As APIs de geração de vídeo por IA têm fama de temperamentais — e por um bom motivo. Em completions de texto, uma falha resulta imediatamente em um erro 400. Já a renderização de vídeo é diferente e muito mais imprevisível. Um job pode ficar parado para sempre na fila de GPU sem aviso, retornar apenas metade dos clipes solicitados ou, às vezes, concluir a renderização perfeitamente, mas entregar um vídeo fisicamente impossível ou distorcido.
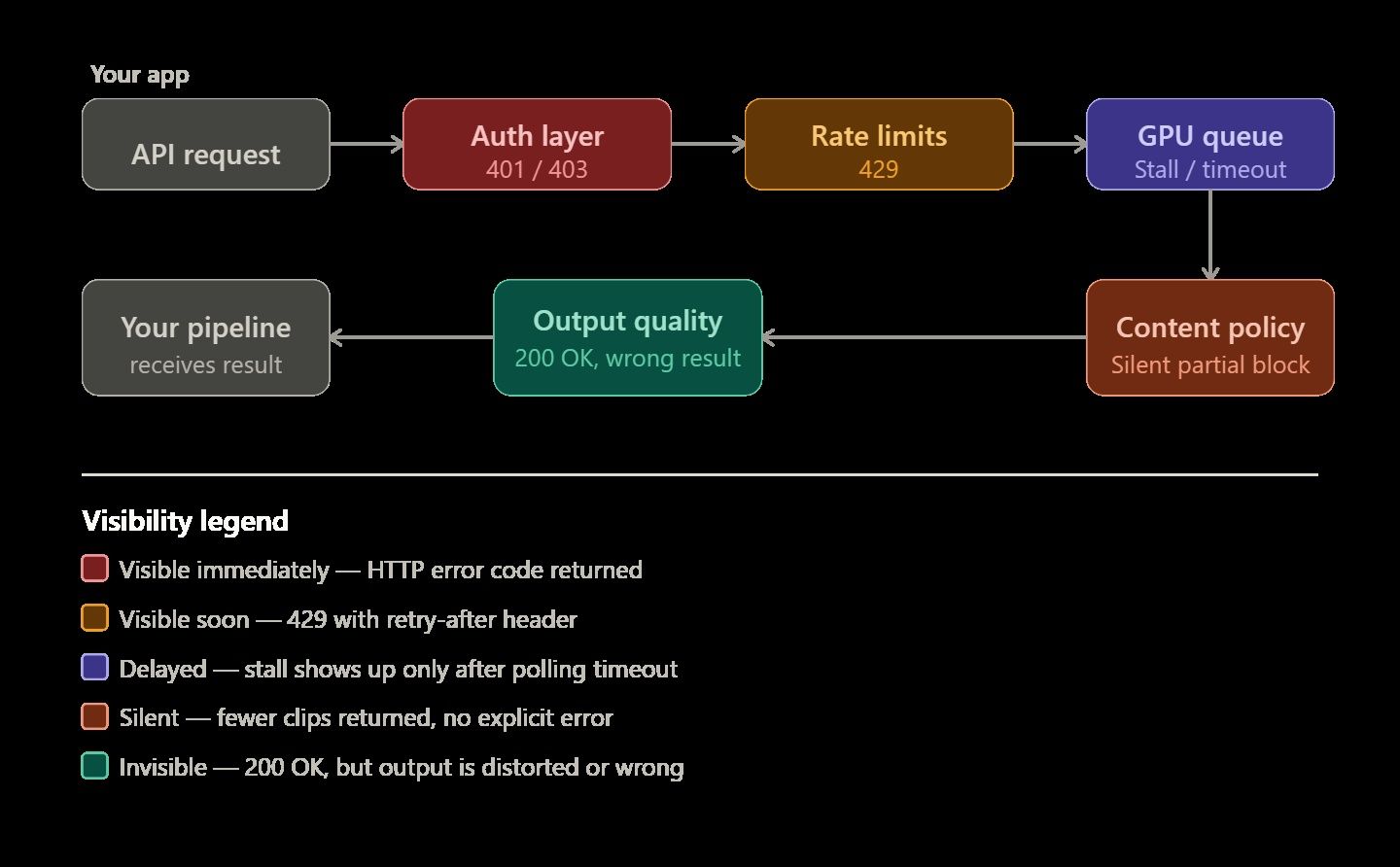
Você precisa entender por que esses erros específicos ocorrem para construir um sistema confiável. Esse conhecimento é a principal diferença entre uma demonstração simples e um pipeline de vídeo que realmente funciona para usuários reais.
