
A MiniMax acaba de apresentar uma aceleração de 15,6× na decodificação com 1 milhão de tokens. Se esse número se confirmar, o custo de rodar contextos de um milhão de tokens cairá quase uma ordem de magnitude — e a geração ficará mais rápida, em vez de mais lenta, durante o processo.
Para quem desenvolve com esses modelos, isso redefine o que é acessível. Workloads que hoje não são viáveis começam a fazer sentido: entregar ao seu agente de codificação toda a sua base de código em vez de fragmentos, execuções de agentes de várias horas que acumulam históricos enormes, ou busca em conjuntos completos de documentos em vez de trechos isolados. A pergunta que toda equipe enfrenta — quanto posso colocar na janela de contexto antes que a fatura ou a latência matem o produto? — ganha um teto muito mais alto.
O mecanismo é a atenção esparsa (sparse attention), e a MiniMax não está sozinha. A DeepSeek a implementou em três linhas de modelos, a Qwen tem sua própria versão e agora a MiniMax. A direção está definida. O que está mudando é a consequência: quando todo modelo de fronteira consegue executar contextos longos a baixo custo, o modelo deixa de ser o diferencial competitivo — e essa é a parte que merece sua atenção, à qual voltaremos no final.
Dois avisos honestos primeiro, pois são importantes para qualquer pessoa que vá implementar isso:
- Estes são números da própria MiniMax, extraídos de um único diagrama de um modelo não lançado, na infraestrutura deles. Um forte sinal de direção — não um benchmark de terceiros. Trate-os como "o que a MiniMax alega" e teste novamente com seu próprio workload quando os pesos forem liberados.
- O M3 ainda não é público. Esperamos trazê-lo para o Atlas Cloud com acesso no dia do lançamento (day-zero access) assim que for liberado — mais detalhes ao final.
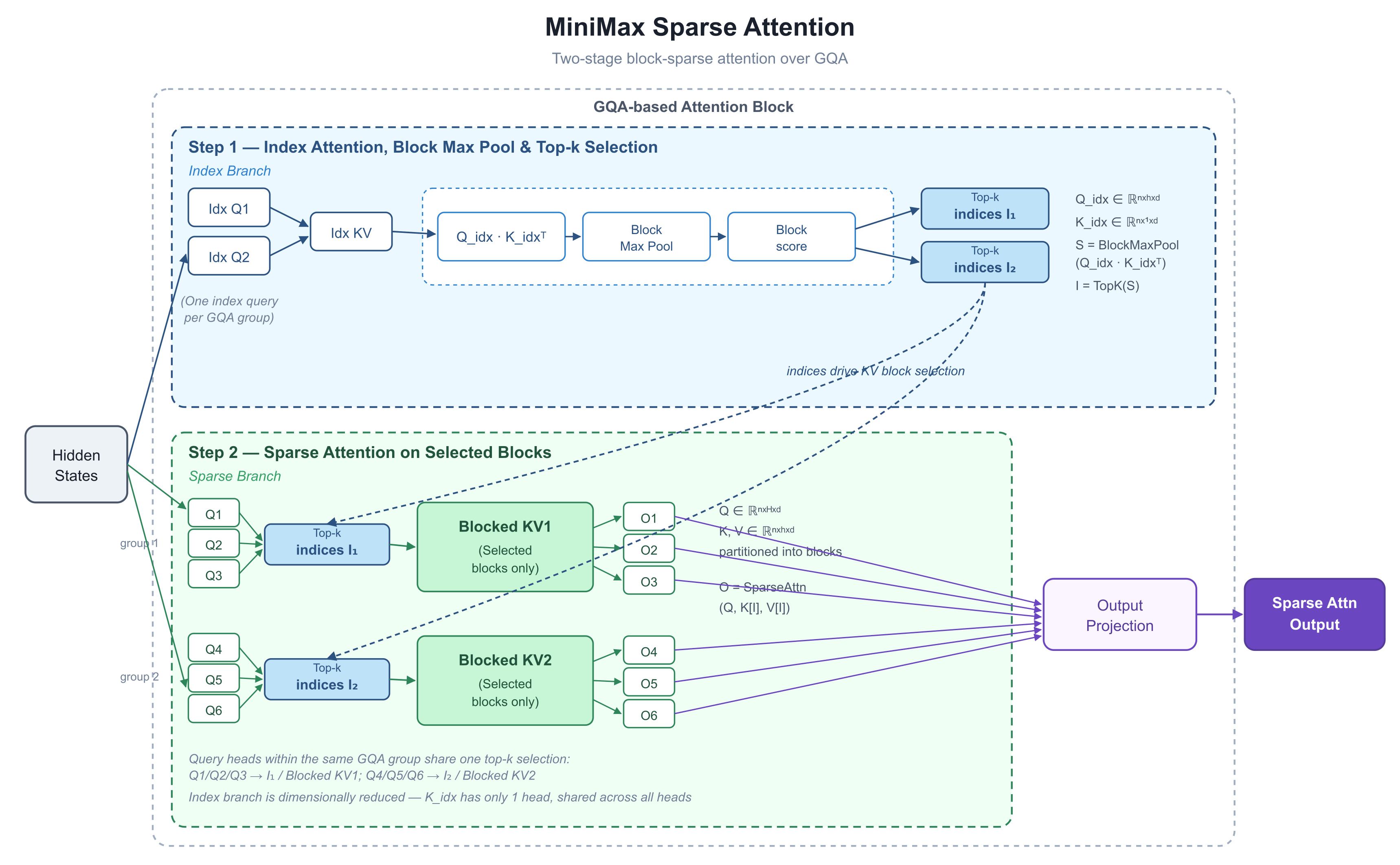
Então, como a MiniMax está conseguindo isso? Em 26 de maio, Skyler Miao, líder de P&D da MiniMax, postou um diagrama no X — paleta contida, muita informação — intitulado MiniMax Sparse Attention, com duas curvas apresentando os números que todos notaram: 9,7× mais rápido no prefill, 15,6× mais rápido na decodificação com 1 milhão de tokens. A comunidade interpretou quase unanimemente como o teaser do M3. Nós o analisamos para entender a arquitetura por trás desses números.
