MiniMax LLM Models
As a premier suite of Large Language Models (LLMs) developed by MiniMax AI, MiniMax is engineered to redefine real-world productivity through cutting-edge artificial intelligence. The ecosystem features MiniMax M2.5, which is purpose-built for high-efficiency professional environments, and MiniMax M2.1, a model that offers significantly enhanced multi-language programming capabilities to master complex, large-scale technical tasks. By achieving SOTA performance in coding, agentic tool use, intelligent search, and office workflow automation, MiniMax empowers users to streamline a wide range of economically valuable operations with unparalleled precision and reliability.
สำรวจโมเดลชั้นนำ
Atlas Cloud มอบโมเดลสร้างสรรค์ล่าสุดที่นำหน้าในอุตสาหกรรมให้กับคุณ
สิ่งที่ทำให้ MiniMax LLM Models โดดเด่น
Atlas Cloud มอบโมเดลสร้างสรรค์ล้ำสมัยชั้นนำของอุตสาหกรรมให้กับคุณ
การใช้เหตุผลระดับแนวหน้า
โมเดลภาษาที่ล้ำสมัยซึ่งสร้างขึ้นเพื่อการให้เหตุผลเชิงลึก การแก้ปัญหาที่ซับซ้อน และการวางแผนแบบหลายขั้นตอน
การเข้าใจบริบทที่มีความยาวพิเศษ
กลไก Attention แบบ Lightning และสถาปัตยกรรมที่ได้รับการปรับปรุงช่วยให้โมเดล MiniMax สามารถประมวลผลและรักษาบริบทที่ยาวได้,
ประสิทธิภาพ MoE ที่คุ้มค่า
การออกแบบสถาปัตยกรรม Mixture-of-Experts มอบความอัจฉริยะขั้นสูง ความหน่วงต่ำ และประสิทธิภาพต่อราคาที่ดีกว่าอย่างมีนัยสำคัญ
ตระกูลโมเดลอเนกประสงค์
ตั้งแต่โมเดลอเนกประสงค์อันทรงพลังไปจนถึงรุ่นที่ปรับแต่งมาเพื่อการเขียนโค้ดและเอเจนต์โดยเฉพาะ
ความน่าเชื่อถือระดับองค์กร
โครงสร้างพื้นฐานที่เสถียรและปรับขนาดได้ พร้อมระบบตรวจสอบและความปลอดภัยสำหรับการใช้งานจริง
เปิดกว้างและเป็นมิตรกับนักพัฒนา