Este guia percorre os modos de falha mais comuns, como ler respostas de API com precisão e estratégias concretas para construir um pipeline de renderização de vídeo que custa menos e quebra com menos frequência. Os exemplos de código utilizam a Atlas Cloud API, uma plataforma de inferência unificada que fornece acesso a mais de 300 modelos de vídeo e multimodais através de um único endpoint — tornando-a uma referência útil para padrões multimodais.
As Cinco Categorias de Erros de API de Vídeo por IA
Erros em pipelines de vídeo por IA geralmente se encaixam em cinco grupos específicos. Saber a categoria correta ajuda você a resolver problemas mais rapidamente, seja corrigindo seu código, reescrevendo seu prompt ou simplesmente aguardando.
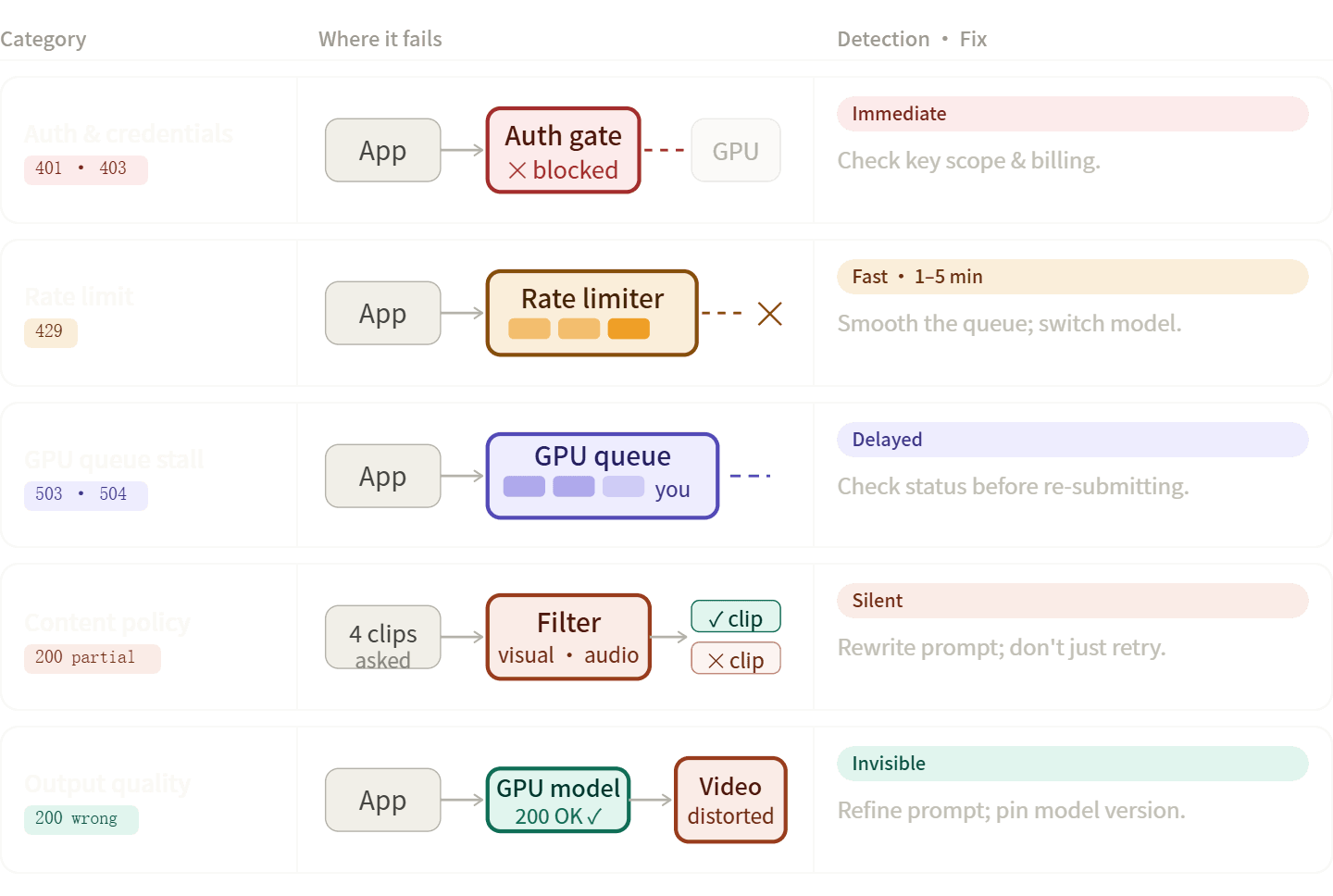
Erros de Autenticação e Credenciais (401, 403)
| Código | Causa Típica | Correção |
| 401 Unauthorized | Header Authorization: Bearer <key> ausente ou malformado | Verifique se a chave é carregada de variáveis de ambiente, não hardcoded |
| 403 Forbidden (cota) | Créditos da API esgotados | Adicione faturamento ou atualize o plano |
| 403 Forbidden (permissão) | Chave sem escopo para o modelo solicitado | Regenere a chave com as permissões corretas |
As pessoas costumam se confundir aqui. Um 403 por atingir uma cota e um 403 por permissão negada usam o mesmo código, mas exigem correções diferentes. Não olhe apenas para o número do status. Sempre leia a mensagem de erro completa no corpo da resposta para ver o que deu errado.
Em plataformas como Atlas Cloud, uma única chave de API cobre todos os modelos — o que significa que o desvio de autenticação, onde chaves para o Provedor A funcionam, mas as chaves para o Provedor B expiraram, simplesmente não acontece.
Erros de Limite de Taxa (429)
