
ChatGPT API for Frontier GPT 5.6 Reasoning
A ChatGPT API na Atlas Cloud reúne a mais nova família GPT 5.6 da OpenAI em uma única integração, abrangendo Sol para raciocínio de fronteira aprofundado, Terra para workloads de produção bem fundamentados e Luna para conversas naturais e geração de conteúdo. Encaminhe todos os modelos por uma única chave compatível com OpenAI, conte com disponibilidade em nível de produção e pague tarifas transparentes de pay-as-you-go a partir de $1 por milhão de tokens de entrada. Comece a criar hoje mesmo.
Explorar Modelos Líderes
O Atlas Cloud oferece os modelos criativos mais avançados e inovadores do setor.
Escolha o modelo certo da API ChatGPT: todos os endpoints comparados
Cinco endpoints de geração de texto que vão do raciocínio de ponta à conversação econômica, todos disponibilizados por meio de uma única chave compatível com OpenAI, com preços transparentes de pagamento conforme o uso.
| Modalidade | Descrição |
|---|---|
| GPT 5.6 Sol API (Texto para texto) | Criado para cargas de trabalho de IA de ponta, o GPT 5.6 Sol transforma prompts de texto complexos em saídas de raciocínio profundo e em várias etapas para resolver problemas ambiciosos. O preço padrão é de $5 por milhão de tokens de entrada e $30 por milhão de tokens de saída, posicionando-o como a opção principal quando a qualidade da resposta pesa mais do que o custo. |
| GPT 5.6 Terra API (Texto para texto) | Precisa de um padrão de produção confiável? O GPT 5.6 Terra converte prompts em texto fundamentado e prático para fluxos de trabalho reais e pipelines de análise, por $2.50 de entrada e $15 de saída por milhão de tokens. As equipes o implementam em aplicações voltadas para clientes quando a consistência é mais importante do que a profundidade experimental. |
| GPT 5.6 Luna API (Texto para texto) | Encaminhe tráfego conversacional e criativo para o GPT 5.6 Luna, um modelo de texto ajustado para diálogo natural, geração de conteúdo e experiências de IA personalizadas. Por $1 de entrada e $6 de saída por milhão de tokens, é o ponto de entrada mais econômico desta linha da API ChatGPT, muito adequado para produtos de chat e geração de textos em alto volume. |
| GPT 5.4 API (Texto para texto) | O GPT 5.4 processa instruções de texto em código confiável, conteúdo longo e saídas estruturadas de resolução de problemas, com alta precisão. Concebido como um modelo multimodal avançado, situa-se na faixa intermediária de preços, com $2.50 de entrada e $15 de saída por milhão de tokens, sendo uma opção prática para assistentes de programação e plataformas de conteúdo. |
| GPT 5.5 API (Texto para texto) | Quando problemas difíceis justificam um investimento premium, o GPT 5.5 oferece raciocínio avançado, programação e geração de conteúdo a partir de um único endpoint de texto. Com preço de $5 de entrada e $30 de saída por milhão de tokens, destina-se a cargas de trabalho complexas e críticas para a confiabilidade, como orquestração de agentes e análise técnica. |
A ChatGPT API: níveis GPT 5.x e pesos abertos
Aceda a toda a linha GPT 5.x e ao GPT OSS 120B de pesos abertos através de uma única ChatGPT API, ajuste o esforço de raciocínio de low a xhigh, combine texto, imagens e ficheiros numa só chamada e invoque ferramentas nativas com pesquisa web em tempo real usando uma única chave compatível com OpenAI.
Texto, imagens e ficheiros numa só chamada da ChatGPT API
Um único pedido à ChatGPT API pode combinar texto simples, URLs de imagens e ficheiros de documentos numa só mensagem. Isto elimina serviços separados de OCR ou visão, permitindo resumir contratos digitalizados ou ler capturas de ecrã numa única passagem.
Fidelidade às instruções na ChatGPT API
O GPT OSS 120B adere a prompts de sistema em camadas, mantendo formatos, restrições e tom estáveis entre respostas, sem desvios. Essa fiabilidade é adequada para agentes autónomos, extração estruturada e pipelines de produção em que a saída tem de cumprir as regras.
