
Os avatares de IA atuais conseguem manter uma conversa em tempo real e até permitem que você os interrompa no meio de uma frase — e você pode hospedar um deles por conta própria com um projeto de código aberto, mantendo todos os seus dados locais. Este post detalha como um humano digital em tempo real, pronto para produção, é realmente construído usando o OpenTalking e onde ele economiza dinheiro em comparação com serviços cobrados por minuto, como o HeyGen.
Este é o momento que chamou minha atenção: um avatar na minha tela estava falando, eu o interrompi no meio da frase e ele parou para ouvir — e então continuou de onde eu havia parado. Não era um clipe pré-renderizado. Era uma interação real. Legendas surgindo em sincronia, com uma latência baixa o suficiente para não parecer IA.
E o primeiro passo para construí-lo não me custou nada e nem exigiu uma GPU.
Por que começar com isso? Porque, quando a maioria das pessoas ouve "humano digital", elas ainda imaginam o boneco de PPT rígido, lendo um roteiro, de dois anos atrás — expressão congelada, reprodução unilateral, surdo a qualquer coisa que você diga. Então, a pergunta real não é "se um humano digital pode gerar lucro". É:
Até onde os avatares de IA chegaram em 2026?
O suficiente para deixarem de ser "um vídeo que se move" para serem "algo que responde". Após a demonstração em tempo real do GPT-4o, o nível subiu para tempo real, interrompível e capaz de fazer perguntas. Este ano, a comunidade open-source lançou uma onda deles — SoulX-LiveAct, Mnn3dAvatar da Alibaba, duix.ai, LiveTalking. O que estou analisando aqui conecta todo o pipeline de forma excepcionalmente limpa: OpenTalking.
Sem enrolação — vamos dividir em três pontos: o que ele faz, quanto vale e como um não desenvolvedor pode construí-lo.
1. O que ele faz: um avatar que realmente responde
O OpenTalking é um framework de orquestração de conversação para humanos digitais em tempo real de código aberto. Em termos simples: ele encadeia todo o ciclo — o usuário fala → reconhecimento de voz (STT) → uma LLM pensa em uma resposta → conversão de texto em fala (TTS) → o avatar fala e faz o streaming para o seu navegador via WebRTC — em um único pipeline em tempo real.
O que ele realmente pode fazer:
- Conversa em tempo real — ele responde ao vivo, não é um vídeo pré-gravado
- Interrupção — fale por cima dele e ele para para ouvir (esta é a parte que parece humana)
- Eventos de legenda — legendas renderizadas conforme ele fala
- Clonagem — geração orientada por áudio/texto, para que você possa construir seu próprio gêmeo digital
Aplique isso a um negócio e o cenário se torna concreto rapidamente: um apresentador de livestream que vende 24/7 sem precisar fazer pausas, ou um agente de suporte que está online às 3 da manhã e pode ser interrompido com uma pergunta de acompanhamento.
2. Quanto vale: os números apresentados
O que realmente importa para quem não é desenvolvedor: isso economiza ou gera dinheiro? Aqui está o que os dados públicos dizem:
- Uma livestream de marca tradicional com uma equipe humana custa de ¥150 mil a ¥250 mil por mês; estima-se que uma livestream com avatar de IA custe de alguns milhares a ¥20 mil/mês — uma redução de custos de aproximadamente 90% (segundo o White Paper de Livestream de E-commerce de Humanos Digitais de 2026 da iResearch).
- Um agente de suporte humano digital pode filtrar mais de 60% das consultas de alta frequência e reduzir os custos operacionais em 30–60%.
Agora, o outro caminho — um SaaS pronto para uso como o HeyGen. Ele é genuinamente "turnkey" e o resultado é excelente, mas cobra por minuto: a API custa cerca de USD 0.376/minuto para geração padrão, USD 4/minuto para o Avatar IV, USD 3/minuto para o Avatar V; e o plano Creator (USD 29/mês) inclui 200 créditos — o suficiente para apenas cerca de 10 minutos de vídeo de avatar premium.
Pense nessa diferença: SaaS significa que a cada minuto usado, você paga por esse minuto. Uma configuração de código aberto auto-hospedada é construída uma vez, envolvendo basicamente gastos com eletricidade e depreciação de hardware (GPU). Para uma empresa que opera por longos períodos e em grande volume (pense em transmissões ao vivo diárias), essas duas curvas de custo não acabam um pouco distantes — elas acabam em mundos completamente diferentes.
