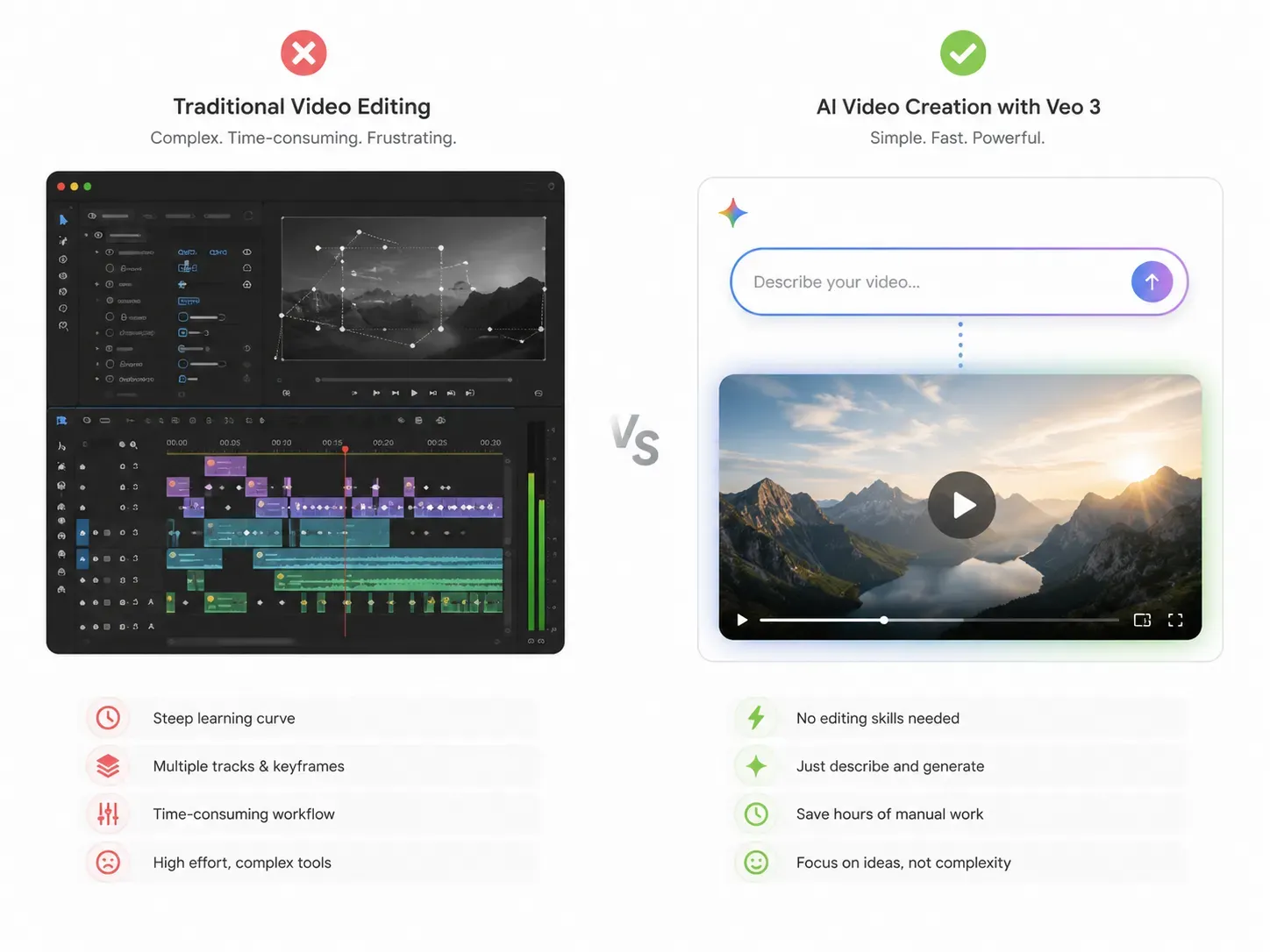
O Google Gemini Omni é um modelo de IA tudo-em-um do Google DeepMind, apresentado no Google I/O em 19 de maio de 2026. O seu maior marco é a multimodalidade nativa. Isso significa que ele processa e cria texto, imagens, som e vídeo dentro de um único sistema, em vez de conectar diferentes ferramentas. Foi concebido para criadores, programadores e empresas que pretendem criar e editar vídeos através de uma conversação simples, sem alternar entre aplicações.
