
Se você escreve kernels de GPU, você se encontra em algum ponto de um espectro. Em uma ponta está o Triton: rápido de escrever, mas o compilador toma a maioria das decisões de layout e memória compartilhada para você. Na outra ponta está o CUTLASS / CuTe: controle total, ao custo de muito maquinário de templates. O TileLang fica no meio. Você escreve em Python, mas diz explicitamente o que vive na memória compartilhada, como o pipeline é organizado e como os warps dividem o trabalho — e uma passagem de inferência de layout preenche o restante.
Neste post, abordaremos o modelo mental, escreveremos um GEMM e, em seguida, construiremos um kernel de produção real: o decode de MLA do DeepSeek, onde as decisões interessantes realmente aparecem. O objetivo não é ser exaustivo. É mostrar como você pensa sobre blocos (tiles) e onde o TileLang silenciosamente faz as partes difíceis para você. Terminaremos com uma história mais típica de produção — um kernel onde a vitória não foi a velocidade.
O modelo mental
Aqui está a ideia completa em três pontos.
- Um tile é um objeto de primeira classe. Um pedaço de dados com formato definido (block_M × block_K, por exemplo) é de propriedade e operado por um bloco de threads, um warp ou uma thread. Você para de pensar puramente no nível de bloco de threads como faz no Triton, e para de gerenciar manualmente threads individuais como faz no CUDA.
- Você mesmo coloca os buffers na hierarquia de memória. Você declara o que vai para a memória compartilhada (T.alloc_shared), o que vai para registradores (T.alloc_fragment) e o que é local à thread. Esta é a maior diferença em relação ao Triton, que esconde a alocação de memória compartilhada e o staging dentro do compilador.
- O compilador infere o mapeamento de threads. Uma vez que você definiu onde um tile vive e qual operação é executada nele (uma cópia, um gemm, uma redução), uma passagem de inferência de layout o paraleliza entre as threads e resolve os layouts de registradores e de memória compartilhada. Você pode substituir isso quando precisar, mas na maioria das vezes não precisará. Esta passagem é o recurso de sustentação — quando chegarmos ao MLA, você verá o porquê.
Se você vem do Triton, aqui está o mapeamento aproximado.
| Triton | TileLang | |
|---|---|---|
| Granularidade | bloco de threads + vetorização implícita | tile (bloco / warp / thread) |
| Memória comp. | gerenciada pelo compilador | explicit alloc_shared + copy |
| Layout | o compilador decide | inferido, mas você pode anotar |
| Pipelining | tl.range + compilador | explícito T.Pipelined(num_stages=) |
| Tensor Core | tl.dot | T.gemm com política de warp selecionável |
| Backends | NVIDIA (principalmente) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL, além de forks Ascend e MUSA |
