
Grok Imagine Video Generation é o sistema de IA multimodal de vídeo de ponta da xAI, e já redefiniu o que os criadores podem esperar de uma única chamada de API. Construído sobre o mecanismo xAI Aurora, este modelo utiliza uma rede de especialistas (mixture-of-experts) autorregressiva. Ele processa tokens de texto, imagem, vídeo e áudio simultaneamente. Essa abordagem substitui completamente os métodos de difusão-transformer encontrados em sistemas como Sora e Veo.
O principal benefício é a sincronização natural de áudio e vídeo criada durante uma única etapa de geração. Você não precisa de uma ferramenta de dublagem separada posteriormente.
Em resumo: Principais especificações
| Recurso | Detalhe |
| Duração | 1–15 segundos |
| Taxa de quadros | 24 FPS |
| Resolução | 480p / 720p |
| Áudio | Sincronia labial nativa, SFX, diálogo, música ambiente |
| Ranking | #1 no Artificial Analysis Video Arena (Elo 1404 ±6) |
Lançado no final de maio de 2026, o Grok imagine video generation estreou no topo do ranking de Imagem-para-Vídeo do Artificial Analysis Video Arena, desbancando o Seedance 2.0 da ByteDance. Para qualquer fluxo de trabalho digital moderno que exija vídeos rápidos e prontos para produção com som integrado, esta é a referência a ser batida.
Entendendo a arquitetura do Grok Imagine Video Generation da xAI
Para explorar totalmente os recursos do Grok, precisamos primeiro olhar sob o capô. Ao contrário dos modelos de vídeo tradicionais que unem som e imagem após o fato, o Grok os trata como uma entidade única. Compreender essa mudança central explica por que seu comportamento de prompt e velocidades de renderização diferem tão drasticamente das alternativas de mercado.
O que é o Grok Imagine e como ele funciona?
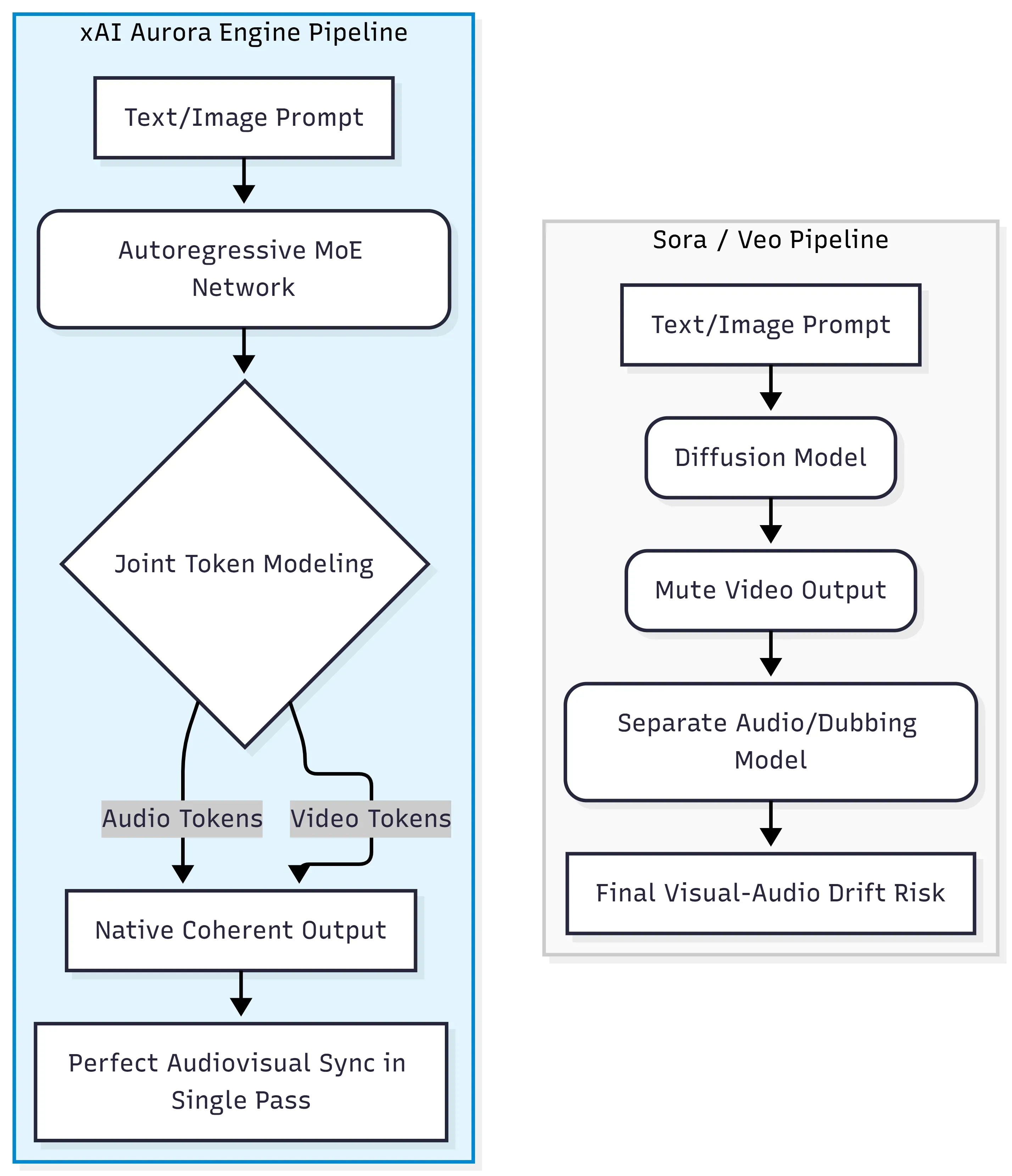
Em sua essência, o Grok Imagine Video Generation roda no mecanismo xAI Aurora, uma rede de especialistas (MoE) autorregressiva que prevê o próximo token em um fluxo unificado de dados de texto, imagem, vídeo e áudio. Isso é arquiteturalmente distinto do paradigma de difusão-transformer usado pelo Sora da OpenAI e pelo Veo do Google, onde vídeo e áudio são normalmente gerados ou alinhados em estágios separados.