Os limites de taxa em APIs de vídeo são mais punitivos do que em APIs de texto, porque cada solicitação ocupa um slot de GPU por 30 a 90 segundos. Algumas solicitações simultâneas podem saturar um limite que parece generoso no papel.
Principais distinções para verificar primeiro:
- RPM: Modelos de produção na API Veo 3.1 da Google permitem 50 RPM; modelos de prévia limitam a 10 RPM com um máximo de 10 solicitações simultâneas por projeto.
- Limites de solicitações simultâneas: Mesmo dentro do seu orçamento de RPM, atingir o limite de simultaneidade resultará em um 429.
- TPM (tokens por minuto): Menos comum para vídeo, mas relevante em plataformas com faturamento unificado entre modalidades.
O que realmente ajuda:
| Abordagem | Quando funciona | Quando não funciona |
|---|---|---|
| Exponential back-off + retry | 429s causados por picos momentâneos | Quando a simultaneidade é o limite real |
| Suavização de rajadas / enfileiramento | Pipelines de alto volume em lote | UX interativa e sensível à latência |
| Agendamento fora do horário de pico | Workflows de pré-geração de conteúdo | Geração em tempo real |
| Roteamento de modelo para variante menos carregada | Plataformas unificadas com modelos equivalentes | Configurações de provedor único |
Rejeições por Política de Conteúdo e Filtros de Segurança
Esses são fáceis de diagnosticar erroneamente, pois a resposta da API nem sempre é um erro claro — pode ser apenas um número menor de clipes do que o solicitado. A documentação do Veo do Google observa explicitamente que, se menos vídeos do que o solicitado forem retornados, parte da saída pode ter sido bloqueada por filtros de segurança em vez de a solicitação inteira falhar na camada de transporte.
Duas superfícies de gatilho distintas:
- Prompts visuais: Assunto, contexto da cena ou violência implícita/conteúdo explícito.
