O Claude Code custa cerca de USD 13 por desenvolvedor por dia ativo, e a automação pesada pode elevar essa conta para algo entre USD 500 e USD 2.000 por engenheiro a cada mês (CloudZero, 2026). Para uma equipe de 50 pessoas, estamos falando de uma linha de despesa de cinco dígitos que surge do nada. Se a sua conta de codificação por IA disparou no último trimestre e ninguém consegue explicar o motivo, você não está sozinho, e a solução raramente é "usar menos a IA".
O problema real é que as ferramentas de codificação agentic consomem tokens de uma maneira fundamentalmente diferente de uma janela de chat, e a maioria das equipes paga o preço total por tokens que poderiam estar obtendo por uma fração do custo. Este guia apresenta sete táticas concretas para reduzir o custo de tokens de codificação por IA, com os números por trás de cada uma e as mudanças exatas de configuração que as tornam eficazes.
Principais pontos
- Ferramentas de codificação agentic queimam de 10 a 100 vezes mais tokens do que o chat, porque o contexto completo é reenviado a cada chamada de ferramenta (LeanOps, 2026).
- O cache de prompts (prompt caching) é a mudança de maior impacto: leituras em cache custam cerca de 10% dos tokens de entrada padrão, e uma equipe reduziu o gasto total com LLM em 59% apenas com isso.
- Mudar a codificação diária para modelos de pesos abertos (open-weight) como GLM, Kimi e DeepSeek pode reduzir o custo por token em 80% ou mais em comparação com modelos de fronteira, com uma diferença de qualidade menor do que a maioria espera.
- Rotear todas as suas ferramentas através de um único gateway mantém um orçamento unificado, uma única chave de API e preços consistentes, em vez de pagar preços de varejo em cinco fornecedores diferentes.
Por que o custo de tokens de codificação por IA sai do controle
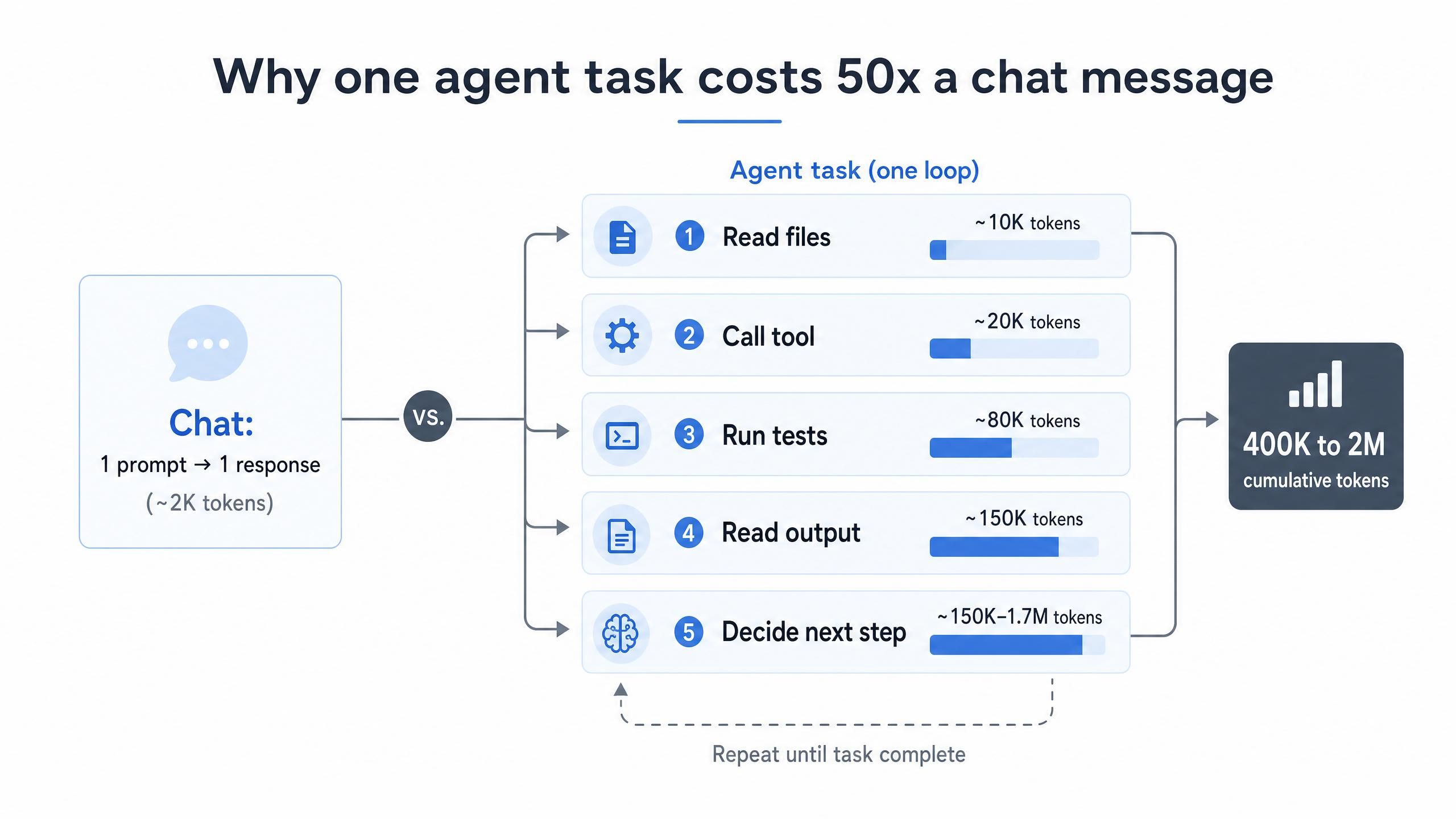
A razão principal pela qual o custo de tokens de codificação por IA é tão alto é estrutural, não comportamental. Uma troca de mensagens em chat envia um prompt e recebe uma resposta. Um agente faz algo muito diferente: ele lê arquivos, chama ferramentas, executa testes, lê a saída e decide a próxima ação. Cada uma dessas etapas de raciocínio reenvia o contexto acumulado, então o uso de tokens se acumula a cada loop. Agentes de IA queimam tokens de 10 a 100 vezes mais rápido que chatbots exatamente por esse motivo (LeanOps, 2026).
