AI動画における真のボトルネックは、出力結果が不自然に見えることではありません。「遅い」と感じさせることなのです。
m2TCkQo3cYg
1. AI動画の15秒間が物足りなくなる理由
Seedance 2.0を実際に使い込んだ人なら誰もが直面する壁があります。15秒のクリップを生成しようとすると、モデルは3〜4カットを出力するだけで終わってしまうのです。
格闘シーンを生成させても、「戦士が入場 → 武器を構える → 動きが止まる」という風に、設定・アクション・終了という構成でクレジットが流れて終わってしまいます。
しかし、実際の映像作品における格闘シーンはそのような構成ではありません。パンチが当たる前に肩が入り、回避の後にすぐさま反撃の動作に移る。ワイドショットから超クローズアップへ切り替わり、スローモーションのインパクトへ繋がる。緊張感を生むのは「カットの密度」であり、個々のショットの美しさではないのです。
プロンプトでどう指示しようとも、モデルは自力で16カットものシーンを生成してはくれません。
それが問題の本質です。私たちがどう解決したのかを解説します。
2. ワークフローを変えた3つの視点
シングルキャラクターのアクションデモを一貫して作成する過程で、以下の3つの重要な要素に行き着きました。
① アクションの緊張感はカット密度から生まれる。 個々のショットを完璧にしようとするのはやめましょう。まず15秒間を16分割の絵コンテに分解し、それをビデオモデルに渡すのです。
② GPT Image 2の真の強みは、スタイルの一貫性ではなく「スクリプトの理解とショットのレイアウト」にある。 当初はGPT Image 2で全編にわたり単一のスタイルを維持しようとしました。しかし検証の結果、参照画像から動画への生成過程で自然とCG寄りに寄ってしまい、強制的に合わせるのは不可能だと理解しました。しかし、GPT Image 2はスクリプトを読み取り、ショットを計画し、16分割の絵コンテを作成するという点において、他のモデルにはない並外れた能力を持っています。
③ パイプライン全体が1つのAtlasCloud APIキーで動作する。 GPT Image 2、Nano Banana 2、そしてSeedance 2.0はすべてAtlasCloud上の同じモデルプールに存在します。キーは1つ、エンドポイントも1つ、請求も1つ、クォータも1つ。複数のベンダーを連携させるような複雑な作業は不要です。
3. シングルキャラクターのストレステスト
GPT Image 2を徹底的にテストするため、最も難易度の高いキャラクターを設定しました。
Ranx(ランクス) —— サイバータクティカルオペレーター。砂金色のツインテール。そして4つの完全に非対称な装備を持たせています。
- 右脚のみの黒いニーハイソックス
- 右太もものみの赤いハードシェルホルスター
- 右膝のみのシアン色のパイピング
- ベルトの右後部から左ふくらはぎにかけて回り込む太い黒いコイル
モデルに渡した参照画像は**背面斜め(バック・スリークォーター)**からのショット1枚のみ。モデルはこれをもとに、正面、側面、表情、武器の詳細を導き出す必要があり、かつ4つの非対称な装備を一つとして左右反転させてはならないという条件です。
結果: 生成は1回。ターンアラウンド6枚、頭部スタディ4枚、表情4枚、武器パネル、手、足、すべてを1ページで生成。4つの非対称性はすべて保持され、左右反転もゼロでした。


