Gemini Omni Flash API for Conversational Video Editing
Gemini Omni API, Google DeepMind'ın Google I/O 2026'da tanıtılan çok modlu video üretim ve düzenleme modelini stack'inize taşır. Gemini Omni, Gemini'nin akıl yürütme motorunu üretken medyayla birleştirir; metin, görsel, video ve sesin her türlü kombinasyonunu kabul ederek tutarlı ve bilgiye dayalı çıktılar üretir. Sonuçları doğal bir sohbetle iyileştirin: fizik, karakterler ve süreklilik bozulmadan nesneleri değiştirin, sahneleri yeniden yazın ve stilleri dönüştürün. Atlas Cloud; metinden videoya, 7 adede kadar referans görselle görselden videoya ve referanstan videoya olmak üzere tüm Gemini Omni Flash serisini tek bir birleşik API üzerinden, $0.112'den başlayan şeffaf saniye başı fiyatlandırmayla ve abonelik gerektirmeden sunar. Bugün geliştirmeye başlayın.
Önde Gelen Modelleri Keşfedin
Atlas Cloud size sektörün en yeni ve önde gelen yaratıcı modellerini sunar.







Gemini Omni Flash API ile Üretim Yapmanın Dört Yolu
Metinden videoya ve görüntüden videoya dönüştürmeden referans odaklı üretime ve konuşmaya dayalı düzenlemeye kadar, işinize en uygun Gemini Omni Flash API uç noktasını seçin.
| Modalite | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | Yalnızca bir metin isteminiz mi var? Gemini Omni Flash Text-to-Video API, bunu tek bir seferde senkronize sesli 720p bir klibe dönüştürür ve 10 saniyeye kadar olan klipler için sahne, hareket ve kamera üzerinde akıl yürütme odaklı yönetimi takip eder. |
| Gemini Omni Flash Image-to-Video API (I2V) | Gemini Omni Flash Image-to-Video API, orijinal kaynağı açılış karesi olarak sabitleyerek sabit bir görüntüyü hareketli hale getirir. Doğal hareket ve senkronize ses ile ürün çekimlerine, portrelere ve konseptlere 720p çözünürlükte hayat verir. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Gemini Omni Flash Reference-to-Video API'yi kullanarak en fazla yedi referans görüntü ve üç kısa video klip ile bir üretimi yönlendirin. Klip boyunca karakter, stil ve sahne tutarlılığını korur; markalı içerikler ve dizi içerikleri için idealdir. |
| Gemini Omni Flash Video Edit API | Bir klipte değişiklik yapılması gerektiğinde, Gemini Omni Flash Video Edit API, durumlu (stateful) bir Interactions API aracılığıyla doğal dil komutlarını uygular. Karşılıklı etkileşim turları boyunca görüntülerin geri kalanını sağlam tutarken öğeleri değiştirir, ışıklandırmayı ayarlar ve sahneleri yeniden stillendirir. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
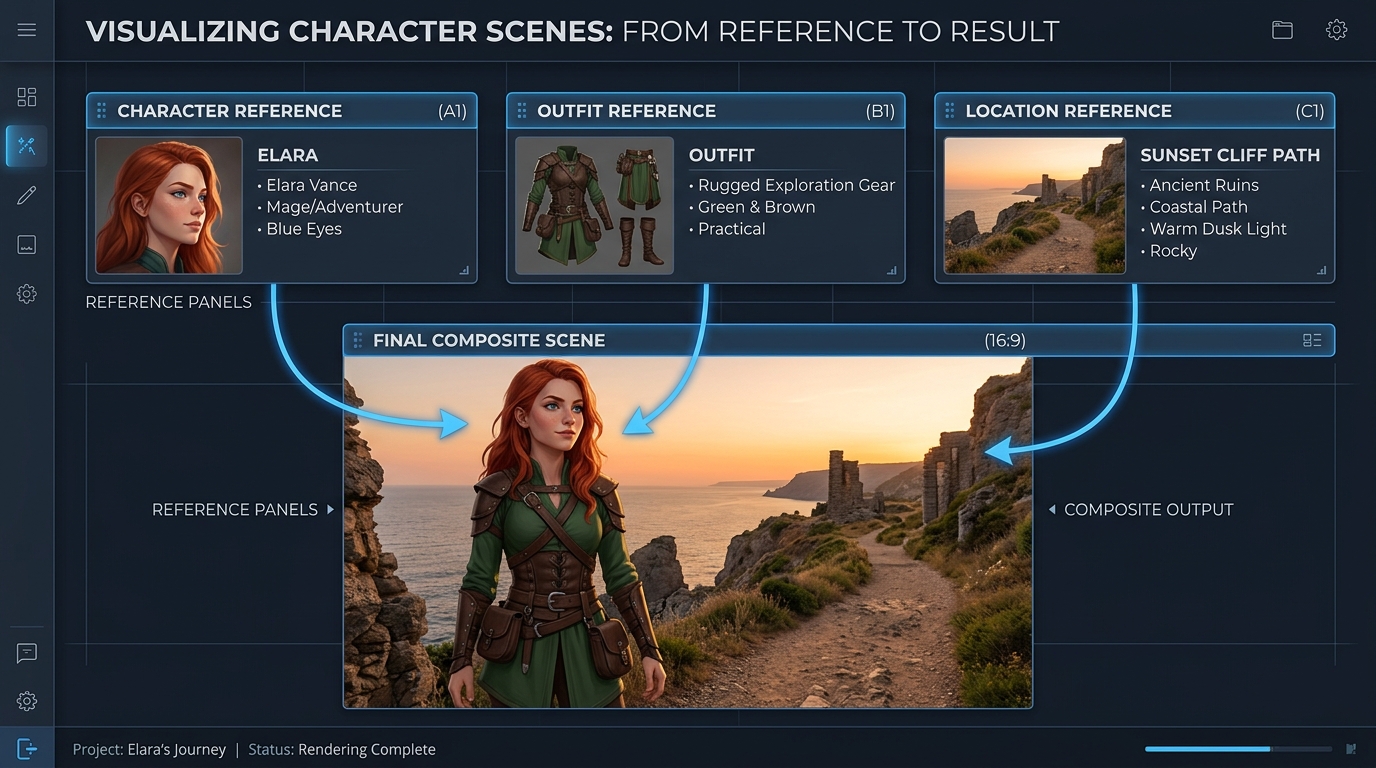
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Gemini Omni Flash API Karşılaştırması
