Resumo
Em meados de maio de 2026, o Qwen3.7-Max e o Qwen3.7-Plus apareceram silenciosamente no LM Arena. @Alibaba_Qwen definiu as expectativas da comunidade com a frase "Alibaba #6 em Texto, #5 em Visão". Em 2 de junho, a equipe Alibaba Cloud Tongyi Qianwen lançou oficialmente este modelo de agente multimodal. Ele já está disponível no Alibaba Cloud Model Studio e no Qwen Chat, com acesso via API sob alibaba/qwen3.7-plus e um preço de tabela de cerca de USD 0,40 / USD 1,60 por milhão de tokens de entrada/saída.
O posicionamento oficial é claro: Plus é o modelo multimodal com melhor custo-benefício; Max é o carro-chefe para texto.
Passamos uma tarde executando uma bateria de testes rigorosos no Qwen3.6-plus, Qwen3.7-plus e Qwen3.7-Max: reparo automático de 10 bugs reais, 15 problemas do concurso de matemática AIME 2025, além de uma comparação mais ampla de multimodalidade, velocidade e custo.
Os resultados devem ser interpretados como 5 observações de nível de tarefa, não como um ranking geral de modelos:
- BugFind-10 (execução única): O Plus passou em todos os testes externos pytest. Sob este conjunto de 10 tarefas, o scaffold oficial Stirrup e a configuração de execução única, o Plus marcou 10/10, enquanto o Max e o 3.6-Plus marcaram 9/10. Isso indica a adequação à tarefa neste cenário; não deve ser extrapolado para um ranking geral de codificação.
- Matemática: O Plus, com o "thinking" ativado, atingiu a mesma pontuação de execução única que o Max. Em 15 problemas de matemática de competição, o Plus e o Max responderam 14 corretamente; nesta execução, o Qwen3.7-plus levou muito menos tempo do que o Qwen3.7-Max (113s vs 303s por problema).
- Um salto geracional de velocidade: Em tarefas de agente, o throughput de ponta a ponta para o Qwen3.7-plus atingiu 147,5 t/s, enquanto o Qwen3.6-plus atingiu apenas 41,5 t/s, uma melhoria de 3,55x. Tarefas matemáticas que a geração anterior não conseguia finalizar tornaram-se fáceis de concluir.
- A multimodalidade ainda apresenta falhas: Em nossos testes multimodais controlados, o Qwen3.7-plus respondeu corretamente a perguntas simples sobre imagens, mas a imagem de exemplo oficial
dog_and_girl.jpegfoi descrita como "um trem e uma multidão". - Algumas capacidades ficaram próximas do Max, com vantagem de latência: Em vários testes nesta execução, o Qwen3.7-plus atingiu resultados próximos ao Qwen3.7-Max, exibindo menor latência. Isso não é uma afirmação de ranking geral.
Abaixo estão os dados completos dos testes, a metodologia e as recomendações de seleção de modelos para líderes de engenharia. Todas as comparações estão limitadas a esta pequena amostra, execução única e scaffold fixo.
0. Contexto de Capacidade do Modelo e Leaderboard
A linha de produtos Alibaba Qwen já havia se consolidado em um padrão na geração 3.6: Max = carro-chefe de texto, Plus = modelo multimodal de contexto longo. A versão 3.7 continua essa lógica:
| Dimensão | Qwen3.7-Max | Qwen3.7-Plus |
|---|---|---|
| Modalidades de entrada | Primariamente texto | Texto + imagem |
| Ponto de venda típico | Teto de raciocínio, agentes de longo prazo | 1M de contexto, visão, raciocínio híbrido, menor preço unitário |
| Arena (2026-05) | Cerca de #13 no ranking geral de texto | Cerca de #16 em visão |
| Preço de gateway (01-06) | USD 1,25 / USD 3,75 por M | USD 0,40 / USD 1,60 por M |
1. Como a narrativa oficial posiciona o Plus?
O post de lançamento do Alibaba Qwen reduz a mensagem a uma frase:
"Um modelo. Vê, pensa, codifica, age."
Os principais pontos de venda são: um agente híbrido interativo multimodal com operação unificada de GUI e CLI, um agente de codificação versátil e generalização entre frameworks de agentes. O desenvolvedor central do Qwen, shuai bai_, explicou melhor:
Nosso objetivo é transformar a IA multimodal de uma ferramenta passiva de legendagem de imagens em um resolvedor de problemas ativo: um que pode ver, raciocinar, escrever código, operar interfaces e verificar resultados. É um passo em direção a uma inteligência multimodal verdadeiramente agente.
