
Google Nano Banana 2 Lite (conhecido pelo endpoint da API gemini-3.1-flash-lite-image) é uma ferramenta de IA pequena e rápida, desenvolvida para configurações ágeis de aplicativos. É a API de imagem do Google mais acessível disponível atualmente. Ela converte texto em imagens em apenas 4 segundos, sendo perfeita para grandes aplicativos empresariais que precisam de um volume massivo de imagens de forma veloz.

Esperar que centenas de filas de geração automática de imagens sejam processadas é um gargalo exaustivo para desenvolvedores que criam aplicativos de alta concorrência. Quando sua plataforma precisa renderizar dinamicamente milhares de variações de anúncios localizados, avatares de usuários ou mockups web rápidos, depender de modelos criativos premium aumenta rapidamente os custos de produção e prejudica a experiência do usuário. A alta latência e as taxas elevadas por imagem muitas vezes obrigam as equipes de desenvolvimento a escolher entre a velocidade do aplicativo e o orçamento operacional mensal.
O Google resolve esse atrito com a mais recente adição à sua linha de modelos criativos. Ao separar os níveis de desempenho com base nas demandas explícitas de carga de trabalho, os desenvolvedores agora podem otimizar pipelines de ativos de alta velocidade sem pagar caro por recursos de renderização desnecessários. A solução reside em um modelo de geração de imagem especializado e leve, projetado diretamente para implementação programática rápida.
Atendendo à demanda pela API de imagem mais barata do Google
Para equipes de engenharia que executam fluxos de trabalho visuais de alto volume, as APIs de geração de imagem tradicionais apresentam um grande desafio financeiro. Pagar vários centavos por imagem torna-se insustentável ao escalar para milhões de chamadas de API automatizadas. Esse obstáculo econômico intensificou a demanda por uma API de imagem do Google verdadeiramente barata, capaz de lidar com solicitações em massa sem introduzir um imenso custo de infraestrutura.
O lançamento do modelo gemini-3.1-flash-lite-image altera a arquitetura da geração programática de imagens ao mudar a base econômica. Em vez de tratar cada solicitação visual como um ativo artístico premium, essa arquitetura trata a geração de imagens de alta velocidade como um utilitário básico. Isso permite que engenheiros de software integrem a criação de imagens fluida e em tempo real diretamente em aplicativos multi-inquilinos (multi-tenant) e softwares sociais interativos, onde a eficiência de custos é a principal métrica operacional.
Análise profunda dos benchmarks de desempenho do Nano Banana 2 Lite
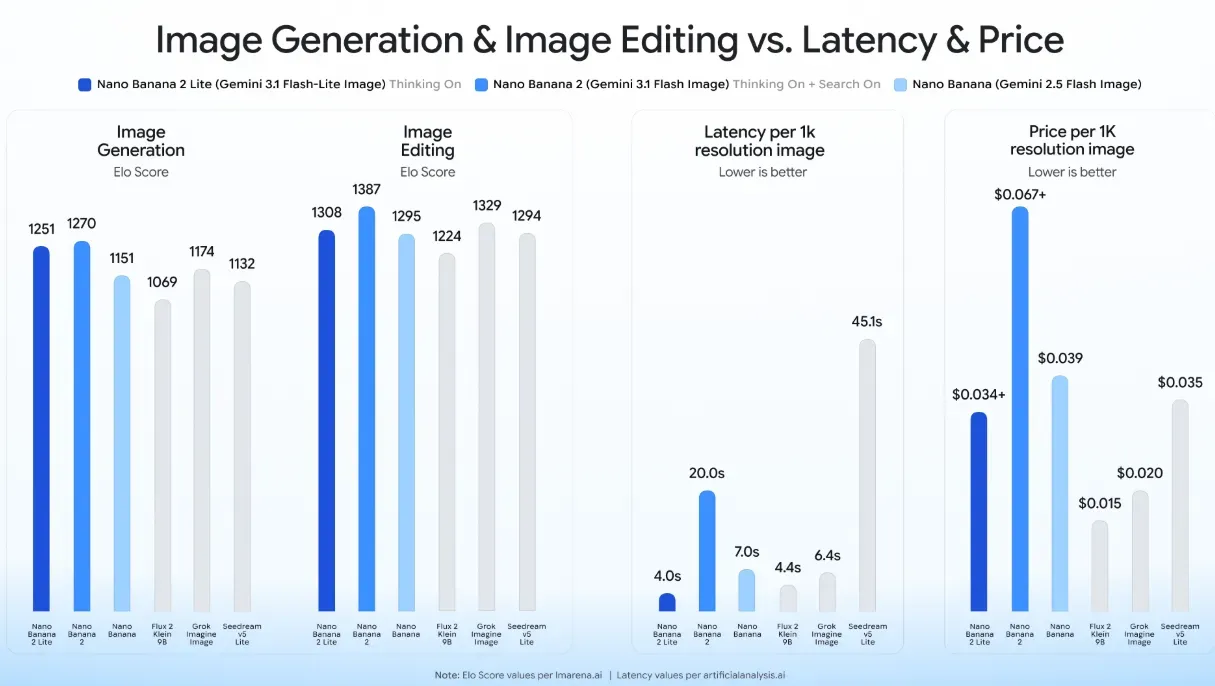
A designação comercial para este nível de modelo focado em eficiência é Nano Banana 2 Lite. Este modelo foi projetado com foco rigoroso na maximização do throughput de processamento e na minimização do overhead de resposta. Testes reais e especificações oficiais confirmam que o modelo atinge uma latência de geração de texto para imagem de apenas 4 segundos. Essa rapidez representa uma velocidade aproximadamente 5x maior do que os níveis de modelo padrão, transformando o fluxo de trabalho do desenvolvedor de uma operação assíncrona baseada em fila para uma experiência de usuário síncrona e quase em tempo real.