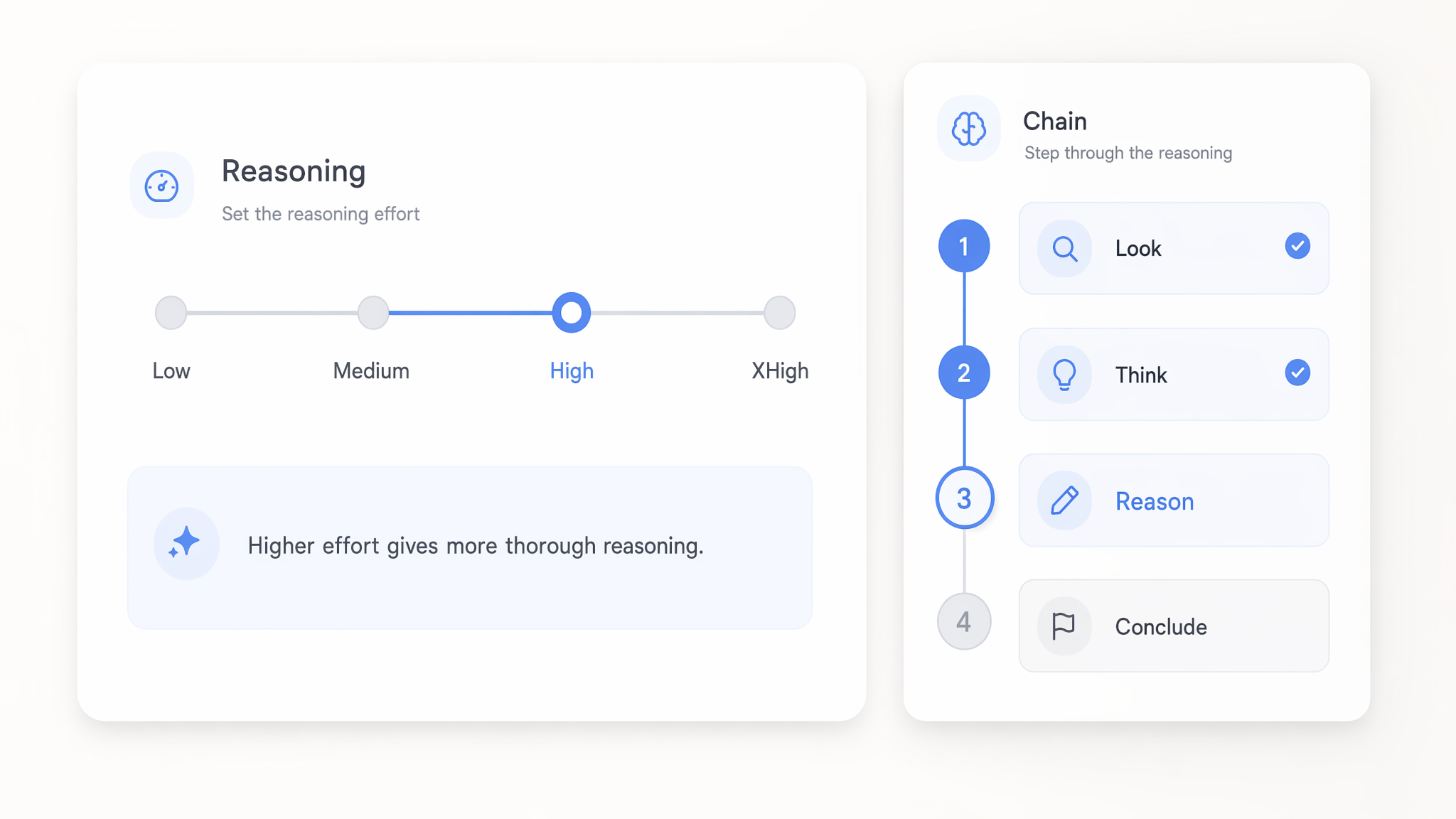
Ajuste o esforço de raciocínio de low a xHigh
Defina o esforço de raciocínio nos modelos GPT 5.x em qualquer ponto entre low e xhigh para controlar a profundidade com que pensam antes de responder. Definições low respondem a chamadas simples de forma rápida e económica, enquanto xhigh gasta mais computação em lógica multi-etapa complexa.