Os posts de desempenho do tópico oficial dão o posicionamento chave:
- O desempenho de texto é "próximo ao nível do Max" (afirmação do fornecedor)
- Melhorias multimodais focam em capacidades centrais de agente: compreensão visual complexa, raciocínio visual, uso de ferramentas e execução de código/GUI
| Alegação comum no X | Fonte | Nosso resultado | Conclusão |
|---|---|---|---|
| Texto do Plus é "próximo ao Max" | Oficial | AIME com thinking: mesma pontuação, 14/15; Plus foi 2,68x mais rápido | Mesma pontuação de matemática em execução única; latência menor nesta execução |
| Max é melhor para código / trabalho de longo prazo | Documentação Vercel | BugFind: Plus 10/10, Max 9/10; Plus 147,5 t/s | Esta tarefa não suporta aplicar essa suposição cegamente |
| O ranking de visão é forte | Arena | Exemplo oficial de imagem falhou; imagem controlada ✓ | Um alto score de leaderboard e uma falha em imagem única podem coexistir |
2. Nosso método de avaliação: Quatro tipos de tarefas e uma regra rígida
Para manter o teste justo, mantemos um conjunto chamado BugFind-10: 10 bugs do mundo real cobrindo cálculo de preços, limites de array, manipulação de caminhos, concorrência, JSON, SQL, comportamento de cache, Unicode, configuração e muito mais. Cada bug vem com testes pytest. O modelo deve executar dentro do framework de agentes Stirrup oficial com ferramentas locais de execução de código e completar o ciclo completo sozinho: "reproduzir → localizar → editar código de produção → executar testes".
Por que construir nosso próprio conjunto de testes?
Leaderboards públicos têm três modos comuns de falha:
- Memorização e vazamento: modelos carro-chefe já estão saturados em problemas antigos. Selecionamos a AIME 2025, um concurso publicado após os prováveis pontos de corte de treinamento dos modelos.
- Autorrelatos de fornecedores podem divergir de retestes independentes: a mesma métrica pode mudar significativamente dependendo da versão do dataset, se o "thinking" está ativado e se ferramentas são permitidas.
- Benchmarks de agentes dependem de scaffolding: diferentes frameworks de agentes podem alterar pontuações em 2-3 pontos percentuais. Fixamos o framework no Stirrup oficial e adicionamos verificação externa.
As quatro tarefas de teste
| Tarefa | O que mede | Métrica central |
|---|---|---|
| Verificação de acesso | Confirmação de identidade, suporte a thinking, capacidade visual | Passar / falhar |
| BugFind-10 | Reparo automático de 10 bugs de código reais | Taxa de aprovação em pytest externo, contagem de chamadas, tempo de relógio |
| AIME 2025 I | 15 problemas de matemática de competição | Precisão, tempo por problema, ablação de thinking |
| Quick Eval | 8 problemas de matemática do ensino fundamental | Linha de base de velocidade, TTFT, benefício do thinking em tarefas simples |
Nossa regra rígida: Pontuações de código só contam sob Pytest externo
Este é o fundamento de toda a revisão. Também aborda diretamente a preocupação do Hacker News de que um agente dizendo "testes passaram" não é suficiente.
Processo:
- O agente edita o código no workspace, executa o pytest sozinho e escreve um CHANGELOG.
- Copiamos o código de produção modificado para um ambiente isolado e executamos o pytest de forma independente.
- Publicamos apenas o código de saída e a pilha de falhas da etapa 2.
Uma analogia: o agente é o aluno que faz o exame. Não apenas lemos a resposta que ele entrega; levamos a resposta para outra sala e corrigimos novamente, para não confiar cegamente em sua crença de que obteve sucesso.
3. Capacidade de código e agente
Visão geral dos três modelos
| Modelo | Resultado pytest | Taxa de reparo | Chamadas LLM | Tempo de relógio | T/s ponta a ponta |
|---|---|---|---|---|---|
| Qwen3.6-Plus | 1 falhou, 26 passou | 9/10 | 63 | 334s | 41,5 |
| Qwen3.7-Plus | 27 passou | 10/10 | 52 | 205s | 147,5 |
| Qwen3.7-Max | 1 falhou, 26 passou | 9/10 | 20 | 249s | 51,8 |
O fato de o Plus ter obtido o melhor resultado de execução única no BugFind foi inesperado:
- O Plus foi a única execução 10/10 neste teste.