環境設定としては、完成されたデザインリファレンス(サイバーパンクな濡れた路地裏、Stray風の美学)を使用しました。

4. 手法を証明するA/Bテスト
この実験は本ワークフローの根幹となるものです。同じスクリプト、同じキャラクターシート、同じシーンリファレンスを使用し、唯一の違いは「絵コンテがあるかどうか」だけです。
対照群:文章のプロンプトのみ(絵コンテなし)
Seedance 2.0のリファレンス・トゥ・ビデオへの入力:
- キャラクターシート1枚
- シーンリファレンス1枚
- 4つのハードカットを記述した詳細な15秒間の文章プロンプト
E6uub9qOmFM
映像は読み取れるし、技術的にも問題ありません。しかし、全体として**3つの緩やかな動き(路地への入場、武器を構える、停止)**にしか見えません。格闘シーンではなく、キャラクターデモのように見えてしまいます。
実験群:16分割の絵コンテを使用
GPT Image 2を使用し、同じスクリプトを4×4=16分割の絵コンテに分解させました。各セルには以下の情報をタグ付けしています。
- ショット番号 (① ② ③ … ⑯)
- ショットサイズ (WIDE / MS / CU / ECU)
- カメラワークの矢印 (→ ↘ ↙ ↑ ↓ ↗)
- リズムメモ ("static rise" / "hard cut" / "impact" / "kill shot" / "outro")
- 手書きの中国語による短いディレクターズノート —— 純粋に情報の密度を高める選択です。中国語は限られた絵コンテのセル内に多くの演出意図を詰め込むことができます(GPT Image 2とSeedance 2.0は両言語を同等に理解します)
その後、Seedance 2.0のリファレンス・トゥ・ビデオに1行のプロンプトを入力します。
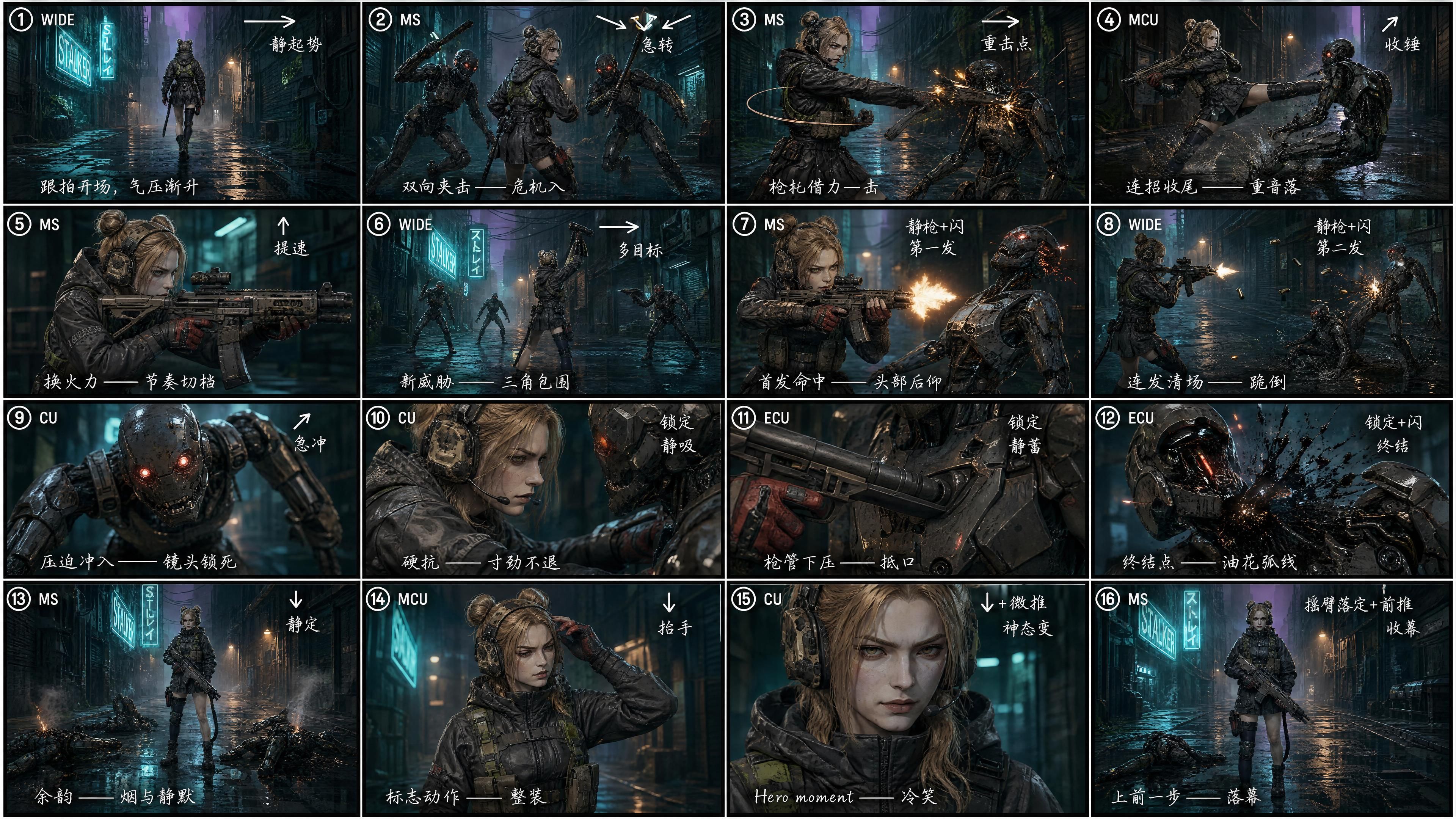
"参照画像3を絵コンテとして厳密に従い、ビデオを生成せよ。強い映画的質感とショット言語、誇張されたダイナミクス、重みのあるアクションを表現すること。"
l-btYYAZfHk
その差は一目瞭然です。カット密度はおよそ4倍に向上しました。ワイドな追跡から、ミドルショットの肩越しカメラ、マズル(銃口)の超クローズアップ、そしてヒーローポーズでのフィニッシュまで——15秒間が完全に詰まっています。スクリプトは同じでも、テンポが全く異なります。前者はデモのように感じられ、後者は予告編のように見えます。
これが本ワークフローのすべてです:GPT Image 2はスタイルを固定するためのものではなく、スクリプトを高密度のショットシーケンスに分解するためのものなのです。
5. スケールアップ:二人の対決
シングルキャラクター版が完成したら、次はデュエル(対決)へとスケールアップします。2人での格闘で最も難しいのは、キャラクターA、キャラクターB、環境、アクションのリズムという4つの要素を同時に固定することです。
4枚の画像を別々に生成して繋ぎ合わせるのではなく、GPT Image 2を使って、これらすべてを1枚の画像内で処理させました。
- キャラクターA (A-27):Ranxの微調整版。砂金色のポニーテール、タクティカルなショートコートを着用。
- キャラクターB:オリジナルの男性傭兵。黒と赤のロングコート、結んだ髪、腰に大剣を帯びている。
- 環境:Ash City と呼ばれる工業地帯の要塞。夕暮れの琥珀色の光、遠くで燃える炉の明かり、煙が充満する空間。