Métricas de desempenho do Nano Banana 2 Lite
| Dimensão de Parâmetros | Especificação Oficial / Métrica | Notas e Paradigma Operacional |
| Modalidades Suportadas | Entrada: Texto, Imagem, Vídeo; Saída: Texto, Imagem | Áudio não é suportado; Vídeo é apenas entrada. |
| Limites da Janela de Contexto | Entrada máx: 65.536 tokens; Saída máx: 4.096 tokens | Otimizado para lógica de aplicação de alta frequência e rápida. |
| Capacidades Principais | Geração de imagem, imagens/texto intercalados, edição de imagens, edição de imagem em vários turnos | Geração de imagem a partir de entrada de vídeo não é suportada. |
| Resolução de Saída | Estritamente 1K (Aproximadamente 1 Megapixel) | Consome exatamente 1.120 tokens de imagem de saída por geração 1K. |
| Proporções Suportadas | 1:1, 1:4, 4:1, 1:8, 8:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9 | Cobre perfeitamente layouts de e-commerce, redes sociais e banners padrão. |
| Restrições por Prompt | Entrada máx: 14 imagens por prompt; Saída máx: Limitada a 32.768 tokens de saída | A contagem de arquivos é limitada pela janela de contexto de 65.536 tokens. |
| Custo de Token Multimodal | Imagem de entrada: 1.120 tokens/imagem; Vídeo de entrada: 70 tokens/segundo (amostrado a 1 fps) | Cobranças adicionais se aplicam para modalidades de entrada e saída de texto. |
| Salvaguardas de Concorrência | Provisioned Throughput (Throughput Provisionado) é suportado | Crucial para plataformas empresariais garantirem latência de 4 segundos sob carga máxima. |
Os ganhos de desempenho do Nano Banana 2 Lite em relação aos modelos legados baseiam-se em atualizações arquitetônicas substanciais. Quando comparado ao modelo mais antigo gemini-2.5-flash-image, a nova variante Lite oferece avanços técnicos específicos:
- Integração de Conhecimento Global: O modelo exibe uma compreensão contextual altamente precisa de locais, estruturas físicas e layouts espaciais abstratos, tornando-o altamente eficaz para wireframing de UI/UX rápido.
- Consistência de Personagem: Mantém identidades de personagens e detalhes estruturais de objetos estáveis em gerações sequenciais. Isso permite que engenheiros construam softwares de storyboard iterativos ou recursos de provador virtual programático para plataformas de e-commerce.
- Tipografia e Localização em Linha: O sistema renderiza texto legível e limpo diretamente nos gráficos gerados. Isso permite que desenvolvedores construam variantes de anúncios automatizadas e personalizadas para diferentes mercados geográficos instantaneamente.
Decodificando preços e mecânica de tokens da API Nano Banana 2 Lite
| Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Preço Padrão (/1M tokens) <= 200K tokens de entrada |
| Entrada (texto, imagem, vídeo) | USD0.25 |
| Saída de texto (resposta e raciocínio) | USD1.50 |
| Saída de Imagem | USD30 |
Entender seus custos operacionais exige um olhar atento sobre a estrutura de tokens subjacente, em vez de depender de médias de marketing genéricas. Embora a promoção padrão do setor liste uma taxa fixa de aproximadamente USD0.034 por 1.000 imagens, a estrutura real de cobrança do Google baseia-se em uma infraestrutura precisa de tokens multimodais. As taxas específicas do nível pago para desenvolvedores do preço da API Nano Banana 2 Lite são divididas em diferentes mecânicas de transação.