Os números crescem rapidamente. Uma única tarefa de agente não trivial pode consumir de 400.000 a 2.000.000 de tokens de entrada cumulativos através da API à medida que a janela de contexto é preenchida e preenchida novamente (Morph, 2026). Multiplique isso por dezenas de tarefas por dia em uma equipe, e a fatura mensal deixa de ser um erro de arredondamento.
Esta não é uma preocupação hipotética para grandes organizações. De acordo com um relatório coberto pelo The Next Web, a Microsoft retirou a maioria das suas licenças internas do Claude Code em parte devido ao custo, com faturas por engenheiro subindo para a faixa de USD 500 a USD 2.000 (The Next Web, 2026). Quando uma das organizações de engenharia mais bem equipadas do mundo hesita diante da conta, vale a pena entender para onde os tokens realmente vão antes de tentar reduzi-los.
Como reduzir o custo de tokens de codificação por IA sem perder velocidade
A boa notícia é que quase nenhuma dessas táticas exige escrever menos código ou supervisionar o agente. Elas funcionam eliminando o desperdício, precificando o mesmo trabalho e combinando cada tarefa com o modelo mais barato capaz de realizá-la. Aqui estão as sete que mais trazem resultados, aproximadamente em ordem de esforço versus retorno.
Tática 1: Use Prompt Caching para reduzir o custo de tokens
O prompt caching é a mudança individual de maior alavancagem. Quando um agente reenvia o mesmo prompt de sistema, definições de ferramentas e contexto de arquivo em cada etapa, o cache permite que o modelo leia esse conteúdo repetido do cache em vez de processá-lo novamente. Leituras de cache são precificadas em cerca de 0,10 vezes a taxa de entrada padrão, um desconto de 90% na parte repetida de cada solicitação (Finout, 2026).
Um ponto importante: as escritas em cache custam um pouco mais do que um token de entrada normal, cerca de 1,25 vezes o padrão para uma janela de cinco minutos. Portanto, o cache compensa quando o contexto é reutilizado dentro do período de vida (time-to-live), que é exatamente o padrão que um agente produz. O impacto no mundo real não é teórico. A equipe da ProjectDiscovery documentou uma redução de 59% no custo total de LLM após implementar o prompt caching em seu pipeline (ProjectDiscovery, 2026).
Se você usa o Claude Code ou um agente compatível, confirme se o cache está ativado e se o seu prompt de sistema e contextos de arquivos grandes estão em blocos armazenáveis. Essa única mudança geralmente gera a maior queda percentual na fatura.