Pesos Apache 2.0 que são totalmente seus
Distribuído sob a licença Apache 2.0, o GPT OSS 120B permite utilização comercial e fine-tuning privado numa única GPU de 80GB. Aloje-o on-premises para manter dados proprietários internamente e evitar por completo custos por token.

Cinco níveis GPT, uma ChatGPT API
Uma única ChatGPT API disponibiliza toda a linha GPT 5.x, com preços desde Luna a $1 até Sol a $5 por milhão de tokens de entrada. Associe cada chamada ao nível adequado ao seu custo e necessidade de inteligência, sem alterações de endpoint.
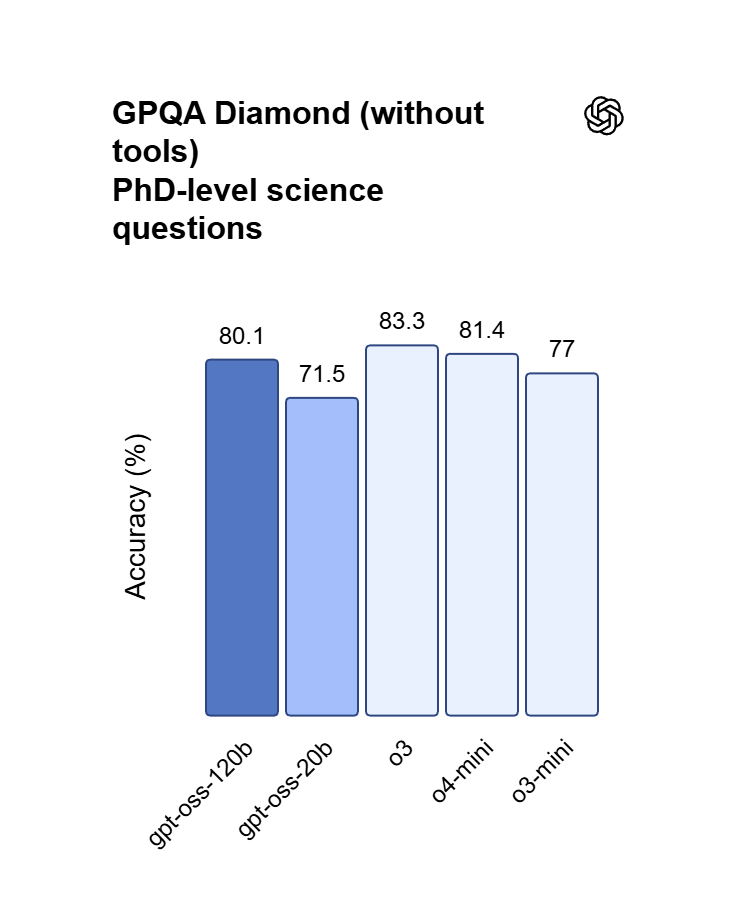
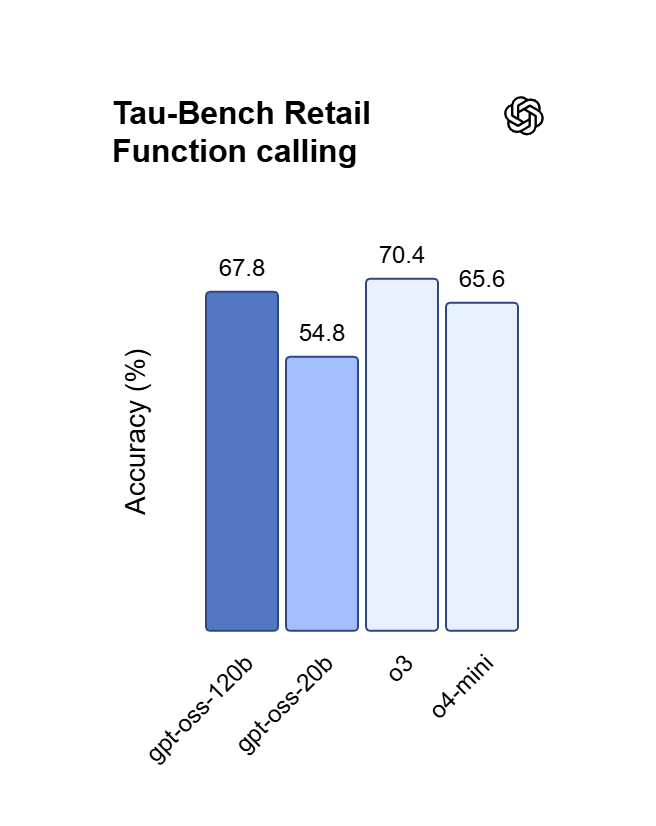
Raciocínio ajustado para Vibecoding
Com quase paridade face ao OpenAI o4-mini, o GPT OSS 120B consegue lidar com síntese de código em várias etapas e provas matemáticas. Transforme ideias em linguagem natural em aplicações web funcionais, depure lógica aninhada e orquestre fluxos complexos de agendamento de tarefas.

Chamadas de funções com pesquisa web em tempo real
Os modelos GPT 5.x suportam chamadas de funções com seleção automática de ferramentas, além de uma pesquisa web integrada que obtém resultados atuais. Transmita respostas como eventos server-sent enquanto o cache de prompts reduz a entrada em cache do GPT 5.6 Sol para $0.5 por milhão de tokens.
Um Prompt, Três Concorrentes: ChatGPT API Frente a Frente
Demos exatamente a mesma instrução de build a modelos através da ChatGPT API e a dois flagships rivais; depois renderizámos cada resposta HTML bruta sem alterações, para que possa avaliar lado a lado a profundidade do raciocínio, a qualidade do código e o gosto de design.
Crie um único ficheiro HTML autónomo (apenas CSS e JavaScript inline — absolutamente sem bibliotecas externas, CDNs, frameworks, fontes ou URLs de imagens) que abra diretamente em qualquer navegador moderno e execute um simulador vivo e autocrescente de ecossistema de estufa de vidro, renderizado inteiramente como ilustração vetorial plana em Canvas/SVG. A cena em ecrã completo é uma estufa vitoriana abobadada: uma cúpula curva de vidro atravessa o topo como elemento de enquadramento, com os seus painéis desenhados como polígonos translúcidos verde-jade, realces especulares suaves e contornos finos de caixilhos, e uma faixa de solo escuro de cultivo ao longo da parte inferior. A direção artística é de ilustração vetorial limpa — folhas e caules desenhados com contornos nítidos de linhas de nervuras e preenchimentos em camadas semitransparentes, uma paleta assente em verde-sálvia enevoado e castanho-musgo, com luz solar âmbar e apontamentos de