A mudança em relação aos modelos de difusão-transformer
Os modelos de difusão tradicionais funcionam removendo gradualmente o ruído aleatório para formar quadros coerentes. Eles se destacam na qualidade visual, mas tratam o áudio como um complemento, exigindo ferramentas externas ou pipelines de pós-produção para adicionar som. O Aurora segue um caminho totalmente diferente.
| Abordagem | Arquitetura | Método de áudio |
| Sora / Veo | Difusão-Transformer | Pós-produção / modelo separado |
| Grok Imagine Video | MoE Autorregressivo | Geração nativa em passada única |
Processamento de tokens multimodais intercalados
Em vez de lidar com modalidades sequencialmente, o Aurora processa dados multimodais intercalados — o que significa que tokens audiovisuais (diálogo, efeitos sonoros, música ambiente) são gerados junto com os quadros de vídeo na mesma passada. Essa modelagem conjunta de tokens é exatamente o que permite que a sincronia labial e os efeitos sonoros alinhados aos eventos surjam do próprio modelo, em vez de sistemas de alinhamento separados.
Esta amostra de produção demonstra a execução em passada única do Aurora, onde a frequência acústica do motor rugindo entra em perfeita fase com a aceleração visual e a física de fricção dos pneus.
Treinamento em escala: Colossus
Eles treinaram este modelo no supercomputador Colossus da xAI. O site gigante usa cerca de 555.000 GPUs NVIDIA e consome cerca de 2 gigawatts de energia. É oficialmente o maior cluster de treinamento de IA em um único local. Essa configuração massiva é o segredo de como o Aurora mistura quatro tipos diferentes de mídia sem diminuir a qualidade.
Principais capacidades: Imagem-para-Vídeo, configurações de formato e modos de qualidade
Embora o Grok suporte texto-para-vídeo, sua verdadeira utilidade corporativa brilha nos fluxos de trabalho de Imagem-para-Vídeo (I2V). Ao fornecer ao modelo uma imagem de referência estática, você fixa as características do personagem instantaneamente, transferindo o trabalho pesado do texto descritivo para controles mecânicos precisos. Antes de mergulhar nos modos de estilo, você precisa configurar as restrições principais do pipeline.