Tática 2: Combine o modelo com a tarefa para reduzir o custo
A maioria das equipes roteia todas as solicitações para o seu modelo mais capaz, o que é como usar um caminhão de carga para ir ao supermercado. O padrão mais inteligente é reservar o modelo de fronteira (frontier model) caro para o trabalho que realmente precisa dele e enviar todo o resto para um modelo mais barato.
Uma divisão prática seria:
- Raciocínio, arquitetura, depuração difícil: um modelo de alto nível onde a qualidade justifica o preço.
- Geração e edições de código diárias: um modelo aberto de nível intermediário sólido.
- Tarefas de background de alto volume, classificação, código repetitivo (boilerplate): o modelo capaz mais barato.
A economia é drástica porque a diferença de preço é enorme. No lado mais barato, o DeepSeek V4 Flash custa cerca de USD 0,14 por milhão de tokens de entrada, enquanto modelos de fronteira custam muitos múltiplos disso (Codersera, 2026). Gastar 80% do seu volume de tokens em um modelo que custa uma fração do valor, mantendo o modelo premium para os 20% que realmente precisam dele, pode reduzir o gasto total em mais da metade sem uma queda perceptível na qualidade.
Tática 3: Mantenha a janela de contexto enxuta
Como cada token no contexto é reenviado a cada etapa do agente, uma janela de contexto inchada é um imposto que você paga repetidamente. Dois hábitos ajudam. Primeiro, defina o escopo de cada tarefa rigorosamente para que o agente carregue apenas os arquivos necessários, em vez de todo o repositório. Segundo, inicie uma sessão nova ao alternar tarefas em vez de permitir que uma conversa acumule centenas de milhares de tokens obsoletos.
Um modelo mental útil: se você não colaria um arquivo em um chat para responder a uma pergunta, não o deixe no contexto do agente. Reduzir uma janela de contexto de 200.000 para 40.000 tokens não economiza apenas uma vez. Economiza em cada chamada de ferramenta pelo restante daquela tarefa, o que faz com que a composição trabalhe a seu favor.
Tática 4: Mude para modelos de pesos abertos (open-weight)
Esta é a tática com a maior economia anunciada e as suposições mais desatualizadas. Os modelos de codificação de pesos abertos lançados em 2026 são genuinamente bons. No SWE-Bench Pro, um modelo de fronteira líder pontua cerca de 91, enquanto o Kimi K2.6 atinge 76,8 e o DeepSeek V4 Pro chega perto de 77 (Codersera, 2026). Essa é uma diferença real no benchmark mais difícil, mas para trabalho de rotina, refatorações e escrita de testes, a diferença é muito menor do que a diferença de preço.
E a diferença de preço é o ponto central. Modelos de pesos abertos como GLM, MiniMax, Kimi e DeepSeek custam uma fração do preço dos modelos de fronteira por token. Para a maioria da codificação do dia a dia, um modelo aberto faz o trabalho por uma fração do custo. A dificuldade historicamente tem sido o acesso: gerenciar contas separadas, chaves distintas e preços inconsistentes entre provedores.
É aqui que um gateway de codificação unificado muda a matemática. Uma plataforma como a Atlas Cloud agrega os principais modelos de pesos abertos atrás de uma única API e um saldo de créditos, para que você possa direcionar o Claude Code, Codex ou OpenClaw para o GLM-5.1 hoje e para o Kimi K2.6 amanhã, sem precisar reconfigurar nada. A Atlas Cloud publica multiplicadores de crédito por modelo que resultam em uma economia de cerca de 45% a 55% em comparação com os preços oficiais da API desses modelos, e a empresa posiciona sua taxa de crédito como mais barata que a da OpenRouter para os mesmos modelos.
Veja como seus multiplicadores de crédito se traduzem entre modelos de codificação populares:
| Modelo | Contexto | Multiplicador Entrada | Multiplicador Saída | Aprox. economia vs oficial |
|---|---|---|---|---|
| deepseek-ai/deepseek-v4-flash | 1M | 0.23 | 0.46 | ~50% |
| deepseek-ai/deepseek-v3.2 | 160K | 0.42 | 0.62 | ~55% |
| minimaxai/minimax-m2.5 | 200K | 0.65 | 2.18 | ~45% |
| moonshotai/kimi-k2.6 | 262K | 1.72 | 7.26 | ~45% |
| zai-org/glm-5.1 | 200K | 2.54 | 7.99 | ~45% |
Fonte: Regras de crédito do Plano de Codificação da Atlas Cloud. Custo de crédito = tokens de entrada × multiplicador de entrada + tokens de saída × multiplicador de saída.