3. Como um não desenvolvedor constrói: começando sem GPU
Este é o coração desta análise. A escolha de design mais inteligente do OpenTalking é não forçar a compra de uma GPU logo no primeiro dia. Ele oferece três níveis de implementação que você pode escalar um de cada vez:
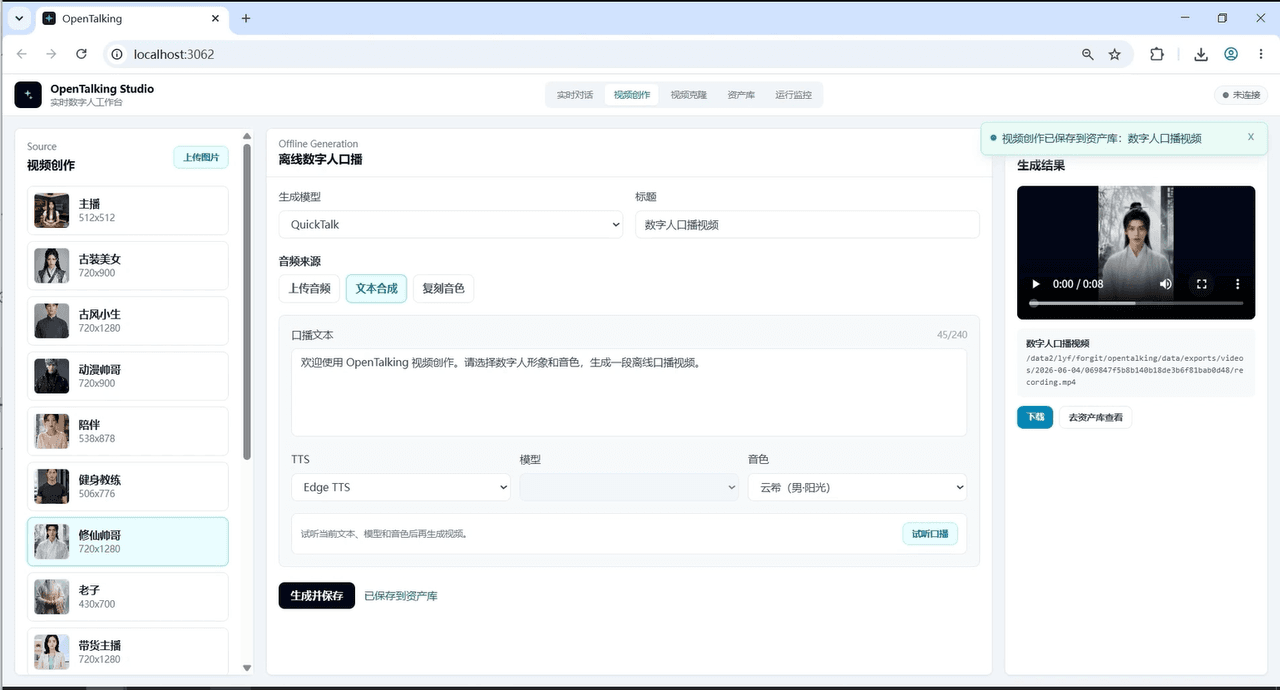
Passo 0 — Modo Mock (sem GPU, prove a lógica primeiro)
Inicie todo o ciclo do produto com o backend mock — interação front-end, estado da sessão, todo o fluxo de conversação — em um computador comum. O objetivo: confirmar se este formato de produto é o que você realmente deseja antes de gastar um centavo em uma GPU. A maioria das pessoas trava no "preciso comprar uma placa só para começar". Aqui, você pode testar tudo antes.
Passo 1 — Dê a ele um cérebro e uma boca (a LLM)
Para o avatar responder, você conecta uma LLM. O OpenTalking é compatível com a API da OpenAI, então você não precisa mexer em código — basta inserir um endpoint e uma chave. Para este passo, peguei uma chave no AtlasCloud: uma única chave chama o DeepSeek, Seedance, Nano Banana e muito mais, então pulei a etapa de registrar uma pilha de contas separadas. A voz/TTS é escolhida diretamente na interface web.
Passo 2 — Adicione uma GPU de consumo, troque por um modelo de renderização real
Assim que a lógica rodar e o modelo estiver conectado, remova o modo mock e anexe um backend de renderização real. Localmente, uma placa de consumo como uma RTX 3060 (8GB VRAM) é o suficiente para começar; ela suporta QuickTalk, Wav2Lip, MuseTalk, FlashTalk e outros — escolha com base no equilíbrio entre qualidade e velocidade.