Quais são os limites de vídeo, proporções e resoluções para o Grok Imagine?
Transformar imagens em vídeos é um dos recursos mais úteis do Grok Imagine. Você apenas carrega uma foto estática e digita um prompt simples para descrever o movimento. O modelo então anima a imagem e adiciona áudio correspondente ao mesmo tempo. Você pode controlar totalmente o formato final usando quatro configurações: duração, taxa de quadros, resolução e proporção.
Duração e taxa de quadros
O controle granular de duração permite solicitar qualquer número inteiro de segundos de 1 a 15. Isso estende o limite anterior de 10 segundos em 50%, mantendo a consistência temporal em toda a janela mais longa. Todas as saídas são renderizadas em uma base fixa de 24 FPS.
Opções de resolução
| Resolução | Qualidade | Velocidade |
| 480p | Definição padrão | Mais rápido (padrão) |
| 720p | HD (720p) | Mais lento |
Para entregas finais ou distribuição em redes sociais, 720p é a escolha prática. Use 480p para iteração rápida e testes de prompt.
Variações de proporção (aspect ratio)
Sete variações de proporção são suportadas:
| Razão | Melhor caso de uso |
| 16:09 | Widescreen / YouTube (padrão) |
| 9:16 | TikTok / Instagram Reels / Stories |
| 1:01 | Miniaturas (thumbnails) sociais |
| 4:3 / 3:4 | Apresentações / retratos |
| 3:2 / 2:3 | Formatos fotográficos |
Para a geração de imagem-para-vídeo, a saída assume como padrão a proporção nativa da imagem de entrada, a menos que seja substituída.
Diretrizes de engenharia de prompt para movimento cinematográfico e identidade zero-shot
Como o mecanismo xAI Aurora depende de modelagem de tokens conjunta, sua estratégia de prompt deve mudar. Você não precisa mais gastar tokens descrevendo a aparência física de um personagem — a imagem de entrada cuida disso por meio da preservação de identidade zero-shot. Em vez disso, seu prompt deve focar estritamente no movimento direcional, no comportamento da câmera e, crucialmente, no ambiente acústico que você deseja que o mecanismo gere em conjunto.
Como criar prompts para o Grok Imagine Video para obter os melhores resultados?
O princípio mais importante: como o Grok Imagine suporta preservação de identidade zero-shot, o modelo carrega a aparência do sujeito diretamente da imagem de entrada. Você não precisa redescobrir a cor do cabelo, roupas ou características faciais. Gaste cada palavra em dinâmicas de movimento, ambiente e direção de câmera.
A sintaxe ideal de prompt
Misture e combine estes blocos de tokens otimizados para construir ambientes cinematográficos altamente controlados:
| Ação & Movimento | Dinâmica da Câmera | Acústica & Ambiente |
| ...caminha com confiança, casaco balançando | Zoom dolly afasta-se lentamente | ...reflexos de neon em asfalto molhado. SFX: Chuva forte batendo no asfalto |
| ...corre por uma multidão, olhando para trás | Filmagem de acompanhamento baixo | ...luzes fluorescentes piscando. SFX: Murmúrios de multidão e respiração ofegante |
| ...vira lentamente, abrindo os olhos | Panorâmica macro da esquerda p/ direita | ...profundidade de campo rasa, poeira flutuando. SFX: Grave cinematográfico profundo |
Cenário A: Sequência de perseguição Cyberpunk, alta dinâmica, sincronia de áudio pesada
Prompt:
Ação & Sujeito: Um cara corre rápido por um beco molhado iluminado por letreiros de neon.
Dinâmica da Câmera: A câmera permanece baixa e segue-o de perto. O fundo passa rapidamente e luzes brilhantes cruzam a tela.
SFX: Música eletrônica rápida mistura-se com passos em poças e sirenes distantes. As batidas combinam perfeitamente com as luzes de neon piscando.