Uma visão geral das funcionalidades do Gemini Omni começa com uma ideia: criar qualquer coisa a partir de qualquer input. Ao contrário das ferramentas de IA de texto para vídeo independentes, o Omni combina o raciocínio do Gemini com uma renderização de multimédia avançada num único passo.
Resumo das Capacidades Principais
| Funcionalidade | Detalhe |
|---|---|
| Inputs aceites | Texto, imagem, áudio, vídeo |
| Output principal | Vídeo (imagens e áudio disponíveis em breve) |
| Estilo de edição | Conversacional, prompts de várias etapas |
| Primeiro modelo | Gemini Omni Flash |
| Disponibilidade | Subscritores Google AI Plus, Pro & Ultra |
Onde Aceder
- Aplicação Gemini — Subscritores AI Plus/Pro/Ultra globalmente
- Google Flow — fluxos de trabalho completos para curtas-metragens
- YouTube Shorts / YouTube Create — criação de vídeos curtos
- API para Programadores — disponível dentro de semanas
O que é o Google Gemini Omni e como funciona?
O Google Gemini Omni é um enorme salto em frente. É o principal modelo de IA criativa tudo-em-um do Google DeepMind. Revelado no Google I/O 2026, o sistema aceita texto, imagens, som e vídeo simultaneamente para criar conteúdo de vídeo de alta qualidade. Substitui oficialmente o Veo dentro do ecossistema Gemini.
O Motor Principal: A Multimodalidade Nativa Explicada
A maioria das ferramentas de vídeo com IA anteriores seguiam um pipeline sequencial: converter o input em descrições de texto e, depois, passar essas descrições para um renderizador de vídeo separado. O Gemini Omni funciona de forma diferente. É construído sobre um modelo multimodal nativo — um sistema que processa todos os tipos de multimédia simultaneamente dentro de um único motor, em vez de os encaminhar através de passos isolados.
Isto é importante porque, ao eliminar as camadas de conversão, o modelo retém um contexto mais rico. Quando fornece uma fotografia de referência juntamente com um prompt de texto, o Omni raciocina sobre ambos ao mesmo tempo, preservando detalhes visuais que um passo de conversão de texto normalmente eliminaria.
O Input Multimodal do Gemini Omni na Prática
O input multimodal do Gemini Omni suporta estas combinações num único prompt:
| Tipo de Input | Exemplo de Utilização |
|---|---|
| Apenas texto | Descrever uma cena do zero |
| Imagem + Texto | Animar uma fotografia estática com uma instrução escrita |
| Vídeo + Texto | Editar um clipe existente de forma conversacional |
| Áudio + Texto | Orientar o tom juntamente com um prompt visual |
| Misto (os quatro) | Combinar clipes de referência, imagens de estilo e narração |
Processamento em Tempo Real e Controlo Conversacional
Como o raciocínio ocorre dentro de um único modelo, o processamento em tempo real de instruções de edição torna-se prático. O Omni refina os outputs através de uma conversação de várias etapas — altere um fundo, ajuste a iluminação ou estabilize uma filmagem descrevendo simplesmente a mudança. Não é necessário repetir o prompt do zero.
Nicole Brichtova, do Google DeepMind, descreveu-o como "mais do que uma atualização do Veo" — o raciocínio do Gemini fundido com a renderização de multimédia num sistema coerente.
