RSpqXx0wq8Q
Em 19 de maio de 2026, no Google I/O, a DeepMind lançou o Gemini Omni. No mesmo dia, o guia de prompts do Gemini Omni foi disponibilizado no site de documentação da DeepMind, posicionado entre o cartão de modelo do Omni Flash e as notas da API. A maioria das pessoas assistiu às demos do keynote; o documento passou quase despercebido.
Primeiro, os fatos rápidos. O Gemini Omni é o novo modelo de geração multimodal da DeepMind. O primeiro produto, Gemini Omni Flash, gera vídeos de até 10 segundos a partir de qualquer combinação de entradas de texto, imagem, áudio ou vídeo. Cada saída traz uma marca d'água SynthID. Assinantes do AI Plus, AI Pro e AI Ultra receberam acesso imediato; usuários do YouTube Shorts e do app YouTube Create recebem acesso gratuito a partir desta semana de lançamento (relato do Gagadget). O acesso à API estará disponível "em semanas", segundo o Google.
Voltando ao guia de prompts. O guia da Google DeepMind descreve a mudança diretamente, na seção "World understanding" (compreensão de mundo):
Com o Veo, você precisa compartilhar instruções precisas para obter os melhores resultados. Mas com o Gemini Omni, você não precisa ser tão prescritivo com seu prompt. Em vez disso, diga ao Omni o que você deseja criar – e observe o raciocínio e o conhecimento de mundo do modelo darem vida aos detalhes.
A tradução: escreva menos.
Leia isso em paralelo com os guias de prompt que a ByteDance e a Kuaishou publicam para seus próprios modelos de vídeo. As estruturas diferem, mas apontam para a mesma direção.
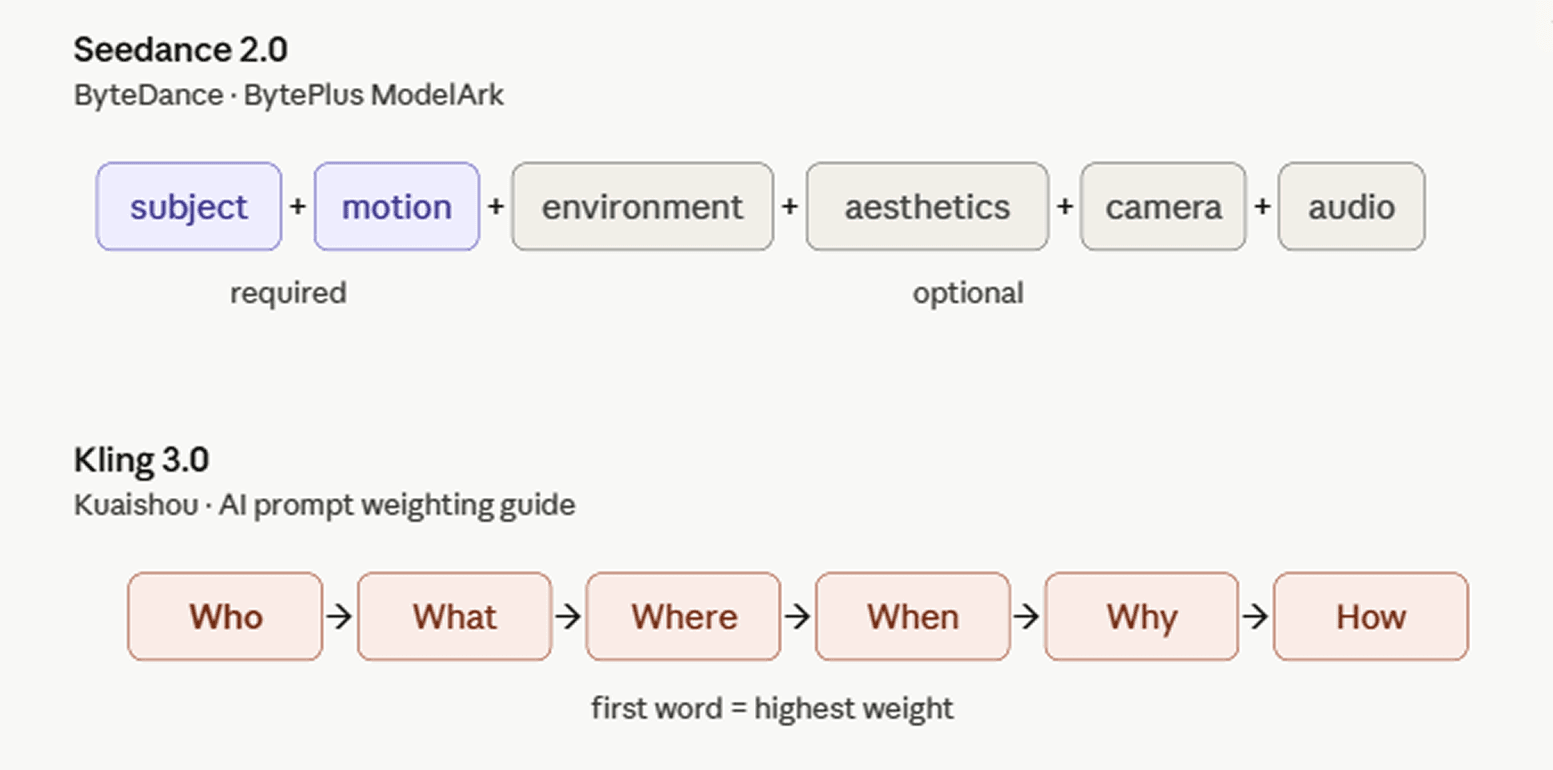
A ByteDance documenta o Seedance 2.0 em sua plataforma internacional de desenvolvedores com o guia de prompts BytePlus ModelArk. A estrutura recomendada: assunto + movimento (+ ambiente + estética + movimento de câmera/corte + áudio). Nem todos os componentes são necessários; você escolhe o que se encaixa na cena.
O guia de ponderação de prompts de IA da Kuaishou enquadra isso por meio de uma fórmula 5W1H: Quem + O quê + Onde + Quando + Por quê + Como. O "Quem" — o assunto — geralmente tem a maior prioridade e lidera o prompt, já que a posição da palavra determina o peso no Kling 3.0: o que vem primeiro recebe a maior atenção computacional. Escolhas estilísticas, como meio ou perspectiva, funcionam melhor no final, agindo como um filtro sobre a cena já estabelecida. O guia alerta contra o empilhamento cego de elementos; muitas palavras-chave conflitantes degradam a qualidade.
Três empresas chegaram a essa conclusão independentemente, o que sugere que seus modelos atingiram um nível de capacidade semelhante quase ao mesmo tempo. O Google diz para escrever menos, a ByteDance marca a maioria dos componentes como opcionais e a Kuaishou enfatiza a ordem das palavras em vez do volume total. As abordagens específicas diferem, mas todos os três laboratórios orientam os criadores para prompts mais livres e naturais.
Agora, sobre como o guia de prompts do Gemini Omni se desenrola na prática.
Estrutura de Prompt do Gemini Omni: 5 Dimensões que o Google DeepMind Utiliza
O guia começa com um exemplo completo:
Um plano de acompanhamento em grande angular desliza suavemente por um lago sereno, revelando um objeto colossal, reflexivo e em forma de feijão cromado levitando sem esforço acima, girando lentamente para revelar seus reflexos distorcidos de falésias majestosas e um objeto menor e semelhante parcialmente submerso na água azul clara abaixo, enquanto um sol brilhante surge atrás da anomalia flutuante, banhando toda a cena com uma luz do dia nítida e etérea com tons vibrantes de azul e verde, criando uma atmosfera cinematográfica e inspiradora sublinhada por uma trilha orquestral majestosa e sobrenatural que enfatiza a vastidão e o mistério da paisagem alienígena, com zumbidos profundos e tênues emanando do objeto levitante.
_SpuwEI0tIU
Mais de 90 palavras. Divida isso e você obtém 5 dimensões.
- Enquadramento e movimento da câmera. Grande angular, plano médio ou close-up? A câmera deve deslizar suavemente ou se mover rapidamente? Os dois verbos produzem resultados visivelmente diferentes, então algumas rodadas de teste valem a pena quando você busca a sensação de movimento correta.
- Estilo. Realista, cinematográfico, etéreo, majestoso? Esta dimensão não precisa de detalhes. Diga ao modelo o tom emocional e isso é suficiente.
- Iluminação. De onde vem a luz? O sol, um poste de luz, na câmera ou fora da tela? Deve parecer nítida, quente ou etérea?
- Cena. Uma linha no guia merece destaque: "você não precisa descrever cada detalhe, pois o Omni trabalhará com sua intenção geral". Isso coincide com o que o Seedance e o Kling dizem em seus documentos oficiais.
- Ação e interação. Quem e o que está na cena, como eles se movem e como interagem.
Edição Conversacional do Gemini Omni vs. Reescrever Prompts no Veo
O Omni e o Veo produzem qualidade de geração comparável. A verdadeira diferença é o que você pode fazer depois que o vídeo é gerado.
Anteriormente, alterar um detalhe significava reescrever todo o prompt, gerar novamente e torcer para que a consistência entre quadros fosse mantida. O Omni substitui essa etapa por uma conversa.
O guia oficial fornece alguns exemplos.
Um vídeo estilo stop-motion de um garotinho. Primeira edição: "mude a borboleta para uma abelha". Em seguida: "mude a abelha para um pequeno enxame de vaga-lumes". Um elemento muda por vez; outros quadros são preservados automaticamente.
5zDLZZccPTY
A câmera funciona da mesma maneira. Um vídeo de um violinista recebe três comandos em sequência: "transporte o violinista para o ambiente da imagem", "torne o violino invisível", "mude o ângulo da câmera para ficar sobre o ombro do violinista". Troca de ambiente, remoção de objeto, reposicionamento da câmera, tudo através de linguagem natural.
jXnbo0gBMHQ
Há um ponto importante a destacar. Avaliadores externos observam que, se sua instrução de edição for muito vaga, o Omni tende a editar em excesso, alterando elementos que você queria manter. A recomendação do Google: altere uma variável por vez e declare explicitamente o que deve permanecer igual.
O exemplo de sincronização intermodal é ainda mais interessante. Pegue um vídeo noturno de um prédio de apartamentos e adicione a instrução "as luzes dos apartamentos começam a acender em sincronia com a música". O modelo analisa as batidas na trilha sonora e alinha as luzes das janelas a elas. Fazer isso no After Effects exige uma linha do tempo, um metrônomo e ajustes manuais quadro a quadro.
93oo4Yvghl8
As 4 Capacidades Avançadas do Gemini Omni: Conhecimento de Mundo, Renderização de Texto, Referência de Ação e Multi-Input
A segunda parte do guia detalha 4 capacidades.
Conhecimento de mundo aplicado
O exemplo de prompt: Explique a diferença entre computação regular e computação quântica. Visualize esta frase usando um estilo contemporâneo de mídia plana que combina formas vetoriais minimalistas com texturas orgânicas ricas. A estética é definida por uma paleta de cores "elétricas" de alto contraste, de rosas neon, cianos e limas definidos contra um fundo azul-marinho profundo. Uma marca registrada deste estilo é o uso de sombreamento pontilhado e gradientes granulados, que adicionam uma qualidade tátil, semelhante a um risógrafo, às formas geométricas simples. Ao combinar bordas afiadas com essas transições suaves e salpicadas, a ilustração atinge uma sensação lúdica e editorial.
O modelo já sabe o que é superposição quântica e como transmiti-la por meio de um conjunto comparativo de cenas. O usuário não precisa explicar mecânica quântica, apenas o tom visual.
3b29A-7qHvE
Isso funciona porque o Omni é executado em um modelo de raciocínio de fronteira, que modelos de vídeo focados apenas em geração não conseguem igualar. Demis Hassabis, em uma entrevista ao Semafor após o I/O, descreveu o Omni como um passo no projeto de construir uma IA que compreenda melhor o mundo real. Ele apontou que a Waymo, divisão de direção autônoma da Alphabet, já está testando modelos de mundo semelhantes para dar aos carros autônomos uma espécie de "imaginação" para lidar com situações imprevisíveis. A geração de vídeo é apenas a aplicação mais visível dessa arquitetura.
Renderização de texto
Exemplo de prompt: palavra por palavra, uma palavra na tela de cada vez, cada palavra com um estilo animado diferente, ritmo perfeito em um compasso, sizzle reel.
_NV7lrxo6Ik
Referência de ação complexa
Exemplo de prompt: edite isso mantendo tudo igual, adicione efeitos de movimento animados saindo do skate.
b94aat8s22c
Referência de múltiplas entradas (Multi-input)
Exemplo de prompt: Os pássaros do vídeo formam vagamente a forma imperfeita de um pássaro com base na imagem. Eles se movem com a música do áudio e se dissipam enquanto voam.
3jdeP-az3oQ
Transferência de estilo
Exemplo de prompt: Crie uma progressão estilística de quatro partes da referência de vídeo que começa com uma estética vibrante de giz de cera, apresentando traços ricos, cerosos e texturizados e designs de personagens lúdicos desenhados à mão contra um pano de fundo de papel altamente granulado. Transicione perfeitamente para um esboço de lápis de grafite em papel texturizado, utilizando hachuras, espessuras de linha variadas e um efeito de "line boiling" de 12fps para enfatizar a sensação de desenho à mão. Em seguida, transforme-se em um estilo 3D de vidro translúcido hiper-realista, caracterizado por refrações de luz complexas, padrões cáusticos e brilhos internos suaves em um ambiente de estúdio minimalista. Conclua a sequência com uma aparência de impressão risográfica tátil, aplicando uma paleta limitada de três cores, texturas granuladas de meio-tom e sobreposições de registro intencionais para um acabamento retrô e mecânico.
n9TesZsfVNw
Referência de storyboard
Prompt: Mostre-me nesta história. Siga a história exatamente na ordem começando pelo topo esquerdo. História completa em 10 segundos. Cinematográfico.
uT937Ptk9fg
Consistência entre cenas (Cross-shot)
RSpqXx0wq8Q
Por que os conselhos sobre prompts do Gemini Omni, Seedance da ByteDance e Kling da Kuaishou estão convergindo
Voltando à observação anterior. A semelhança nos conselhos de prompt do Seedance, Kling e Omni não é resultado de empréstimos mútuos. Mais plausivelmente, esta geração de modelos atingiu um nível de capacidade semelhante por conta própria.
Uma vez que um modelo pode lidar com linguagem natural no nível da cena, suplementar detalhes com conhecimento de mundo e inferir o que o usuário realmente quer dizer, a prescrição excessiva torna-se o gargalo. Os três laboratórios discordam sobre quanto de estrutura adicionar, mas concordam que a resposta não é continuar escrevendo mais.
Este é o resultado de dois anos de modelos de difusão treinados em conjunto com grandes modelos de linguagem. O Omni leva o resultado a um estado relativamente completo.
Chamando o Gemini Omni através da Atlas Cloud: API Unificada para Seedance, Kling, Veo
O Gemini Omni está chegando à Atlas Cloud. A Atlas Cloud agrega mais de 300 modelos de IA em texto, imagem, vídeo e áudio. Os principais modelos de vídeo já rodam na plataforma: Seedance 2.0, Kling 3.0, Wan 2.7, Veo, entre outros. Para uma comparação lado a lado, veja a análise profunda Wan 2.7 vs Seedance 2.0 vs Kling 3.0 da Atlas Cloud.
Uma conta gerencia todo o pipeline. Não há necessidade de registrar, pagar ou manter chaves de API em várias plataformas regionais. O Playground oferece suporte à depuração interativa. Uma API unificada compatível com OpenAI conecta-se a fluxos de trabalho existentes.
A biblioteca de prompts da Atlas Cloud possui mais de vinte categorias de prompts prontos para uso, cobrindo anime, ficção científica, mistério, culinária e formatos de vlog. Cada prompt vem com um vídeo de exemplo e notas de parâmetros. Copie, troque algumas palavras e execute.
Uma API Unificada para Geração de Vídeo em Produção
Enquanto o Google lança o Gemini Omni Flash dentro do aplicativo Gemini e do Google Flow para usuários finais, desenvolvedores e equipes de produto que desejam incorporar o mesmo mecanismo de vídeo multimodal em seus próprios fluxos de trabalho precisam de uma camada de API estável e previsível.
A Atlas Cloud oferece o Gemini Omni Flash através de uma API unificada e compatível com OpenAI, juntamente com mais de 300 outros modelos de imagem, vídeo e LLM — para que você possa integrar o modelo multimodal nativo do Google sem precisar lidar com contas de fornecedores, portais de cobrança ou SDKs separados.
Ambas as variantes do Gemini Omni Flash estão ativas na Atlas Cloud:
| Variante | Melhor Para | Entradas | Resolução | Duração | Preço Inicial |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | Geração cinematográfica pura via prompt | Texto (até 20.000 caracteres) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
| Gemini Omni Flash Image-to-Video (Developer) | Vídeo com consistência de assunto a partir de referências reais | Texto + até 7 imagens de referência | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
Início Rápido — Gere um vídeo Gemini Omni Flash em 5 linhas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
A API retorna um ID de previsão imediatamente — verifique /api/v1/model/prediction/{id} para a URL do MP4 renderizado. Esquemas completos, exemplos de código em 7 idiomas e um Playground no-code estão disponíveis nas páginas dos modelos vinculadas acima.






