
Kling 2.6 é a atualização mais significativa do Kling AI até hoje, mas traz uma ressalva importante que você precisa conhecer antes de começar.
Este lançamento marca a primeira vez que o Kling disponibiliza um modelo com sincronização de áudio nativa. Anteriormente, cada vídeo gerado era essencialmente um filme mudo. Antes, os criadores precisavam adicionar narrações, efeitos sonoros e ruído de fundo manualmente após a criação do vídeo. O novo modelo VIDEO 2.6 muda tudo: ele cria o visual, narrações realistas, efeitos sonoros correspondentes e áudio de fundo simultaneamente. Esse recurso coloca a ferramenta em um patamar completamente diferente.
O que funciona bem
Este modelo é excelente em sincronizar visão e som. O ritmo da voz, o ruído de fundo e as ações na tela alinham-se perfeitamente, eliminando a desconexão comum entre vídeos e faixas de áudio separadas. Os sons cinematográficos parecem incrivelmente realistas. É possível ouvir claramente detalhes como fogo estalando, chuva nas ruas e o som ambiente de uma multidão. O suporte abrange seis tipos de áudio:
| Tipo de Áudio | Caso de uso |
| Narração de voz | Vídeos de produtos, vlogs |
| Diálogo com vários personagens | Entrevistas, esquetes |
| Canto / Rap | Apresentações musicais |
| Som ambiente | Natureza, cenas urbanas |
| Efeitos sonoros (SFX) de objetos/ações | Impactos, ruídos mecânicos |
| Som misto | Produções completas e imersivas |
A principal limitação
Cenas de diálogo com vários personagens (três ou mais falantes) podem produzir atribuição de voz inconsistente. Para obter a sincronização audiovisual mais confiável, os criadores devem optar por diálogos entre dois personagens ou considerar um enquadramento alternativo.
Como ele se compara
A versão 2.6 é um grande salto em relação aos modelos silenciosos anteriores. Alguns usuários podem precisar de controle perfeito ou resultados de altíssima qualidade; para eles, o ideal é o Kling 3.0. No entanto, a maioria dos criadores de conteúdo faz avaliações altamente positivas do Kling 2.6 porque ele oferece uma excelente qualidade pelo preço.
A anatomia do áudio nativo do Kling: mergulho profundo em diálogos, efeitos sonoros e ambiência
O Kling 2.6 não apenas adiciona áudio ao vídeo; ele gera as três camadas de áudio simultaneamente com os quadros visuais em uma única passagem. Veja como cada camada funciona na prática:
Diálogo e fala
A geração de diálogos do Kling AI abrange um alcance maior do que a maioria dos criadores espera. Este modelo gerencia facilmente falas solo, diálogos entre personagens, narração, canto e rap, ajustando o tom emocional para combinar com cada estilo. Além disso, a ferramenta é bilíngue e suporta nativamente saídas de voz em inglês e chinês. Se você inserir outros idiomas, o modelo os traduz automaticamente para o inglês para a geração de voz, sem afetar o resultado visual do vídeo.
O vídeo de 8 segundos acima demonstra nossa saída direta usando o Kling 2.6 através da plataforma de orquestração da Atlas Cloud. Ao fazer o upload de uma imagem base de alta resolução do falante e uma faixa de voz em inglês pré-gravada de 8 segundos, o motor processou a sincronia labial nativamente.
Observe como a sincronização dos músculos faciais mapeia suavemente fonemas complexos sem a distorção robótica comum do "vale da estranheza" (uncanny valley). Isso serve como um modelo perfeito para ativos rápidos de porta-vozes de marca gerados por IA.
Regras rápidas para economizar tempo:
- Atenção às letras maiúsculas. Use minúsculas para palavras comuns. Reserve maiúsculas para nomes e siglas.
- Identifique seus falantes. Dê a cada pessoa uma etiqueta como [Personagem A] ou [Personagem B]. Isso evita que a IA misture suas vozes.
- Descreva o clima. Coloque notas de tom logo após a etiqueta. Por exemplo, escreva [Repórter, voz calma e firme].
