas formas: uma assinatura mensal com renovação diária de créditos (melhor para uso diário consistente) e um pacote pay-as-you-go com uma janela de 90 dias (melhor para cargas de trabalho variáveis ou experimentais). Como você provavelmente testará ambos os modelos, a opção pay-as-you-go oferece flexibilidade sem o compromisso de um volume mensal.
Perguntas Frequentes sobre Kimi K2.6 vs GLM 5.1
Qual modelo custa menos para rodar em escala? O Kimi K2.6 é mais barato por token tanto na entrada quanto na saída. A diferença é maior na entrada (a taxa de entrada do GLM 5.1 é cerca de 48% maior), o que é mais importante em fluxos de trabalho de codificação que enviam grandes quantidades de contexto. Em volumes altos de solicitação, isso se transforma em uma diferença orçamentária significativa.
Qual modelo lida melhor com tarefas em língua chinesa? Ambos os modelos possuem fortes capacidades na língua chinesa, o que era esperado devido às suas origens. O GLM 5.1 da Zhipu AI possui um histórico particularmente consolidado em tarefas de língua chinesa, construído ao longo de várias gerações da série GLM. O Kimi K2.6 também lida bem com o chinês, dado o foco da Moonshot AI no mercado chinês. Para tarefas predominantemente em chinês, ambos são sólidos, com o GLM 5.1 tendo uma leve vantagem pelo histórico.
Posso misturar ambos os modelos no mesmo pipeline? Sim. Através de um gateway unificado, você pode rotear diferentes etapas do mesmo pipeline para modelos diferentes alterando apenas o parâmetro do modelo por solicitação. Você pode usar o Kimi K2.6 para etapas de análise com uso intensivo de contexto (menor custo de entrada, janela maior) e o GLM 5.1 para etapas de geração de saída estruturada (melhor seguimento de instruções), tudo com uma única chave de API.
A diferença de contexto de 262K vs 200K merece atenção? Para a maioria das tarefas cotidianas de codificação, não. Ambas as janelas são grandes o suficiente para solicitações típicas. A diferença importa se suas sessões acumulam regularmente 150-200K tokens, se você está passando arquivos de código grandes para análise ou se está rodando sessões de agentes longas sem reinicializações. Se você raramente atinge 50K tokens por solicitação, não é um fator decisivo.
Esses modelos precisam de configuração especial para funcionar com o Claude Code?
Nenhuma configuração especial além da mostrada acima. O Claude Code lê suas configurações de modelo a partir de ~/.claude/settings.json e, contanto que você aponte para um gateway que forneça esses modelos em formato compatível com OpenAI, a conexão ocorre sem problemas. A única coisa a observar é o formato da URL base especificamente para o Claude Code: ele usa https://api.atlascloud.ai sem /v1, diferentemente da maioria das outras ferramentas.
Veredito Final: Kimi K2.6 vs GLM 5.1
A escolha entre esses dois modelos é mais sobre adequação à carga de trabalho do que um vencedor óbvio.
O Kimi K2.6 é o padrão mais econômico. É mais barato por token, lida com mais contexto por solicitação e é bem adequado para os tipos de tarefas de grande entrada e longo contexto que os agentes de codificação geram. Se você está otimizando para custo em escala ou trabalhando regularmente com grandes bases de código, ele é a escolha mais forte com base nos números.
O GLM 5.1 justifica seu preço ligeiramente mais alto em tarefas que exigem um seguimento de instruções preciso e saídas estruturadas consistentes. Se o seu pipeline é menos intensivo em contexto, mas exige alta precisão em cada etapa de geração individual, vale a pena testá-lo em seu tipo de tarefa específica.
A abordagem prática: comece com o Kimi K2.6 pela vantagem de custo e a maior janela de contexto, rode sua carga de trabalho real através dele e compare o GLM 5.1 nas mesmas tarefas se tiver dúvidas sobre a qualidade da saída estruturada. Com ambos os modelos atrás da mesma chave de API no Atlas Cloud Coding Plan com 45% de desconto sobre as taxas oficiais, o custo da comparação é baixo o suficiente para deixar que o desempenho real guie a decisão.
As especificações dos modelos e taxas de crédito baseiam-se na documentação do Atlas Cloud Coding Plan de maio de 2026. As capacidades dos modelos refletem informações disponíveis publicamente da Moonshot AI e Zhipu AI. As taxas estão sujeitas a alterações; verifique os valores atuais diretamente com cada provedor.