No uso padrão do nível pago via Google AI Studio ou Gemini Enterprise Agent Platform, entradas de texto, imagem ou vídeo custam exatamente USD0.25 por 1 milhão de tokens. Tokens de saída de texto e raciocínio estrutural são cobrados a USD1.50 por 1 milhão de tokens. Ao gerar uma imagem de resolução 1K padrão (~1 megapixel), o sistema processa um payload de saída fixo equivalente a USD30.00 por 1 milhão de tokens de imagem de saída. Isso mapeia diretamente para um custo exato por imagem de USD0.0336.
Além disso, engenheiros podem implementar otimizações orçamentárias massivas utilizando a execução em lote (batch) assíncrona. O Google oferece um desconto fixo de 50% para solicitações não urgentes e processadas em lote dentro de uma janela de 24 horas. Isso reduz o custo de uma imagem de resolução 1K para impressionantes USD0.0168, tornando-a a escolha definitiva para a geração de ativos de segundo plano.
Comparação arquitetônica lado a lado: Família de modelos criativos do Google
Para selecionar o modelo mais eficiente para seu stack de produção, é útil contrastar as estruturas de desempenho e custo de toda a linha de imagens criativas do Google. Cada variante de modelo visa um limite operacional diferente, exigindo que os desenvolvedores correspondam aos requisitos específicos de seus aplicativos ao endpoint de API adequado.
| Métrica / Recurso | Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Gemini 3.1 Flash Image (Nano Banana 2) | Gemini 3 Pro Image (Nano Banana Pro) |
| ID do Modelo da API | gemini-3.1-flash-lite-image | gemini-3.1-flash-image | gemini-3-pro-image |
| Preço do Token de Entrada | USD0.25 / 1M tokens | USD0.50 / 1M tokens | USD2.00 / 1M tokens |
| Preço do Token de Imagem de Saída | USD30.00 / 1M tokens | USD60.00 / 1M tokens | USD120.00 / 1M tokens |
| Custo de Imagem 1K Padrão | USD0.03 | USD0.07 | USD0.13 |
| Custo de Imagem 1K em Lote | USD0.02 | Não disponível | Não disponível |
| Latência Média | ~4 segundos | ~6–8 segundos | ~10–12 segundos |
| Maior Desvantagem | Limite rígido de resolução 1K; dificuldade com parágrafos de texto densos. | Falta de descontos em batch para operações pesadas. | Alta latência e custos elevados limitam uso em loops de alta concorrência. |
| Melhor Caso de Uso | Pipelines de alto volume, interações em tempo real, banners localizados. | Aplicações de nível intermediário que exigem edição profunda de imagens. | Criação de ativos cinematográficos, design gráfico complexo, fidelidade de texto. |
Script de integração rápida do SDK para gemini-3.1-flash-lite-image
A integração da geração de imagens do Google AI Studio em um pipeline de aplicativo existente pode ser feita diretamente por meio do SDK nativo Google GenAI. O bloco de código abaixo demonstra como inicializar o cliente, configurar parâmetros programáticos e executar com segurança uma solicitação assíncrona de texto para imagem direcionada ao endpoint gemini-3.1-flash-lite-image.
Python
python1import os 2from google import genai 3from google.genai import types 4 5def generate_bulk_asset(prompt_text: str, output_path: str): 6 """ 7 Inicializa o cliente Google GenAI e executa uma solicitação de geração 8 texto-para-imagem de baixa latência usando o modelo otimizado gemini-3.1-flash-lite-image. 9 """ 10 # Inicializa o cliente; espera que a variável de ambiente GEMINI_API_KEY esteja definida 11 client = genai.Client() 12 13 print(f"Enviando solicitação de geração para o modelo: gemini-3.1-flash-lite-image") 14 15 try: 16 response = client.models.generate_images( 17 model='gemini-3.1-flash-lite-image', 18 prompt=prompt_text, 19 config=types.GenerateImagesConfig( 20 number_of_images=1, 21 output_mime_type="image/jpeg", 22 aspect_ratio="1:1", # Aceita proporções padrão como 1:1, 16:9, 4:3 23 person_generation="ALLOW_ADULT" 24 ) 25 ) 26 27 # Processa e salva o payload da imagem gerada 28 for i, generated_image in enumerate(response.generated_images): 29 image_bytes = generated_image.image.image_bytes 30 full_path = f"{output_path}_asset_{i}.jpg" 31 with open(full_path, "wb") as f: 32 f.write(image_bytes) 33 print(f"Ativo de imagem 1K salvo com sucesso em {full_path}") 34 35 except Exception as e: 36 print(f"Execução da API falhou: {str(e)}") 37 38if __name__ == "__main__": 39 prompt = "Um mockup profissional de produto de um robô companheiro de mesa em uma mesa de escritório, iluminação limpa" 40 generate_bulk_asset(prompt, "output_production")
Ao implantar este script em escala, as camadas de segurança e conformidade são tratadas automaticamente pela infraestrutura. O Google incorpora marcas d'água SynthID imperceptíveis e credenciais de conteúdo C2PA estruturais diretamente nos metadados de cada imagem de saída por padrão. Isso garante que todos os ativos programáticos gerados através do seu pipeline permaneçam completamente rastreáveis e em conformidade corporativa, sem exigir scripts de pós-processamento personalizados.