Em resumo: se você quer controle preciso sobre bloqueio (blocking), profundidade de pipeline e particionamento de warp sem escrever CUTLASS, o TileLang é o ponto ideal. Para operações simples elemento a elemento ou fusões leves, o Triton ainda é mais rápido de recorrer.
Configuração
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # wheel pré-compilado, caminho mais fácil
Se você pretende mexer nas passagens do compilador, compile a partir do código-fonte (você precisará de um toolchain LLVM/CUDA local):
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
Vamos escrever um GEMM
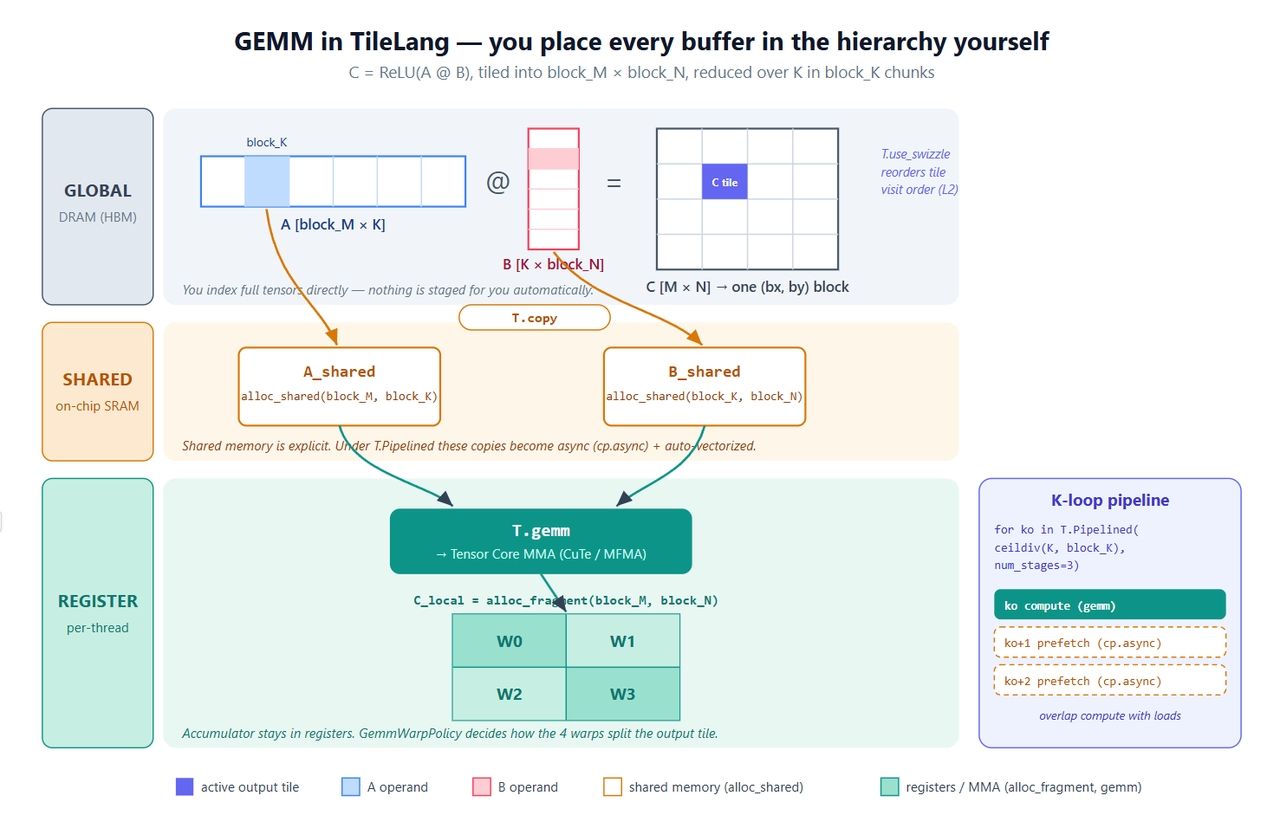
Começaremos com o kernel que todos começam: C = ReLU(A @ B). É pequeno, mas toca em cada primitiva que importa — buffers explícitos, cópia paralela, pipeline de software, a chamada de Tensor Core e um swizzle de L2.
plaintext1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # dims da grade: (#blocos ao longo de N, #blocos ao longo de M); 128 threads por bloco 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # Diga explicitamente onde cada tile vive. 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # memória compartilhada 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # acumulador em registradores 23 24 T.use_swizzle(panel_size=4, order="col") # opcional: melhor reuso em L2 25 T.clear(C_local) # limpa o acumulador 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # global -> shared 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # MMA ao nível de tile 31 32 for i, j in T.Parallel(block_M, block_N): # ReLU fundido 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # escreve de volta 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
Aqui está o que cada peça faz:
- Três buffers, três níveis. A_shared e B_shared vivem na memória compartilhada; C_local vive em registradores. Acumulador em registradores, operandos organizados via memória compartilhada — essa é a receita padrão de GEMM, exceto que aqui você a escreve. Essa é toda a diferença do Triton em uma linha.
- T.copy é um atalho para uma cópia paralela. Ela se expande para um movimento do estilo T.Parallel, e o compilador deriva uma transferência global→shared vetorizada e coalescente a partir dela. Quando a cópia fica dentro de T.Pipelined, ela se torna automaticamente cp.async.
- T.Pipelined(extent, num_stages=N) é um pipeline de software. num_stages=3 significa buffer triplo — enquanto você computa o tile-K ko, os carregamentos para ko+1 e ko+2 já estão em andamento. No Triton, isso é uma flag de compilação; aqui é apenas o loop, o que é mais fácil de raciocinar.
- T.gemm(A, B, C) é o matmul ao nível de tile. Ele reduz para CuTe/MMA na NVIDIA e o intrínseco correspondente na AMD. Ele também aceita transpose_A / transpose_B e um policy=T.GemmWarpPolicy.* que controla como os warps dividem o tile de saída. Guarde esse argumento de política — ele é tudo quando chegarmos ao MLA.