vidro-jade; sem fotorrealismo, sem gradientes usados como texturas, mantendo uma sensação gráfica e ilustrada à mão. Interação principal: clicar em qualquer ponto do solo planta uma semente nesse local, e a planta cresce em tempo real usando um L-system real — implemente uma gramática recursiva de reescrita (axioma mais regras de produção com parênteses de ramificação e variações aleatórias de ângulo/comprimento por instância, para que nenhuma planta seja idêntica) e anime a derivação para que os ramos se estendam, bifurquem e desdobrem folhas progressivamente ao longo de alguns segundos, em vez de aparecerem já totalmente formados. Fetos tropicais e trepadeiras devem dobrar-se e enrolar-se fototropicamente em direção a um sol arrastável: renderize um disco solar âmbar brilhante que o utilizador possa agarrar e arrastar para qualquer ponto do céu, e cada ponta em crescimento deve reorientar continuamente a sua direção de crescimento para a posição atual do sol, de modo que arrastar o sol conduza visivelmente a inclinação e a escalada de todo o jardim. As plântulas desdobram-se com uma animação de easing, e gotículas de condensação formam-se no vidro e deslizam lentamente para baixo em loop. Controle tudo com um ciclo dia-noite ligado à posição do sol: a luz ambiente e a lavagem do céu transitam suavemente num gradiente de dourado quente para azul frio, a localização do sol define a direção e o comprimento das sombras suaves das plantas projetadas no chão e dos pontos de luz à deriva no vidro, e ao anoitecer os pirilampos surgem gradualmente como pequenos pontos de luz pulsantes a flutuar entre a folhagem. A composição irradia o crescimento das plantas da base para cima, em direção ao centro, contida pelo arco da cúpula. Use requestAnimationFrame para um loop de animação contínuo e discretamente vivo; mantenha o desempenho fluido com muitas plantas no ecrã ao mesmo tempo. Inclua controlos subtis e discretos (por exemplo, um slider ou alternador de avanço automático para a hora do dia, e um botão de reiniciar/limpar) estilizados para combinar com a estética ilustrada, além de uma dica de uma linha a dizer ao utilizador para clicar no solo para plantar e arrastar o sol para orientar o crescimento. Torne-o responsivo a qualquer tamanho de janela, e dê-lhe um tom emocional calmo, quieto e vivo — a primeira luz da manhã a entrar de lado enquanto rebentos tenros se abrem em conjunto. Isto é uma simulação generativa, não um jogo nem um dashboard: dê prioridade ao algoritmo genuíno de crescimento recursivo, ao loop de animação e à física de luz/sombra/fototropismo.