- O Max usou o menor número de chamadas, mas não obteve nota máxima. O 3.7-Max parou após apenas 20 chamadas de modelo, o menor entre os três. Ele tendia a "pensar por muito tempo e fazer uma grande alteração", com menos iterações. Em contraste, o 3.7-Plus usou 52 chamadas e estava disposto a editar, executar, inspecionar o feedback e editar novamente.
- O Plus teve o menor tempo de relógio e o maior throughput. Para a experiência de agente em IDE, isso importa muito mais do que alguns pontos de Elo em um leaderboard.
Uma tarefa, três filosofias de reparo: Mergulho profundo na tarefa05
Esta tarefa testa a regra de que JSON inválido não deve ser ignorado silenciosamente. Quando o parser vê dados ruins, ele não deve fingir sucesso e retornar um objeto vazio; ele deve relatar o erro claramente. O bug original:
plaintext1def safe_parse(data: str): 2 try: 3 return json.loads(data) 4 except Exception: 5 return {} # Bug: ignora a exceção
Os testes exigem:
- Para entrada como "isso não é json {", a função não deve retornar um dict vazio {}.
- Para entrada inválida sem chaves, como "bad", deve levantar uma exceção.
Abordagem do Max (teste externo ✗): levantar um JSONParseError personalizado.
Isso parece uma solução limpa, mas para "isso não é json {" ele levantou imediatamente, então o teste falhou antes mesmo de a primeira asserção ser executada. No entanto, o CHANGELOG do Max disse confiantemente "27 passaram". É exatamente por isso que a verificação externa é obrigatória: a autoavaliação de um agente e uma auditoria externa frequentemente divergem.
3.6-Plus (externo ✗): falhou no mesmo primeiro obstáculo.
3.7-Plus (externo ✓):
plaintext1if re.search(r'[\{\[\]\}]', data): 2 return {"error": str(e), "raw": data} 3raise ValueError(f"Invalid JSON: {e}") from e
Para entrada malformada contendo chaves, ele retorna um objeto de erro que é distinguível de {}. Para entrada sem chaves, ele levanta uma exceção. Ele acertou ambos os lados do contrato de teste precisamente.
Por que o Max não obteve nota máxima nesta tarefa? Comece com a contagem de chamadas:

O 3.7-Max parou após apenas 20 chamadas de modelo. Ele tendia a "pensar por muito tempo e fazer uma grande alteração", com menos iteração. O 3.7-Plus usou 52 chamadas e estava disposto a editar, executar, inspecionar feedback e editar novamente. Em tarefas de codificação de agente que exigem interação repetida com o ambiente, mais iteração pode ajudar a cobrir casos de borda que o Max perdeu nesta execução. Isso aponta para um fato frequentemente ignorado: em tarefas de agente, "raciocínio mais profundo" não significa necessariamente uma entrega mais estável. Usar bem o feedback da ferramenta é tão importante quanto.
Na qualidade de reparo, todos os três modelos se saíram bem na tarefa03. Esta tarefa concatena diretamente user_id em um caminho de arquivo, então ".." pode criar travessia de caminho e "user;rm -rf" pode carregar metacaracteres de shell. O reparo adicionou um saneador de whitelist, identificando um defeito de segurança real em vez de corrigir cegamente para testes verdes:
plaintext1user_id = re.sub(r'[^a-zA-Z0-9_-]', '', user_id) or "unknown"
Conclusões de engenharia:
- Para tarefas de agente, a disposição para lidar com o ambiente (o Plus teve 52 turnos de diálogo e 98 execuções de código) importa mais do que a iteração mínima.
- O Max parou após 20 turnos e acreditou prematuramente que a tarefa05 estava resolvida.
- Na correção de bugs interativa, uma solução limpa de "levantar uma exceção" nem sempre é mais útil do que retornar dados sujos de uma forma distinguível.
4. Raciocínio e Matemática: O modo Thinking é uma decisão de custo
A série Qwen3.7 enfatiza o "raciocínio híbrido", controlado através da chave enable_thinking. Vale a pena ativar esta chave? Executamos uma ablação em dois grupos de tarefas com dificuldades muito diferentes. O conjunto difícil foi AIME 2025 I, um concurso publicado após os prováveis pontos de corte de treinamento, sendo mais resistente à contaminação. Verificamos cada problema e resposta contra duas fontes independentes, AoPS e Areteem, e então avaliamos automaticamente.
