
A maioria das pessoas trata a geração de vídeos com IA como um segundo emprego em tempo integral. Você escolhe um novo modelo promissor, lê sua documentação técnica densa, descobre os parâmetros JSON exatos para resolução e duração, lida com tokens de tarefas assíncronas e, em seguida, atualiza manualmente o painel de controle.
Se você está tentando gerenciar um canal do YouTube automatizado "sem rosto" (faceless) ou escalar uma matriz de vídeos no TikTok para lucrar com o tráfego de IA, esse processo manual destrói suas margens. O maior gargalo na produção de vídeos com IA hoje não é o custo do processamento bruto, mas sim o seu tempo gasto "babando" o sistema.
Quando você passa metade do dia olhando para um ícone de carregamento, você não é um empreendedor; você é um monitor de fila.
O verdadeiro atalho para escalar a produção de conteúdo é eliminar os intermediários. Ao combinar o espaço de trabalho com agente conversacional do VM0 com a infraestrutura unificada do AtlasCloud, você pode comprimir completamente a geração de vídeo em uma única janela de chat. Veja exatamente como configurar um pipeline de vídeo automatizado e autônomo que cuida do trabalho pesado enquanto você se concentra na estratégia criativa.
O Problema Principal: Por que Renderizações Assíncronas Roubam seu Tempo
APIs multimodais tradicionais são construídas para engenheiros de software, não para criadores ágeis. Quando você solicita um clipe de vídeo de alta fidelidade de modelos de ponta como Seedance 2.0 da ByteDance, Veo 3.1 do Google ou Kling v2.5 Turbo Pro da Kuaishou, a geração é assíncrona. Isso significa que o servidor não lhe entrega o vídeo imediatamente; ele fornece um "ID de tarefa".
Para obter o arquivo, seu sistema precisa solicitar repetidamente ao servidor — um processo chamado polling — até que a renderização termine. Se um script apresentar erro ou um token expirar no meio do caminho, você precisa começar tudo de novo.
Em vez de lidar com essa dor de cabeça técnica, a combinação do VM0 e do AtlasCloud gerencia todo o ciclo de vida para você. O VM0 fornece o agente inteligente ("Zero") que entende o que você deseja, enquanto o AtlasCloud atua como o pipeline único que oferece acesso instantâneo e unificado a mais de 300 modelos curados de todas as principais modalidades, sem a necessidade de contas separadas.
Guia Passo a Passo: Gerando um Clipe Cinematográfico de 8 Segundos sem "Babá"
Este fluxo de trabalho leva menos de cinco minutos para ser configurado inicialmente e, uma vez concluído, funciona inteiramente por comandos de texto automatizados.
Passo 1 — Vincule sua Infraestrutura Multimodal
Primeiro, você precisa conceder ao seu agente de IA a capacidade de chamar os modelos. Abra o menu Connectors na barra lateral esquerda do VM0. Navegue até a aba Built-in e role para baixo até a seção AI → General Models and Reasoning. Encontre o bloco AtlasCloud e clique no ícone +.
Cole sua chave de API do AtlasCloud no campo de autorização. Uma vez salvo, o status mudará para um indicador verde de Connected. Suas credenciais brutas são completamente isoladas e armazenadas com segurança dentro do espaço de trabalho da plataforma. O agente de IA pode acessar modelos em seu nome, mas nunca poderá visualizar ou expor a chave em si.
Passo 2 — dite sua Visão em Linguagem Simples
Esqueça a formatação de esquemas JSON ou a busca por regras de nomenclatura de modelos. Abra uma nova janela de chat com seu agente e diga exatamente que tipo de filmagem você precisa.
Por exemplo, digite um prompt altamente descritivo como este:
"Gere um voo panorâmico cinematográfico de 8 segundos por uma megacidade neon à noite — arranha-céus rosa e ciano, outdoors holográficos, carros voadores, ruas molhadas pela chuva, clima de blade-runner. 1080p, 16:9, com áudio sincronizado. Use o AtlasCloud."