Um pouco de base antes da análise. Três termos explicam toda a história:
- Prefill é a etapa em que o modelo lê sua entrada de uma só vez.
- Decode é a fase mais lenta, token por token, onde o modelo escreve a saída — e em contextos longos, a decodificação é o gargalo, porque cada novo token precisa verificar tudo o que veio antes dele.
- Atenção esparsa é a solução: em vez de fazer com que cada token preste atenção a todos os outros tokens (o padrão, cujo custo cresce com o quadrado do tamanho da sequência), o modelo presta atenção a um subconjunto escolhido cuidadosamente — mantendo a maior parte da qualidade por uma fração do processamento. A forma como esse subconjunto é escolhido é onde cada laboratório se diferencia.
E a razão pela qual este teaser tem peso: em outubro, a MiniMax publicou um post intitulado Por que o M2 terminou como um modelo de atenção total? — incomumente direto, explicando que o M2 ignorou a "Lightning Attention" eficiente do M1 porque ela ainda não estava pronta para produção. Seis meses depois, o M3 surge com atenção esparsa em primeiro plano. O subtexto é uma frase: desta vez, está pronta.
1. O que o diagrama mostra: dois estágios — escolha antes de computar
O diagrama é o desdobramento interno de um único bloco de atenção. Sua principal manobra é separar "quais tokens observar" de "como computar a atenção sobre eles" em duas etapas claramente distintas.
Uma nota sobre a infraestrutura, já que é recorrente: o M3 é construído sobre GQA — Grouped-Query Attention. Em uma camada de atenção padrão, cada "cabeça de consulta" (query head) carrega seu próprio conjunto de chaves e valores, o que é expressivo, mas incha o KV cache (o cache de key/value — as chaves e valores armazenados de todos os tokens anteriores, mantidos para não serem recomputados a cada passo). A GQA divide as cabeças de consulta em grupos, e cada grupo compartilha um conjunto de chaves e valores. É o layout de economia de memória predominante usado na maioria dos modelos de produção hoje. Guarde isso — é a base de todo o design.