API ที่หลากหลาย SDK และการเปิดเผยน้ำหนักโมเดล (open-weight) ช่วยให้นักพัฒนามีความยืดหยุ่นในการรวมระบบ ปรับแต่งละเอียด หรือโฮสต์ด้วยตนเอง
ความเร็วสูงสุด
ต้นทุนต่ำที่สุด
| โมเดล | คำอธิบาย |
|---|---|
| MiniMax M2.5 | MiniMax M2.5 เป็น LLM ระดับเรือธงที่ได้รับการปรับให้เหมาะสมสำหรับประสิทธิภาพการทำงานในโลกแห่งความเป็นจริง โดยผสานรวมสถาปัตยกรรมการอนุมานขั้นสูงเข้ากับความสามารถในการประมวลผลบริบทที่กว้างขวางถึง 196.61K ด้วยประสิทธิภาพระดับ SOTA ในระบบอัตโนมัติในสำนักงานและการค้นหาอัจฉริยะ ทำให้โมเดลนี้ทำหน้าที่เป็นเครื่องมือที่มีประสิทธิภาพสูงสำหรับการจัดการงานที่มีมูลค่าทางเศรษฐกิจและการใช้เหตุผลทั่วไปที่ซับซ้อนในสภาพแวดล้อมทางวิชาชีพ |
| MiniMax M2.1 | MiniMax M2.1 คือ LLM ประสิทธิภาพสูงที่ปรับแต่งมาเพื่อความท้าทายทางเทคนิคที่ซับซ้อน ผสานรวมการเขียนโปรแกรมหลายภาษาที่ได้รับการปรับปรุงอย่างมีนัยสำคัญเข้ากับการประมวลผลบริบทขนาด 196.61K ที่แข็งแกร่ง ด้วยความแม่นยำที่ยอดเยี่ยมในการใช้เครื่องมือแบบ Agentic มันจึงทำหน้าที่เป็นรากฐานสำหรับการสร้าง Agents จัดตารางงานที่ซับซ้อนและการแก้ปัญหาทางวิศวกรรมขนาดใหญ่ที่ยุ่งยาก |
| MiniMax M2 | MiniMax M2 คือ SOTA LLM อเนกประสงค์ ที่ผสานรวมโมดูลการให้เหตุผลที่มีประสิทธิภาพสูงเข้ากับความสามารถในการประมวลผลบริบทที่กว้างขวางถึง 196.61K ด้วยความอเนกประสงค์ที่แข่งขันได้ในการเขียนโค้ด การค้นหา และเวิร์กโฟลว์ระดับมืออาชีพ จึงทำหน้าที่เป็นรากฐานสำคัญที่เชื่อถือได้สำหรับการดำเนินงานขององค์กรในแต่ละวันที่ต้องการการบูรณาการที่ราบรื่นของการดำเนินการงานหลายขั้นตอน |
ฟีเจอร์ใหม่ของ MiniMax LLM Models + โชว์เคส
การผสมผสานโมเดลขั้นสูงกับแพลตฟอร์มเร่งความเร็ว GPU ของ Atlas Cloud มอบความเร็ว ความสามารถในการปรับขนาด และการควบคุมเชิงสร้างสรรค์ที่ไม่มีใครเทียบได้สำหรับการสร้างภาพและวิดีโอ
การเขียนโค้ดขั้นสูงและการวางแผนเอเจนต์ด้วย MiniMax M2.5
