MiniMax LLM Models
As a premier suite of Large Language Models (LLMs) developed by MiniMax AI, MiniMax is engineered to redefine real-world productivity through cutting-edge artificial intelligence. The ecosystem features MiniMax M2.5, which is purpose-built for high-efficiency professional environments, and MiniMax M2.1, a model that offers significantly enhanced multi-language programming capabilities to master complex, large-scale technical tasks. By achieving SOTA performance in coding, agentic tool use, intelligent search, and office workflow automation, MiniMax empowers users to streamline a wide range of economically valuable operations with unparalleled precision and reliability.
Erkunden Sie die Führenden Modelle
Atlas Cloud bietet Ihnen die neuesten branchenführenden kreativen Modelle.
Was MiniMax LLM Models Auszeichnet
Atlas Cloud bietet Ihnen die neuesten branchenführenden kreativen Modelle.
Schlussfolgerung auf Frontier-Niveau
Hochmoderne Sprachmodelle, die für tiefgehendes logisches Denken, komplexe Problemlösungen und mehrstufige Planung entwickelt wurden.
Ultra-Langkontext-Verständnis
Lightning-Style Attention und eine optimierte Architektur ermöglichen es MiniMax-Modellen, lange Kontexte zu verarbeiten und zu behalten,
Kosteneffiziente MoE-Leistung
Mixture-of-Experts-Architekturen bieten hohe Intelligenz, geringe Latenz und ein signifikant besseres Preis-Leistungs-Verhältnis.
Vielseitige Modellfamilie
Von leistungsstarken Allzweckmodellen bis hin zu für Coding und Agenten optimierten Varianten.
Unternehmenstaugliche Zuverlässigkeit
Stabile, skalierbare Infrastruktur mit Überwachung und Sicherheit für den Produktionseinsatz.
Offen & entwicklerfreundlich
Umfangreiche APIs, SDKs und Open-Weight-Releases geben Entwicklern die Flexibilität, Modelle zu integrieren, ein Fine-Tuning vorzunehmen oder selbst zu hosten.
Spitzengeschwindigkeit
Niedrigste Kosten
| Modell | Beschreibung |
|---|---|
| MiniMax M2.5 | MiniMax M2.5 ist ein Flaggschiff-LLM, das für die Produktivität in der realen Welt optimiert ist und fortschrittliche Inferenzarchitekturen mit umfassenden 196,61K-Kontextverarbeitungsfunktionen integriert. Mit SOTA-Leistung bei der Büroautomatisierung und intelligenten Suche dient es als hocheffiziente Engine für die Verwaltung wirtschaftlich wertvoller Aufgaben und komplexer allgemeiner Schlussfolgerungen in professionellen Umgebungen. |
| MiniMax M2.1 | MiniMax M2.1 ist ein leistungsstarkes LLM, das speziell für komplexe technische Herausforderungen entwickelt wurde und eine deutlich verbesserte mehrsprachige Programmierung mit einer robusten 196.61K-Kontextverarbeitung integriert; mit außergewöhnlicher Präzision bei der Nutzung von Agentic-Tools dient es als Grundlage für den Aufbau anspruchsvoller Aufgabenplanungs-Agents und die Lösung komplizierter, groß angelegter technischer Probleme. |
| MiniMax M2 | MiniMax M2 ist ein universelles SOTA-LLM, das hocheffiziente Reasoning-Module mit umfassenden 196,61K-Kontextverarbeitungsfunktionen integriert. Mit seiner wettbewerbsfähigen Vielseitigkeit in den Bereichen Coding, Suche und professionelle Arbeitsabläufe dient es als zuverlässiger Eckpfeiler für den täglichen Unternehmensbetrieb, der eine nahtlose Integration der Ausführung mehrstufiger Aufgaben erfordert. |
Neue Funktionen von MiniMax LLM Models + Showcase
Die Kombination fortschrittlicher Modelle mit der GPU-beschleunigten Plattform von Atlas Cloud bietet unübertroffene Geschwindigkeit, Skalierbarkeit und kreative Kontrolle für die Bild- und Videogenerierung.
Fortgeschrittene Programmierung und Agentenplanung mit MiniMax M2.5
MiniMax M2.5 unterstützt über 10 Programmiersprachen, darunter Rust, Go und Python, um eine umfassende Full-Stack-Entwicklung auf Web-, Mobil- und Desktop-Plattformen zu ermöglichen. Durch die Integration tiefgreifender Branchenkenntnisse für professionelle Dokumentenformatierung und Finanzmodellierung ermöglicht es nahtlose Übergänge vom Systemarchitekturdesign bis hin zu abschließenden Produkttests. Es ist die definitive Lösung für komplexe Softwareentwicklung und anspruchsvolle Arbeitsabläufe in der Büroproduktivität.