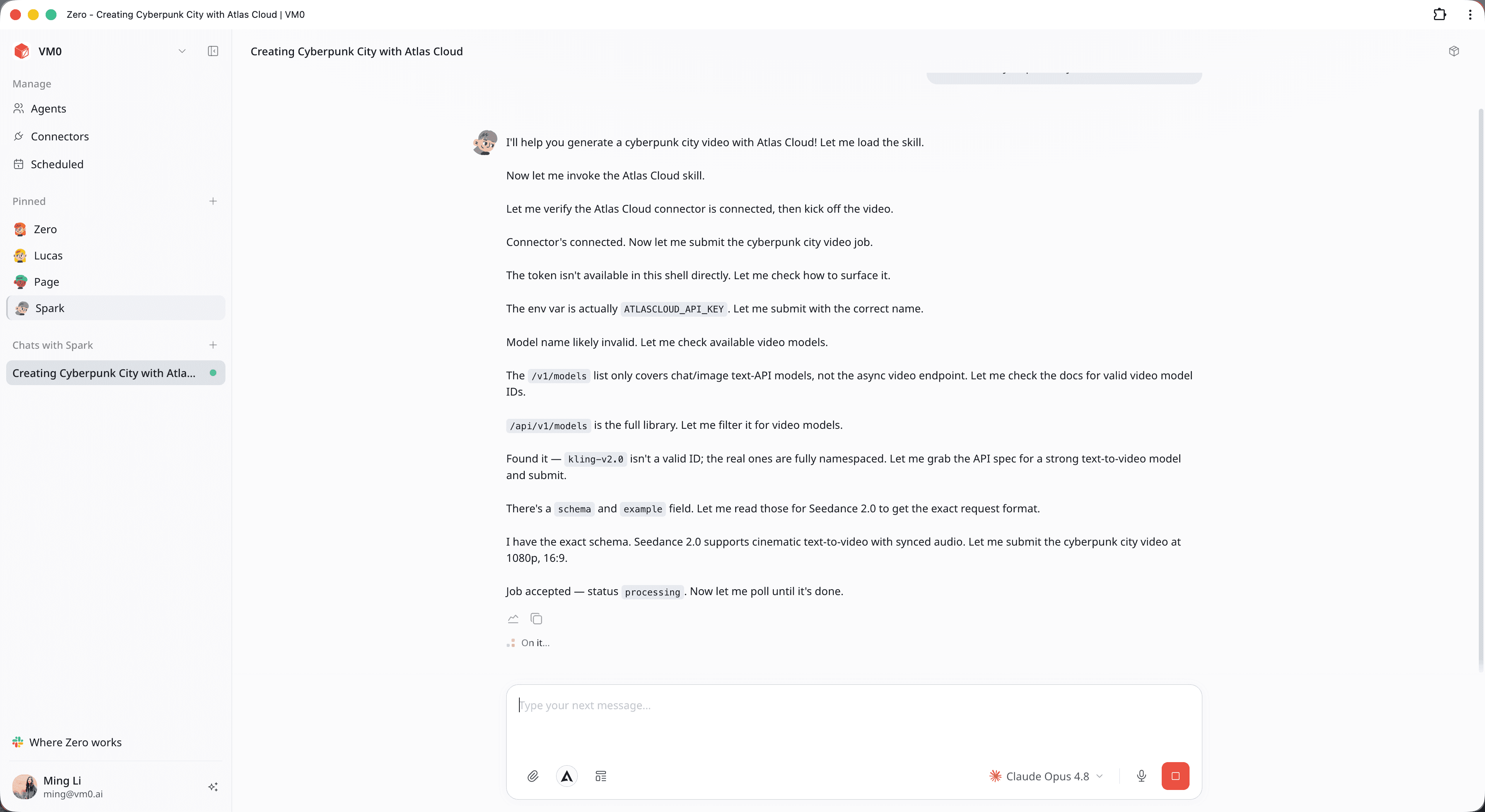
Passo 3 — Deixe o Agente Gerenciar a Fila de Polling
Assim que você enviar, seu trabalho estará efetivamente concluído. Você não precisa manter a aba ativa ou monitorar os logs de rede. Em segundo plano, o agente lida com a orquestração multimodal:
- Resolução de Esquema: O agente consulta o catálogo do AtlasCloud, mapeia automaticamente o ID com namespace necessário (como bytedance/seedance-2.0/text-to-video) e formata o layout técnico.