Objetivo do teste: Este teste verifica quão bem o mecanismo Aurora lida com formas durante movimentos rápidos. Também avalia a perfeição com que o mecanismo sincroniza sons com visuais, como combinar batidas de sintetizador com luzes de neon.
As vitórias (O que o Grok acertou):
- Retenção de Identidade Zero-Shot: A transição da imagem base estática é impecável. A textura de couro enrugado do sobretudo e o cabelo escuro bagunçado do personagem permanecem perfeitamente estáveis sem qualquer deformação de identidade.
- Coerência Física: O Grok lida com a corrida em alta velocidade sem duplicação de membros ou recortes de roupas — um ponto de falha notório para rivais de difusão.
- Física de Iluminação Dinâmica: Os reflexos de neon rosa e azul no asfalto molhado mudam com precisão em sincronia com o ângulo de rastreamento frontal da câmera.
As falhas (Onde gargala):
- Viés de Token de Áudio: Embora a sincronia de áudio nativa de passada única seja impressionante, o mecanismo priorizou fortemente o token de "música synthwave", abafando completamente os efeitos sonoros localizados de "respingos de poça".
- Compressão de Movimento: Em 720p, o movimento rápido da câmera causa um leve desfoque nas bordas e artefatos digitais ao redor de textos de fundo distantes, como "MIDNIGHT DINER".
Cenário B: Diálogo Cinematográfico & Explosão Emocional
Prompt:
Ação & Sujeito: Ela faz um discurso de filme tenso, sussurrando "Acaba hoje" com total convicção.
Dinâmica da Câmera: A câmera aproxima-se lentamente do rosto dela exatamente quando uma rajada forte de vento bagunça seu cabelo.
SFX: Sua voz baixa combina perfeitamente com os movimentos labiais, misturada com uma rajada de vento repentina e alta soprando no microfone e agitando suas roupas.
Objetivo do teste: Isso serve como um teste de estresse definitivo para a integração multi-token do mecanismo xAI Aurora. Ele força o modelo a executar uma sincronia labial nativa impecável e mecânica muscular facial dinâmica enquanto calcula simultaneamente a interação física caótica do movimento de cabelo/roupa, tudo combinado com efeitos sonoros ambientais realistas em uma única passada de inferência.
As vitórias (O que o Grok acertou):
- Sincronia Labial Nativa Impecável: As palavras faladas "Acaba hoje" correspondem perfeitamente aos movimentos dos lábios e mandíbula da personagem. Isso acontece naturalmente sem edição extra.
- Retenção de Microexpressão: Suas sardas faciais, pequenos piscares e olhar fixo permanecem exatamente no lugar. Isso mostra que o mecanismo mantém sua identidade estável mesmo durante closes macro.
- Simulação de Física do Vento: Assim que ela termina de falar, uma brisa repentina sopra pelo seu cabelo escuro. As mechas movem-se realisticamente e mantêm seu volume natural.
As falhas (Onde gargala):
- Artefatos de Áudio: A voz gerada, embora bem cronometrada, exibe um timbre robótico sintético ligeiramente comprimido, perdendo a textura crua e ofegante solicitada no prompt.
- Micro-transformação Temporal: Durante a sequência de agitação pelo vento, ocorre uma pequena mistura de textura ao redor da orelha e da linha do cabelo, onde o mecanismo luta ligeiramente para separar o cabelo em movimento do fundo estático da pele.
Mitigação de problemas: A matriz de contraexemplo
Como o Grok Imagine não suporta um parâmetro de prompt negativo dedicado no endpoint público atual, os engenheiros de pipeline devem mudar as heurísticas de prompt baseadas em difusão tradicionais:
- ❌ A Abordagem Incorreta (Mentalidade de Difusão): "Um homem correndo, altamente detalhado, 4k, sem borrão, sem distorção, iluminação cinematográfica."
- Análise Editorial: Isso preenche a janela de contexto com tokens irrelevantes e introduz frases negativas como "sem borrão". Uma rede de especialistas (MoE) autorregressiva como o Aurora pode interpretar mal esses termos como âncoras semânticas, gerando acidentalmente a distorção que você deseja evitar.