- Prompts de áudio/diálogo: Conteúdo de fala, solicitações de música e paisagens sonoras densas acionam pilhas de filtros separadas.
Se o seu clipe falha apenas quando o áudio faz parte do prompt, depure o áudio separadamente da cena visual. Tentar novamente um prompt bloqueado por política raramente resolve — o prompt precisa ser alterado.
Erros de Transporte e Infraestrutura (500, 503, 504)
| Código | Tempo de resolução típico | O que fazer |
|---|---|---|
| 429 RESOURCE_EXHAUSTED | 1–5 minutos | Back-off e repetição |
| 503 Service Unavailable | 30–120 minutos | Aguarde; verifique o dashboard de status |
| 504 Gateway Timeout | Variável | Verifique se a renderização ainda está processando antes de reenviar |
| 500 Internal Server Error | Depende | Registre o ID da predição; não tente automaticamente sem checar o status |
A regra crítica para erros 500/504: verifique se sua renderização ainda está sendo processada antes de reenviar. Repetições cegas em um 504 podem resultar em renderizações duplicadas e custos dobrados.
Falhas de Qualidade de Saída
Esses não são erros HTTP — a API retorna 200, mas a saída está errada. Formas comuns:
- Artefatos visuais ou imprecisões geométricas: O vídeo por IA é probabilístico. O modelo interpreta entradas em vez de calculá-las fisicamente.
- Áudio ausente em modelos que o suportam: Geralmente um problema de prompt ou parâmetro, não uma falha de infraestrutura.
- Duração ou resolução errada: Acionado por combinações não suportadas — nem todos os modelos suportam todos os pares de duração/resolução.
- Drops silenciosos no pipeline: Alguns pipelines de codificação descartam silenciosamente vídeos em certos formatos, aparecendo apenas no QA.
Lendo Respostas Assíncronas: IDs de Predição e Polling de Status
A geração de vídeo por IA é assíncrona por design. O ciclo de solicitação-resposta tem duas fases:
- POST para o endpoint de geração → receba um
prediction_id - GET o endpoint de resultados com esse ID → faça polling até um estado terminal
O schema de resposta da Atlas Cloud ilustra como uma predição concluída se parece:
plaintext1{ 2 "id": "pred_abc123", 3 "status": "completed", 4 "model": "bytedance/seedance-2.0/text-to-video", 5 "outputs": ["https://storage.atlascloud.ai/outputs/result.mp4"], 6 "metrics": { "predict_time": 45.2 }, 7 "created_at": "2025-01-01T00:00:00Z", 8 "completed_at": "2025-01-01T00:00:45Z" 9}
Os três estados terminais:
| Status | Significado | Ação |
|---|---|---|
| completed | Renderização concluída; saídas disponíveis | Faça o download dentro da janela de expiração |
| failed | Renderização falhou; verifique o campo de erro | Registre a mensagem de erro; decida sobre a repetição |
| expired | Saídas não estão mais disponíveis | Reenvie se ainda for necessário |
O Erro de Polling Mais Comum
Desenvolvedores frequentemente verificam status === "failed", mas nunca leem o campo de erro que o acompanha. Esse campo é onde reside a informação acionável — sem ele, você sabe que uma renderização falhou, mas não se deve corrigir o prompt, verificar sua cota ou esperar uma oscilação de infraestrutura passar.
Padrão de Polling Pronto para Produção
plaintext1import time 2import requests 3 4def poll_prediction(prediction_id: str, api_key: str, max_wait: int = 600) -> dict: 5 url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 6 headers = {"Authorization": f"Bearer {api_key}"} 7 terminal_states = {"completed", "failed", "expired"} 8 wait = 5 9 10 for _ in range(max_wait // wait): 11 resp = requests.get(url, headers=headers).json() 12 status = resp.get("status") 13 14 if status in terminal_states: 15 if status == "failed": 16 print(f"Render failed: {resp.get('error')}") 17 return resp 18 19 time.sleep(wait) 20 wait = min(wait * 1.5, 60) # limite de back-off em 60s 21 22 raise TimeoutError(f"Prediction {prediction_id} did not complete within {max_wait}s")
Registre metrics.predict_time em cada renderização concluída. Picos neste valor são um indicador principal de degradação da infraestrutura — um sinal útil antes de começar a ver falhas definitivas.