Farklı sağlayıcıların modellerinin nasıl karşılaştırıldığını görün — performans, fiyatlandırma ve benzersiz güçlü yönleri karşılaştırarak bilinçli bir karar verin.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Tamamlanmış videoyu sohbet yoluyla düzenleme | Yes | Evet, durumlu | Metin, görüntü, video, ses |
| Veo 3.1 | Sahne genişletme özellikli sinematik klipler | Yes | No | Metin, görüntü, referans |
| Seedance 2.0 | Referans kontrollü üst düzey kaliteli video | Yes | No | Metin, görüntü, video, ses |
| Kling 3.0 | Çoklu çekim AI yönetmenliğinde hikaye anlatımı | Yes | No | Metin, görüntü, referans |
Atlas Cloud'da Gemini Omni Flash Nasıl Kullanılır
Dakikalar içinde başlayın — Atlas Cloud platformu üzerinden modelleri entegre etmek ve dağıtmak için şu basit adımları izleyin.
Atlas Cloud Hesabı Oluşturun
atlascloud.ai adresinde kaydolun ve doğrulamayı tamamlayın. Yeni kullanıcılar platformu keşfetmek ve modelleri test etmek için ücretsiz kredi alır.
Atlas Cloud'da Gemini Omni Flash'i Neden Kullanmalı
Gemini Omni Flash'in gelişmiş modellerinin Atlas Cloud'un GPU hızlandırmalı platformuyla birleşimi, benzersiz performans, ölçeklenebilirlik ve geliştirici deneyimi sunar.
Performans ve Esneklik
Düşük Gecikme:
Gerçek zamanlı akıl yürütme için GPU optimize çıkarım.
Birleşik API:
Gemini Omni Flash, GPT, Gemini ve DeepSeek'i tek entegrasyonla çalıştırın.
Şeffaf Fiyatlandırma:
Sunucusuz seçeneklerle öngörülebilir token tabanlı faturalandırma.
Kurumsal ve Ölçekleme
Geliştirici Deneyimi:
SDK'lar, analitik, ince ayar araçları ve şablonlar.
Güvenilirlik:
%99,99 kullanılabilirlik, RBAC ve uyumluluk için hazır günlükleme.
Güvenlik ve Uyumluluk:
SOC 2 Type II, HIPAA uyumluluğu, ABD'de veri egemenliği.
Google Gemini Omni Flash API Hakkında Sıkça Sorulan Sorular
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Daha Fazla Aile Keşfedin
Seedance 2.0
Seedance 2.0 API, ByteDance'in çok modlu video modeline üretim düzeyinde erişim sağlar — dört modlu girdiler (metin, görüntü, video, ses) ve çekimler arasında kompozisyonu, kamera hareketini ve karakter eylemlerini kilitleyen endüstri lideri bir "Universal Reference" sistemi. Tek bir API çağrısı, 0,09$/sn sabit ücret, anında anahtar ve bekleme listesi olmadan yönetmen düzeyinde kontrolü entegre edin — kurumsal düzeyde çalışma süresi ve uyumlulukla desteklenir. Seedance 2.0 Native 4K şimdi yayında!
Grok Imagine
Grok Imagine API, geliştiricilere xAI'ın görüntü, video ve ses üretimini tek bir pakette sunar. Çok dilli metin oluşturma özelliğiyle 2K'ya kadar görüntüler ve yerel, senkronize ses ve referans tabanlı düzenleme ile 15 saniyeye kadar videolar üretir. Atlas Cloud üzerinde tek bir anahtar her Grok Imagine modunu çalıştırır, böylece ayrı kurulumlar olmadan görüntü, video ve ses arasında geçiş yapabilirsiniz; görüntü başına 0,02 dolar ve saniye başına 0,05 dolardan başlayan fiyatlarla.