- T.use_swizzle reordena como os blocos de threads são escalonados para que blocos adjacentes no L2 sejam executados próximos no tempo. Geralmente resulta em alguns por cento a mais de largura de banda livre.
A figura abaixo mapeia tudo isso no hardware. Vale a pena ler comparando com o código, porque os pontos rotulados são exatamente onde o TileLang lhe dá o controle que o Triton mantém para si mesmo.
Algumas primitivas que você usará
Você pode escrever a maioria dos kernels com um vocabulário pequeno.
- Alocação: T.alloc_shared, T.alloc_fragment (registradores), T.alloc_local.
- Mover e inicializar: T.copy(src, dst) entre quaisquer dois níveis; T.clear, T.fill.
- Computação: T.gemm(...); T.Parallel(d0, d1, ...) para loops elemento a elemento (este é o ponto de entrada para inferência de layout); T.reduce_max / T.reduce_sum; matemática escalar como T.exp, T.exp2, T.max, T.infinity.
- Escalonamento: T.Pipelined(extent, num_stages=), T.use_swizzle(...), T.annotate_layout(...) quando você precisar de um layout específico (evitar conflito de banco, swizzle personalizado).
- Forma dinâmica: M = T.dynamic("m") para que você não precise recompilar por forma (é chamado de T.symbolic em algumas versões).
Verificando seu trabalho
Duas coisas que você desejará frequentemente. Para ver o que o compilador realmente emitiu:
plaintext1print(kernel.get_kernel_source()) # CUDA / HIP gerado
E para medir o tempo:
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latência: {profiler.do_bench()} ms")
T.print(buf) imprime um tile de dentro do kernel, e o examples/plot_layout do repositório desenha o layout de memória, o que é útil quando você está perseguindo um conflito de banco ou verificando um swizzle.
Agora um real: MLA decode
O GEMM mostra a mecânica. Este próximo mostra por que elas importam. Vamos percorrer o kernel de decode MLA (Multi-Head Latent Attention) do DeepSeek, porque é o exemplo mais claro do TileLang fazendo valer a pena. A referência do TileLang chega a aproximadamente o desempenho do FlashMLA no H100 (benchmarked no batch 64/128 em fp16, confortavelmente à frente do Triton e FlashInfer) em cerca de 80 linhas de Python. A questão interessante é como, porque a parte difícil do MLA não é a matemática — é a pressão sobre os registradores.
Vamos revisar o loop que todos conhecem. Todo kernel da família FlashAttention tem a mesma forma. Por bloco de query, você faz streaming sobre blocos de key/value e mantém um máximo corrente e um denominador, para que a matriz de scores completa nunca vá para a memória:
plaintext1# acc_s : [block_M, block_N] scores para este bloco KV 2# acc_o : [block_M, dim] acumulador de saída 3for i in range(num_kv_blocks): 4 acc_s = Q @ K[i].T 5 m_prev = scores_max 6 scores_max = max(m_prev, rowmax(acc_s)) 7 scores_scale = exp(m_prev - scores_max) 8 acc_o *= scores_scale # redimensiona a saída anterior 9 acc_s = exp(acc_s - scores_max) # probabilidades 10 acc_o += acc_s @ V[i]
Tanto acc_s quanto acc_o querem ficar nos registradores. Para MHA ou GQA, isso é ótimo. Para MLA, não é.
Aqui é onde fica difícil. As dimensões de head do MLA são grandes: query e key têm 512 de largura (uma parte "nope" de 512 sem codificação posicional, mais uma parte "rope" de 64), e value é 512. Então acc_o = [block_M, 512], e precisa permanecer residente nos registradores durante todo o loop KV.
Agora, traga o hardware. No Hopper, o caminho rápido é o wgmma.mma_async, que vincula 4 warps (128 threads) em um warpgroup e requer um M mínimo de 64. Portanto, o menor M que um warpgroup pode ter é 64, o que significa que um warpgroup estaria mantendo um acumulador de 64 × 512. Isso é grande demais para o arquivo de registradores de um único warpgroup. Ele sofre spill e o desempenho cai drasticamente.