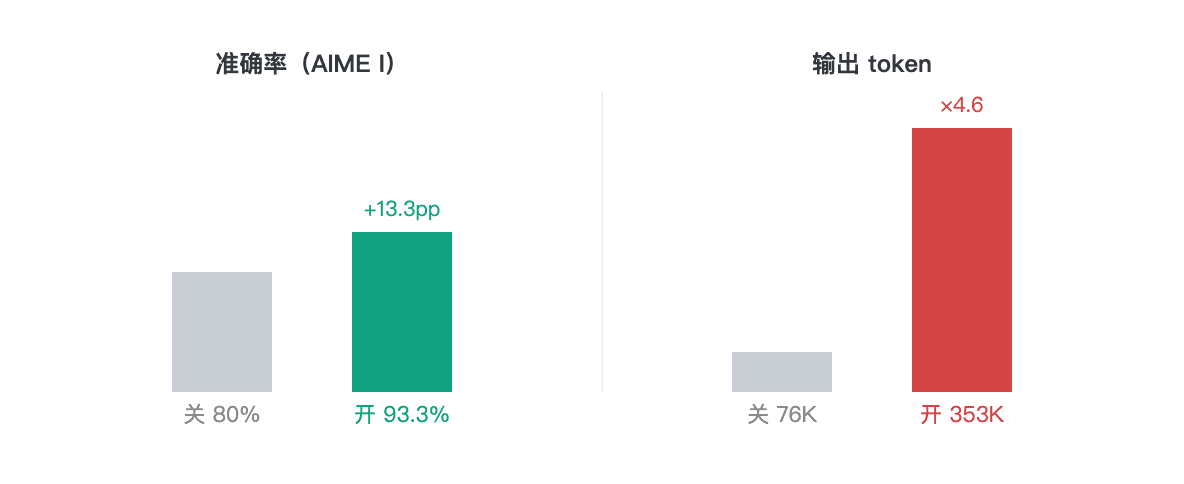
| Modelo / modo | Precisão | Tempo médio/problema | Tokens de saída |
|---|---|---|---|
| 3.7-Plus · thinking off | 12/15 (80%) | 24,7s | 76.502 |
| 3.7-Plus · thinking on | 14/15 (93,3%) | 113,4s | 353.424 |
| 3.7-Max · thinking on | 14/15 (93,3%) | 303,1s | 307.801 |
| 3.6-Plus · thinking | Primeiros 6 problemas: 6/6 | 464s | 25,7K/problema |
Comparação de custos:
| Configuração | Correto | Precisão | Tempo médio/problema | Total tokens saída | Média tps | Custo placeholder |
|---|---|---|---|---|---|---|
| Plus thinking off | 12/15 | 80,0% | 24,7s | 76.502 | 204,0 | USD 0,15 |
| Plus thinking on | 14/15 | 93,3% | 113,4s | 353.424 | 205,4 | USD 0,69 |
| Max thinking on | 14/15 | 93,3% | 303,1s | 307.801 | 68,3 | USD 0,60 |
Nota: o preço placeholder foi estimado com 3.6-Plus a USD 0,325/USD 1,95 por M. O preço oficial de Gateway de USD 0,40/USD 1,60 está mais próximo do preço de produção.
Benefício marginal da chave Thinking
Com o raciocínio ativado, o Plus atingiu a mesma pontuação AIME de execução única que o Max. O 3.7-Plus com thinking ligado e o 3.7-Max marcaram 14/15, mas o Plus levou 113 segundos por problema, enquanto o Max levou 303 segundos. Nesta execução, a latência maior do Max não produziu uma pontuação maior; essa execução única ainda não prova que o Max não tem vantagem em outras tarefas matemáticas.
Em 8 problemas de matemática do ensino fundamental, ambos os modos tiveram 100% de acerto. Ativar o "thinking" consumiu apenas 24% mais tokens. Junte os dois conjuntos e a conclusão é clara:
Desligue o "thinking" para tarefas simples para economizar dinheiro; ligue-o para tarefas difíceis para ganhar precisão. Deixar o raciocínio globalmente ativado significa pagar continuamente mais de 4x em solicitações simples sem ganho de precisão. O valor da chave é permitir rotear dinamicamente pela dificuldade da tarefa.