- ✅ A Abordagem Correta (Mentalidade Nativa Aurora): "Caminha para frente dinamicamente. Foco nítido em toda parte, texturas cinematográficas cristalinas, raios de luz volumétricos atravessando a poeira."
- Análise Editorial: Isso substitui exclusões por descrições espaciais e físicas afirmativas e determinísticas, direcionando claramente o caminho de previsão de tokens do mecanismo para uma renderização nítida.
Dicas Pro:
A coerência temporal degrada quando os prompts introduzem instruções espaciais conflitantes, como comandos simultâneos de zoom-in e panorâmica para a direita. Mantenha os movimentos de câmera singulares e direcionais. Para clipes com mais de 8 segundos, ancore o prompt em um arco de movimento contínuo em vez de múltiplos cortes de cena.
Integração da API Grok Imagine Video Generation: Início rápido com Python e REST
A transição da conceituação criativa para o dimensionamento de produção requer o envio desses parâmetros pelo gateway da API oficial da xAI. Dependendo da sua infraestrutura atual e se você prefere o levantamento automático em segundo plano ou um loop personalizado leve, a xAI oferece dois caminhos de implementação distintos.
Como chamo a API Grok Imagine para vídeo?
Existem dois caminhos suportados para chamar a API Grok Imagine: o cliente xai_sdk nativo (que lida com o polling automaticamente) e a abordagem REST base_url compatível com OpenAI via https://api.x.ai/v1. Ambos exigem autenticação com chave de API definida como uma variável de ambiente.
Pré-requisitos
Antes de escrever qualquer código, conclua estas etapas:
- Gere uma chave de API em console.x.ai
- Exporte-a no seu shell: export XAI_API_KEY="sua-chave-aqui"
- Instale o SDK: pip install xai-sdk
Caminho 1: xai_sdk nativo (Recomendado)
O cliente xai_sdk envolve todo o loop de polling assíncrono internamente, para que você receba um objeto de vídeo concluído com uma única chamada para o endpoint video.generate:
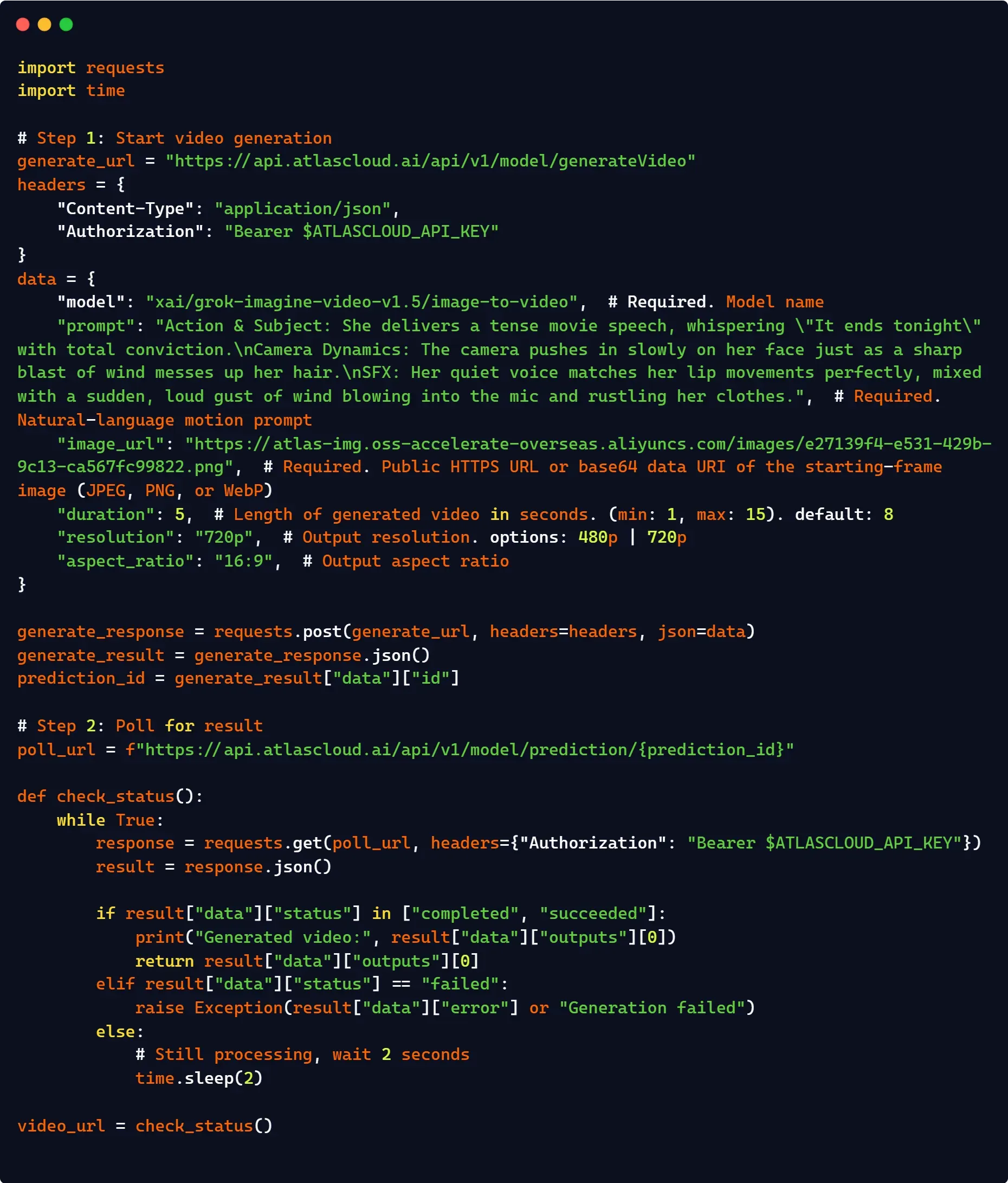
python1import os 2import xai_sdk 3 4client = xai_sdk.Client(api_key=os.getenv("XAI_API_KEY")) 5 6# Certifique-se de passar a imagem de referência para fluxos de trabalho de Imagem-para-Vídeo 7response = client.video.generate( 8 model="grok-imagine-video", 9 image="sua imagem", # URL obrigatória ou base64 10 prompt="seu prompt", 11 duration=5, 12 aspect_ratio="16:9", 13 resolution="720p", 14) 15 16# CORRIGIDO: Alinhado com o esquema de resposta padrão do xai_sdk 17print(f"Geração bem-sucedida. URL do vídeo: {response.video.url}")
Nenhum polling manual é necessário. O SDK envia a solicitação, aguarda a conclusão e retorna a URL.
Caminho 2: API REST Padrão (Loop assíncrono personalizado)
Para ambientes onde o SDK nativo não está disponível, use os endpoints HTTP subjacentes. Como a geração de vídeo é assíncrona, você deve implementar manualmente uma sequência de polling para rastrear o status da execução:
python1import os 2import time 3import requests 4 5headers = { 6 "Authorization": f"Bearer {os.environ['XAI_API_KEY']}", 7 "Content-Type": "application/json", 8} 9 10payload = { 11 "model": "grok-imagine-video", 12 "image": "sua imagem", 13 "prompt": "prompt", 14 "duration": 5, 15 "aspect_ratio": "16:9", 16 "resolution": "720p" 17} 18 19# 1. Enviar a solicitação de geração de vídeo 20res = requests.post("https://api.x.ai/v1/videos/generations", headers=headers, json=payload) 21res.raise_for_status() 22request_id = res.json()["request_id"] 23 24# 2. Consultar o status do endpoint até ficar pronto 25while True: 26 poll = requests.get(f"https://api.x.ai/v1/videos/{request_id}", headers=headers) 27 data = poll.json() 28 29 if data["status"] == "done": 30 # CORRIGIDO: Alinhado com o retorno do esquema JSON oficial da xAI 31 print(f"Sucesso! Ativo disponível em: {data['video']['url']}") 32 break 33 elif data["status"] in ["expired", "failed"]: 34 print(f"Geração falhou com status: {data['status']}") 35 break 36 37 time.sleep(5) # Intervalo de limitação de taxa seguro
Referência de status de polling
A API retorna um dos quatro valores de status durante a geração:
| Status | Significado |
| pending | Ainda processando |
| done | Vídeo pronto, URL disponível |
| expired | Solicitação expirou |
| failed | Erro na geração |
Consulte a cada 5 segundos para permanecer dentro de limites de taxa razoáveis. O SDK usa intervalos padrão de 100ms, mas 5 segundos é prático para fluxos de trabalho de produção.