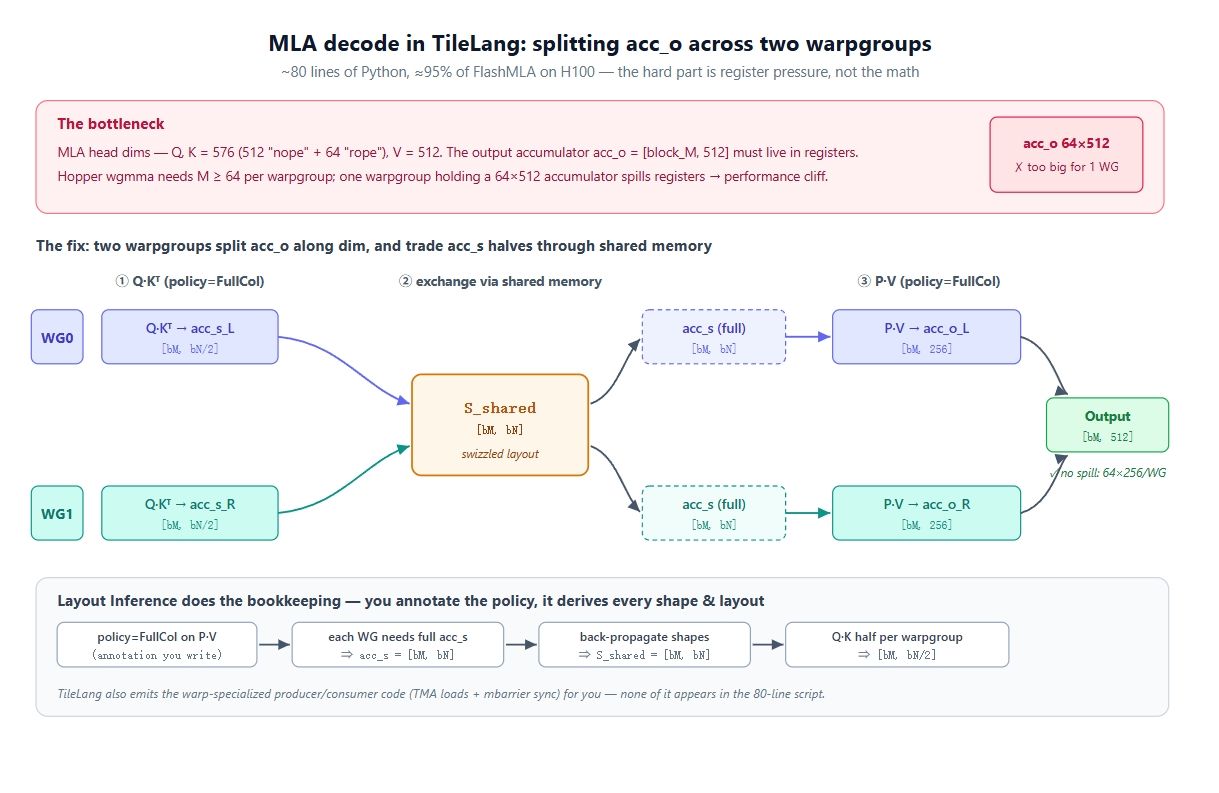
A solução é dividir a saída entre dois warpgroups. Você não pode reduzir M abaixo de 64, então o único eixo restante é dim. Use dois warpgroups: WG0 possui acc_o[:, :256], WG1 possui acc_o[:, 256:]. Agora cada um mantém um acumulador de 64 × 256, que cabe. Isso cria um segundo problema, no entanto: o passo P @ V (com policy=FullCol, cada warpgroup produzindo uma fatia de coluna da saída) precisa do acc_s completo, mas em Q @ K cada warpgroup naturalmente computou apenas metade dele. A resolução é uma troca de memória compartilhada. Durante Q @ K, cada warpgroup escreve sua metade de acc_s na memória compartilhada e lê a metade do outro warpgroup, então, posteriormente, ambos possuem o acc_s completo e podem cada um computar sua fatia de acc_o. O diagrama acima é exatamente isso: dividir os scores, trocar através de S_shared, dividir a saída.
No CuTe, você escreveria manualmente os layouts, os swizzles, o alinhamento de Tensor Core e a sincronização produtor/consumidor para conseguir isso. A razão pela qual isso colapsa para ~80 linhas aqui é a inferência de layout.