MiniMax M2.5 รองรับภาษาโปรแกรมมากกว่า 10 ภาษา รวมถึง Rust, Go และ Python เพื่ออำนวยความสะดวกในการพัฒนาแบบ Full-stack ที่ครอบคลุมทั้งบนแพลตฟอร์ม Web, มือถือ และเดสก์ท็อป ด้วยการผสานรวมความรู้เชิงลึกในอุตสาหกรรมสำหรับการจัดรูปแบบเอกสารระดับมืออาชีพและการสร้างแบบจำลองทางการเงิน ช่วยให้การเปลี่ยนผ่านจากการออกแบบสถาปัตยกรรมระบบไปจนถึงการทดสอบผลงานขั้นสุดท้ายเป็นไปอย่างราบรื่น นี่คือโซลูชันที่สมบูรณ์แบบสำหรับวิศวกรรมซอฟต์แวร์ที่ซับซ้อนและเวิร์กโฟลว์การทำงานในสำนักงานที่มีความสำคัญสูง
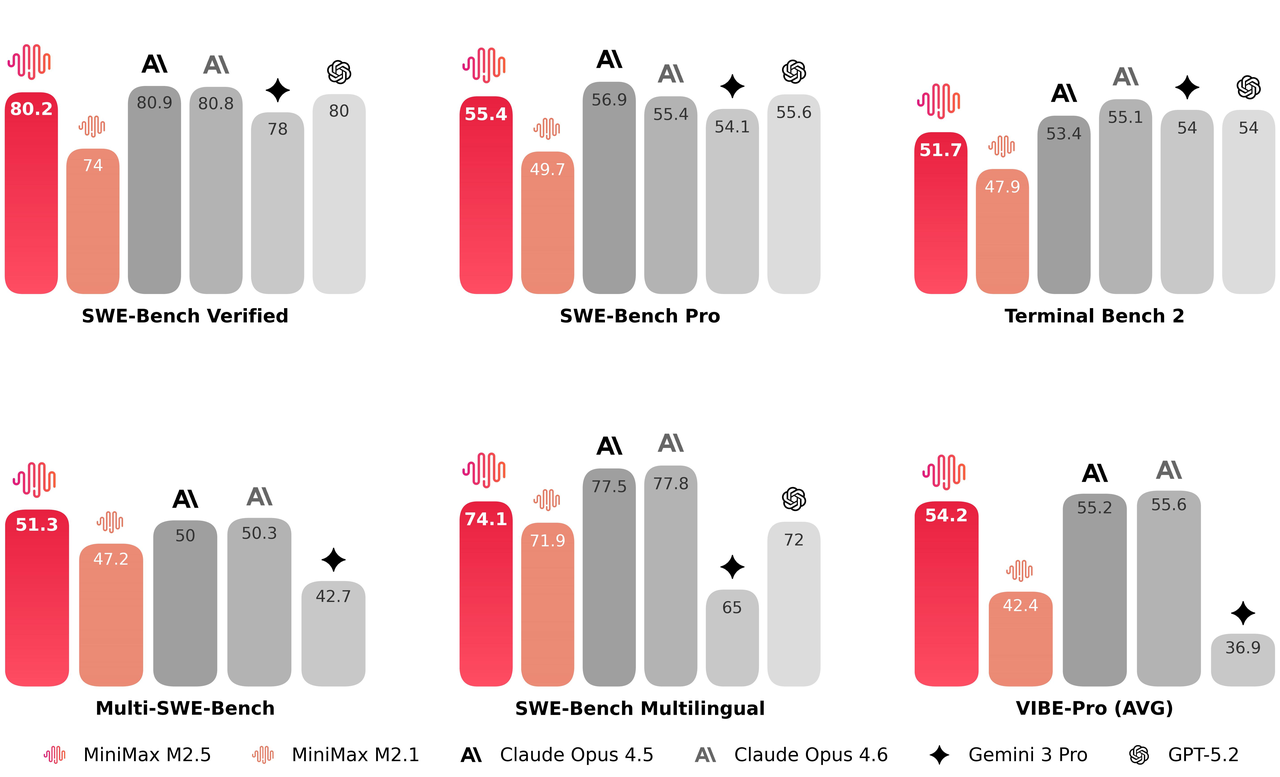
การตอบสนองที่รวดเร็วและประสิทธิภาพการตัดสินใจงานด้วย MiniMax M2.5
สถาปัตยกรรม M2.5 เพิ่มความเร็วในการประมวลผลแบบ End-to-End ได้ถึง 37% โดยลดระยะเวลาของงานที่ซับซ้อนจาก 31.3 เหลือ 22.8 นาทีในการทดสอบ SWE-bench อย่างมีนัยสำคัญ ด้วยการปรับปรุงตรรกะการแยกย่อยงาน โมเดลนี้จึงใช้ Token และรอบการค้นหาน้อยลง 20% ในการบรรลุเป้าหมายในการทดสอบมาตรฐานอย่าง BrowseComp ซึ่งนำเสนอโซลูชันที่คล่องตัวสำหรับการตัดสินใจที่รวดเร็ว พร้อมทั้งขจัดภาระการคำนวณที่ซ้ำซ้อน
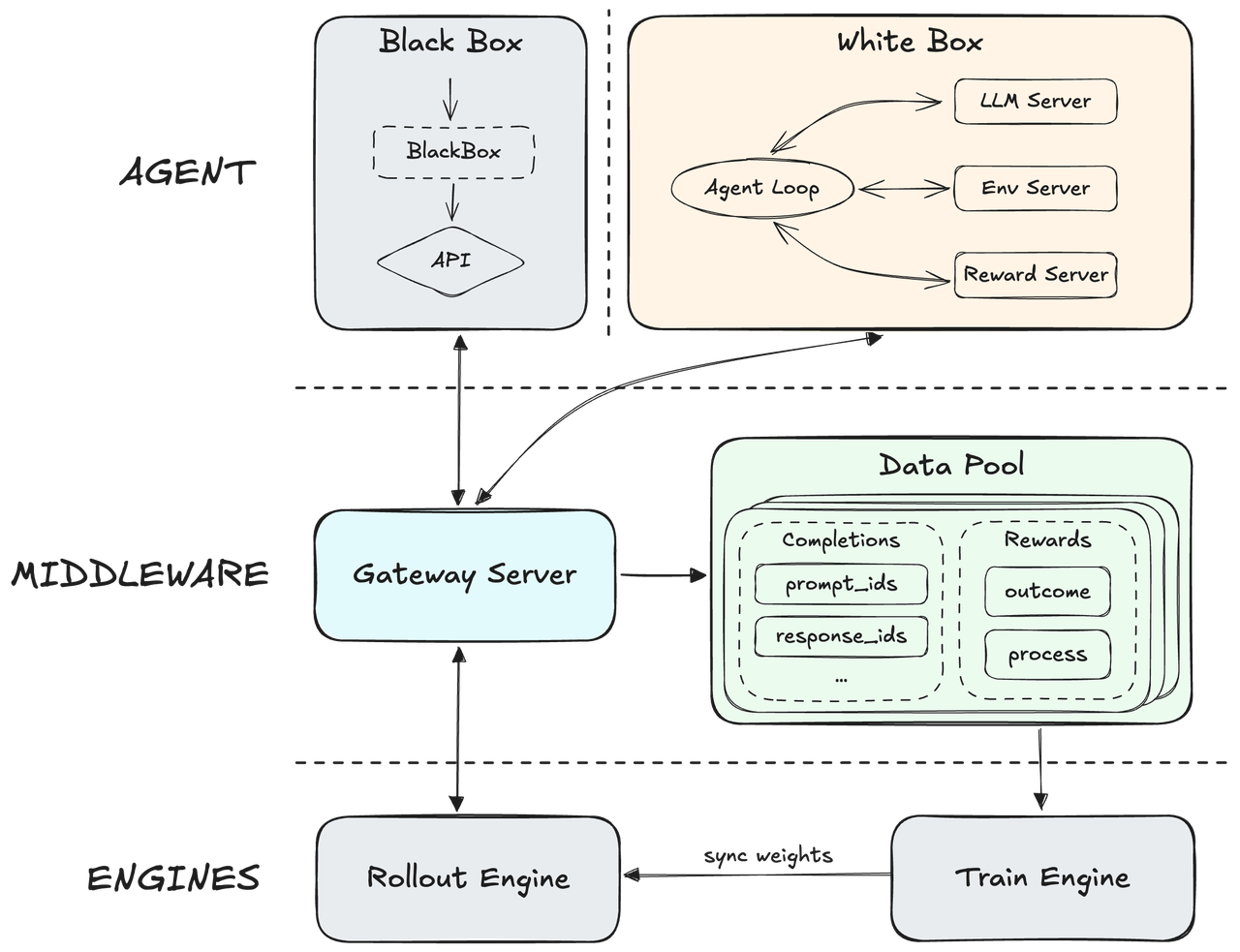
สถาปัตยกรรมวิวัฒนาการผ่านการเรียนรู้แบบเสริมกำลังขนาดใหญ่โดยใช้ MiniMax M2.5
MiniMax สร้างขึ้นบนเฟรมเวิร์ก Agent RL แบบเนทีฟ โดยแยกเครื่องยนต์หลักออกจากโครงสร้างของเอเจนต์ (agent scaffolding) เพื่อให้สามารถทำงานทั่วไปได้ในสภาพแวดล้อมจริงที่หลากหลายนับแสนแห่ง ระบบประกอบด้วยกลไกการให้รางวัลกระบวนการที่ซับซ้อน ซึ่งใช้ผลป้อนกลับจากการดำเนินการแบบเรียลไทม์เพื่อปรับแต่งเส้นทางการใช้เหตุผลและรับประกันคุณภาพผลลัพธ์ระดับสูง สิ่งนี้สร้างระบบที่ปรับตัวได้สูง ซึ่งสามารถรักษาความแม่นยำที่เหนือกว่าในขณะที่เพิ่มความเร็วในการตอบสนองการปฏิบัติงานโดยรวมให้สูงสุด
สิ่งที่คุณทำได้กับ MiniMax LLM Models