Preparando seu stack de produção para o futuro com camadas de API unificadas
Embora chamar o SDK nativo do Google funcione perfeitamente para ambientes isolados, escalar esse fluxo de trabalho de texto para imagem em aplicativos empresariais multi-inquilinos geralmente exige uma camada de gerenciamento de API unificada.
Plataformas de infraestrutura e orquestração como a Atlas Cloud descentralizaram oficialmente esse pipeline, fornecendo caminhos de integração prontos para produção para esta variante de modelo específica. Por meio do hub Atlas Cloud Nano Banana 2 Lite text to image/edit model, os desenvolvedores agora podem rotear seus fluxos de trabalho visuais de alta velocidade diretamente através de uma infraestrutura de API unificada.
Conectar-se por meio de um hub como o Atlas Cloud permite que sua equipe de desenvolvimento combine a ferramenta de vídeo rápida de 4 segundos deste modelo com opções de backup de outros modelos. Ele também oferece um local centralizado para estatísticas de uso e cobrança simples. Isso significa que você não precisa adicionar código extra complexo aos seus servidores principais.
Solução de problemas: códigos de erro da API e limites de taxa
Você certamente encontrará limitações de servidor ou cliente se expandir seu aplicativo para lidar com dezenas de milhares de requisições de imagem de uma só vez. Lidar com esses engarrafamentos de tráfego de forma suave evita que seu aplicativo trave e mantém o funcionamento rápido para os usuários.
Lidando com 429 Too Many Requests
O erro mais frequente durante execuções ocupadas de aplicativos é a mensagem 429 Too Many Requests. Isso significa que seu aplicativo excedeu os limites de velocidade compartilhados concedidos às contas de desenvolvedor comuns do Google AI Studio. Para resolver isso, os desenvolvedores devem criar um algoritmo de retrocesso exponencial (exponential backoff) com jitter em seus loops de solicitação, atrasando chamadas de API subsequentes quando um status 429 é capturado. Para operações empresariais que exigem capacidade garantida, os engenheiros podem migrar para arranjos de Throughput Provisionado dentro da Gemini Enterprise Agent Platform, que reserva alocação de hardware dedicada para garantir throughput consistente.
Resolvendo erros 400 Invalid Argument e 403 Forbidden
Um erro 400 Invalid Argument geralmente significa que suas configurações de vídeo têm tamanhos incorretos ou proporções ruins. O plano Lite é muito rigoroso e só permite saídas de vídeo 1K. Certifique-se de que sua proporção corresponda a tamanhos regulares como 1:1 ou 16:9.
Por outro lado, um erro 403 Forbidden significa que há um problema com a chave da API ou um bloqueio de segurança. O Google usa filtros automáticos para verificar todo o texto. Se o seu prompt violar essas regras de segurança, o sistema bloqueará o vídeo. Você precisará reescrever o texto para seguir as diretrizes da plataforma.
Realidades do desenvolvedor: integrando fluxos de trabalho de imagem de baixo custo nativamente
Implantar um modelo otimizado para orçamento significa reconhecer suas limitações práticas. Como a arquitetura do modelo é ajustada para velocidade excepcional e baixo custo, ela faz trocas explícitas:
- O teto rígido de resolução 1K significa que ele não pode produzir gráficos nativos 4K prontos para impressão.
- Além disso, ao ser encarregado de prompts altamente complexos contendo camadas estruturais densas, o modelo pode ocasionalmente apresentar oscilações de consistência de personagem em transições de cena amplamente diferentes.
Para mitigar essas desvantagens sem inflar seus custos operacionais, você pode encadear seu pipeline de geração em um fluxo de trabalho de edição de vários turnos.