Passo 1: Ramo de Índice — pontue tudo de forma barata
A metade superior é o ramo de índice. Ele corre paralelamente ao caminho principal com uma tarefa: dizer ao resto do bloco quais blocos de tokens valem a pena ser observados.
Cada grupo GQA compartilha uma consulta de índice (o diagrama mostra seis cabeças reais pareadas com duas consultas de índice, "Idx Q" — uma por grupo). O lado da chave deste ramo é deliberadamente simplificado:

Observe que K_idx tem apenas uma cabeça — cada cabeça compartilha a mesma chave de índice. Isso faz com que o passo de pontuação (Q_idx · K_idxᵀ) não custe praticamente nada.
O Block Max Pool então comprime essas pontuações de nível de token em pontuações de nível de bloco (ele divide a sequência em blocos de tamanho fixo e mantém a maior pontuação em cada um):

Finalmente, o TopK — "mantenha os k itens com pontuação mais alta" — decide quais blocos KV sobrevivem para esta camada e este grupo. A saída é uma lista curta de índices: I₁, I₂.
Passo 2: Ramo Esparso — onde a atenção realmente ocorre
A metade inferior é a computação real. As consultas, chaves e valores ainda estão na forma GQA padrão. Usando I₁ e I₂ do Passo 1, o bloco extrai apenas os subconjuntos selecionados das chaves e valores totais, e executa a atenção apenas sobre eles:

A escolha de design mais importante: cada cabeça de consulta em um grupo compartilha uma única seleção top-k. No diagrama, Q1/Q2/Q3 usam I₁; Q4/Q5/Q6 usam I₂. Este é o princípio de alinhamento de hardware que o artigo da NSA da DeepSeek enfatiza — um grupo de consultas carrega um conjunto de blocos KV, esse conjunto cabe na SRAM (a memória rápida do chip da GPU) em uma única passagem, e kernels padrão no estilo FlashAttention (a implementação de atenção otimizada dominante) podem ser reutilizados sem alterações.
2. Três subtrações deliberadas em relação à família DeepSeek
A comunidade imediatamente comparou isso aos três designs de atenção esparsa da DeepSeek:
- NSA — Native Sparse Attention. "Nativo" significa que a esparsidade é treinada desde o início do pré-treinamento, não adicionada depois. Três ramos paralelos (comprimir + selecionar + janela deslizante) mais um portão (gate) aprendido.
- DSA — DeepSeek Sparse Attention. A variante implementada no DeepSeek V3.2; seleção em nível de token com um indexador muito leve.
- CSA — abreviação da comunidade para a direção em nível de bloco associada ao DeepSeek V4.
A leitura resumida da comunidade: o M3 usa GQA em vez de MLA, seleção em nível de bloco no espírito da CSA, mas computa a atenção sobre as chaves e valores reais.
Expandido em uma tabela:
| Dimensão | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (inferido) |
|---|---|---|---|---|
| Substrato KV | MLA (latente) | GQA | MLA | GQA |
| Granularidade de seleção | nível de token | nível de bloco | nível de bloco | nível de bloco |
| Ramos paralelos | 1 (indexador + select) | 3 (compress + select + sliding) | 1 | 1 (apenas select) |
| Onde ocorre a atenção | K/V reais | fusão tripla | KV comprimido | K/V reais |
| Custo do indexador | Indexador Lightning | ramo de compressão | resumos de bloco | K de cabeça única + Block Max Pool |
| Gating | nenhum | portão aprendido | nenhum | nenhum |
Essa tabela oculta um acrônimo importante: MLA — Multi-head Latent Attention, o truque característico da DeepSeek. Em vez de armazenar chaves e valores completos, o MLA os comprime em um pequeno vetor "latente" compartilhado, armazena isso e descomprime na hora. O cache KV encolhe drasticamente — mas a matemática não corresponde mais à atenção padrão, então ele precisa de kernels personalizados. Esse contraste leva à primeira das três compensações do M3.
Primeira subtração: GQA como substrato, não MLA. Como o M3 permanece no GQA simples, a stack de serviço padrão — vLLM e SGLang (os dois servidores de inferência de código aberto amplamente utilizados) mais o FlashAttention — funciona com pouca ou nenhuma modificação. Nenhuma engenharia necessária para contornar o KV latente do MLA. Para um laboratório que visa "pronto para produção", é o caminho de menor risco. Esta é a ideia mais legível para negócios em todo o design: a MiniMax otimizou para o que roda imediatamente no hardware e software que todos já possuem.