IA de Edição de Vídeo Conversacional: Como utilizar o Gemini Omni para modificação avançada de ativos
Entender a arquitetura é uma coisa, pô-la em prática é outra. É aqui que a capacidade de IA de edição de vídeo conversacional do Gemini Omni se destaca das ferramentas convencionais.
Os editores de vídeo tradicionais exigem linhas do tempo, camadas e keyframing manual. O Gemini Omni substitui totalmente esse fluxo de trabalho. Carregue o seu vídeo, escreva ou diga o que precisa de mudar e o modelo volta a renderizar o clipe. Sem plugins. Sem software externo.
O Gemini Omni pode lidar com a substituição complexa de elementos de vídeo por IA?
Sim — e é uma das suas funcionalidades mais práticas. De acordo com a documentação oficial da Google, as tarefas de modificação de ativos de vídeo suportadas incluem:
- Trocas de fundo — substituir o ambiente atrás de um sujeito mantendo a personagem
- Mudanças de guarda-roupa e estilo — modificar o vestuário ou transferir um estilo visual através de um clipe
- Substituição de objetos — trocar um item específico numa cena a meio da filmagem
- Ajustes de iluminação — alterar o ambiente ou a intensidade da iluminação da cena através de uma única instrução
- Estabilização de vídeo — suavizar filmagens trémulas através de um prompt em linguagem simples
- Trocas de personagens — substituir um sujeito por outro usando uma imagem de referência
Edição de Vídeo Interativa através de Conversação de Várias Etapas
O que torna esta edição de vídeo interativa, e não uma geração única, é o ciclo de várias etapas. Cada instrução de edição baseia-se na anterior, pelo que o modelo mantém a coerência da cena — o mesmo fundo, lógica de iluminação e identidade da personagem — ao longo de sucessivas rondas de refinamento.
Por exemplo, um criador pode instruir primeiro: "troca o fundo por uma rua da cidade", depois seguir com "torna a iluminação mais quente" e, finalmente, "estabiliza a filmagem" — tudo isto sem reiniciar a geração.