Alternativa de Produção: Simplificação via Atlas Cloud API Gateway
Para pipelines corporativos que exigem alta concorrência, faturamento unificado ou roteamento de alta disponibilidade, a integração via um gateway gerenciado de terceiros como o Atlas Cloud é uma alternativa de produção viável. Em vez de gerenciar seus próprios loops de polling assíncronos e verificações de status complexos localmente, o wrapper unificado do Atlas Cloud lida com o enfileiramento do lado do servidor e a persistência de estado automaticamente.
Além disso, ele oferece uma substituição direta ao rotear solicitações através de uma URL base unificada, minimizando alterações de código enquanto desbloqueia limites de taxa de nível corporativo que normalmente excedem os limites dos níveis públicos padrão da xAI.
Desempenho de Benchmark: Custo, Latência e Comparação com Concorrentes
Saídas audiovisuais de alta fidelidade só são viáveis para pipelines corporativos se estiverem alinhadas com orçamentos de computação rígidos e requisitos de latência. Para ver onde o Grok se posiciona no mercado, testes de estresse de terceiros mapeiam suas velocidades de geração e custos por segundo diretamente contra gigantes da indústria estabelecidos.
O Grok Imagine Video é mais rápido e barato que outras ferramentas de IA de vídeo?
Em benchmarks independentes, a resposta é em grande parte sim. O Grok Imagine Video estreou em primeiro lugar no ranking de Imagem-para-Vídeo da Artificial Analysis Video Arena com uma pontuação Elo de 1404 ±6, deslocando o Seedance 2.0 da ByteDance da primeira posição.
Comparação direta entre concorrentes
| Modelo | Desenvolvedor | Duração Máx | Resolução Máx | Áudio Nativo |
| Grok Imagine V1.5 | xAI | 15s | 720p | Sim |
| Comparação Seedance 2.0 | ByteDance | 4–12s | 720p | Sim |
| Veo 3.1 | 8s | 1080p | Sim | |
| Sora 2 | OpenAI | 20s | 1080p | Sim |
| Runway Gen-4 | Runway | 10s | 1080p | Parcial |
Velocidade de inferência e latência
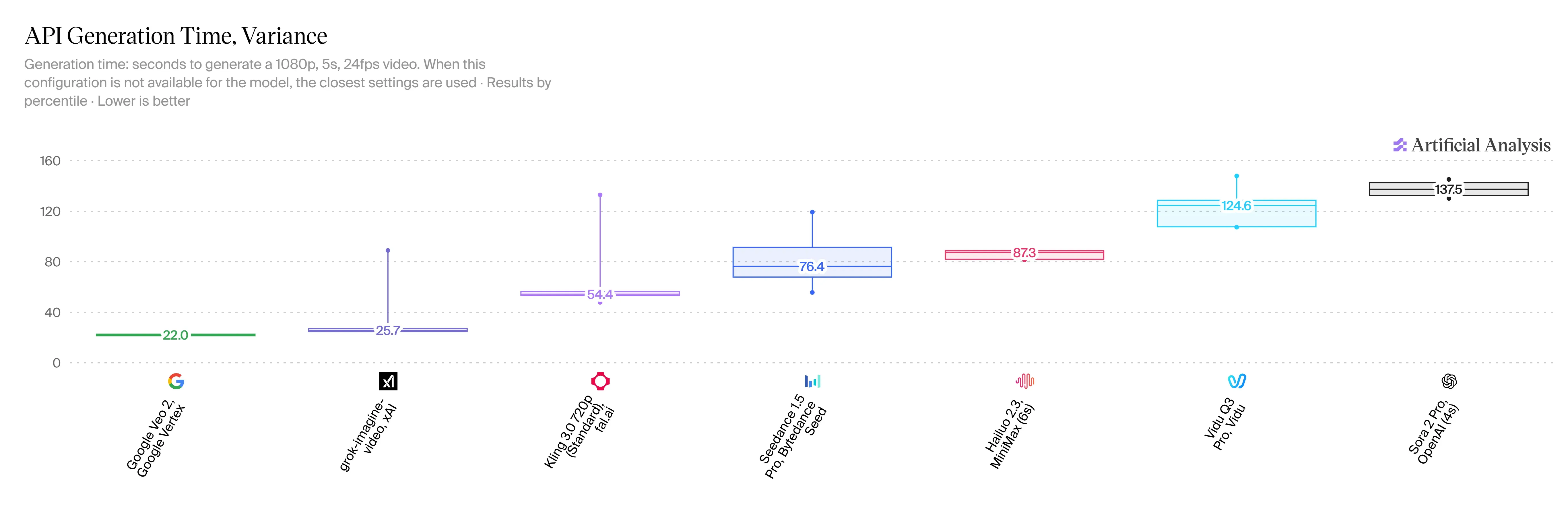
A V1.5 é incrivelmente rápida, e isso é uma grande vitória para os usuários. Você pode criar um clipe de 5 segundos e 720p em apenas 20 a 30 segundos. Comparado ao HappyHorse 2.3, isso reduz seu tempo de espera de 2 a 3 vezes. Ainda não temos estatísticas oficiais de velocidade para o Veo 3.1, mas as pessoas online dizem que leva mais de um minuto para um clipe semelhante.
Estrutura de preços