- 10の手書きアクション・ビート:突き → ラッシュ → ブロック → 回避 → フック → カウンター → ピン留め → 膝蹴り → 接近 → 転倒

重要な点:キャラクターAのみ、以前のRanxの参照画像を使用しました。 キャラクターB、環境全体、そして10すべてのアクションビートは、GPT Image 2が自ら設計しました。こちらは雰囲気(バイブス)を記述しただけで、それ以外の細部はモデルが補完しました。
スタイル、キャラクターの個性、環境、そして10のビート——すべてが1回の生成で固定されました。画像間でのズレはなく、途中で衣装が変わることもありません。
そのままSeedance 2.0のリファレンス・トゥ・ビデオへ入力します。
tfYkRiuq-sY
床面に記された二つの陣営の紋章、中盤の組み合い、そして最後の一撃——2人での15秒間の振り付けが一度のパスで完成しました。
6. なぜこのパイプラインが1つのAPIキーで動くのか
これまでの「キャラクター → シーン → 絵コンテ → 動画」というチェーンは、複数のベンダー間でAPIキー、SDK、ドキュメント、支払い、レート制限を管理し、使い分ける必要がありました。
AtlasCloudでは、すべてが1つのエンドポイントの背後に統合されています。
| 工程 | モデル | プラットフォーム |
|---|---|---|
| キャラクターシート | GPT Image 2 | AtlasCloud |
| シーンコンセプト | Nano Banana 2 | AtlasCloud |
| 絵コンテ | GPT Image 2 | AtlasCloud |
| 動画 | Seedance 2.0 | AtlasCloud |
キーは1つ、エンドポイントは1つ、クォータも1つ、請求も1つ。統合と運用負荷はほぼゼロまで下がります。
7. 結論:モデル間のスタイル統一に固執せず、各モデルの強みを活かそう
私たちは、プロセスの全ステップで単一のスタイルを維持しようと懸命に努力しました。しかし、リファレンス・トゥ・ビデオモードにおいては、その戦いに勝つことはできません。スタイルの一貫性を強く求めすぎると、かえって出力結果が悪化してしまいます。
その目標を手放したとき、ワークフローが一気に開けました。各モデルの得意分野に集中させるのです。
- GPT Image 2 — スクリプトを分解し、ショットをレイアウトする。
- Seedance 2.0 — 時間を展開し、アクションを描画する。
- AtlasCloud — 1つのキーで、1つのチェーンを構築する。
もしあなたがAIを使ってアクションショートムービーや格闘シーン、デュエルの振り付けを作成しているのなら、このワークフローを強くおすすめします。
試してみる
すべてのモデルは同じAtlasCloudモデルプール内にあり、1つのAPIキーでチェーン全体を実行できます:
- Seedance 2.0 (リファレンス・トゥ・ビデオ) → atlascloud.ai/collections/seedance2
- GPT Image 2 (キャラクターシート + 絵コンテ) → atlascloud.ai/collections/gpt-image-2
- Nano Banana 2 (シーンコンセプト) → atlascloud.ai/collections/nanobanana-2
ステップバイステップの手順と、この記事で使用したすべてのプロンプトは、YouTubeの動画ウォークスルーでも公開されています。
さあ、何か作り出しましょう。