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Crie uma página HTML completa de ficheiro único contendo um dashboard interativo de financiamento global de startups, com dados fictícios mas internamente consistentes para 8 setores industriais ao longo de 5 anos. Todo o CSS e JavaScript deve ser inline, sem quaisquer dependências externas, sem bibliotecas de gráficos, sem CDNs e sem imagens. Renderize três visualizações programadas manualmente em canvas ou SVG: um gráfico de barras animado que se reordena com easing quando o utilizador escolhe um ano num slider, um gráfico de linhas com tooltips ao passar o cursor que mostram valores exatos e uma guia vertical de acompanhamento, e um gráfico de donut cujos segmentos se expandem ao passar o cursor com uma animação de mola. Inclua uma UI moderna escura com uma paleta de acentos violeta-a-turquesa, contadores numéricos animados em quatro cartões de estatísticas KPI, uma linha de filtros de setor com toggle chips que atualiza instantaneamente todos os gráficos, e um seletor de tema claro/escuro com transições suaves de cor. O layout deve ser responsivo, colapsando para uma única coluna abaixo de 768px, e todas as interações devem responder em tempo real sem recarregar a página.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
Todas as cargas de trabalho que a ChatGPT API pode impulsionar
De programação agêntica e extração estruturada a chat de suporte fundamentado e conteúdo em alto volume, a ChatGPT API na Atlas Cloud encaminha cada tarefa para o tier GPT 5.6 certo por meio de uma única chave compatível com OpenAI.

Lance ferramentas de programação agêntica com a ChatGPT API
Encaminhe refatorações complexas e síntese de código em vários arquivos para o GPT 5.6 Sol, o tier de raciocínio profundo da família, criado para cargas de trabalho de engenharia de ponta. Equipes que criam copilotos de código, bots de revisão automatizada e geradores de testes obtêm lógica pronta para produção.

Geração de conteúdo alinhado à marca em escala
O GPT 5.6 Luna, o tier criativo da família, redige posts de blog, descrições de produtos e textos localizados com tom natural e saída personalizada. Equipes de conteúdo e plataformas de ecommerce produzem textos em alto volume sem sacrificar a voz da marca.

Impulsione assistentes de suporte na ChatGPT API
Precisa de um chatbot que siga o roteiro? O GPT 5.6 Terra oferece respostas confiáveis e fundamentadas, criadas para conversas em produção, para que equipes de suporte e produtos SaaS possam automatizar tickets e desviar consultas repetitivas com confiabilidade.