Efeitos sonoros (SFX)
Os efeitos sonoros de vídeo por IA no 2.6 são acionados pelo contexto, em vez de serem atribuídos manualmente. O modelo lê a descrição da cena e infere os sons apropriados. A IA gera sons baseados diretamente em suas palavras de ação. Ele pode criar passos no cascalho, vidro quebrando, pneus cantando ou o zumbido de uma máquina. Para melhores resultados, nomeie a fonte sonora específica claramente. Por exemplo, escrever [Porta de madeira fecha, estrondo alto] funciona muito melhor do que apenas dizer "há um ruído".
Som ambiente
A síntese de áudio ambiente lida com a camada do cenário: murmúrio de café, chuva no vidro, vento em um campo aberto, metrô chegando. Essas faixas de fundo tocam sob o seu diálogo e efeitos sonoros, adicionando profundidade real ao vídeo. Você deve nomear o cenário específico no seu prompt. Por exemplo, use termos como [acústica de sala pequena] ou [reverberação de salão aberto]. Isso dá ao modelo um objetivo claro e melhora o áudio.
Duração: Saída de 5 segundos vs. 10 segundos
Essa escolha afeta diretamente a estabilidade do áudio. A decisão entre vídeo de 5 segundos vs. 10 segundos no Kling é mais importante para conteúdos focados em fala.
| Tipo de conteúdo | Duração recomendada | Motivo |
| Apenas ambiente / SFX | 5s | Saída limpa e precisa |
| Monólogo / Narração | Qualquer um | Depende do tamanho do roteiro |
| Diálogo com vários personagens | 10s | Alternância de voz mais estável |
| Canto / Rap | 10s | Evita cortes na letra |
Para cenas de canto ou diálogo, o parâmetro de 10 segundos é recomendado para resultados mais completos e estáveis. Clipes mais curtos funcionam bem para atmosfera pura ou pareamento de ação e som, mas qualquer coisa que envolva falas se beneficia da janela mais longa para evitar o desvio (drift) de áudio nos segundos finais.
A fórmula de prompt perfeita do Kling 2.6 para uma sincronia audiovisual impecável
A maioria dos problemas de sincronia no Kling 2.6 não vem do modelo, mas de prompts que deixam muita coisa aberta à interpretação. Pense no seu prompt como o briefing de um diretor: quanto mais precisamente você define cada elemento, menos o mecanismo de inferência precisa adivinhar — e é quando ele tenta adivinhar que o ritmo falha.
A fórmula central
Este modelo de prompt do Kling mapeia diretamente como o modelo processa a geração:
Cena → Assunto → Movimento e Câmera → Plano de Áudio
A estrutura oficial do prompt é: Cena (descrição do cenário) + Elemento (descrição do assunto) + Movimento (descrição do movimento) + Áudio (diálogo / canto / efeitos sonoros / música) + Outros (estilo / emoção / câmera).
Cada bloco alimenta uma parte diferente do pipeline de geração. Pular qualquer um deles força o modelo a preencher a lacuna, que é o momento em que o ritmo audiovisual se perde.
Detalhamento bloco a bloco
| Bloco | O que incluir | Erro comum |
|---|---|---|
| Cena | Localização, iluminação, hora do dia | Vago demais: "um quarto" |
| Assunto | Aparência, papel, posição no quadro | Personagens sem nome ou apenas pronomes |
| Movimento e Câmera | Sequência de ação, linguagem de controle de câmera (zoom lento, tracking, close-up) | Nenhuma instrução de câmera |
| Plano de Áudio | Diálogo entre aspas, etiqueta de emoção, rótulo de SFX, camada ambiente | Diálogo enterrado no texto de descrição |
Exemplo pronto: A anatomia de uma renderização perfeita
Devido a restrições de API regionais e gargalos na fila da plataforma nativa do Kling, utilizar o pipeline kling-v2.6-std-avatar na Atlas Cloud é o caminho mais confiável para produção automatizada de alto volume. Embora este nível limite você a um formato de "cabeça falante" estática em vez de cenas dinâmicas com vários agentes, ele se destaca imensamente no mapeamento fonético preciso.
Para provar a autoridade da nossa Fórmula Central, executamos o blueprint exato acima através do Kling 2.6 (nível kwaivgi-kling-v2.6-std-avatar) via plataforma Atlas Cloud. O clipe de 2 segundos acima representa a saída comercial não editada, feita em uma única passagem.