Estruturando um Pipeline de Renderização Resiliente
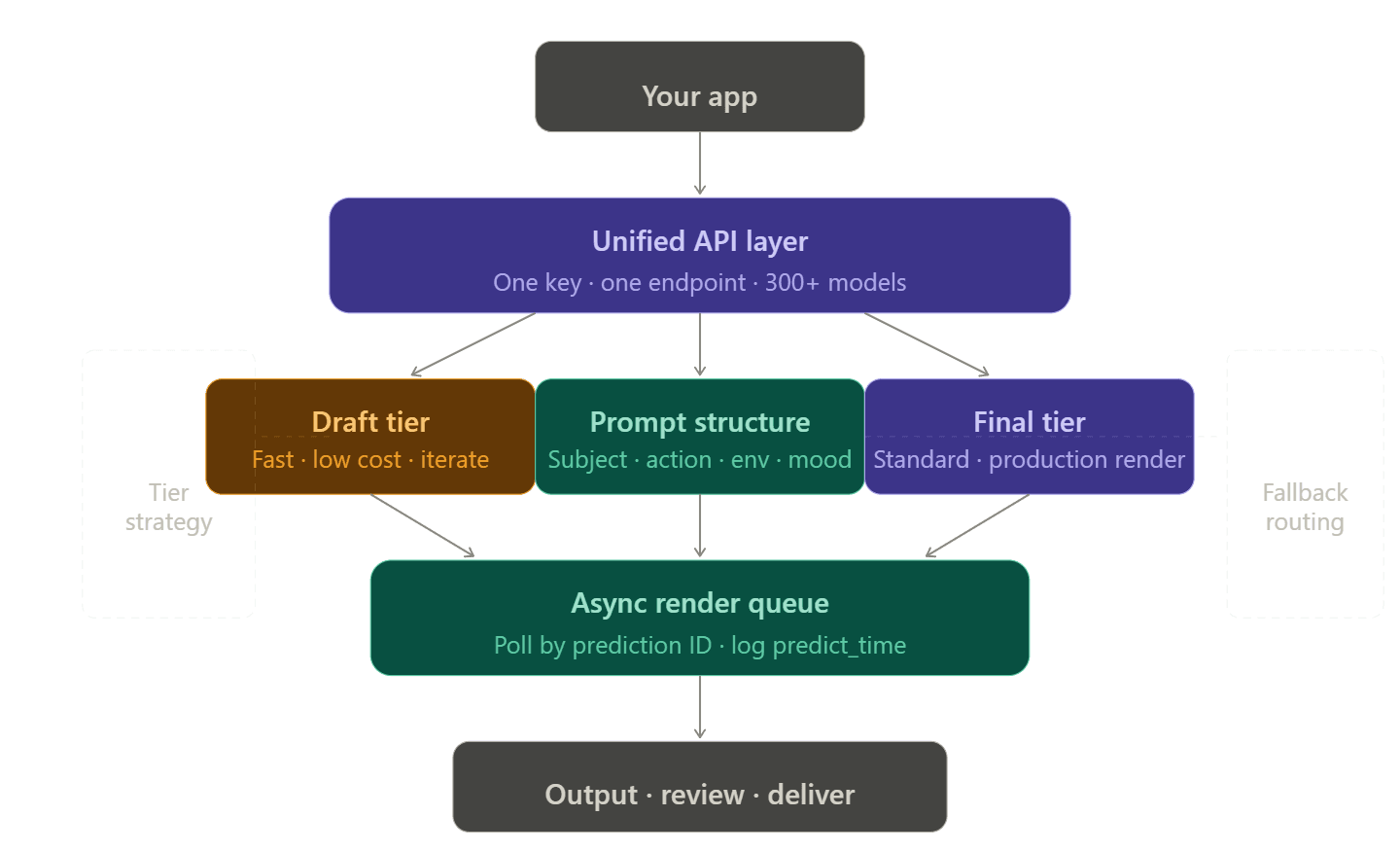
Arquitetura de API de Fornecedor Único vs. Unificada
Gerenciar várias contas, tokens e páginas de faturamento para cada provedor de vídeo é um pesadelo. Desenvolvedores costumam chamar isso de "imposto de integração". Se um modelo atinge um limite, você precisa de um backup. Esse backup, por sua vez, precisa de sua própria chave de API, configuração de faturamento e código personalizado para lidar com erros.