Substituição de Elementos de Vídeo por IA: O que esperar agora
A substituição de elementos de vídeo por IA no modelo atual Gemini Omni Flash foca-se em clipes de 10 segundos. Estão planeadas para lançamentos futuros modificações de ativos de vídeo mais complexas em formatos mais longos — e tipos de output adicionais, como imagens e áudio independentes.
Domine o Ciclo de Várias Etapas: Um Guia Prático de Prompts para o Gemini Omni
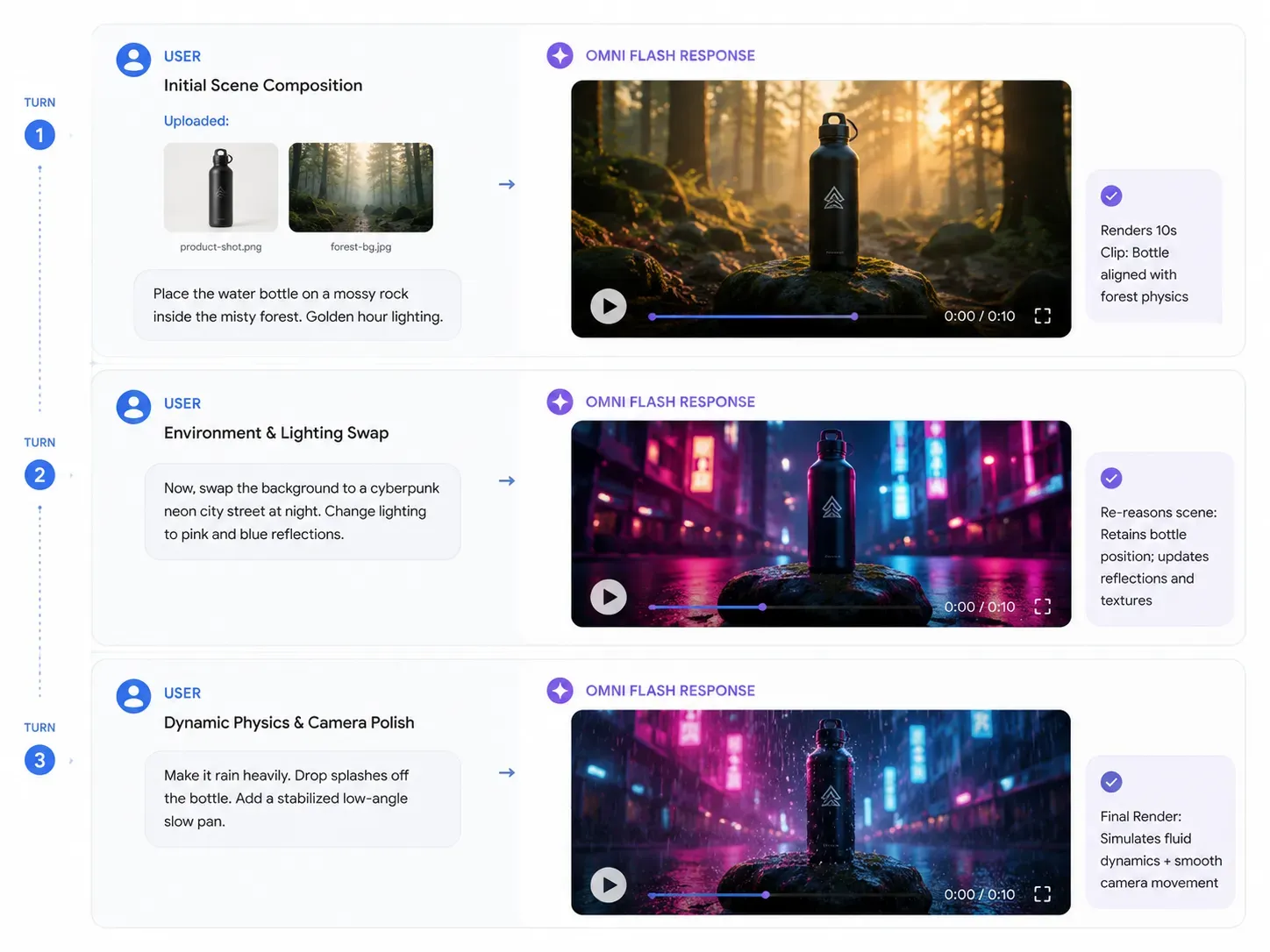
Para desbloquear todo o potencial da multimodalidade nativa do Gemini Omni, a sua estratégia de prompts deve passar da geração de uma única vez para uma conversação contínua. Como o motor de física do modelo de mundo retém a lógica do ambiente, pode sobrepor instruções passo a passo.
Aqui tem um modelo pronto para produção para um fluxo de trabalho típico de um criador comercial:
Passo 1: O Input de Referência Inicial
Ativos de Input: Carregue marca-produto-foto.png (uma garrafa de água metálica) e fundo-referencia.jpg (uma floresta enevoada).
Prompt: "Gera uma montra de produto cinematográfica de 10 segundos. Coloca a garrafa de água metálica da foto do produto numa rocha coberta de musgo dentro da floresta enevoada. Define a iluminação para a hora dourada do início da manhã."
Output esperado da IA: O Omni raciocina sobre ambas as imagens simultaneamente, colocando a garrafa de forma realista na rocha com um peso preciso baseado na física e um lançamento de sombras inicial.
Passo 2: A Modificação Dinâmica de Ativos
Contexto do Input: Conversa contínua dentro da mesma sessão (não é necessário voltar a carregar).
Prompt: "Agora, troca o fundo. Substitui a floresta enevoada por uma rua de cidade cyberpunk minimalista e elegante à noite. Muda a iluminação para reflexos de néon azul frio e rosa choque a atingir a superfície metálica da garrafa."