Vamos analisar por que essa renderização alcança um naturalismo perfeito sem cair no "vale da estranheza":
- Bloqueio de Composição (Frame 0): Ao usar uma imagem inicial onde a anfitriã já está posicionada com o smartwatch próximo ao rosto, eliminamos o risco de distorção de membros. A IA não precisa adivinhar a mecânica óssea complexa; ela apenas anima as microexpressões.
- Precisão de Sincronia Labial: Observe como os movimentos labiais e o rastreamento dental acompanham perfeitamente a velocidade das sílabas de "Zero lag. All day battery."
- Iluminação Cinematográfica e Profundidade: A profundidade de campo rasa (fundo desfocado) filtra pesadamente o ruído de fundo, forçando os pipelines de IA a focar 100% do seu peso computacional na renderização de poros da pele realistas e texturas de roupas nítidas.
Duração e a janela de áudio
Conhecer a duração máxima do clipe no Kling AI é importante para o planejamento do áudio. As saídas atuais vão até 10 segundos. Para uma demonstração de produto como o exemplo acima, 10 segundos é a escolha certa: dá espaço para a narração terminar de forma limpa sem cortar a última palavra. Clipes de 5 segundos atendem bem a atmosferas puras ou pares de ação-SFX onde não há fala para concluir.
Planeje o tamanho do seu roteiro de acordo com a duração do clipe antes de escrever o prompt, não depois.
Fluxo de trabalho de imagem para vídeo: Mantendo a consistência do personagem com o Kling Motion Control
Para criadores profissionais, o caminho texto-para-vídeo é apenas um ponto de entrada. O fluxo de trabalho de imagem para vídeo no Kling é onde conteúdos sérios focados em personagens são criados. Quando combinado com o Kling 2.6 Motion Control, ele oferece um nível de consistência que o simples prompt de texto não consegue alcançar.
Como o pipeline I2V ancora a identidade
Quando você faz upload de uma imagem de referência no modo Imagem-para-Audiovisual, ela atua como um contrato visual com o modelo. A imagem de entrada especifica a aparência, composição, estilo e outros recursos visuais do sujeito, tornando o vídeo gerado mais próximo da imagem original. Essa é a base da consistência de personagens por IA: o modelo trata o rosto, a roupa e o enquadramento enviados como restrições fixas, e não como sugestões.
Isso é fundamental para:
- Conteúdo de porta-vozes de marca que exigem o mesmo rosto em vários clipes
- Personagens de PI que precisam manter a aparência entre cenas
- Anfitriões de demonstração de produto onde a identidade visual é parte do ativo
Motion Control: Projetando dados físicos
Uma imagem de referência trava a aparência. O Kling 2.6 Motion Control adiciona a camada física ao projetar dados de gestos, postura e movimento de uma referência de movimento sobre o personagem gerado. A referência de movimento atua como um modelo de performance, com o modelo transferindo a mecânica corporal enquanto preserva a identidade visual ancorada pela imagem de entrada.
Essa separação entre identidade (imagem) e movimento (clipe de referência) é o que torna a abordagem de animação por IA com referência de vídeo mais confiável do que descrever o movimento apenas em texto.
Sincronia labial e alinhamento de áudio no I2V
A sincronia labial do Kling 2.6 é tratada nativamente quando o Áudio Nativo está ativado no modo Imagem-para-Vídeo. O recurso de Controle de Voz permite vincular uma voz específica a um personagem usando o formato [Personagem@NomeDaVoz], permitindo que o modelo replique com precisão as características vocais para executar o conteúdo especificado.