Tática 5: Agrupe trabalhos de background para reduzir custos
Nem todo token precisa ser gasto a preços interativos em tempo real. Avaliações noturnas, tarefas grandes de classificação, revisões de documentação e refatorações em massa não precisam de um humano esperando por elas, o que significa que podem ser executadas por vias de processamento em lote (batch) mais baratas ou no modelo de menor custo disponível. Mover esse volume não urgente para fora do seu modelo interativo premium é dinheiro fácil, pois é um trabalho que você já estava pagando preço cheio sem benefício de qualidade adicional.
O princípio é simples: separe os tokens de "estou esperando por isso" dos tokens de "isso pode terminar durante a noite", e precifique-os de forma diferente. Para a maioria das equipes, uma parte surpreendente do volume total de tokens acaba sendo do tipo noturno.
Tática 6: Roteie todas as ferramentas por um único gateway
A proliferação de ferramentas infla silenciosamente o custo de tokens de codificação por IA. Um desenvolvedor típico pode usar o Claude Code no terminal, Codex para algumas tarefas, Cursor no editor e alguns agentes por fora, cada um com sua própria assinatura, sua própria chave e sua própria fatura opaca. Você perde a capacidade de ver o gasto total e paga preços de varejo em toda parte.
Consolidar em um único endpoint compatível com OpenAI resolve ambos os problemas. Como a Atlas Cloud expõe uma URL base e um pool de créditos que funciona em Codex, Claude Code, OpenClaw, OpenCode, Cursor e chamadas diretas de API, você obtém uma fatura, um orçamento e um lugar para trocar de modelos. Seus planos variam de um nível Starter de USD 10/mês a níveis superiores para equipes mais exigentes, e pacotes pay-as-you-go trazem um desconto de 41%, permitindo ajustar o compromisso ao uso real, em vez de apenas supor.
Apontar o Claude Code para o gateway é uma simples alteração no arquivo de configuração. No macOS ou Linux, edite
1~/.claude/settings.jsonJSON1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "sua-api-key-atlas", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "zai-org/glm-5.1", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "zai-org/glm-5.1", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "zai-org/glm-5.1", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Para usuários do Codex, o equivalente fica em
1~/.codex/config.toml1base_url1https://api.atlascloud.ai/v11~/.codex/auth.jsonTática 7: Defina orçamentos e monitore os custos
Você não pode reduzir o que não pode ver. As equipes que foram pegas de surpresa por faturas gigantescas quase sempre compartilhavam uma característica: sem controles de gastos e sem visibilidade por desenvolvedor. A solução é colocar um teto no consumo antes do mês começar, não depois que a fatura chega.
Um plano baseado em créditos com uma cota diária faz isso estruturalmente. Em vez de um medidor sem limite, uma assinatura mensal que renova uma franquia fixa de créditos a cada dia à meia-noite limita o impacto de um loop de agente descontrolado, enquanto pacotes pay-as-you-go absorvem picos ocasionais após o uso da franquia diária. Quando você precisar escalar, upgrades proporcionais significam que você paga apenas a diferença. O fluxo de upgrade da Atlas Cloud, por exemplo, cobra o valor restante contra o novo nível, então uma mudança no meio do ciclo pode custar apenas alguns dólares em vez de um plano novo completo.
Comparação real de custos entre modelos
Para tornar a economia concreta, considere um desenvolvedor que processa cerca de 1,5 milhão de tokens de entrada e 300.000 tokens de saída por meio de seu agente em um dia agitado, um valor realista dado que tarefas únicas podem atingir a casa dos milhões em entrada cumulativa. Em um modelo de fronteira precificado perto de USD 5 por milhão de entrada e USD 25 por milhão de saída, isso custa cerca de USD 7,50 em entrada mais USD 7,50 em saída, ou aproximadamente USD 15 por dia para o desenvolvedor, o que se alinha com o valor amplamente citado de USD 13 por dia ativo (CloudZero, 2026).
Execute o mesmo volume por meio de um modelo de pesos abertos, como GLM ou Kimi via um gateway com desconto, e a parte da entrada sozinha cai 70% ou mais, com a saída seguindo de perto. Adicione o prompt caching, e o contexto repetido que domina as cargas de trabalho dos agentes é faturado a um décimo da taxa. Empilhe as três táticas juntas — cache, modelo mais barato e contexto enxuto — e um dia de trabalho de um desenvolvedor pode, realisticamente, cair para algo próximo de USD 3 a USD 5, sem alterar como alguém escreve código.