Output esperado da IA: O ambiente de fundo muda instantaneamente. Crucialmente, a posição da garrafa na rocha permanece consistente, mas os seus reflexos de superfície mudam dinamicamente para espelhar as novas fontes de luz de néon.
Passo 3: O Polimento Físico
| Ação do Prompt | Comando de Destino |
|---|---|
| Adicionar Física Ambiental | "Faz com que comece a chover intensamente na cena. Garante que as gotas de chuva salpiquem realisticamente o topo da garrafa e que se formem ondulações de água no chão." |
| Aplicar Controlo de Câmara | "Faz um pan lento com a câmara de um ângulo baixo para cima e aplica estabilização de vídeo em linguagem simples para suavizar a transição." |
Embora dominar o ciclo de várias etapas dentro do Google Flow otimize o seu pipeline de prompts, os programadores que escalam fluxos de trabalho com vários modelos exigem frequentemente uma maior flexibilidade. Implementar APIs de IA multimodais unificadas permite que plataformas como a Atlas Cloud sirvam mais de 300 modelos — incluindo motores avançados de vídeo, imagem e raciocínio LLM — sob uma única camada de orquestração.
Simular a Realidade: O Poder do Motor de Física do Modelo de Mundo do Gemini Omni
A edição conversacional produz excelentes resultados apenas quando o modelo compreende o porquê de uma cena parecer como parece. É aqui que a camada de física do modelo de mundo do Gemini Omni se torna crítica.
No Google I/O 2026, o CEO do Google DeepMind, Demis Hassabis, descreveu o Gemini Omni não como um gerador de vídeo, mas como um modelo de mundo — um sistema que constrói uma compreensão interna da realidade e raciocina sobre o que deve acontecer a seguir dentro de qualquer cena.
O que significa "Modelo de Mundo" na prática

A maioria das ferramentas de IA de vídeo anteriores previa o próximo fotograma através da correspondência de padrões de pixéis à escala. Produziam filmagens que pareciam reais mas que não se comportavam de forma consistente — as personagens transformavam-se entre cortes, as sombras ignoravam as fontes de luz e os fluidos moviam-se como uma textura e não como uma substância.
O Gemini Omni é treinado de forma diferente. De acordo com a Google, o modelo incorpora uma compreensão do mundo real sobre física, movimento e IA de consciência espacial para basear os seus outputs na forma como o mundo físico realmente funciona.
Propriedades Físicas que o Gemini Omni é treinado para Simular
A Google afirma que o modelo tem uma noção intuitiva das seguintes propriedades físicas, baseando-se no Genie — a plataforma de simulação de mundos de jogo do DeepMind:
| Propriedade Física | Efeito Prático no Vídeo |
|---|---|
| Gravidade | Os objetos caem e aterram com um peso preciso |
| Energia cinética | O momento é preservado durante as colisões |
| Dinâmica de fluidos | A água, o fumo e os líquidos comportam-se naturalmente |
| Consistência da iluminação | As sombras deslocam-se corretamente quando as cenas são editadas |
| Anatomia espacial | As proporções das personagens mantêm-se consistentes entre cortes |
Por que isto é importante para a geração consistente de vídeo
Durante a apresentação principal do I/O 2026, esta camada foi posta à prova ao criar uma explicação em plasticina altamente precisa sobre o enrolamento de proteínas — provando que o modelo vai além da correspondência de pixéis para compreender a realidade científica e espacial real.
Esta base de modelo de mundo é o que permite uma geração de vídeo consistente em edições de várias etapas. Quando um utilizador troca um fundo ou ajusta a iluminação através de conversa, o modelo não compõe apenas uma nova camada — ele raciocina novamente a relação física entre o sujeito, o novo ambiente e a fonte de luz. O resultado é simular a realidade física ao nível da cena, em vez de apenas remendar pixéis.