Vamos analisar o que a inferência de layout faz. Você anota a intenção nas chamadas T.gemm, e ela propaga as restrições através do programa para você:
- policy=FullCol em P @ V significa que cada warpgroup precisa do acc_s completo, então acc_s = [block_M, block_N].
- Isso se propaga de volta para o buffer de staging, então S_shared em T.copy(S_shared, acc_s) também é [block_M, block_N].
- E para a frente em Q @ K: com FullCol, a fatia de score de cada warpgroup é [block_M, block_N/2].
O insight chave é que você nunca escreve nenhuma dessas formas. Você escolhe a política de warp e escreve a matemática; as formas, os layouts swizzled e o código produtor/consumidor especializado para warp surgem todos da inferência.
O esqueleto do kernel. No MLA decode, a query se divide em uma parte "nope" (Q, dim 512) e uma parte "rope" (Q_pe, dim 64), e o latente comprimido serve tanto como K quanto V. Então o score é uma soma de dois GEMMs, e a saída é mais um. O loop interno parece com isso (um esqueleto representativo, não exato linha por linha — veja example_mla_decode.py):
plaintext1# acc_s = Q_nope @ KV^T + Q_rope @ K_pe^T 2T.gemm(Q_shared, KV_shared, acc_s, transpose_B=True, 3 policy=T.GemmWarpPolicy.FullCol, clear_accum=True) 4T.gemm(Q_pe_shared, K_pe_shared, acc_s, transpose_B=True, 5 policy=T.GemmWarpPolicy.FullCol) 6 7# softmax online 8T.copy(scores_max, scores_max_prev) 9T.fill(scores_max, -T.infinity(accum_dtype)) 10T.reduce_max(acc_s, scores_max, dim=1, clear=False) 11# ... exp, redimensiona acc_o por scores_scale, reduce_sum em logsum ... 12 13# acc_o += P @ V (V é o mesmo KV latente) 14T.copy(acc_s, acc_s_cast) 15T.gemm(acc_s_cast, KV_shared, acc_o, policy=T.GemmWarpPolicy.FullCol)
A troca de S_shared entre os dois warpgroups é a parte que a inferência insere para você, uma vez que as políticas FullCol forçam o acc_s a ser completo por warpgroup.
A parte boa: as otimizações são de uma linha cada. É aqui que o TileLang compensa — todo o kit de ferramentas de desempenho é composto de comandos de uma linha, e o lowering bagunçado é tratado para você.
- Swizzling de threadblock para reuso em L2: T.use_swizzle(panel_size, order="row").
- Swizzling de memória compartilhada para conflitos de banco: T.annotate_layout({S_shared: T.layout.make_swizzled_layout(S_shared)}) — remapeamento de endereços estilo XOR para que acessos concorrentes se espalhem pelos bancos em vez de serializar.
- Especialização de Warp: você escreve um script simples, e ele é reduzido para um warpgroup produtor (carregamentos TMA) mais warpgroups consumidores, com toda a sincronização mbarrier gerada. Nada disso aparece no seu código.
- Pipelining: T.Pipelined(range, num_stages) sobrepõe carregamentos com computação — mais estágios, mais sobreposição, mas mais memória compartilhada, então é uma configuração.
- Split-KV (estilo FlashDecoding): quando o batch é pequeno e os SMs estão ociosos, divida o contexto KV entre os SMs e combine. É um parâmetro num_split mais um kernel de combinação.
Portanto, o raciocínio genuinamente difícil — orçamento de registradores contra o piso de M≥64, quem possui o quê entre os warpgroups, a troca de memória compartilhada — você expressa escolhendo uma política e escrevendo a matemática. Tudo o que seriam centenas de linhas frágeis no CuTe é inferência e codegen. Essa é a proposta, e o MLA é onde ela é mais convincente.
Um caso nosso: um RMSNorm drop-in na AtlasCloud
O último exemplo é um de nossos kernels de produção na AtlasCloud, do VAE de geração de vídeo Wan no H100/H200. É uma ótima ilustração da outra coisa em que o TileLang é excelente: cobrir uma configuração que um kernel ajustado manualmente não consegue alcançar, com um drop-in limpo.
A configuração. Já enviamos um kernel RMSNorm + SiLU fundido ajustado manualmente. É rápido e compilado para as dimensões ocultas D ∈ {96, 192, 384} que uma configuração de modelo usa. Uma configuração mais nova precisa de larguras de canal como {160, 256, 320, 512, 640, 1024}, então nessa configuração o caminho rápido ajustado manualmente não pode ser executado. Escrevemos um drop-in em TileLang para cobrir exatamente essa lacuna.