- Polling Assíncrono: Como o vídeo leva tempo para ser processado, a chamada inicial da API retorna um status de processamento. O agente executa automaticamente um loop de polling interno, verificando o AtlasCloud em intervalos ideais até que o arquivo de saída esteja pronto.
Passo 4 — Revise, Ajuste e Troque de Modelo Instantaneamente
Quando a renderização é concluída, o arquivo MP4 final em alta definição cai diretamente no seu feed de chat, juntamente com uma análise estruturada dos metadados da geração:
- Modelo Utilizado: Seedance 2.0 (via AtlasCloud)
- Atributos: 8 segundos, resolução 1080p, proporção 16:9, áudio sincronizado nativo, sem marca d'água.
Se o estilo visual não for exatamente o que você queria, não precisa reescrever um script complexo. Você pode falar com ele como um editor humano. Digite: "Mude a proporção para um corte vertical 9:16 para redes sociais e troque o motor para o Kling v2.5 Turbo Pro para ver como a iluminação muda." O agente interpreta o ajuste, acessa o endpoint correto do AtlasCloud e gerencia a próxima fila de renderização automaticamente.
Por que "Agente + API Unificada" Supera o Jeito Antigo
Para criadores sérios, gerenciar várias contas e codificar scripts personalizados é um enorme desperdício de tempo e dinheiro. Veja como a abordagem unificada se compara aos fluxos de trabalho tradicionais:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Recurso / Métrica | Painéis Web Manuais | Scripts Python de API Personalizados | Espaço de Trabalho VM0 + AtlasCloud |
| Tempo de Configuração | Alto (5+ sites para registrar) | Alto (Horas escrevendo loops assíncronos) | Menos de 2 minutos |
| Habilidades de Programação | Nenhuma | Avançadas | Nenhuma (Linguagem Natural) |
| Gerenciamento de Fila | Atualização manual da página | Tratamento complexo de erros | Polling automático em segundo plano |
| Seleção de Modelo | Fragmentada entre plataformas | Preso a endpoints codificados | Mais de 300 modelos via uma única chave |
| Fricção no Fluxo de Trabalho | Alta (custo de troca) | Alta (manutenção) | Zero fricção |
Perguntas Frequentes
O vídeo está travado em "Processando" por mais de um minuto. A API travou?
Não, este é um comportamento completamente normal para renderizações de vídeo de alta qualidade. Como ativos multimodais avançados exigem processamento pesado no servidor, a tarefa permanece em uma fila temporária. O agente está verificando ativamente o código de status em segundo plano e exibirá o arquivo de vídeo no segundo em que o servidor o liberar.
Qual modelo devo usar para curtas de redes sociais: Seedance 2.0 ou Veo 3.1?
Depende inteiramente do seu estilo de conteúdo. O Seedance 2.0 se destaca em movimento rápido, estética neon fluida e efeitos atmosféricos altamente detalhados, como chuva e fumaça cinematográfica. O Veo 3.1 tende a oferecer estabilidade estrutural superior para ambientes fotorrealistas e visualizações arquitetônicas. Com uma plataforma unificada, a melhor estratégia é testar o mesmo prompt em ambos os backends para ver qual estética se adapta melhor à sua marca.
Como gerencio pagamentos e tokens em todas essas plataformas de vídeo diferentes?
Esse é o principal benefício de utilizar uma plataforma de inferência consolidada. Em vez de registrar cartões de crédito em cinco portais internacionais diferentes de fornecedores de IA e gerenciar múltiplos limites mínimos de gastos mensais, você financia apenas uma conta. A chave unificada lida com as conversões de tokens entre todas as famílias de modelos de forma transparente, nos bastidores.