A Mudança de Paradigma: Correspondência de Pixéis vs. Simulação de Mundo
| Ferramentas de IA de Vídeo Legadas (Era Antiga) | Google Gemini Omni (Modelo de Mundo) |
| ❌ Falta de lógica central; prevê apenas a probabilidade estatística do próximo grupo de pixéis. | 🧠 Compreende a massa dos objetos, o momento cinético e a conservação da energia fluida. |
| ❌ As sombras deformam-se e as texturas rasgam-se dinamicamente quando o ângulo da câmara muda. | 🧠 Simula a iluminação global, garantindo que os raios de luz e os reflexos se refratam naturalmente. |
| ❌ A anatomia da personagem e as estruturas de fundo distorcem-se após 3–5 segundos. | 🧠 Retém um ambiente unificado, lógica de iluminação e identidade em edições de várias etapas. |
Avatares Digitais Personalizados: O Gemini Omni pode criar um avatar de IA para criadores de conteúdo?
A física do modelo de mundo descrita acima faz com que as filmagens geradas pareçam reais. A funcionalidade de avatar faz com que pareçam você.
O Gemini Omni pode criar um avatar de IA? Sim. O Gemini Omni Flash inclui uma ferramenta de avatar dedicada que permite aos criadores construir uma representação digital de si mesmos — usando a sua própria aparência e voz — e implementá-la diretamente em vídeos gerados sem ter de carregar material de referência de cada vez.
![]()
Como funciona a integração de Avatares
Para evitar o uso indevido, a Google adicionou um passo de verificação estruturado antes da criação do avatar. De acordo com o TechCrunch, os utilizadores completam um processo de integração dedicado que envolve gravar-se a si próprios e ler uma série de números. A semelhança gravada é então armazenada e reutilizada em sessões futuras.
A edição de fala completa de clipes de terceiros existentes permanece sob revisão enquanto a Google trabalha numa implementação responsável. Todos os avatares digitais personalizados e vídeos gerados possuem a marca de água digital SynthID da Google, que é verificável através da aplicação Gemini, Gemini no Chrome e Pesquisa Google.
Como é que o Gemini Omni se integra com o YouTube Shorts e o Google Flow?
A tabela abaixo mapeia o acesso atual por plataforma:
| Plataforma | Nível de Acesso | Notas |
|---|---|---|
| Aplicação Gemini | Subscritores AI Plus, Pro & Ultra | Funcionalidades completas do Omni Flash, incluindo avatar |
| Plataforma Google Flow | Subscritores AI | Inclui Flow Agent, edição em lote, Flow Music |
| Ferramentas de criador YouTube Shorts | Gratuito, sem necessidade de subscrição | Lançado na semana do Google I/O 2026 |
| Aplicação YouTube Create | Gratuito | Mesmo cronograma de lançamento dos Shorts |
| API para Programadores | Disponível em semanas | Acesso a Enterprise e Google AI Studio |
A plataforma Google Flow recebeu atualizações adicionais juntamente com o Omni Flash: um Flow Agent para brainstorming e geração em lote, uma funcionalidade de Ferramentas personalizadas para fluxos de trabalho partilháveis sem código e suporte Flow Music para a criação de videoclipes completos e transformação de estilo.
Segurança e Origem do Conteúdo: Como a Marca de Água de Vídeo Google SynthID protege a multimédia
Ferramentas poderosas de criação de avatares e edição de vídeo levantam uma questão óbvia: o que impede que sejam usadas para criar conteúdo enganoso? A resposta da Google é uma marca de água impercetível e não opcional incorporada em cada clipe que o Gemini Omni produz.
O que é a Marca de Água de Vídeo Google SynthID?