ค้นพบกรณีการใช้งานจริงและเวิร์กโฟลว์ที่คุณสามารถสร้างด้วยตระกูลโมเดลนี้ — ตั้งแต่การสร้างเนื้อหาและระบบอัตโนมัติไปจนถึงแอปพลิเคชันระดับโปรดักชัน
การดีบัก Full-Stack ระดับโปรดักชันด้วย MiniMax M2.5
MiniMax M2.5 ทำหน้าที่เสมือนสถาปนิกด้านเทคนิคอาวุโส โดยตรวจสอบข้อผิดพลาดทางตรรกะใน Backend API, ฐานข้อมูล และ Frontend Framework เช่น React หรือ Swift แทนที่จะให้เพียงโค้ดบางส่วน แต่จะปรับโครงสร้าง (Refactor) โมดูลทั้งหมดเพื่อให้มั่นใจถึงความเข้ากันได้ทั้งระบบ เหมาะสำหรับการสร้างต้นแบบอย่างรวดเร็ว (Rapid Prototyping) API นี้จัดการทุกอย่างตั้งแต่การตั้งค่าสภาพแวดล้อม ไปจนถึงการทดสอบ Edge-case และการปรับปรุงโค้ดรุ่นเก่า (Legacy Code) ให้ทันสมัยสำหรับระบบระดับองค์กร
การสร้างแบบจำลองทางการเงินและการรายงานระดับมืออาชีพโดยใช้ MiniMax M2.5
สำหรับนักวิเคราะห์ที่ต้องการความแม่นยำสูงสุด API นี้จะช่วยทำแบบจำลองทางการเงิน Excel ที่ซับซ้อนโดยอัตโนมัติ และสร้างรายงานการวิจัยที่พร้อมเผยแพร่ตามกรอบการลงทุนระดับมืออาชีพ โดยจะตีความข้อมูลดิบเพื่อสร้างตรรกะการควบคุมความเสี่ยงและชุดสไลด์นำเสนอระดับมืออาชีพที่มีการจัดรูปแบบที่ได้มาตรฐาน ซึ่งเหมาะสำหรับสภาพแวดล้อมการให้คำปรึกษาและการธนาคารที่มีเดิมพันสูง ซึ่งความถูกต้องและการปฏิบัติตามมาตรฐานการรายงานอย่างเป็นทางการเป็นสิ่งที่ไม่สามารถต่อรองได้
การวิจัยเว็บแบบหลายขั้นตอนอัตโนมัติด้วย MiniMax M2.5
MiniMax M2.5 ดำเนินการค้นหาที่ซับซ้อนและมีหลายรอบเพื่อสังเคราะห์ข้อมูลเว็บที่กระจัดกระจายให้เป็นบทสรุปสำหรับผู้บริหารที่เชื่อมโยงกัน ด้วยการแยกย่อยคำค้นหาแบบกว้างอย่างชาญฉลาดและการเรียกดูด้วยความซ้ำซ้อนของโทเค็น (token redundancy) ที่น้อยที่สุด จึงหลีกเลี่ยงการให้เหตุผลแบบวนอ่างเพื่อนำเสนอข้อเท็จจริงที่ได้รับการตรวจสอบแล้ว เป็นเครื่องมืออันทรงพลังสำหรับนักวิจัยตลาดและทีมกลยุทธ์ที่ต้องการข้อมูลเชิงลึกโดยไม่ต้องกรองแหล่งข้อมูลหลายร้อยแห่งด้วยตนเอง