Segunda subtração: seleção em nível de bloco, mas a atenção roda sobre chaves e valores reais. Ao contrário da CSA, que computa a atenção sobre KV comprimido, o M3 mantém todo o poder expressivo da atenção softmax padrão. O custo: o cache KV não encolhe junto com a esparsificação — mas trocar um pouco de memória pela preservação da qualidade é uma barganha sensata.
Terceira subtração: os outros dois ramos da NSA sumiram. A NSA executa três caminhos paralelos (comprimir + selecionar + janela deslizante) mais um portão aprendido. O M3 mantém apenas a seleção. Um resumo da comunidade chamou de NSA simplificada e racionalizada. Em uma frase: engenharia em primeiro lugar. Dos dois ramos cortados, a janela deslizante provavelmente é substituída por RoPE (Rotary Position Embedding) mais um "attention sink", ou simplesmente pela atenção densa como um fallback por camada, da mesma forma que o Gemma 3 e o Qwen3-Next fazem. O ramo de compressão é absorvido naquele "K de cabeça única + Block Max Pool" mínimo.
3. Como ler os números
| Estágio | Aceleração @ 1M | O que significa |
|---|---|---|
| Prefill | 9,7× | Processar 1M de tokens de entrada em uma única passagem |
| Decode | 15,6× | Gerar token por token |
A decodificação superar o prefill faz sentido. Durante o prefill, o ramo de índice ainda precisa escanear o comprimento total da entrada, então a economia cai apenas na atenção principal. Durante a decodificação, cada novo token interage apenas com seus blocos KV selecionados, e a pressão de largura de banda de memória sobre o cache KV cai cerca de uma ordem de magnitude — que é exatamente onde reside o custo do tempo de decodificação.
Retrocedendo a taxa de seleção: suponha um tamanho de bloco de 64 tokens, então 1M de tokens são cerca de 16.000 blocos. Uma aceleração de 15,6× na decodificação implica que cada consulta toca apenas cerca de 6–7% dos blocos — um campo de visão efetivo em torno de 60k–70k tokens. Essa proporção fica quase exatamente na taxa de esparsidade que o artigo da NSA relata (6–10%). Não é coincidência — é o ponto ideal para esse tipo de design na escala de 1M.
4. Inferindo o resto do M3
Extrapolando deste único bloco de atenção para o modelo completo:
- A espinha dorsal MoE provavelmente permanece.MoE — Mixture of Experts — é a espinha dorsal do modelo: em vez de rotear cada token através de uma rede gigante, um roteador envia cada token para algumas sub-redes "especialistas" especializadas, para que você obtenha a qualidade de um modelo grande com o processamento ativo de um modelo pequeno. O M2 foi lançado como 230B de parâmetros totais / ~10B ativos / roteamento Top-2; o M2.7 já levou a contagem de especialistas para 256. Não há razão para o M3 abandonar isso.
- A stack de atenção total é substituída por GQA bloco-esparsa. É improvável que a Lightning Attention do M1 retorne. O M3 não está apostando novamente em atenção linear; ele está seguindo o caminho "expressividade softmax + seleção de bloco top-k" — custo sub-quadrático enquanto preserva a qualidade.
- Provavelmente esparsidade treinada nativamente. Esta é a lição central do artigo da NSA: o padrão esparso precisa entrar nos gradientes durante o pré-treinamento, ou o comportamento de recuperação do modelo será corrompido. A MiniMax tem sua própria linha de pesquisa sobre cabeças de recuperação, então eles não devem cair nessa armadilha.
- O campo de batalha é o contexto de 1M+. O M1 foi treinado em 1M e extrapolado para 4M na inferência. O M3 parece pronto para consolidar isso enquanto corta drasticamente o custo de inferência — um ritmo de produto muito natural.
5. Colocando o M3 no espaço de design de 2026
Ao longo de 2025–2026, os designs de atenção esparsa divergiram rapidamente:
- DeepSeek V3.2 DSA: MLA + top-k em nível de token, indexador muito leve; qualidade mais estável, mas engenharia de kernel pesada.