A marca de água de vídeo Google SynthID não é um logótipo visível ou uma etiqueta de metadados removível. É um sinal incorporado diretamente nos pixéis de um vídeo no momento da geração — invisível ao olho humano, mas legível pelas ferramentas de deteção da Google. De acordo com a apresentação do I/O 2026 da Google, o SynthID já marcou mais de 100 mil milhões de imagens e vídeos gerados por IA desde o seu lançamento.
Criticamente, o sinal foi concebido para sobreviver a operações comuns de pós-processamento que poderiam, de outra forma, apagar um marcador de nível superficial:
- Compressão e re-codificação
- Redimensionamento e corte
- Conversão de formato
Para o Gemini Omni especificamente, o SynthID está ativado por defeito e não pode ser desativado.
Como funciona a verificação de proveniência de multimédia de IA
A proveniência de multimédia de IA pode ser verificada através de três superfícies da Google: a aplicação Gemini, o Gemini no Chrome e a Pesquisa Google. Os utilizadores carregam um clipe e o detetor destaca os timestamps específicos onde um sinal de marca de água é encontrado — oferecendo uma verificação contextual em vez de um simples resultado sim/não.
SynthID como estratégia de mitigação de Deepfakes
| Camada de Segurança | O que faz |
|---|---|
| Marca de água ao nível do píxel | Sobrevive à compressão, corte e re-codificação |
| Incorporação não opcional | Não pode ser desativada pelo utilizador |
| Adoção multiplataforma | A OpenAI e a ElevenLabs estão a adotar a norma C2PA |
| Porta de integração de avatar | Requer verificação de voz antes da semelhança ser armazenada |
| Edição de fala retida | Edição de voz completa retida até à implementação responsável |
Sundar Pichai citou o contexto claramente no I/O 2026: estudos mostram que as pessoas identificam corretamente vídeos deepfake de alta qualidade apenas cerca de um quarto das vezes. O SynthID, juntamente com a funcionalidade de edição de fala retida, forma a abordagem em camadas do Gemini Omni para a mitigação de deepfakes e funcionalidades de segurança de conteúdo.
Gemini Omni Flash vs Pro: Níveis de Subscrição, Preços de Token e Acesso à API
Com o conjunto de funcionalidades esclarecido, a questão seguinte é prática: quanto custa realmente o acesso e que nível se adequa ao seu fluxo de trabalho?
Como obter acesso ao Gemini Omni Flash agora?

O Gemini Omni Flash começou a ser lançado a 19 de maio de 2026. As vias de acesso dependem da forma como pretende utilizá-lo:
| Nível de Plano | Preço Mensal | Armazenamento na Cloud | Aplicação Gemini e Funcionalidades Principais |
|---|---|---|---|
| Google AI Plus | $7.99 / mês | 200 GB | Limites de uso: 2x superiores aos de um plano sem Google AI; Acesso Plus ao modelo Flash Thinking; |
| Google AI Pro | $19.99 / mês | 5 TB | Limites de uso: 4x superiores aos de um plano sem Google AI; Acesso Plus ao modelo Pro, Deep Research e mais; |
| Google AI Ultra | $99.99 / mês | 20 TB | Limites de uso: 5x superiores aos do nível Pro; Obtenha limites superiores ao plano Google AI Pro, mais acesso às funcionalidades mais avançadas como Deep Think; |
Como obter acesso ao Gemini Omni dentro do Google Flow depende dos créditos Google Flow Omni atribuídos ao plano: passando do acesso de nível de entrada no AI Plus, para pipelines de cinema de várias etapas avançados no AI Pro, até limites de computação de estúdio de alto nível no AI Ultra.
Para implementações de aplicações padrão, o modelo de pagamento por token da Vertex AI da Google mantém os custos previsíveis. No entanto, para pipelines de renderização de nível de produção que atingem limites rígidos de API, mudar para modelos de preços de GPU a pedido flexíveis oferece um plano mais económico, dando às equipas controlo bruto do hardware sem compromissos mínimos.