Plataformas de API unificada eliminam isso roteando vários provedores através de um único endpoint. Na Atlas Cloud, mudar de openai/sora-2/text-to-video para bytedance/seedance-2.0/text-to-video requer alterar apenas uma string — os headers, a autenticação e o faturamento permanecem idênticos.
Nivelamento de Rascunho para Final
Uma das melhorias de custo e confiabilidade mais eficazes disponíveis é simplesmente escolher o nível de modelo certo para o estágio de workflow certo:
| Estágio | Nível recomendado | Por que |
|---|---|---|
| Exploração de prompt / teste de conceito | Nível Rápido / econômico | Economia de 78%+ vs Standard; erros surgem de forma barata |
| Rascunhos de revisão interna | Nível Rápido | Bom o suficiente para revisão das partes interessadas |
| Renderizações finais de produção | Nível Standard / Pro | A diferença de qualidade justifica o custo |
| Conteúdo em lote (redes sociais, marketing) | Nível Rápido | O volume torna o delta de custo significativo |
Na Atlas Cloud, o nível Rápido do Seedance 2.0 custa $0.081/seg versus $0.10/seg para o Standard — uma diferença que aumenta rapidamente em escala. Uma equipe que gera 200 clipes de dez segundos por mês gastaria $162 no Rápido contra $200 no Standard para o mesmo conjunto de prompts.
Engenharia de Prompt como Prevenção de Erros
Prompts vagos são uma fonte subestimada de falhas no pipeline. Um prompt como "uma pessoa caminhando" força o modelo a fazer escolhas arbitrárias demais, produzindo resultados inconsistentes que exigem mais tentativas.
Uma estrutura de prompt confiável de 4 componentes:
plaintext1[Sujeito + detalhe] + [Ação + estilo de movimento] + [Ambiente + iluminação] + [Câmera + clima] 2 3Exemplo: 4"Uma mulher de casaco vermelho caminhando rapidamente por uma rua de Tóquio molhada pela chuva à noite, 5reflexos de neon no pavimento úmido, tomada média de acompanhamento, cinematográfico e tenso"
Ao usar modelos que suportam entrada multimodal — o Seedance 2.0 aceita até 12 arquivos de referência (imagens, clipes de vídeo e áudio) — fornecer referências visuais reduz a ambiguidade que leva a falhas de qualidade de saída.
Escolhendo o Modelo Certo
Nem toda ferramenta de vídeo por IA falha pelo mesmo motivo. Isso ocorre porque elas são construídas para objetivos diferentes. Usar o modelo errado para sua tarefa específica é um grande erro. Isso leva a resultados ruins que parecem bugs técnicos, mas geralmente o modelo simplesmente não foi feito para realizar aquele trabalho.
Referência de Capacidade do Modelo
| Modelo | Força | Cuidado com | Preço (Atlas Cloud) |
|---|---|---|---|
| wan 2.7 | Simulação física, interação realista de objetos | Apenas referência de imagem única; custo mais alto | $0.1/seg |
| Kling 3.0 | Saída de alta resolução; lip-sync nativo; nível gratuito (66 créditos diários) | Tempos de geração mais longos na resolução máx | $0.071-0.143/seg |
| Veo 3.1 | Qualidade cinematográfica; forte conformidade de segurança | Limites de taxa do modelo de prévia (10 RPM) | $0.05–0.20/seg |
| Seedance 2.0 | Controle de entrada multirreferência; áudio nativo | Requer construção de prompt mais cuidadosa | $0.081–0.10/seg |
| Wan 2.6 | Custo mais baixo; conteúdo de alto volume | Sem áudio nativo; máx 1080p | $0.018-0.07/seg |
Preços obtidos na documentação da Atlas Cloud, abril de 2026. Para preços específicos, consulte o site oficial.
Quando Mudar de Modelo vs. Corrigir a Solicitação
Mude o modelo se:
- Clipes falham consistentemente apenas quando áudio ou diálogo está no prompt (o modelo pode não ter capacidade de áudio).
- A qualidade da física ou da interação de objetos é a falha, não o prompt.
- Você está em um modelo de prévia atingindo limites de taxa que um modelo de produção não atingiria.
Corrija o prompt se:
- A saída está estilisticamente errada, mas estruturalmente correta.
- Filtros de segurança estão sendo acionados por linguagem específica.
- Parâmetros de duração ou resolução estão sendo rejeitados.
Fixe uma string de versão específica (ex: kling-v3.0-std e não kling-latest). Atualizações silenciosas de modelo podem introduzir regressões de qualidade quase impossíveis de depurar sem fixação de versão.
Seu Toolkit de Depuração
O que Registrar em Cada Estágio
O log é a maneira mais rápida de reduzir o tempo de depuração pela metade. Um log eficaz mínimo captura:
Na solicitação:
- ID e versão do modelo
- Hash do prompt, não o prompt completo — mantém os logs compactos
- Parâmetros de duração, resolução e modo
- Timestamp
Na resposta:
- ID da predição
- Status inicial
- Qualquer mensagem de erro imediata
Na conclusão do polling:
- Status final
predict_timedas métricas- Conteúdo do campo de erro (se falhou)
- URL de saída (se concluído)
Lendo Erros de Infraestrutura vs. Erros de Aplicação
Quando uma geração falha, uma sequência de diagnóstico rápida economiza tempo:
- Verifique o dashboard de saúde da API primeiro — se a plataforma estiver degradada, você está depurando a coisa errada.
- Leia os headers de resposta
x-deny-reason— negações de proxy de saída aparecem aqui e parecem erros de modelo sem esse header. - Verifique erros de CORS se estiver chamando do frontend — eles produzem o mesmo sintoma de falhas de autenticação no DevTools do navegador.
- Verifique restrições de arquivo antes de assumir um erro de modelo — a maioria das plataformas impõe um tamanho máximo de arquivo de entrada (frequentemente 16 MB) e um conjunto limitado de formatos aceitos.
O painel de monitoramento da Atlas Cloud mostra o status de auto-scaling e dados de uso por solicitação, o que ajuda a distinguir um dia de infraestrutura lenta de um problema de prompt ou código.
Otimização de Custos
As Três Alavancas
O custo de renderização é um produto de três variáveis. Otimizar as três simultaneamente — em vez de apenas escolher um modelo mais barato — produz as maiores economias:
| Alavanca | Escolha de baixo custo | Escolha de alto custo | Multiplicador típico |
|---|---|---|---|
| Nível do modelo | Rápido | Standard/Pro | 3–5× |
| Duração | 4–5 segundos | 12–15 segundos | 3× |
| Resolução | 720p | 4K | 2–4× |
Uma única renderização Standard 4K de 8 segundos pode custar 6–8× mais que uma equivalente Rápido 720p na mesma duração. Se seu canal de distribuição é redes sociais ou web, 720p ou 1080p geralmente é indistinguível para os usuários finais.
Faturamento Baseado em Uso vs. Assinatura
Planos de IA para consumidores, como o Google AI Pro por $19,99/mês ou AI Ultra por $249,99/mês, fornecem geração de vídeo limitada através da interface Google AI, mas não incluem acesso à API. Este é um erro comum de planejamento orçamentário para equipes migrando de ferramentas de consumo para pipelines de produção.
A Atlas Cloud usa faturamento baseado em uso para alinhar seus custos com o quanto você realmente constrói. Isso funciona melhor se as necessidades do seu projeto mudarem de semana para semana. Você deve rastrear o custo por segundo de vídeo acabado. Esta é a melhor maneira de comparar diferentes modelos e níveis de preço de forma justa.