| Camada de entrada | O que controla |
| Imagem de Referência | Rosto, roupa, enquadramento, estilo visual |
| Referência de Movimento | Gestos, mudanças de postura, ritmo corporal |
| Vinculação de Controle de Voz | Timbre, estilo de entrega, consistência entre idiomas |
| Bloco de áudio do prompt | Conteúdo do diálogo, etiqueta de emoção, camada ambiente |
Exemplo pronto: Aplicando a Fórmula Central em fluxos de trabalho de Imagem para Vídeo (I2V)
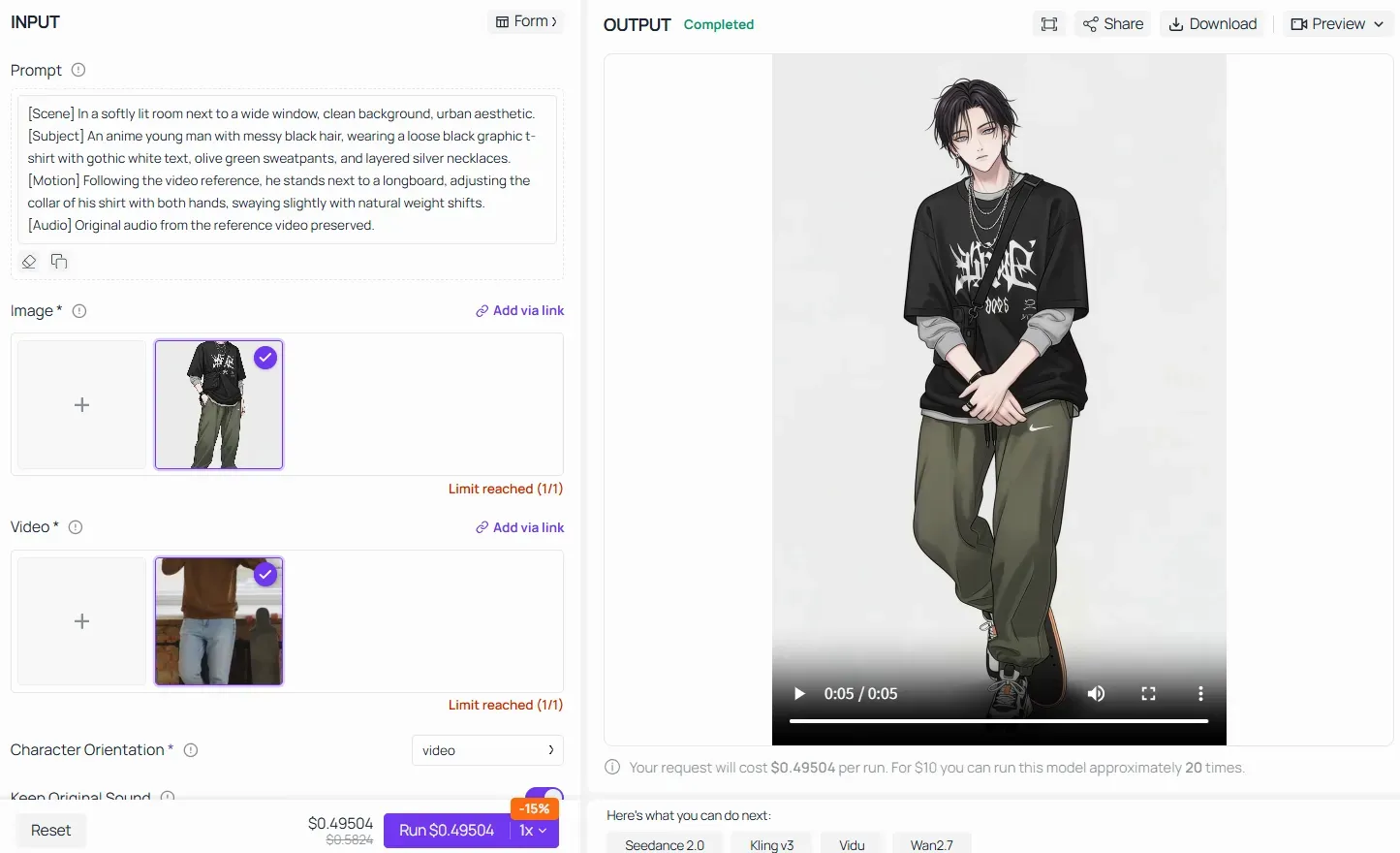
Ao utilizar recursos avançados como Vídeo de Referência / Transferência de Movimento em plataformas como Atlas Cloud, a Fórmula Central ainda detém autoridade absoluta. Em vez de dar à IA instruções vagas como "faça o personagem de anime fazer a mesma dança", você deve estruturar o prompt separando a cena, congelando as características da imagem enviada e travando o mapeamento de movimento:
Ao preencher cada bloco do pipeline, você garante que o modelo de IA transfira perfeitamente a mecânica óssea física pesada do vídeo do mundo real para o ativo de personagem de anime carregado, sem destruir sua identidade visual.