เปรียบเทียบโมเดล
ดูว่าโมเดลจากผู้ให้บริการต่างๆ เปรียบเทียบกันอย่างไร — เปรียบเทียบประสิทธิภาพ ราคา และจุดแข็งเฉพาะตัวเพื่อตัดสินใจอย่างมีข้อมูล
| โมเดล | บริบท | เอาต์พุตสูงสุด | ข้อมูลนำเข้า | การวางตำแหน่ง |
|---|---|---|---|---|
| MiniMax M2.5 | 196.61K | 196.61K | ข้อความ | การเขียนโค้ดเชิงตัวแทนที่ล้ำสมัย |
| MiniMax M2 | 196.61K | 196.61K | ข้อความ | โมเดลประสิทธิภาพสูง |
| MiniMax M2 | 196.61K | 196.61K | ข้อความ | รุ่นเรือธงทั่วไป |
| GLM-5 | 202.75K | 202.75K | ข้อความ | โมเดลพื้นฐานเรือธง |
| DeepSeek V3.2 | 163.84K | 163.84K | ข้อความ | เรือธงทั่วไป |
How to Use MiniMax LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
ทำไมต้องใช้ MiniMax LLM Models บน Atlas Cloud
การรวมโมเดล MiniMax LLM Models ขั้นสูงเข้ากับแพลตฟอร์มที่เร่งด้วย GPU ของ Atlas Cloud ให้ประสิทธิภาพ ความสามารถในการขยาย และประสบการณ์นักพัฒนาที่ไม่มีใครเทียบได้
ประสิทธิภาพและความยืดหยุ่น
เวลาแฝงต่ำ:
inference ที่ปรับแต่ง GPU เพื่อการตอบสนองแบบเรียลไทม์
API แบบรวมศูนย์:
รัน MiniMax LLM Models, GPT, Gemini และ DeepSeek ด้วยการเชื่อมต่อเดียว
ราคาโปร่งใส:
ชำระเงินต่อโทเค็นที่คาดเดาได้พร้อมตัวเลือก serverless
องค์กรและขนาด
ประสบการณ์นักพัฒนา:
SDK, การวิเคราะห์, เครื่องมือปรับแต่ง และเทมเพลต
ความน่าเชื่อถือ:
ความพร้อมใช้งาน 99.99%, RBAC และการบันทึกที่พร้อมสำหรับการปฏิบัติตาม
ความปลอดภัยและการปฏิบัติตาม:
SOC 2 Type II, สอดคล้อง HIPAA, อธิปไตยข้อมูลในสหรัฐอเมริกา
คำถามที่พบบ่อยเกี่ยวกับ MiniMax LLM Models
เรานำเสนอสามเวอร์ชันหลัก: MiniMax M2.5 (รุ่นเรือธงสำหรับการทำงานในสำนักงานและการค้นหา), MiniMax M2.1 (ปรับปรุงสำหรับการเขียนโค้ดและตรรกะที่ซับซ้อน) และ MiniMax M2 (โมเดลอเนกประสงค์ที่สมดุล)