Max vs Plus: De onde veio a latência nesta execução
O Max também marcou 14/15 e também falhou no I-14 (previu 69, resposta correta 60). Mesmo teste, mesmo problema perdido, mesmo padrão de falha, não foi "o Max foi mais inteligente e falhou em outro caso difícil". O Max resolveu o I-15 enquanto o Plus errou, então há variância em problemas muito difíceis, e uma execução não pode declarar um modelo globalmente mais forte.
Mas a diferença de velocidade foi impressionante. No problema I-2, o Max levou 261 segundos; o Plus levou apenas 108 segundos. Em todo o conjunto, o Max teve uma média de 68,3 tps, enquanto o Plus teve uma média de 205,4, aproximadamente 3x mais rápido.
Conclusão: uma vez que o "thinking" está ativado, o Plus atingiu a mesma pontuação de execução única que o Max neste conjunto de matemática, mantendo uma clara vantagem de latência e custo. Para cenários interativos em tempo real, essa diferença importa.
Controle de tarefa simples
Usamos 8 problemas de matemática do ensino fundamental como um teste de carga simples:
| Modo | Precisão | Tempo médio | Total tokens saída |
|---|---|---|---|
| thinking off | 8/8 | 2,17s | 2.314 |
| thinking on | 8/8 | 2,48s | 2.881 |
Ligar o "thinking" consumiu 24% mais tokens com ganho zero de precisão. Dificuldade é o único critério sensato para ativar o modo de raciocínio.
5. Velocidade, o gap geracional e uma tarefa que tivemos que matar
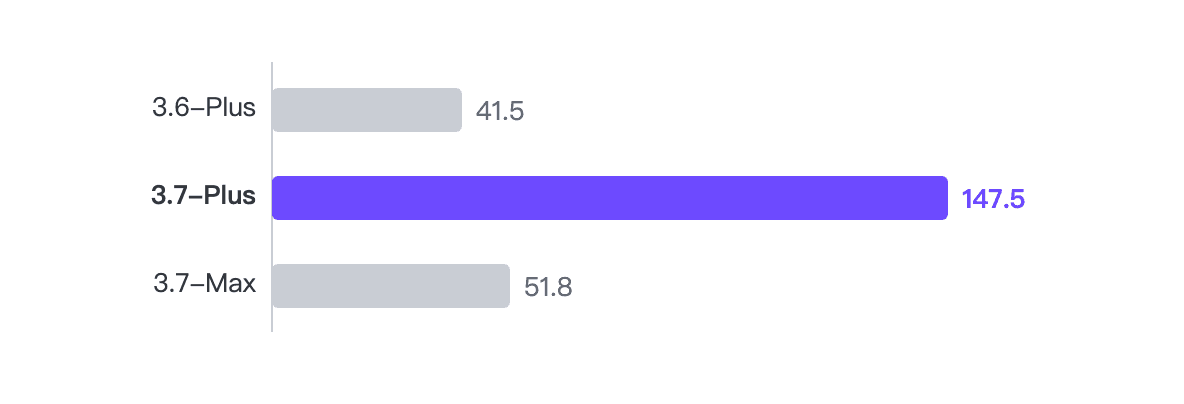
Comparação de throughput de agente
Velocidade real de ponta a ponta extraída de BugFind runner_summary.json:
- 3.7-Plus: 147,5 t/s (52 chamadas, 204,8s)
- 3.7-Max: 51,8 t/s (20 chamadas, 249,0s)
- 3.6-Plus: 41,5 t/s (63 chamadas, 334,5s)
A melhoria geracional (3.6 → 3.7 Plus) foi de cerca de 3,55x. O Plus vs Max da mesma geração foi de cerca de 2,85x.
O exemplo mais dramático do gap geracional veio da execução de matemática no 3.6-Plus. Queríamos adicionar um resultado AIME para ele também, mas ele era lento demais para terminar: o raciocínio ia até o limite em cada problema, a saída de problema único atingia 16K-52K tokens, e cada problema levava 297-932 segundos. Apenas os primeiros 6 problemas levaram 46 minutos. Uma execução completa de 15 problemas não era viável dentro de qualquer orçamento de tempo razoável, então paramos.