Em vez de tentar gerar uma cena altamente complexa e perfeita na primeira tentativa, escreva a lógica do seu aplicativo para gerar um rascunho base rápido de 4 segundos. A partir daí, use solicitações de edição de imagem conversacional para modificar, reluzir ou trocar objetos específicos dentro do ativo programaticamente.
Para aplicativos multimídia avançados, essa saída de imagem 1K pode ser alimentada diretamente em pipelines de geração de vídeo como o Gemini Omni Flash, que processa tarefas de edição de vídeo a uma taxa acessível de USD0.10 por segundo.
O Nano Banana 2 Lite é adequado para o seu stack?
Para simplificar sua avaliação arquitetônica, aqui está uma análise de quais equipes de desenvolvimento obterão o maior ROI do Nano Banana 2 Lite (gemini-3.1-flash-lite-image) e quem deve procurar os níveis premium padrão.
Para quem este modelo é ideal?
- Desenvolvedores de aplicativos de alta concorrência: Se seu software lida com milhares de solicitações de API automatizadas por minuto, como criadores de avatares de usuários em tempo real, geradores instantâneos de anúncios dinâmicos ou sistemas de posicionamento de produtos em e-commerce em massa — este modelo foi criado especificamente para seus requisitos de carga.
- Engenheiros de software sensíveis a custos: Equipes que visam fluxos de trabalho com micro-orçamento, onde manter as despesas operacionais baixas é uma métrica de sobrevivência importante. Aproveitar seu nível de lote de USD0.0168 elimina efetivamente o gargalo fiscal premium padrão.
- Arquitetos de aplicativos interativos: Produtos que exigem um loop síncrono rigoroso, onde os usuários exigem um feedback quase em tempo real, se beneficiarão imensamente de sua velocidade de geração inferior a 4 segundos.
Quem deve evitar este modelo?
- Designers gráficos de alta fidelidade: Se seu aplicativo depende da renderização de gráficos de impressão em larga escala, banners de resolução 4K nativos ou materiais de marketing cinematográficos complexos, o limite de resolução 1K rígido limitará sua saída criativa.
- Profissionais de marketing visual focados em texto: Embora o modelo suporte tipografia em linha, aplicativos que exigem parágrafos densos e hipercomplexos de texto de layout incorporados nativamente em imagens devem utilizar o nível Gemini 3 Pro Image em vez disso, para manter a fidelidade absoluta do texto.
- Construtores de multimídia focados em áudio: Equipes que constroem loops multimodais avançados que dependem fortemente de sincronização de áudio ou geração de imagens diretamente a partir de fluxos de áudio ao vivo contínuos devem procurar outro lugar, pois o áudio não é estritamente suportado por este nível Lite específico.
FAQ
Como o gemini-3.1-flash-lite-image reduz os custos do desenvolvedor em comparação com os níveis padrão?
O modelo corta os custos padrão do desenvolvedor em exatamente 50% em comparação com o modelo gemini-3.1-flash-image padrão. Ao otimizar a pegada de tokens para USD0.25 por 1 milhão de tokens de entrada e USD30.00 por 1 milhão de tokens de imagem de saída, o preço de uma imagem de resolução 1K padrão cai para USD0.0336 sob os níveis pagos padrão. Para tarefas de segundo plano não urgentes, utilizar a API de lote reduz essa taxa para USD0.0168 por imagem.
O Nano Banana 2 Lite pode lidar com cargas de aplicativos corporativos de alta concorrência?
Sim, o modelo foi construído especificamente para atender às demandas corporativas de alta concorrência. Embora os níveis de desenvolvedor padrão compartilhem um pool de infraestrutura comum, as equipes corporativas podem garantir um desempenho dedicado e altamente confiável implantando o throughput provisionado via Gemini Enterprise Agent Platform. Isso ignora completamente os limites de taxa compartilhados padrão e garante uma velocidade de geração estável de 4 segundos durante janelas de tráfego de pico.
A API de imagem mais barata do Google compromete a segurança ou o rastreamento de conteúdo?
A otimização de custos não remove recursos de segurança corporativa ou mecanismos de conformidade. Cada imagem gerada pelo modelo inclui automaticamente uma marca d'água SynthID nativa incorporada diretamente na matriz de pixels, juntamente com as credenciais de conteúdo C2PA padrão. Esses metadados permitem que as plataformas corporativas mantenham o rastreamento transparente e verifiquem completamente a autenticidade de todos os ativos gerados por IA antes que cheguem a aplicativos voltados para o público.