Schnelle Reaktion und Effizienz bei Aufgabenentscheidungen mit MiniMax M2.5
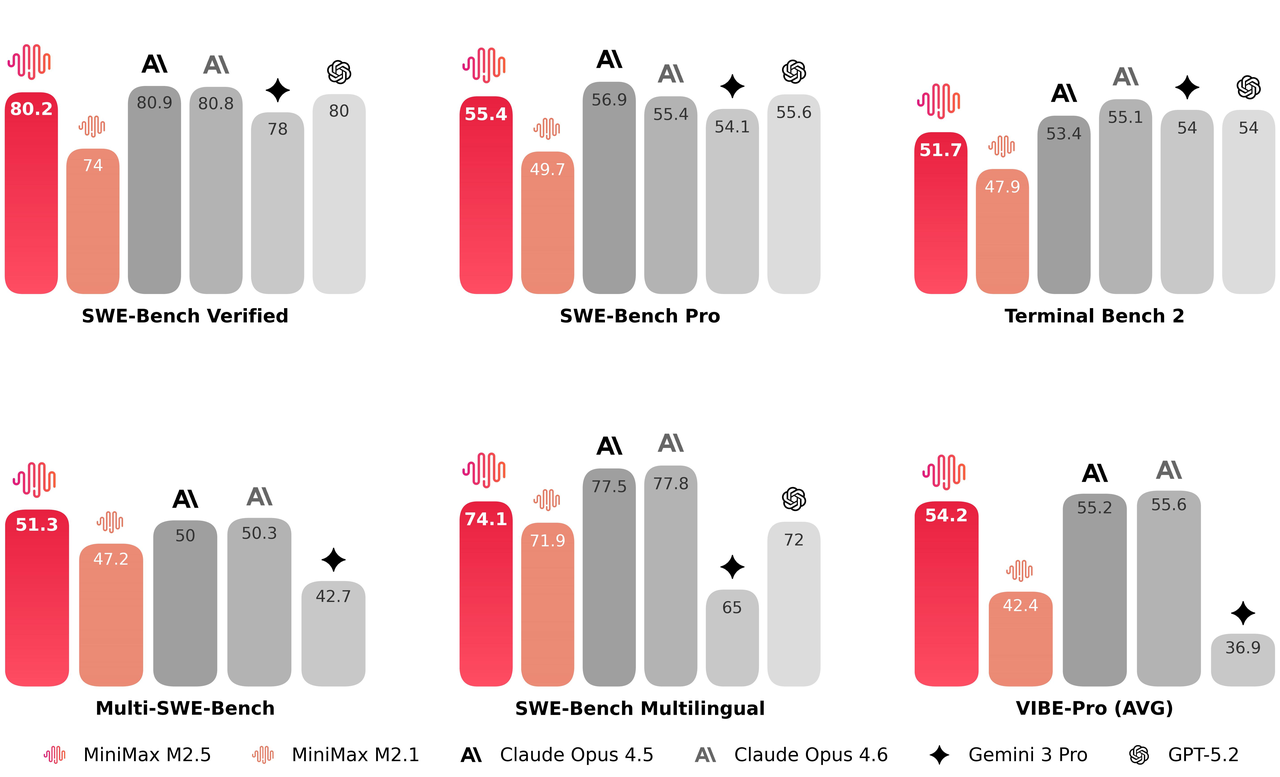
Die M2.5-Architektur erzielt eine Geschwindigkeitssteigerung von 37 % bei der End-to-End-Ausführung und reduziert die Dauer komplexer Aufgaben auf der SWE-bench signifikant von 31,3 auf 22,8 Minuten. Durch die Optimierung der Aufgabenzerlegungslogik benötigt das Modell 20 % weniger Token und Suchrunden, um Ziele in Benchmarks wie BrowseComp zu erreichen. Es bietet eine optimierte Lösung für schnelle Entscheidungsfindung und eliminiert dabei redundanten Rechenaufwand.