Gemini Omni Flash vs Pro: Qual é a diferença?
Na comparação Gemini Omni Flash vs Pro, um lado está confirmado e o outro ainda não está disponível. O Flash gera clipes de 10 segundos — um limite de implementação deliberado para gerir a procura de computação no lançamento, não um limite do modelo, segundo Nicole Brichtova do Google DeepMind.
O Omni Pro foi anunciado, mas não tem data de lançamento. A Google afirma que será lançado quando a equipa verificar "uma mudança de patamar acima do Flash". Até lá, o Flash é o único modelo Omni disponível publicamente.
Gemini Omni vs Google Veo: O que mudou?
Gemini Omni vs Google Veo é uma mudança arquitetónica, não uma atualização de versão. O Veo 3.1 permanece ativo com acesso GA à API para geração de texto para vídeo. O Omni adiciona uma camada de raciocínio, aceita os quatro tipos de input simultaneamente e introduz a edição conversacional de várias etapas — nenhuma das quais o Veo foi concebido para suportar.
Uma API Unificada para Geração de Vídeo de Produção
Enquanto a Google lança o Gemini Omni Flash dentro da aplicação Gemini e do Google Flow para utilizadores finais, os programadores e equipas de produto que pretendem incorporar o mesmo motor de vídeo multimodal nos seus próprios fluxos de trabalho precisam de uma camada de API estável e previsível.
A Atlas Cloud serve o Gemini Omni Flash através de uma API unificada e compatível com a OpenAI, juntamente com mais de 300 outros modelos de imagem, vídeo e LLM — para que possa integrar o modelo multimodal nativo da Google sem gerir contas de fornecedores, portais de faturação ou SDKs separados.
Ambas as variantes do Gemini Omni Flash estão ativas na Atlas Cloud:
| Variante | Melhor para | Inputs | Resolução | Duração | Preço Inicial |
| Gemini Omni Flash Texto para Vídeo (Programador) | Geração cinematográfica pura orientada por prompt | Texto (até 20.000 carateres) | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/seg |
| Gemini Omni Flash Imagem para Vídeo (Programador) | Vídeo consistente com o sujeito a partir de referências reais | Texto + até 7 imagens de referência | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/seg |
Início Rápido — Gere um vídeo Gemini Omni Flash em 5 linhas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
A API retorna um ID de previsão imediatamente — consulte /api/v1/model/prediction/{id} para o URL do MP4 renderizado. O esquema completo, amostras de código em 7 idiomas e um Playground sem código estão disponíveis nas páginas dos modelos mencionadas acima.
Conclusão: O Futuro do Conteúdo Multimodal
O Gemini Omni representa algo mais do que um melhor gerador de vídeo. Ao fundir o motor de raciocínio do Gemini com a geração multimodal nativa, a Google colapsou o que costumava exigir quatro ferramentas separadas — prompt de texto, referenciação de imagem, renderização de vídeo e edição de pós-produção — num único fluxo de trabalho conversacional.
As implicações compõem-se rapidamente. A física do modelo de mundo significa que as edições parecem credíveis sem composição manual. A proveniência do SynthID significa que a responsabilidade está integrada, não adicionada. A criação de avatares significa que os criadores podem produzir à escala sem terem de se colocar em frente a uma câmara de cada vez. E com o Omni Flash já ativo na aplicação Gemini, Google Flow e YouTube Shorts, a barreira de entrada é suficientemente baixa tanto para criadores individuais como para equipas empresariais.
O que vem a seguir — Omni Pro, acesso mais amplo à API e modalidades de output expandidas — definirá até onde essa mudança irá.
Agora queremos ouvi-lo. Qual é a funcionalidade do Gemini Omni que tem maior probabilidade de testar primeiro no seu fluxo de trabalho — edições de fundo conversacionais, criação de avatares ou geração de cenas baseada na física? Deixe a sua resposta nos comentários abaixo.