A estrutura de preços por segundo via gateways de API de terceiros, como o Atlas Cloud, começa em aproximadamente USD0.096 por segundo de vídeo gerado. Nessa taxa, um clipe de 10 segundos custa cerca de USD0.96, tornando a experimentação econômica genuinamente acessível para criadores independentes e pequenas equipes que iteram em múltiplas variantes de prompt antes de se comprometerem com uma execução de produção final.
Segurança corporativa, privacidade de dados e conformidade de conteúdo
Implantar ativos de mídia proprietários ou conteúdo voltado para o cliente em qualquer sistema de IA baseado em nuvem introduz questões legais necessárias. Para casas de produção comercial, saber onde seus dados de entrada generativos param — e como eles são isolados — é tão importante quanto a qualidade da saída final.
A xAI usa meus dados de API ou vídeos gerados para treinar seus modelos?
Esta é uma das perguntas mais comuns de adotantes corporativos, e merece uma resposta direta. De acordo com os termos para desenvolvedores da xAI, as entradas e saídas da API processadas pela plataforma estão sujeitas à revisão de política de conteúdo para filtragem de segurança, mas são tratadas sob princípios de Privacidade de Dados por Design que separam os dados de inferência dos pipelines de treinamento públicos.
Visão geral da estrutura de conformidade
Provedores de gateway de API de terceiros que oferecem acesso ao Grok Imagine, como o Atlas Cloud, publicam suas próprias certificações de conformidade independentes:
| Padrão de Conformidade | Status |
| Conformidade SOC 2 Tipo II | Certificado |
| Residência de dados GDPR | Alinhado |
| HIPAA | Elegível |
Principais limites de privacidade para profissionais
Profissionais que avaliam o Grok Imagine para fluxos de trabalho comerciais devem observar o seguinte:
- As saídas de vídeo geradas são retornadas como URLs hospedadas temporárias e não são armazenadas permanentemente por padrão.
- A revisão da política de conteúdo filtra as saídas quanto a violações de segurança antes da entrega, mas não retém o conteúdo para reutilização.
- Exclusões de treinamento de modelo aplicam-se aos usuários da API: seus prompts e mídia gerada não são alimentados de volta nos loops de treinamento de modelo públicos.
- O alinhamento com a residência de dados GDPR significa que as práticas de tratamento de dados atendem aos padrões europeus de processamento para equipes que operam em diferentes jurisdições.
Para implantações corporativas que exigem acordos de processamento de dados formais ou políticas de retenção personalizadas, o contato direto com a equipe corporativa da xAI via x.ai é o próximo passo apropriado.