Passo 3 — Escale apenas quando o negócio escalar
À medida que você cresce, ele escala para multi-GPU e até NPUs como o Huawei Ascend 910B2. Isso significa que este sistema cresce com você, desde "brincar no meu laptop" até "implantação privada corporativa" — sem precisar trocar de framework no meio do caminho.
4. Então por que não apenas usar um SaaS? Onde o código aberto / auto-hospedagem vence
Vamos pegar os nomes que todos conhecem e fazer uma comparação honesta (cada um tem seus pontos fortes — sem hype, sem preconceito):
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Dimensão | OpenTalking (open-source, auto-hospedado) | HeyGen / D-ID (SaaS) | Workflows de avatar ComfyUI |
| Facilidade de configuração | Média (exige deploy, mas o mock suaviza) | Mais fácil (pronto para uso) | Alta (conectar nós, ajustar grafos) |
| Cobrança | Construa uma vez; custos de hardware/energia | Recorrente por minuto / por crédito | Gratuito para rodar por conta própria |
| Dados | Locais, nunca saem do seu domínio | Upload para os servidores deles | Locais |
| Tempo real + interrompível | Nativo | Focado em vídeo; chat ao vivo limitado | Principalmente renderização offline |
| Personalização | Alta (backends plugáveis, orquestração editável) | Baixa (produto padronizado) | Alta (ecossistema de nós flexível) |
Sejamos justos: o SaaS ao estilo HeyGen vence no quesito "sem complicações" — se você não quer lidar com deploy, quer apenas o resultado e seu volume é baixo, é a escolha certa. O ecossistema de nós e o controle do ComfyUI também são fortes. A vantagem do OpenTalking não é "superar todos na qualidade de imagem" — são duas coisas: os dados nunca saem da sua máquina (um requisito rígido para governo, finanças, saúde ou qualquer empresa que não entregue conversas de clientes a terceiros) e não há um medidor por minuto rodando (o que compensa em volume, a longo prazo).
Qual é a escolha certa depende de se o seu negócio é sobre "clipes ocasionais" ou "operar intensamente todos os dias", e se você se importa em entregar seus dados.
Conclusão
Voltando à pergunta inicial — até onde os avatares de IA chegaram? O suficiente para que um deles consiga conversar com você em tempo real, permitir que você o interrompa e rodar na sua própria máquina. A barreira é menor do que você imagina: prove a viabilidade no modo mock sem custo, confirme se é isso que você quer e só então invista. Para um não desenvolvedor entrando neste espaço, essa pode ser a maneira mais segura de começar.
❓ FAQ
P: Qual GPU eu preciso para construir isso?
R: Para rodar um modelo de renderização real localmente, uma placa de consumo em torno de uma RTX 3060 (8GB VRAM) é o suficiente para começar; escale para multi-GPU ou uma NPU Ascend mais tarde. Mas note — o Passo 0 (modo mock) não precisa de GPU, então um computador comum pode provar a lógica primeiro.
P: Eu não tenho uma GPU. Ainda posso tentar?
R: Sim. O modo mock valida todo o fluxo de conversação sem GPU; se você quiser um modelo real, mas não tiver uma placa, direcione para uma inferência em nuvem e descarregue a renderização para ela.
P: Quanto ele realmente economiza em relação ao HeyGen?
R: Estruturalmente, ele remove a cobrança por minuto. A API do HeyGen custa de USD 1 a 4 por minuto e seus créditos de plano cobrem apenas cerca de 10 minutos/mês; a auto-hospedagem é uma construção única mais custos de hardware e eletricidade. Quanto mais você opera, mais a auto-hospedagem vence — para alguns clipes ocasionais, o SaaS é, na verdade, menos trabalhoso.
P: Posso usar isso comercialmente?
R: Tecnicamente, ele cobre o que o uso comercial precisa — conversa em tempo real, suporte, gêmeos digitais para livestream — com implantação privada e dados que permanecem no seu domínio. Mas, antes de ir ao ar, verifique o licenciamento/conformidade dos modelos de renderização, vozes e semelhanças que você usa. Avatares envolvem o rosto e a voz de alguém — obtenha as permissões primeiro.
P: Sou um iniciante total. Por onde começo?
R: ① Rode o projeto no modo mock e experimente o fluxo de conversa no seu navegador; ② conecte uma chave de LLM compatível com a OpenAI (para simplificar, obtenha uma no AtlasCloud — múltiplos modelos, uma chave); ③ escolha uma voz; ④ adicione uma GPU e troque por um modelo de renderização real por último. Prove primeiro, pague depois.