- DeepSeek NSA: GQA, três ramos + portão; teto de qualidade mais alto, mais complexo de implementar.
- Qwen3-Next: mistura por camada de atenção densa e linear; robusto, mas relativamente conservador.
- MiniMax M3: GQA + seleção de bloco de ramo único; minimalista, aproveitando o impulso do hardware.
O subtexto do design do M3 é inequívoco: não persiga a atenção teoricamente ótima — persiga aquela que roda imediatamente, roda rápido e permite que kernels existentes sejam reutilizados.
6. O que isso significa se você está construindo a próxima onda de aplicativos de IA
Afaste-se da arquitetura e há um padrão maior. Todo laboratório sério agora está lançando uma versão de atenção esparsa treinada — a DeepSeek em três linhas, a Qwen com sua mistura por camada, agora a MiniMax. A direção está definida e a consequência é direta: quando todo modelo de fronteira consegue rodar contextos longos a baixo custo, o modelo em si deixa de ser o diferencial. O custo bruto de inferência se comprime em direção a uma commodity. A diferenciação sobe um nível — para qual modelo você roda para qual workload, como você roteia entre eles e quão rápido você adota o próximo quando ele for lançado seis semanas depois.
Isso é um problema mais difícil do que "encontrar o endpoint mais barato". Uma equipe rodando um aplicativo de produção está equilibrando quatro coisas ao mesmo tempo — qualidade, latência, custo e o resultado de negócios — e a resposta certa difere por workload e muda a cada ciclo de lançamento.
Escolher o modelo mais barato não é mais uma estratégia vencedora. Em vez disso, serão os construtores que criaram uma camada que permite escolher, rotear e trocar modelos sem ter que reintegrar tudo a cada movimento da fronteira — e que gastam seu orçamento de engenharia no próprio produto em vez de perseguir notas de lançamento a cada poucas semanas.
É nessa camada que o Atlas Cloud opera: uma API em mais de 300 modelos abrangendo LLM, vídeo, imagem e áudio, com roteamento inteligente e acesso no dia do lançamento a novas tecnologias. O M3 ainda não é público — quando for, esperamos trazê-lo para o Atlas com acesso imediato, para que as equipes que já estão construindo conosco possam colocá-lo diante de seus usuários no dia em que for lançado.
Considerações Finais
Muita coisa não pode ser confirmada a partir de um único diagrama: se o padrão esparso é misturado camada por camada, se há um fallback denso, se o ramo de índice compartilha embeddings com a rede principal, como a perda do ramo de índice é formulada. Tudo isso aguarda o artigo oficial ou os pesos.
Mas uma coisa já está definida: seguindo a DeepSeek, outro grande laboratório montou uma stack funcional de atenção esparsa + contexto longo + pesos abertos. No segundo semestre de 2026, 1M de contexto em código aberto provavelmente deixará de ser um diferencial de venda para se tornar uma linha de base — e isso, por si só, importa mais do que qualquer benchmark isolado.
Referências
- Skyler Miao (Líder de P&D da MiniMax), post original no X: Something BIG is coming — https://x.com/SkylerMiao7/status/2059285750458544561
- Resumo da comunidade: MiniMax details its M3 sparse attention architecture — https://digg.com/ai/78gnmbpg
- Blog da MiniMax: Why Did M2 End Up as a Full Attention Model? — https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model
- Artigo da DeepSeek sobre NSA: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention — https://arxiv.org/pdf/2502.11089
- Artigo sobre DeepSeek V3.2 DSA: Architectural Efficiency in LLMs: DeepSeek-V3.2-Exp and DSA — https://gregrobison.medium.com/architectural-efficiency-in-large-language-models-a-comprehensive-analysis-of-deepseek-v3-2-exp-e9802adfcdbd
- Sebastian Raschka: A Technical Tour of the DeepSeek Models from V3 to V3.2 — https://magazine.sebastianraschka.com/p/technical-deepseek
- Relatório técnico MiniMax-01: Scaling Foundation Models with Lightning Attention — https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf






