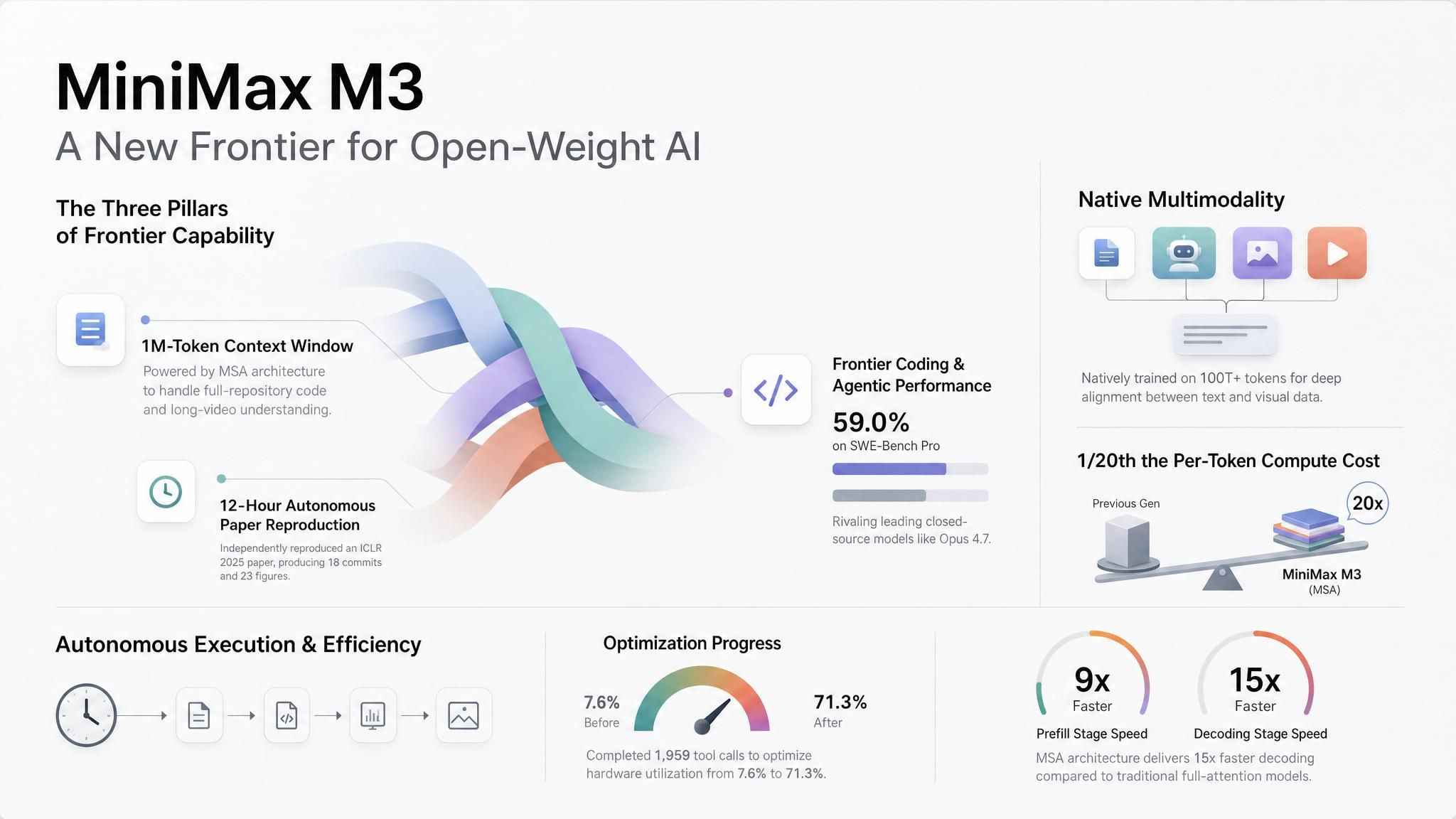
O MiniMax M3 foi lançado e aqui está o resumo: use-o se você precisa de um modelo com pesos abertos que processe imagens e vídeos nativamente, suporte um milhão de tokens de contexto por um custo baixo e execute loops longos de codificação e agentes sem resetar. Esse é o caso de uso principal e, se você tem agentes rodando autonomamente enquanto você dorme, recomendamos testá-lo! O M3 já está disponível no Atlas Cloud.
Se você não trabalha com agentes de longa execução, o M3 ainda vale a pena pelo direcionamento que a MiniMax tomou para chegar lá. Eles mantiveram 1M de contexto acessível com uma arquitetura de atenção esparsa (MiniMax Sparse Attention, ou MSA) que reduz o processamento por token para aproximadamente 1/20 da geração anterior em contexto completo — e fizeram isso escolhendo o caminho mais barato que roda na stack de servimento atual, não o mais exótico. Esperamos que essa seja a direção padrão de todos os grandes provedores: contexto longo e barato através de atenção esparsa ou comprimida. Isso transforma a janela de 1M de um diferencial em pré-requisito, elevando a competição para um nível acima: quão bem você roteia entre modelos, e não em qual modelo único você aposta.
A MiniMax anunciou o M3 em 1 de junho de 2026. A API já está disponível, e a empresa afirma que publicará o relatório técnico e os pesos em cerca de 10 dias após o anúncio.
Se você já utiliza outro modelo de fronteira atualmente
O M3 vale o teste quando o trabalho exige um conjunto de dados maior, contexto visual ou um loop de agente mais longo do que o seu modelo padrão lida bem. A coluna que importa é a última: o que o M3 adiciona de fato sobre o modelo que você já usa.
| Se você usa hoje | Para este trabalho | O que o M3 adiciona de fato |
|---|---|---|
| GPT-5.5 ou GPT-5.5 Pro | Codificação agente, uso de computador, pesquisa, análise de dados e automação de tarefas intelectuais | Entrada de vídeo nativa e um caminho de pesos abertos anunciado — uma segunda rota de agente com curva de custo diferente que você pode auto-hospedar futuramente. (O GPT-5.5 já tem visão de imagem, então teste vídeo e economia, não suporte a imagem.) |
| Claude Opus 4.8 | Agentes de codificação de longa duração, trabalho intelectual com alta carga de recuperação (retrieval) e uso de ferramentas | Uma alternativa de pesos abertos e menor custo para A/B em codificação de repositórios completos e custo por tarefa concluída. O Opus 4.8 já oferece janela de 1M e visão, então o teste real é preço, entrada de vídeo e economia de tarefas — não o tamanho da janela. |
| Qwen3.7-Plus (multimodal) | Agentes de visão e GUI, screenshot-para-código, automação de navegador e desktop | Multimodalidade comparável com posicionamento mais forte em codificação/agentes e um caminho de pesos abertos. (O Qwen3.7-Plus é proprietário, apenas via API.) |
| Qwen3.7-Max (flagship só texto) | Raciocínio textual, agentes de longo prazo, automação de escritório | Entrada nativa de imagem e vídeo no mesmo contexto. O Qwen3.7-Max é apenas texto — para visão, você teria que mudar para o Plus. |
| DeepSeek-V4-Pro ou DeepSeek-V4-Flash | Raciocínio sensível a custo, codificação, chamadas de ferramenta e cargas de API de contexto longo | Multimodalidade nativa (imagem e vídeo) além do contexto longo. O DeepSeek-V4 é apenas texto, portanto, o M3 é a alternativa multimodal quando a carga de trabalho envolve sinal visual. |
O teste prático é simples. Tente o M3 se você está tentando:
- manter o repositório, histórico de tarefas, logs e plano atual em um único contexto de trabalho;
- permitir que um agente continue após dezenas de chamadas de ferramenta em vez de reiniciar a conversa;
- raciocinar sobre código, texto, screenshots, gráficos, PDFs e frames de vídeo em uma única passagem;
- reduzir as transferências entre um modelo de texto, um modelo de visão e uma camada de recuperação separada;
- comparar o custo de contexto longo por tarefa concluída, não apenas o preço por milhão de tokens.
Não mude apenas porque um gráfico de lançamento parece bom. Mude quando o M3 completar uma tarefa que sua stack de roteamento atual descarta, trunca, cobra caro demais ou divide entre muitos modelos.
Onde o M3 ajuda
Agentes com espaço para trabalhar. Os exemplos de lançamento da MiniMax superam o padrão comum de chat-demo. Em um teste, o M3 reproduziu os experimentos principais de um artigo premiado do ICLR 2025 após rodar por quase 12 horas. Produziu 18 commits e 23 figuras experimentais. Em outro, trabalhou por cerca de 24 horas em um kernel CUDA FP8 GEMM, fez 147 submissões de benchmark e 1.959 chamadas de ferramenta, elevando a utilização de hardware de 7,6% para 71,3%.
Não interprete esses exemplos como prova de que um agente de um dia inteiro funcionará no seu primeiro prompt. Eles mostram por que o M3 deve estar na lista de curadoria para fluxos de trabalho onde o modelo precisa planejar, rodar ferramentas, inspecionar resultados, revisar e continuar após uma tentativa inicial falha.
Contexto em escala de repositório e documento. O M3 suporta até 1M de tokens via API, com a MiniMax garantindo 512K como mínimo garantido. Com 1M de contexto, a MiniMax reporta um custo computacional por token de 1/20 da geração anterior, com prefill mais de 9x mais rápido e decodificação mais de 15x mais rápida.
Isso altera o design do produto. Um agente de codificação pode ver mais do repositório. Um assistente de pesquisa pode carregar uma trilha de evidências mais longa. Uma ferramenta de revisão de contratos pode manter o material de origem e a análise no mesmo conjunto de trabalho. A recuperação (retrieval) ainda tem seu lugar, mas o modelo não precisa mais começar de uma pequena fatia do problema.
Contexto visual na mesma requisição. A MiniMax treinou o M3 com dados multimodais desde o início. O modelo aceita entrada de imagem e vídeo, e a MiniMax diz que ele pode lidar com texto, imagens e vídeo intercalados em um único contexto.
Isso reduz as transferências entre modelos. Um fluxo de suporte pode ler a mensagem do usuário e inspecionar o screenshot. Um fluxo de pesquisa pode raciocinar sobre gráficos dentro de um artigo. Um agente de uso de computador pode olhar para a tela e decidir a próxima ação sem enviar o passo visual para um modelo separado primeiro.
Acesso hospedado agora, pesos em breve. A MiniMax está tratando o M3 como um lançamento de pesos abertos, mas o primeiro caminho de lançamento é acesso via API hospedada. Isso dá às equipes uma sequência útil: testar o modelo hospedado agora e decidir se o lançamento posterior dos pesos se encaixa em implantação privada, fine-tuning ou avaliação interna.
Uma fronteira de preço clara. A MiniMax diz que chamadas de API com até 512K tokens de entrada usam a taxa padrão. O preço de contexto longo começa acima de 512K, onde as equipes geralmente estão rodando cargas de trabalho de repositório completo, documentos completos ou vídeos longos. O M3 também suporta um seletor de "pensamento" (thinking toggle) pelo mesmo preço, para que as equipes possam usar o modo de raciocínio para trabalhos de agente mais difíceis e um modo mais rápido para conclusões sensíveis à latência.
Como é o custo operacional
O MiniMax M3 no Atlas Cloud custa USD0.30/M tokens de entrada e USD1.20/M tokens de saída. O Claude Opus 4.7 custa USD5/M entrada e USD25/M saída, enquanto o GPT-5.5 custa USD5/M entrada e USD30/M saída.
Isso torna o M3:
- 94% mais barato na entrada do que o Opus 4.7 e o GPT-5.5;
- 95,2% mais barato na saída do que o Opus 4.7;
- 96% mais barato na saída do que o GPT-5.5.
O preço do token só importa depois que você o mapeia para o formato da carga de trabalho. Um agente de codificação com um repositório grande em contexto gasta a maior parte do dinheiro em entrada. Um fluxo de pesquisa ou redação com explicações longas gasta mais em saída. Um agente de GUI multimodal também paga pelo contexto visual, e a conversão de tokens depende do provedor.
Use a tabela abaixo como uma referência de taxas, não um benchmark. Ela assume preços em USD, sem hits de cache, sem descontos por lote, sem prêmios regionais, sem taxas de chamada de ferramenta e sem novas tentativas. Para o GPT-5.5, a OpenAI diz que prompts acima de 272K tokens de entrada são cobrados a 2x entrada e 1,5x saída para a sessão completa, portanto, o exemplo de contexto longo usa essa taxa efetiva mais alta.
| Modelo | Taxa utilizada | 100K entrada + 5K saída | 500K entrada + 20K saída | Leitura de custo |
|---|---|---|---|---|
| MiniMax M3 no Atlas Cloud | $0.30 / $1.20 | $0.04 | $0.17 | Rota multimodal de baixo custo. Mais caro que o DeepSeek Flash, mas muito abaixo dos preços de fronteira fechados. |
| DeepSeek V4 Flash | $0.14 / $0.28 | $0.02 | $0.08 | Rota nomeada mais barata para trabalho de alto volume apenas texto. Use quando a entrada visual não faz parte da tarefa. |
| DeepSeek V4 Pro | $0.435 / $0.87 | $0.05 | $0.23 | Próximo ao M3 no custo puro por token, mas apenas texto. Melhor comparação para raciocínio e codificação sem contexto visual. |
| Qwen3.7-Plus | $0.40 / $1.60 até 256K; $1.20 / $4.80 acima 256K | $0.05 | $0.70 | Competitivo para chamadas multimodais curtas. O preço de contexto longo muda a economia acima de 256K. |
| Qwen3.7-Max | $2.50 / $7.50 | $0.29 | $1.40 | Mais barato que GPT e Claude, mas não é um padrão de volume, a menos que vença a tarefa. |
| Claude Opus 4.8 | $5 / $25 | $0.63 | $3.00 | Rota premium para codificação de alto risco, uso de ferramentas e confiabilidade de contexto longo. |
| GPT-5.5 | $5 / $30 std; $10 / $45 acima 272K | $0.65 | $5.90 | Use quando o uso de ferramentas do modelo, comportamento de computador ou eficiência de tokens compensar o prêmio. |
| GPT-5.5 Pro | $30 / $180 | $3.90 | $18.60 | Reserve para os trabalhos mais difíceis. A taxa coloca em uma classe de orçamento diferente. |
A leitura de custo: o M3 não é o modelo de texto mais barato da lista. O DeepSeek V4 Flash ainda vence se a carga de trabalho for apenas texto, de alto volume e tolerante ao nível de capacidade Flash. O argumento de custo do M3 é diferente: ele coloca entrada nativa de imagem e vídeo, longo contexto de trabalho e codificação de agente em uma faixa de preço próxima ao DeepSeek V4 Pro e muito abaixo do GPT-5.5, GPT-5.5 Pro e Claude Opus 4.8.
Para uma rodada de agente de 500K de entrada e 20K de saída, o M3 é cerca de 17x mais barato que o Claude Opus 4.8 e cerca de 34x mais barato que o GPT-5.5 quando o multiplicador de contexto longo da OpenAI é aplicado. É cerca de 4x mais barato que o Qwen3.7-Plus nesse tamanho de requisição e cerca de 8x mais barato que o Qwen3.7-Max. Contra o DeepSeek, a resposta depende da modalidade: o DeepSeek V4 Flash ainda é mais barato, enquanto o V4 Pro fica na mesma faixa ampla. Se a tarefa tiver screenshots, gráficos, estado de UI ou frames de vídeo, o M3 pode evitar o passo extra de roteamento para um modelo de visão separado.
Em escala mensal, a diferença é mais clara. Uma carga de trabalho com 10M de tokens de entrada e 1M de saída custa cerca de USD4.20 no M3, USD1.68 no DeepSeek V4 Flash, USD5.22 no DeepSeek V4 Pro, USD75 no Claude Opus 4.8, USD80 no GPT-5.5 em taxas padrão e USD480 no GPT-5.5 Pro. O Qwen3.7-Plus fica entre USD5.60 e USD16.80, dependendo se cada requisição fica abaixo ou acima do limite de preço de 256K; o Qwen3.7-Max fica em torno de USD32.50.
Nossa recomendação: Trate os modelos caros como rotas que precisam merecer seu lugar. Se o GPT-5.5 ou Opus 4.8 termina uma tarefa difícil em uma execução enquanto o M3 precisa de três tentativas e um ajuste humano, a chamada barata não foi barata. Se a tarefa é análise multimodal de contexto longo, triagem de codificação em escala de repositório, automação de tickets de suporte com screenshots ou trabalho documental onde o M3 atinge o nível de qualidade, sua economia o torna um candidato sério de roteamento, em vez de apenas uma curiosidade de semana de lançamento.
Leia os benchmarks como dados de fornecedores
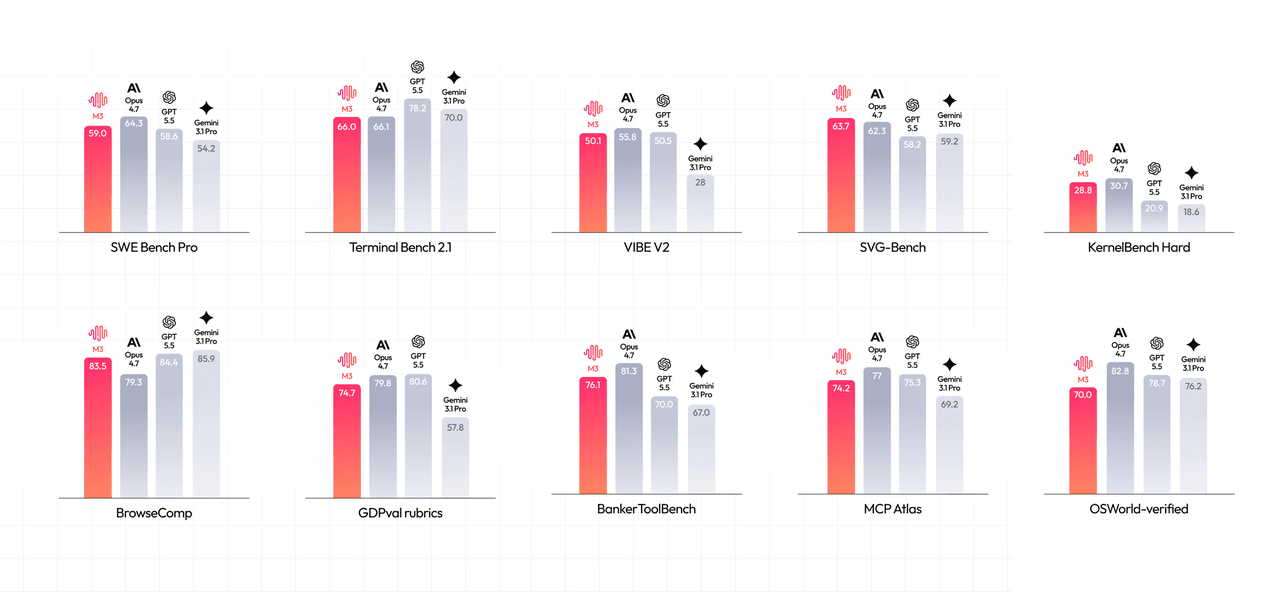
A MiniMax reporta pontuações fortes em tarefas de codificação e agente:
- SWE-Bench Pro: 59,0%
- Terminal-Bench 2.1: 66,0%
- SWE-fficiency: 34,8%
- KernelBench Hard: 28,8%
- MCP-Atlas (um benchmark de uso de ferramenta MCP de terceiros — não relacionado ao Atlas Cloud): 74,2%
- BrowseComp: 83,5, comparado com 79,3 para Claude Opus 4.7 na comparação da MiniMax
Uma nota sobre a última linha: a MiniMax faz o benchmark do M3 contra o Opus 4.7, mas o Opus 4.8 foi lançado em 28 de maio, quatro dias antes do lançamento do M3. A comparação de lançamento já estava uma versão atrasada no primeiro dia — um pequeno detalhe, mas um vislumbre do ponto principal abaixo.
No PostTrainBench, que pede ao modelo para sintetizar dados, treinar, avaliar e iterar em quatro modelos base dentro de uma janela de 12 horas, a MiniMax reporta o M3 com 0,37 na postagem de lançamento, equivalente à pontuação 37,1 mostrada em sua página de modelo. Isso fica atrás do Opus 4.7 com 0,42 e do GPT-5.5 com 0,39, mas à frente do restante do campo reportado.
Essas pontuações são úteis para triagem. Elas não são suficientes para uma decisão de produção. A MiniMax rodou muitos dos testes em sua própria infraestrutura, e várias avaliações usaram scaffolds específicos. Antes de uma equipe usar uma pontuação em um deck de vendas ou decisão de arquitetura, ela deve rodar novamente a tarefa contra seu próprio código, documentos, prompts, alvos de latência e orçamento.
Como avaliar o M3 contra modelos de fronteira atuais
Use o M3 como um candidato de avaliação, não como um padrão. Uma janela de 1M de tokens pode esconder uma arquitetura ruim se você a preencher com arquivos irrelevantes, logs obsoletos ou todas as mensagens que o usuário já enviou.
Execute o mesmo conjunto de testes contra o GPT-5.5, Claude Opus 4.8, Qwen3.7-Plus ou Max, DeepSeek-V4-Pro ou Flash e M3. Em seguida, compare os resultados por tarefa, não pela reputação do provedor.
Comece com seis testes:
- Codificação de repositório completo: Dê a cada modelo o mesmo problema, fatia de repositório, acesso a ferramentas e tempo limite. Pontue a qualidade do patch, taxa de aprovação de testes, tamanho do diff e edições desnecessárias.
- Recuperação de contexto longo: Coloque detalhes relevantes no início, meio e fim do contexto. Adicione distratores semelhantes. Verifique se cada modelo recupera a instância correta, não apenas qualquer frase correspondente.
- Resistência de loop de ferramentas: Execute uma tarefa que precisa de 30, 60 e 100+ chamadas de ferramentas. Observe se cada modelo mantém um plano estável, se repete, perde restrições anteriores ou para antes que a tarefa seja concluída.
- Trabalho de agente visual: Dê a cada modelo multimodal um ticket de suporte com screenshots, um artigo com gráficos ou uma especificação de produto com capturas de tela de UI. Para rotas apenas de texto ou de visão mais fraca, meça o custo extra de transferência para um modelo de visão separado.
- Latência sob contexto real: Compare o tempo para o primeiro token e o tempo total de conclusão em 128K, 512K e 1M de tokens de entrada. Não aceite uma alegação de janela de 1M sem dados de latência.
- Custo por tarefa concluída: Meça tokens de entrada, tokens de saída, novas tentativas, chamadas de ferramenta, hits de cache, latência e correção humana. Uma chamada de modelo mais barata ainda pode custar mais se precisar de três novas tentativas.
É aqui que a maioria das equipes erra a questão do modelo. Elas perguntam qual modelo tem o melhor benchmark de lançamento. A questão de produção é mais estreita: qual modelo completa este fluxo de trabalho na qualidade, latência e custo que seu produto pode tolerar?
Como a MSA mantém o contexto longo utilizável
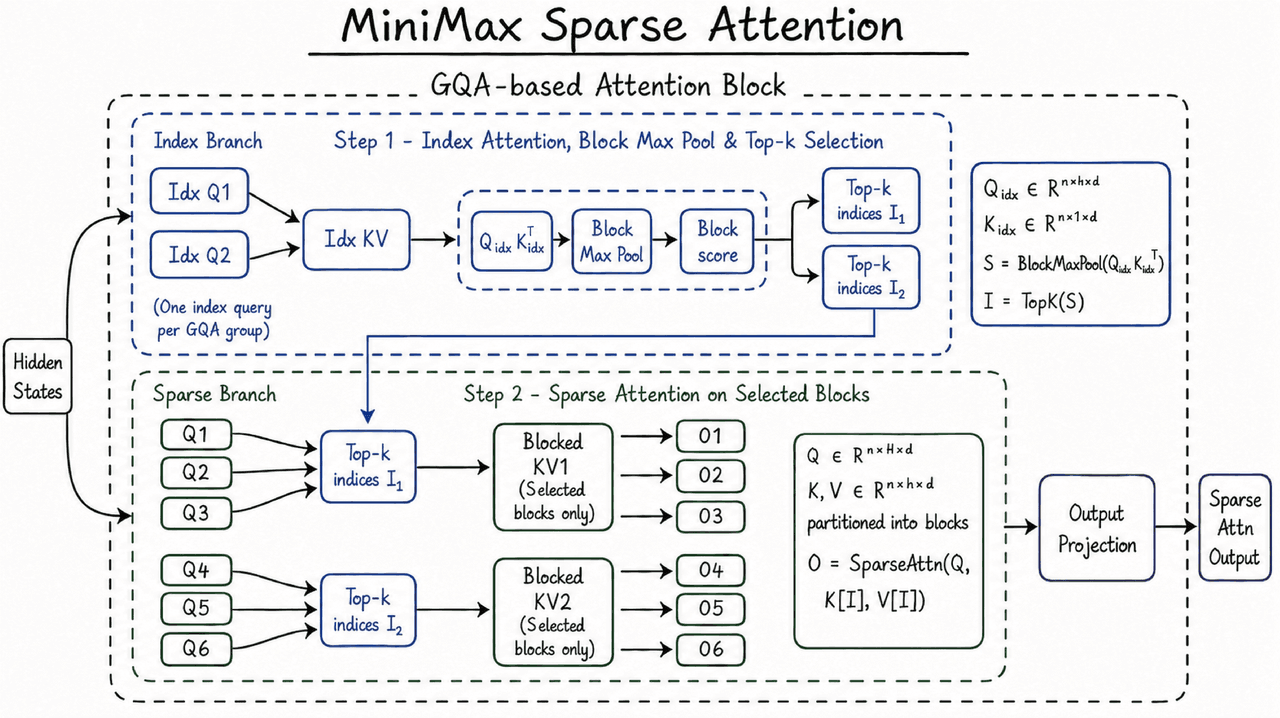
A janela de contexto do M3 depende da MiniMax Sparse Attention, ou MSA.
A atenção completa permite que cada token atenda a cada outro token. À medida que a sequência se torna mais longa, o trabalho cresce com o quadrado do comprimento da sequência. A atenção esparsa adiciona um passo de seleção e, em seguida, executa a atenção sobre as partes do contexto anterior que mais importam.
A MiniMax diz que a MSA particiona o KV cache em blocos e seleciona no nível do bloco. O KV cache armazena os vetores de chave e valor de tokens anteriores, e impulsiona uma grande parte do tráfego de memória na inferência de contexto longo. A MiniMax também descreve um design de operador chamado "KV outer gather Q": os blocos KV tornam-se o loop externo, as consultas que atingem um bloco são reunidas nele, cada bloco é lido uma vez e o acesso à memória permanece contíguo.
Na postagem de lançamento da MiniMax, esse design roda mais de 4x mais rápido que o Flash-Sparse-Attention de código aberto e o flash-moba sob a configuração de heads do M3. A MiniMax também diz que a MSA igualou a atenção completa na grande maioria das ablações.
A afirmação de engenharia importa porque uma janela de 1M de tokens não tem valor se as equipes não puderem pagar para usá-la. A MSA é a razão pela qual a MiniMax pode argumentar que o contexto longo faz parte do modelo operacional normal do M3, não um modo de demonstração único. Também não é única: o V4 do DeepSeek traz um híbrido de Compressed Sparse Attention e Heavily Compressed Attention pelo mesmo motivo. Contexto longo e barato está se tornando um padrão arquitetural.
A tendência maior: lançamentos de modelos estão se tornando eventos de roteamento
O M3 não é um lançamento isolado. Ele se encaixa em um padrão que vem se consolidando em todo o mercado.
A tendência mais clara é o calendário. Em cerca de seis semanas, quatro modelos de 1M de contexto foram lançados:
- DeepSeek V4-Pro e V4-Flash — 24 de abril, pesos abertos, 1M de contexto, modos de pensamento/não-pensamento.
- Qwen3.7-Max — 20 de maio, flagship de raciocínio apenas texto, 1M de contexto (o Qwen3.7-Plus multimodal seguiu no início de junho).
- Claude Opus 4.8 — 28 de maio, com uma janela de 1M de contexto para a família Opus.
- MiniMax M3 — 1 de junho, 1M de contexto mais multimodalidade nativa e um caminho de pesos abertos.
Uma janela de um milhão de tokens passou de diferencial para pré-requisito em um único trimestre. O mesmo está acontecendo com a atenção esparsa, seletores de pensamento, benchmarks de agentes e preços de contexto longo em níveis. Espere que as páginas de modelos continuem convergindo para os mesmos recursos de destaque.
O ritmo também supera o marketing. Os benchmarks de lançamento do próprio M3 da MiniMax comparam contra o Opus 4.7, mas o Opus 4.8 foi lançado quatro dias antes. O modelo que você usou como benchmark na semana passada não é o modelo que seu concorrente está rodando nesta semana. Esse é o mundo dos eventos de roteamento em um exemplo.
Isso não torna o M3 irrelevante, mas muda o que os desenvolvedores devem otimizar.
A vantagem do modelo decairá mais rápido do que o trabalho de integração em torno dele. Se uma equipe codifica um provedor em sua stack de agentes, cada grande lançamento se torna um projeto de migração. Se uma equipe roteia por tarefa, preço, latência, modalidade e resultado de avaliação, cada grande lançamento se torna uma atualização de roteamento.
O vencedor não é a equipe que escolhe um modelo e o defende por um ano. O vencedor é a equipe que pode testar o M3 hoje, compará-lo contra o GPT-5.5, Claude Opus 4.8, Qwen3.7 e DeepSeek-V4 amanhã, e mover o tráfego quando os números disserem para mover.
O que outros provedores podem copiar, e o que não podem
Os provedores podem copiar a superfície primeiro:
- janelas de contexto mais longas;
- variantes de atenção esparsa;
- modos de pensamento ligado/desligado;
- páginas de benchmark de agente de codificação;
- demonstrações de lançamento multimodal;
- mensagens de pesos abertos ou próximos a pesos abertos.
As partes mais difíceis levam mais tempo:
- servimento estável de contexto longo sob concorrência real;
- qualidade profunda no contexto, especialmente com distratores;
- confiabilidade de agente após muitas chamadas de ferramenta;
- alinhamento multimodal entre texto, imagens, gráficos e vídeo;
- precificação que se sustenta quando os clientes usam toda a janela;
- IDs de modelo claros, versionamento e fallbacks em que equipes de produção podem confiar.
Essa lacuna é onde as equipes de desenvolvimento devem gastar seu tempo de avaliação. Não pergunte apenas se outro provedor pode anunciar uma janela de 1M. Pergunte se o modelo ainda segue a instrução enterrada no token 750.000, se pode comparar dois screenshots semelhantes sem desviar, se a latência permanece aceitável e se a economia sobrevive ao tráfego real de usuários.
Por que rodá-lo pelo Atlas Cloud
O Atlas Cloud oferece às equipes uma única chave de API para mais de 300 modelos em cargas de trabalho de LLM, imagem, vídeo e áudio. Isso importa mais à medida que os lançamentos de modelos convergem para os mesmos recursos de destaque.
Você pode testar o M3 contra os modelos já na sua stack, rotear o tráfego para onde ele tem melhor desempenho e manter a superfície de integração estável à medida que novos lançamentos chegam. Você pode manter o GPT-5.5 onde ele vence em trabalho de uso de computador, manter o Claude Opus 4.8 onde ele vence em agentes de codificação de longa duração, usar o Qwen3.7-Plus onde agentes de GUI multimodal vencem, usar o DeepSeek-V4 onde a relação preço/desempenho vence e adicionar o M3 onde contexto longo mais multimodalidade nativa muda o resultado.
Use o M3 onde seu contexto longo e multimodalidade se pagam. Mantenha outros modelos onde eles ainda vencem. Troque com base em avaliações, não no hype de semana de lançamento.
[CTA - intenção do desenvolvedor: Rodar M3 no Atlas Cloud -> atlascloud.ai/models | Obter uma chave de API -> console.atlascloud.ai]