ซีรีส์ MiniMax M2 รองรับบริบทความยาวพิเศษขนาด 196.61K อย่างสม่ำเสมอ ซึ่งช่วยให้สามารถประมวลผลเอกสารทางเทคนิคหลายร้อยหน้าหรือฐานโค้ดวิศวกรรมขนาดใหญ่ได้ในการร้องขอเพียงครั้งเดียว
ในการทดสอบแบบ End-to-End บน SWE-bench รุ่น M2.5 ได้ลดเวลาในการประมวลผลสำหรับงานที่ซับซ้อนจาก 31.3 นาทีเหลือ 22.8 นาที ซึ่งถือเป็นการเพิ่มความเร็วในการทำงานโดยรวมถึง 37%
สำรวจกลุ่มเพิ่มเติม
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
Grok-Imagine Models
Grok Imagine Image Quality is xAI's latest AI image generation model, delivering studio-grade visuals with up to 2K resolution and razor-sharp detail. It offers best-in-class text rendering across multiple languages, photorealistic outputs with natural lighting, rich textures, and believable physics, plus tighter prompt following and image editing with reference inputs for precise creative control. Ideal for hero images, ad creatives, product renders, and brand-grade visuals.
Gemini Omni
Gemini Omni (by Google DeepMind) is a video generation and editing model launched on May 20, 2026 at Google I/O that redefines the standard for "reasoning-driven creation," built specifically to solve the core challenge of AI video: making output that actually understands what you mean, not just what you type. It fuses Gemini's reasoning engine with generative capability, accepting any mix of images, text, video, and audio to produce consistent, knowledge-grounded output. Unlike models that start from scratch each time, Omni lets you edit through natural conversation — swapping objects, rewriting scenes, shifting styles — while keeping physics, characters, and continuity intact across every turn.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.