Gemini Omni Flash
Gemini Omni API, Google DeepMind'ın Google I/O 2026'da tanıtılan çok modlu video üretim ve düzenleme modelini stack'inize taşır. Gemini Omni, Gemini'nin akıl yürütme motorunu üretken medyayla birleştirir; metin, görsel, video ve sesin her türlü kombinasyonunu kabul ederek tutarlı ve bilgiye dayalı çıktılar üretir. Sonuçları doğal bir sohbetle iyileştirin: fizik, karakterler ve süreklilik bozulmadan nesneleri değiştirin, sahneleri yeniden yazın ve stilleri dönüştürün. Atlas Cloud; metinden videoya, 7 adede kadar referans görselle görselden videoya ve referanstan videoya olmak üzere tüm Gemini Omni Flash serisini tek bir birleşik API üzerinden, $0.112'den başlayan şeffaf saniye başı fiyatlandırmayla ve abonelik gerektirmeden sunar. Bugün geliştirmeye başlayın.
GPT Image 2
GPT Image 2 API, geliştiricilere GPT Image 1.5'in halefi olan OpenAI'nin en yeni görüntü modeline erişim sağlar. Latin ve CJK alfabelerinde doğru metin oluşturma özelliğiyle görüntüler üretir ve düzenler; ayrıca posterler, maketler ve infografikler için güçlü kompozisyon sunar. Atlas Cloud üzerinde, 300'den fazla modelin yanı sıra tek bir birleşik API aracılığıyla ücretsiz krediler, %99,99 çalışma süresi ve OpenAI organizasyon doğrulaması gerekmeksizin erişebilirsiniz.
Google'ın en güçlü yaratıcı modellerinin tümü Atlas Cloud'da mevcuttur. Veo 3.1 sinematik video üretimi sunar, Nano Banana 2 yüksek sadakatli görüntü oluşturmaya güç katar ve Gemini her iş akışına çok modlu zeka getirir. Day-0 kullanılabilirliği ve kullandıkça öde (pay-as-you-go) fiyatlandırmasıyla tek bir API key üzerinden tüm Google model paketine erişin.
Seedance 2.0 Mini
Seedance 2.0 Mini, ByteDance'in çok modlu video üretimini hız ve maliyetin en önemli olduğu iş akışlarına getiriyor. Seedance 2.0'ın temel yeteneklerini daha hafif bir yapıyla sunar: daha hızlı üretim, video başına daha düşük maliyet ve halihazırda kullandığınız aynı API entegrasyonu. Yüksek hacimli boru hatları çalıştıran veya büyük ölçekte prototip oluşturan ekipler için Mini, pratik bir varsayılan seçenektir.
ByteDance
Sinematik video üretiminden yüksek sadakatli görüntü oluşturmaya kadar, ByteDance'in en güçlü modelleri Atlas Cloud'da yayında. En düşük çıkarım fiyatlandırması ve sıfır altyapı yükü ile Seedance ve Seedream'i geniş ölçekte çalıştırın.
Alibaba
Atlas Cloud, Alibaba'nın tüm model serisini tek bir API altında birleştiriyor: Dil ve görüntü görevleri için Qwen, 1080p'ye kadar video üretimi için Wan. Abonelik gerektirmeden kullandıkça öde (pay-as-you-go) modeliyle her modele erişin. Alibaba API, mevcut OpenAI uyumlu istemcinizi kullanarak tek bir temel URL (base URL) üzerinden kullanılabilir.
OpenAI
Atlas Cloud, görüntü oluşturma için GPT Image 2'den video için Sora 2'ye kadar tüm OpenAI API serisine erişmenizi sağlar. Her model, aylık taahhüt olmaksızın kullandıkça öde (pay-as-you-go) esasına göre sunulmaktadır. OpenAI uyumlu API'yi kullanarak tek bir temel URL değişikliği ile kolayca entegre olun.
xAI
Atlas Cloud üzerinde xAI API kullanarak eksiksiz görüntü ve video işlem hatları oluşturun. 2K çözünürlükte üretim yapın, referans görüntülerle düzenleyin ve görüntüleri sesle senkronize edilmiş kliplere dönüştürerek canlandırın.
Kwaivgi
Standart fiyatlandırmanın %15 altında Kwaivgi API. Atlas Cloud, kullandıkça öde fiyatlandırması ve koltuk sınırı olmaksızın yeni Kling sürümlerine 0. Gün (Day-0) erişimi sunar. Tek hesap, tek anahtar, standarttan master seviyeye kadar her Kling modeli.
Seedream 5.0 Pro
Seedream 5.0 Pro API, geliştiricilere Atlas Cloud üzerinde ByteDance'in kontrol edilebilir görsel düzenleme modelini sunar. Çapalar ve koordinatlarla düzenlemeleri hassas bir şekilde yerleştirir, görselleri düzenlenebilir katmanlara ayırır, birden fazla referansı birleştirir ve 2K ile 3K'da çok dilli metinlerle kesin renk ve materyalleri eşleştirir. Atlas Cloud'da tek bir anahtarla buna erişebilirsiniz!