Os números exatos variarão de acordo com sua carga de trabalho, mas a lógica permanece: a maior parte do custo de tokens de codificação por IA é o contexto repetido passando por um modelo superfaturado, e ambos são corrigíveis.
Resumo: Uma configuração que mantém o custo baixo
Se você deseja uma configuração inicial que capture a maior parte da economia com o mínimo de esforço, ela seria: use um modelo de pesos abertos como GLM-5.1 ou Kimi K2.6 como seu modelo padrão, mantenha um modelo de fronteira disponível para raciocínios complexos, ative o prompt caching em todos os lugares, defina escopos de tarefas rigorosamente para manter o contexto enxuto e roteie cada ferramenta através de um único endpoint compatível com OpenAI com um orçamento diário fixo.
Essa combinação aborda cada motivador de custo de uma só vez: ela ajusta o preço dos tokens, interrompe o pagamento por contexto repetido e limita o risco. Equipes que desejam isso consolidado sob uma chave e um orçamento podem configurar através do console do Plano de Codificação da Atlas Cloud, que suporta os principais modelos de pesos abertos e as ferramentas de codificação comuns prontamente. A configuração leva alguns minutos; a economia é recorrente todos os dias.
Perguntas frequentes sobre custo de tokens de codificação por IA
Por que meu custo de codificação por IA é muito maior do que meu uso de chat?
Porque os agentes reenviaram o contexto completo acumulado a cada etapa de raciocínio, enquanto o chat envia cada prompt uma vez. Essa diferença estrutural significa que agentes queimam de 10 a 100 vezes mais tokens do que o chat para trabalhos comparáveis (LeanOps, 2026), portanto, algumas dezenas de tarefas de agente podem superar um mês de uso casual de chat.
Qual é a forma mais rápida de reduzir o custo de codificação por IA?
Ative o prompt caching. O contexto repetido em cargas de trabalho de agentes é faturado a cerca de 10% da taxa de entrada padrão uma vez armazenado em cache (Finout, 2026), e pelo menos uma equipe de engenharia relatou uma queda de 59% no custo total de LLM apenas com o cache. Isso não exige nenhuma mudança na forma como você trabalha, o que o torna o de maior retorno pelo menor esforço.
Modelos de pesos abertos mais baratos são bons o suficiente para trabalho real?
Para a maioria das tarefas do dia a dia, sim. No benchmark mais difícil, o SWE-Bench Pro, os melhores modelos abertos pontuam na casa dos 70, versus cerca de 91 para modelos de fronteira (Codersera, 2026), mas o trabalho de rotina raramente pressiona essa diferença. Mantenha um modelo de fronteira em standby para raciocínios genuinamente difíceis e envie o restante para um modelo aberto.
Quanto posso economizar realisticamente?
Combinar as principais táticas — prompt caching, um modelo padrão mais barato e um contexto enxuto — reduz comumente o custo por dia de desenvolvedor de cerca de USD 15 para a faixa de USD 3 a USD 5, com base nas taxas publicadas por token. A economia se acumula em uma equipe, e é por isso que uma fatura mensal de cinco dígitos muitas vezes está a uma redução percentual de dois dígitos de se tornar razoável.
Preciso mudar de ferramentas para baixar meu custo de tokens?
Não. A maior parte da economia vem de como os tokens são precificados e reutilizados, não de qual cliente você usa. Apontar suas ferramentas existentes, seja Claude Code, Codex ou OpenClaw, para um endpoint compatível com OpenAI com desconto é uma mudança de configuração, não uma migração, então seu fluxo de trabalho permanece o mesmo enquanto a fatura cai.
Conclusão
O custo de tokens de codificação por IA parece misterioso até que você veja o mecanismo: os agentes reenviaram o mesmo contexto repetidamente, e a maioria das equipes paga preços de fronteira por tudo isso. Corrija essas duas coisas com prompt caching, roteamento de modelo mais inteligente, contexto enxuto e um único gateway com desconto, e a conta cairá pela metade ou mais sem que ninguém precise escrever uma linha de código de forma diferente. Comece com o cache esta semana, audite quais tarefas realmente precisam do seu modelo mais caro e consolide suas ferramentas em um único orçamento. A configuração leva uma tarde; a economia é permanente.