Regra de ouro para Motion Control no Kling 2.6: seu prompt de texto não precisa se preocupar com os pequenos detalhes mecânicos (como "mova o braço 45 graus"). Deixe o vídeo de referência fazer o trabalho pesado da cinemática. Em vez disso, use seus blocos [Assunto] e [Cena] para travar impiedosamente o estilo visual, as texturas e as paletas de cores, garantindo que a IA transfira a performance sem distorcer a identidade da imagem original.
Qualidade de imagem e limites práticos
Tenha em mente uma regra principal: seu vídeo final parecerá tão bom quanto a imagem que você fizer o upload.
Sempre use imagens de alta resolução. Imagens de baixa resolução resultarão em vídeos granulados e borrados. A IA não consegue corrigir esses detalhes posteriormente. Esse problema é muito evidente em closes de rostos.
Use uma imagem de origem de resolução mais alta e a consistência do seu personagem se manterá em janelas de 5 e 10 segundos sem degradação.
Solução de problemas técnicos: Resolvendo gargalos de geração e desvio de áudio
Mesmo criadores experientes encontram atrito com o Kling 2.6. Os dois problemas mais relatados são gerações que travam no meio do processo e diálogos que perdem a sincronia após a metade do clipe. Ambos têm causas identificáveis e correções práticas.
Por que o Kling trava em 99%
Se o seu vídeo trava em 99%, geralmente acontece por dois motivos: os servidores podem estar muito ocupados ou o seu prompt pode ser complicado demais para o sistema processar. A IA tenta construir todos os sons e visuais exatamente ao mesmo tempo. Se você colocar muita informação no prompt, as instruções entram em conflito. Essa confusão deixa o sistema lento ou o congela completamente.
Correções para tentar:
- Tente novamente mais tarde. Atualize a página e envie o prompt durante horários de menor movimento. O início da manhã geralmente funciona melhor.
- Simplifique. Divida seu prompt complicado em duas partes menores e execute-as como gerações de vídeo separadas.
- Remova descrições de ambiente acumuladas e mantenha uma camada de som dominante por clipe.
- Reduza o número de personagens se estiver usando três ou mais falantes em uma única geração.
Como corrigir o desvio (drift) de diálogo
Corrija o desvio de diálogo abordando sua causa raiz: o processamento multifalantes do modelo degrada após a marca de 5 a 6 segundos quando muitas instruções de voz competem. O desempenho pode cair em cenas com três ou mais personagens.
| Cenário | Correção recomendada |
| Diálogo de dois falantes acima de 10s | Use duração de 10s com pistas claras de troca de falante |
| Três ou mais falantes | Divida em clipes separados por par de falante |
| Monólogo longo desviando | Reduza o roteiro para caber confortavelmente na janela de 10s |
| Canto cortando | Sempre use o parâmetro de 10s para conteúdo musical |
Reduzindo artefatos e otimizando créditos
Para reduzir artefatos de geração, mantenha os arquivos de origem de imagem para vídeo em alta resolução e evite descrições de cena incompatíveis. Sobre a otimização de consumo de créditos, observe que o Áudio Nativo ativado custa 10 créditos por segundo no Modo Profissional, contra 5 créditos por segundo com o áudio desativado. Faça rascunhos com o áudio desligado e, em seguida, ative-o apenas para as renderizações finais para esticar melhor seu orçamento de limitações da plataforma.
Kling 2.6 vs. Kling 3.0 vs. Wan 2.6 vs. Veo 3.1: Comparação direta
Não espere que uma ferramenta de vídeo por IA faça absolutamente tudo. Quando você quer áudio integrado, a "melhor" escolha depende apenas do seu orçamento, fluxo de trabalho e do que seu clipe de vídeo realmente precisa.