O kernel TileLang. Um drop-in com a mesma interface (BTHWC in/out, mesma matemática, mesmo eps) que suporta qualquer C que seja múltiplo de 32. Duas passagens, totalmente coalescido, acumulador FP32:
plaintext1@T.prim_func 2def main(X: T.Tensor((M, C), dtype), # M = B*T*H*W linhas 3 gamma: T.Tensor((C,), dtype), 4 Y: T.Tensor((M, C), dtype)): 5 with T.Kernel(T.ceildiv(M, BLOCK_M), threads=128) as bm: 6 X_chunk = T.alloc_shared((BLOCK_M, BLOCK_C), dtype) 7 ss = T.alloc_fragment((BLOCK_M,), accum_dtype) # soma de quadrados em FP32 8 # passagem 1: loop sobre C em pedaços de BLOCK_C, acumula soma de quadrados em FP32 9 # rinv = rsqrt(ss / C + 1e-5) 10 # passagem 2: recarrega X, y = silu(x * gamma * rinv), escreve de volta
BLOCK_C é 128/64/32 dependendo de C, para respeitar o limite TMA boxDim ≤ 256, e o acumulador FP32 mantém a soma dos quadrados longe de estourar em FP16. O dispatch mantém o caminho ajustado manualmente onde ele funciona e só recorre ao fallback quando precisa:
plaintext1_ATLAS_SUPPORTED_D = (96, 192, 384) 2 3def rms_silu_dispatch(x, gamma, out): 4 if x.shape[-1] in _ATLAS_SUPPORTED_D: 5 atlas_rms_norm_silu(x, gamma, out=out) # mantém o caminho ajustado manualmente 6 else: 7 tilelang_rms_silu_bthwc(x, gamma, out=out) # cobre a lacuna
O que ganhamos. Tudo é ganho, e é um verdadeiro drop-in — mesma interface, mesma matemática, mesmo eps, então ele se encaixa atrás do dispatch existente sem alterações no call-site.
| O quê | Ganho |
|---|---|
| Configuração anteriormente não suportada | 0 → 1 — agora funciona (a vitória principal) |
| RMSNorm em bloco de atenção vs a norma eager do PyTorch que substituiu | 42 μs → 20 μs (~2× mais rápido) |
| VAE ponta a ponta na resolução de produção (720×1280, 21 frames) | ~1.79× encode, ~1.78× decode |
A primeira linha é o ponto real: o TileLang nos permitiu atender a uma configuração de modelo que anteriormente não tinha nenhum caminho rápido, sem tocar no kernel ajustado manualmente que já funciona para a outra configuração. Um drop-in, escrito em Python, e todo um caminho de modelo passou de "falha" para "em produção".
Onde o TileLang brilha
- Controle preciso sobre bloqueio, estágios de pipeline e particionamento de warp, sem escrever CUTLASS/CuTe.
- Kernels estruturalmente complexos e sensíveis ao layout: variantes de GEMM, família FlashAttention, MLA, atenção linear, GEMM quantizado fundido com dequant, roteamento MoE.
- Cobrir uma operação ou configuração que seus kernels ajustados manualmente não alcançam (uma dimensão oculta fora do conjunto instanciado, um layout incomum) — e vencendo um fallback eager enquanto você está nisso.
- Um corpo de kernel em todos os backends (NVIDIA / AMD / forks de fornecedores).
- Todo o kit de ferramentas de otimização é uma chamada de cada vez — T.use_swizzle, T.annotate_layout, T.Pipelined, especialização de warp, split-KV — com o lowering tratado para você.
Conclusão
A parte legal do TileLang é que o raciocínio difícil permanece na sua cabeça, não no boilerplate. Você decide como dividir o trabalho entre os warps, onde os buffers vivem e quão profundo o pipeline funciona — e então a inferência de layout e a especialização de warp transformam isso nos layouts de registradores, nos swizzles e na dança produtor/consumidor que, de outra forma, seriam centenas de linhas de CuTe. Você escolhe uma política e escreve a matemática. Essa é toda a proposta, e é por isso que um kernel MLA de 80 linhas pode ficar ao lado de um CUTLASS ajustado manualmente.