Tentamos "limitação de tempo" cortando max_tokens de 16000 para 4096. Não funcionou. Esta é uma armadilha de engenharia que vale a pena registrar:
- No modo de raciocínio, tokens de raciocínio não são limitados por
max_tokens; o modelo ainda pode emitir dezenas de milhares de tokens de raciocínio. - O timeout da solicitação também não é suficiente. O timeout do OpenAI/httpx é um "timeout de leitura" entre blocos de dados. Enquanto a resposta de streaming continuar emitindo tokens, esse timeout nunca dispara.
Ambas as rotas de timeout estavam bloqueadas, então matamos o processo e reportamos os primeiros 6 problemas recuperados: 6/6 corretos. Isso significa que a capacidade matemática do 3.6-Plus não era o problema. Ele conseguia resolver os problemas. Mas "consegue resolver" e "consegue finalizar dentro de um tempo que os usuários tolerarão" são afirmações diferentes. Para um modelo de produção que deve responder aos usuários, o último é muitas vezes mais importante. Esta é exatamente a dimensão que os leaderboards frequentemente escondem, mas a experiência do usuário expõe.
Conselho para equipes de engenharia: para modelos de raciocínio, estratégias tradicionais de timeout e max_tokens podem falhar. Você precisa de um orçamento total de tokens, limite total de tempo de parede ou limite de tokens de raciocínio.
6. Quarto achado central: Multimodalidade - Imagem controlada passou, exemplo oficial falhou
| Amostra de teste | Entrada | Saída do modelo | Julgamento |
|---|---|---|---|
| Imagem controlada | PNG bloco vermelho/azul (local) | "azul, laranja" | ✓ correto |
| Amostra oficial | dog_and_girl.jpeg (OSS) | "um grupo de pessoas em pé ao lado de um trem..." | ✗ completamente errado |
O Arena Vision classifica o Plus por volta de #16 (preview). Esse benchmark mede diálogo imagem-texto sob preferência humana. Nosso teste mostra que um alto score de leaderboard e uma falha em imagem única podem coexistir.
Conselho para seletores de modelo: não executamos benchmarks de visão padronizados como MMMU ou ChartQA, então não estamos fazendo uma afirmação ampla sobre se a visão do Plus está pronta para produção. Mas o achado é claro: executar 20-50 imagens do seu próprio domínio de negócios (OCR, gráficos, prints de UI, recibos) é muito mais confiável do que ler um leaderboard.
Alguns usuários do Hacker News também testaram o modelo e concluíram que "a visão do Qwen é mais forte que a do Gemma". Esse feedback dos usuários não é contraditório; eram tarefas privadas. A falha da imagem de exemplo oficial é um lembrete de que sucesso privado e falha oficial podem coexistir. A seleção do modelo deve ser impulsionada pelos seus próprios dados.
7. Custo: Quanto custou toda esta rodada
Este artigo é ele próprio uma amostra de custo. Após executar três modelos em quatro tipos de tarefas, o uso real da API Qwen foi de cerca de 2 milhões de tokens (a parte do 3.6-Plus parada não foi totalmente contada), com um custo placeholder de cerca de USD 2-3.
Conta desta rodada de teste
| Item | Escala de token | Custo placeholder |
|---|---|---|
| AIME Plus on | 353K out | ~USD 0,69 |
| AIME Plus off | 76K out | ~USD 0,15 |
| AIME Max on | 308K out | ~USD 0,60 |
| BugFind × três modelos | Entrada cumulativa muito alta | Incluído no total |
| Total | ~2 milhões | USD 2-3 |
Insight 1: uma rodada de avaliação séria custa tanto quanto uma refeição. Equipes devem gastar esse dinheiro em reesecutar suas próprias tarefas, não em cópias de marketing.
Insight 2: o custo do agente não é principalmente o preço unitário. É contagem de turnos × tamanho do histórico por turno. O BugFind usou 52-63 chamadas por modelo, e uma entrada de turno único pode exceder 11K tokens. A otimização deve focar em compressão de histórico, decomposição de subagentes e cache, não apenas em preços de modelo mais baratos.
Custo marginal de Thinking (Exemplo AIME I)
- Thinking off: USD 0,15 / 15 problemas ≈ USD 0,01/problema
- Thinking on: USD 0,69 / 15 problemas ≈ USD 0,046/problema
Duas respostas corretas adicionais (I-9 e I-14) custaram +USD 0,54. Se sua empresa executa 10.000 problemas de dificuldade média por dia, o gap pode facilmente chegar a milhares de dólares por dia. A estratégia de roteamento (começar sem thinking, depois ativar quando a confiança for baixa) é obrigatória na produção.