Resumo da comparação de recursos
| Recurso | Kling 2.6 | Kling 3.0 | Wan 2.6 | Veo 3.1 |
| Áudio Nativo | Completo (Diálogo/SFX/Ambiente) | Completo (Sincronia de passo único) | Completo (Inclui Sincronia Labial) | Completo (Áudio espacial 3D) |
| Duração máx. do clipe | 10s | 15s | 15s | 8s |
| Resolução máx. | 1080p | 4K Nativo | 1080p | 4K Nativo |
| Controle de Movimento | Forte (Esquelético/Ref. de vídeo) | Forte (Bloqueio total de identidade) | Moderado (Transferência de estilo/movimento) | Moderado (Física de dinâmica de fluidos) |
| Multi-Shot | Não | Sim (Até 6 tomadas em passo único) | Sim (Suporte a textos longos de várias cenas) | Não |
| Controle de Voz | Sim | Sim | Não (Depende do prompt) | Não (Depende do prompt) |
| Preço | $0,048 - $0,095/s | $0,071 - $0,357/s | $0,018 - $0,7/s | $0,05 - $0,2/s |
Nota: Os preços referem-se à Atlas Cloud.
Onde o Kling 2.6 leva vantagem
Kling 2.6 vs Wan 2.6 não é uma competição acirrada em áudio. O Wan 2.6 tem apenas suporte parcial a áudio, enquanto o Kling 2.6 oferece camadas completas de diálogo, efeitos sonoros e ambiente em uma única passagem. Para criadores que precisam de clipes completos e prontos para uso sem pós-produção, o Kling 2.6 é o fluxo de trabalho mais limpo.
O Kling 2.6 custa mais de 50% menos que o Veo 3.1. Se você não precisa de qualidade de vídeo de nível de Hollywood, o Kling é a escolha muito mais inteligente, permitindo criar grandes volumes de conteúdo sem estourar o orçamento.
Onde o Veo 3.1 se destaca
Veo 3.1 vs Kling video resume-se ao realismo e à espacialização do áudio. O Veo 3.1 gera ambientes sonoros tridimensionais onde as fontes de áudio se movem pelo campo estéreo, com saída a 48kHz e codificação AAC estéreo a 192kbps. Em março de 2026, nenhum outro grande modelo de vídeo por IA oferece esse nível de espacialização de áudio. Para diálogos com qualidade de transmissão e renderização de texto, o Veo 3.1 continua sendo a escolha mais forte.
Comparação de física de vídeo por IA
Na física de vídeo por IA, os modelos divergem claramente. O Kling 2.6 oferece excelente fluidez de movimento com simulação de física mais realista para o movimento humano, enquanto o Veo 3.1 mostra inconsistências físicas ocasionais, mas se destaca em iluminação e texturas.
Framework de decisão
- Escolha o Kling 2.6 para: personagens controlados por voz, produção econômica, conteúdo social, saída audiovisual completa em uma única passagem.
- Escolha o Kling 3.0 para: tomadas cinematográficas mais longas, storyboards de várias cenas, saída 4K.
- Escolha o Wan 2.6 para: código aberto, iteração de custo zero e testes de rascunho.
- Escolha o Veo 3.1 para: áudio espacial, renderização de texto, anúncios de produtos fotorealistas.
Conclusão: O novo ritmo da produção de vídeos com IA
A cadeia tradicional de produção de vídeo — exportar visuais, gerar narração separadamente, aplicar efeitos sonoros e, em seguida, mixar tudo na pós-produção — não se aplica mais ao usar o Kling 2.6. Toda essa sequência agora se resume a um único envio de prompt.
Os criadores que avançam mais rápido são aqueles que tratam a escrita de prompts como um trabalho de direção, e não como uma busca. O verdadeiro truque para um vídeo de nível profissional é simples: basta reunir seus planos de cena, assunto, movimento e som em um único prompt claro.
Atualmente, o Kling 2.6 é uma das melhores ferramentas disponíveis. Ele funciona muito bem para grandes equipes de conteúdo, criadores solo e estúdios de marketing que desejam vídeos rápidos e de alta qualidade. O teto técnico continuará subindo. Dominar a estrutura do prompt agora constrói a base criativa para escalar com ele.