Evolutionäre Architektur durch groß angelegtes Reinforcement Learning mit MiniMax M2.5
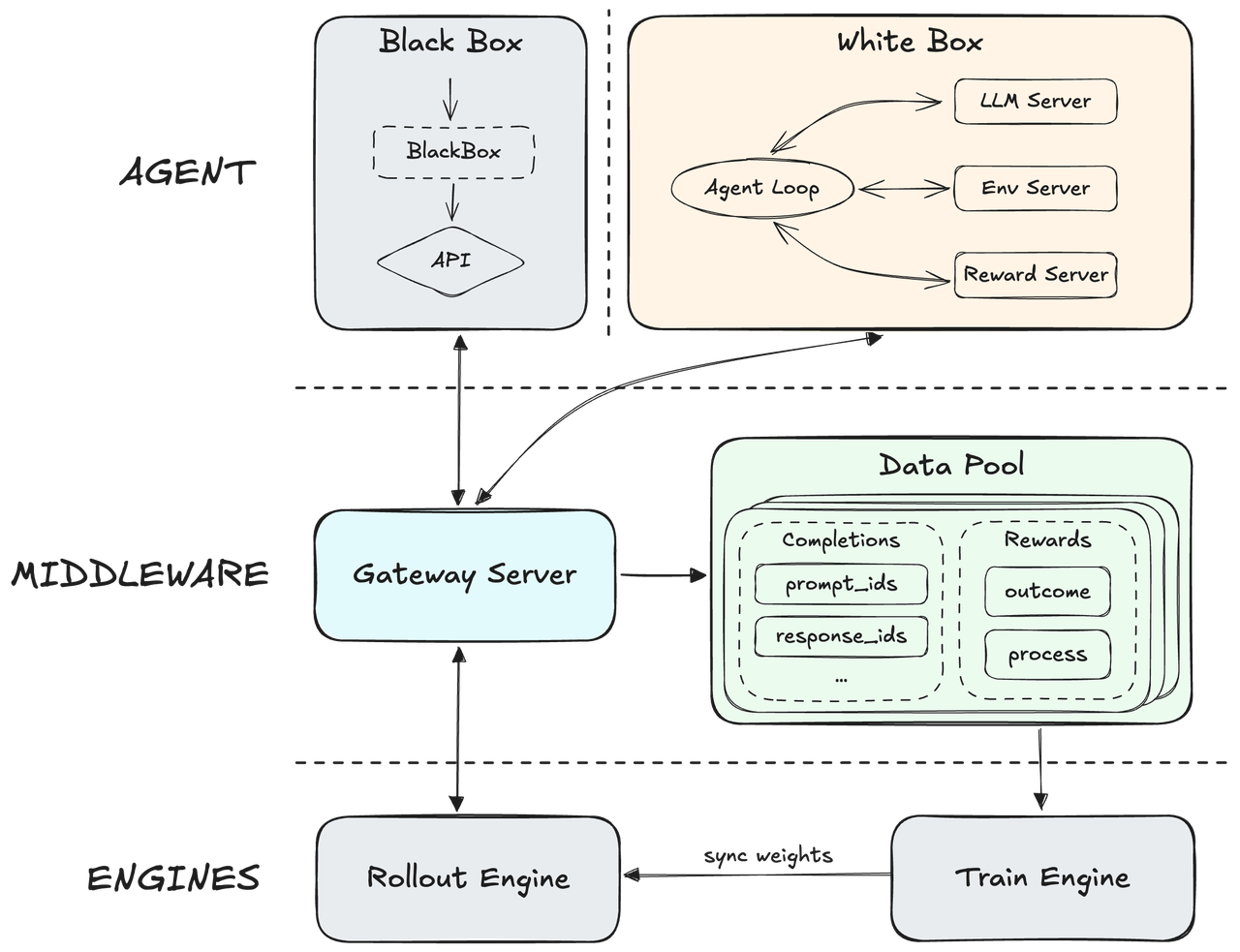
Basierend auf einem nativen Agent-RL-Framework entkoppelt MiniMax seine Core-Engine vom Agent-Scaffolding, um über Hunderttausende verschiedener realer Umgebungen hinweg zu generalisieren. Es integriert einen ausgefeilten Prozessbelohnungsmechanismus, der Echtzeit-Ausführungsfeedback nutzt, um Argumentationspfade zu verfeinern und eine erstklassige Ausgabequalität sicherzustellen. Dies schafft ein hochgradig adaptives System, das in der Lage ist, eine überlegene Genauigkeit beizubehalten und gleichzeitig die gesamte operative Reaktionsgeschwindigkeit zu maximieren.
Was Sie mit MiniMax LLM Models Tun Können
Entdecken Sie praktische Anwendungsfälle und Workflows, die Sie mit dieser Modellfamilie erstellen können — von Content-Erstellung und Automatisierung bis hin zu produktionsreifen Anwendungen.
Produktionsreifes Full-Stack-Debugging mit MiniMax M2.5
MiniMax M2.5 agiert als Senior Technical Architect und spürt Logikfehler in Backend-APIs, Datenbanken und Frontend-Frameworks wie React oder Swift auf. Anstatt einfacher Code-Schnipsel refaktoriert es ganze Module, um systemweite Kompatibilität zu gewährleisten. Ideal für Rapid Prototyping, übernimmt die API alles von der Einrichtung der Umgebung über Edge-Case-Testing bis hin zur Modernisierung von Legacy-Code für Unternehmenssysteme.