Reutilização de Ativos de Referência
Se você está gerando muitos clipes apresentando os mesmos personagens, cenas ou referências de estilo, pré-registre esses ativos:
- Faça upload de imagens ou vídeos de referência uma vez; armazene o ID do ativo retornado.
- Passe
asset://<ark_asset_id>em solicitações subsequentes em vez de fazer o upload novamente. - Uploads de arquivos de referência não são tarifados na maioria das plataformas — apenas a duração da saída gerada é cobrada.
Checklist de Prontidão de Produção
Antes de colocar um pipeline de geração de vídeo em produção, verifique cada um dos itens abaixo:
Autenticação
- Chave da API carregada de variáveis de ambiente, não hardcoded
- Chave com escopos corretos para todos os modelos em uso
- Política de rotação em vigor
Limites de taxa e simultaneidade
- Limites de RPM e solicitações simultâneas confirmados para cada nível de modelo
- Suavização de rajadas ou fila em vigor para workflows em lote
- Modelo de fallback configurado para cenários de limite de taxa
Tratamento de erros
- Estados terminais (completed, failed, expired) todos tratados
- Campo
errorcapturado e registrado em cada status de falha - Timeout de subprocesso/solicitação definido para ≥ 10 minutos para renderizações longas
- Nenhuma repetição automática cega em 500/504 sem verificação de status primeiro
Conteúdo e prompts
- Prompts pré-revisados conforme as diretrizes de conteúdo da plataforma
- Gatilhos de áudio e visual isolados em testes
- Estrutura de prompt de 4 componentes adotada como padrão de equipe
Configuração do modelo
- String de versão específica fixada (não
latest) - Nível do modelo correspondente ao estágio do workflow (Rápido para rascunhos, Standard para finais)
- Todos os parâmetros necessários confirmados para o modelo escolhido (duração, resolução, áudio)
Controles de custo
- Dashboard de faturamento baseado em uso configurado com alertas
- Nível Rápido como padrão para todas as renderizações não finais
- IDs de ativos de referência usados para ativos recorrentes
Observabilidade
- ID da predição, status e
predict_timeregistrados em cada renderização - Dashboard de saúde da API salvo nos favoritos e verificado antes de depurações profundas
- Alertas sobre picos de
predict_timeconfigurados
Um pipeline de vídeo que lida com erros não é muito mais difícil de construir do que um que quebra. Você só precisa ser inteligente sobre como lida com falhas em cada etapa. Certifique-se de que seu logging seja sólido e siga versões de modelos específicas. Antes de se preocupar com qualquer outra coisa, configure um pipeline que vá de rascunhos rápidos a renderizações finais. O restante vem naturalmente.
FAQ
O que causa os erros "429 Resource Exhausted" no plano premium?
O erro 429 significa apenas que você atingiu seus limites de taxa. Para manter o funcionamento suave, os provedores limitarão suas solicitações e tokens.
- A correção: Adicione exponential backoff ao seu código. Isso ajuda o sistema a aguardar e tentar novamente por conta própria. Verifique também seu "Nível de Uso" no painel. Você precisa gastar mais para desbloquear velocidades mais rápidas.
Como evitar falsos positivos de "Moderação de Conteúdo"?
Filtros de segurança frequentemente interpretam mal prompts técnicos como violações de política.
- A correção: Corrija seu prompt trocando palavras vagas por técnicas. Não diga "energia caótica" quando quer dizer "movimento de câmera em alta velocidade". Você também pode usar um LLM para limpar seus prompts, transformando-os em descrições claras que a máquina entende e evita erros.
Como a latência do meu pipeline de renderização pode ser reduzida?
A latência geralmente vem de um polling ruim ou modelos grandes demais. Use Webhooks em vez de polling manual para receber dados de conclusão. Se estiver hospedando por conta própria, aplique a Quantização FP8 para acelerar a inferência. Para usuários de API, mude para Processamento Assíncrono para lidar com múltiplas gerações em paralelo, em vez de sequencialmente.