Comparação de preços de Gateway (01-06-2026)
| Modelo | Entrada / saída por M |
|---|---|
| qwen3.7-plus | USD 0,40 / USD 1,60 |
| qwen3.7-max | USD 1,25 / USD 3,75 |
O Max é cerca de 3x mais caro que o Plus (cerca de 2,3x na saída), enquanto esta execução mostrou a mesma pontuação AIME e uma pontuação BugFind um ponto menor. O custo de tempo é geralmente mais caro que o custo de token: tempo de espera do engenheiro e slots de agente ocupados também são dinheiro.
8. Conselho de seleção de modelo para desenvolvedores
| Cenário | Recomendação |
|---|---|
| Construindo agentes / codificação / correção de bugs | Coloque o 3.7-Plus no conjunto de candidatos padrão. Esta execução única foi 10/10, com alto throughput e mais iteração; mantenha o Max como carro-chefe de texto / fallback de alta dificuldade, e não escolha apenas pelo rótulo de carro-chefe. |
| Raciocínio de dificuldade média ou matemática, com sensibilidade à latência | 3.7-Plus com thinking on. Nesta execução, ele igualou a precisão do Max com menor latência. |
| Q&A simples / classificação / extração | 3.7-Plus com thinking off. Economize o custo extra de raciocínio. |
| Ainda usando 3.6-Plus | Atualize. O principal gap geracional é a velocidade, e 3,5x de throughput muda a experiência do usuário. |
9. Limitações e divulgações honestas
Este artigo é um snapshot profundo de uma tarde, não um artigo acadêmico. As seguintes limitações importam:
- Execução única: nem BugFind nem AIME usaram pass@k. Casos de alta variância como a tarefa05 e I-15 precisam de validação repetida.
- Sem comparação horizontal de concorrentes: Claude, GPT, Gemini e DeepSeek não foram testados. Isso descreve apenas diferenças internas na família Qwen.
- 3.6-Plus completou apenas 6 problemas AIME: sua precisão não pode ser comparada diretamente com as execuções de 15 problemas do Plus/Max.
- Preços usaram estimativas de placeholder: verifique o preço mais recente do Gateway para números oficiais; o preço doméstico do DashScope pode ter descontos separados.
- Apenas um framework de agente foi usado (Stirrup): mudar para SWE-agent poderia alterar o ranking.
- Tamanho da amostra multimodal foi n=2: não pode representar ampla capacidade de visão.
- O modelo testado era um beta de convite: o SKU oficial pode ter pequenas alterações de comportamento.
- Dados do X foram um snapshot de um dia: capturou o sentimento da comunidade no momento da escrita e pode ter mudado após a publicação.
Nota final
Na narrativa oficial de junho de 2026, o Qwen3.7-Plus é o nível chinês carro-chefe no ranking de visão, a escolha com melhor custo-benefício no Gateway e o novo membro da família Qwen que a comunidade descreve como movendo-se a uma velocidade de iteração assustadora.
No nosso universo reproduzível de uma tarde, ele é:
- O modelo que foi o único a marcar 10/10 nesta execução única de correção de bugs em código real.
- O modelo que atingiu a mesma pontuação que o Max nesta execução de matemática de concurso com o thinking ativado, enquanto exibia menor latência.
- O modelo que entregou uma melhoria de 3,55x de throughput em relação à geração anterior, tornando o "incapaz de finalizar" uma coisa do passado.
- O modelo que ainda alucinou na imagem de exemplo oficial enquanto passava em nosso teste de imagem controlada, lembrando você de não escolher um modelo de visão por um único print.
Essas conclusões estão limitadas a esta pequena amostra, execução única e scaffold fixo. Elas apoiam colocar o Plus no conjunto de candidatos padrão de engenharia; elas não apoiam um ranking geral de modelos.
Para engenheiros, a narrativa oficial é responsável pela visão; o diretório outputs/ é responsável pelas evidências. Se você está escolhendo um modelo para produção, leia esta revisão junto com a versão de visualização de dados complementar (13_Qwen3.7-Plus_Eval.html): confie nos números primeiro, depois leia por que estamos dispostos a chamar isso de "avaliação" em vez de um repost.
Na enchente de modelos de IA de 2026, apenas evidências auditáveis reproduzíveis são moeda forte para decisões técnicas.