Professionelle Finanzmodellierung und Berichterstattung mit MiniMax M2.5
Für Analysten, die absolute Präzision benötigen, automatisiert die API komplexe Excel-Finanzmodellierungen und erstellt publikationsreife Forschungsberichte nach professionellen Investment-Rahmenbedingungen. Sie interpretiert Rohdaten, um Risikokontrolllogiken und professionelle Präsentationen mit standardisierter Formatierung zu erstellen. Dies eignet sich für anspruchsvolle Beratungs- und Bankumgebungen, in denen Genauigkeit und die Einhaltung formaler Berichtsstandards nicht verhandelbar sind.
Autonome mehrstufige Web-Recherche mit MiniMax M2.5
MiniMax M2.5 führt komplexe, mehrstufige Suchaufgaben aus, um disparate Webinformationen zu kohärenten Executive Briefs zusammenzufassen. Durch die intelligente Zerlegung breiter Suchanfragen und das Browsen mit minimaler Token-Redundanz vermeidet es Zirkelschlüsse und liefert verifizierte Fakten. Es ist ein leistungsstarkes Werkzeug für Marktforscher und Strategieteams, die tiefgreifende Informationen benötigen, ohne Hunderte von Quellen manuell filtern zu müssen.
Modellvergleich
Sehen Sie, wie sich Modelle verschiedener Anbieter vergleichen — Leistung, Preise und einzigartige Stärken für eine fundierte Entscheidung.
| Modell | Kontext | Maximale Ausgabe | Eingabe | Positionierung |
|---|---|---|---|---|
| MiniMax M2.5 | 196.61K | 196.61K | Text | Modernste agentenbasierte Programmierung |
| MiniMax M2 | 196.61K | 196.61K | Text | Hochleistungsmodell |
| MiniMax M2 | 196.61K | 196.61K | Text | Flaggschiff Allgemein |
| GLM-5 | 202.75K | 202.75K | Text | Flaggschiff-Basismodell |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flaggschiff Allgemein |
How to Use MiniMax LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Warum MiniMax LLM Models auf Atlas Cloud Verwenden
Die Kombination der fortschrittlichen MiniMax LLM Models-Modelle mit der GPU-beschleunigten Plattform von Atlas Cloud bietet unübertroffene Leistung, Skalierbarkeit und Entwicklererfahrung.
Leistung & Flexibilität
Niedrige Latenz:
GPU-optimierte Inferenz für Echtzeit-Reasoning.
Einheitliche API:
Führen Sie MiniMax LLM Models, GPT, Gemini und DeepSeek mit einer Integration aus.
Transparente Preisgestaltung:
Vorhersehbare Token-basierte Abrechnung mit serverlosen Optionen.
Unternehmen & Skalierung
Entwicklererfahrung:
SDKs, Analysen, Fine-Tuning-Tools und Vorlagen.
Zuverlässigkeit:
99,99% Verfügbarkeit, RBAC und compliance-bereite Protokollierung.
Sicherheit & Compliance:
SOC 2 Type II, HIPAA-Ausrichtung, Datensouveränität in den USA.
Häufig gestellte Fragen zu MiniMax LLM Models
Wir bieten drei Hauptversionen an: MiniMax M2.5 (das Flaggschiff für Büroproduktivität und Suche), MiniMax M2.1 (optimiert für Programmierung und komplexe Logik) und MiniMax M2 (das ausgewogene Allzweckmodell).
Die MiniMax M2-Serie unterstützt einheitlich einen ultralangen Kontext von 196,61K, wodurch sie Hunderte von Seiten technischer Dokumentation oder riesige Engineering-Codebasen in einer einzigen Anfrage verarbeiten kann.
In SWE-bench-End-to-End-Tests reduzierte M2.5 die Bearbeitungszeit für komplexe Aufgaben von 31,3 Minuten auf 22,8 Minuten, was einer Steigerung der allgemeinen Aufgabenerledigungsgeschwindigkeit um 37 % entspricht.
Weitere Familien Erkunden
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
Grok-Imagine Models
Grok Imagine Image Quality is xAI's latest AI image generation model, delivering studio-grade visuals with up to 2K resolution and razor-sharp detail. It offers best-in-class text rendering across multiple languages, photorealistic outputs with natural lighting, rich textures, and believable physics, plus tighter prompt following and image editing with reference inputs for precise creative control. Ideal for hero images, ad creatives, product renders, and brand-grade visuals.
Gemini Omni
Gemini Omni (by Google DeepMind) is a video generation and editing model launched on May 20, 2026 at Google I/O that redefines the standard for "reasoning-driven creation," built specifically to solve the core challenge of AI video: making output that actually understands what you mean, not just what you type. It fuses Gemini's reasoning engine with generative capability, accepting any mix of images, text, video, and audio to produce consistent, knowledge-grounded output. Unlike models that start from scratch each time, Omni lets you edit through natural conversation — swapping objects, rewriting scenes, shifting styles — while keeping physics, characters, and continuity intact across every turn.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.