Sistemas de conhecimento com retrieval-augmented generation
Insira manuais de políticas inteiros ou arquivos de pesquisa em um modelo de contexto longo e obtenha respostas fundamentadas com fidelidade às fontes. Equipes jurídicas, médicas e de busca interna ganham um mecanismo confiável para perguntas e respostas com retrieval-augmented generation.

Extração de dados estruturados via ChatGPT API
Faturas, emails e PDFs desorganizados são convertidos em JSON limpo no qual sistemas downstream podem confiar. O seguimento confiável de instruções mantém os schemas intactos, atendendo a pipelines de dados, automação de CRM e workflows de analytics que não podem tolerar desvios.

Associe cada tarefa ao tier de modelo certo
Quando orçamento e latência importam, alterne entre Sol, Terra e Luna por meio de uma única chave compatível com OpenAI. Startups e desenvolvedores independentes prototipam rapidamente com preços pay-as-you-go e depois escalam a mesma integração para produção.
| Modelo | Contexto | Saída máxima | Entrada | Posicionamento |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Texto | LLM de raciocínio de alta eficiência |
| GLM-5 | 202.75K | 202.75K | Texto | Modelo fundacional principal |
| DeepSeek V3.2 | 163.84K | 163.84K | Texto | Generalista principal |
| MiniMax-M2.5 | 204.8K | 196.6K | Texto | Codificação agentiva SOTA |
Como Usar ChatGPT no Atlas Cloud
Comece em minutos — siga estes passos simples para integrar e implantar modelos pela plataforma da Atlas Cloud.
Crie uma Conta no Atlas Cloud
Cadastre-se em atlascloud.ai e conclua a verificação. Novos usuários recebem créditos gratuitos para explorar a plataforma e testar modelos.
Por Que Usar ChatGPT no Atlas Cloud
Combine modelos avançados de ChatGPT com a plataforma acelerada por GPU do Atlas Cloud, fornecendo desempenho, escalabilidade e experiência de desenvolvimento incomparáveis.
Desempenho e Flexibilidade
Baixa Latência:
Inferência otimizada por GPU para respostas em tempo real.
API Unificada:
Uma única integração para acessar ChatGPT, GPT, Gemini e DeepSeek.
Preços Transparentes:
Faturamento por Token, suporta modo Serverless.
Empresa e Escala
Experiência do Desenvolvedor:
SDK, análise de dados, ferramentas de ajuste fino e modelos tudo em um.
Confiabilidade:
99.99% de disponibilidade, controle de permissões RBAC, logs de conformidade.
Segurança e Conformidade:
Certificação SOC 2 Type II, conformidade HIPAA, soberania de dados nos EUA.
ChatGPT API: perguntas de desenvolvedores respondidas
A ChatGPT API permite que desenvolvedores enviem prompts aos modelos GPT da OpenAI e recebam completions programaticamente, em vez de usar a interface de chat. No Atlas Cloud, você acessa toda a linha GPT 5.6, junto com GPT 5.4 e GPT 5.5, por meio de um único endpoint compatível com OpenAI. Cada chamada é cobrada por token, com preços transparentes de pagamento conforme o uso, portanto você paga apenas pelo que gerar.
Cinco modelos cobrem todo o espectro, do raciocínio profundo ao chat do dia a dia. GPT 5.6 Sol é voltado para resolução de problemas ambiciosos e workloads de fronteira, GPT 5.6 Terra atende a fluxos de trabalho de produção confiáveis, e GPT 5.6 Luna é ajustado para conversa natural e geração de conteúdo. GPT 5.4 e GPT 5.5 adicionam raciocínio multimodal e codificação para equipes que desejam desempenho de uso geral comprovado.
Gere uma API key, aponte sua base URL para https://api.atlascloud.ai/v1 e defina o ID do modelo, como openai/gpt-5.6-terra. Como a ChatGPT API aqui é totalmente compatível com OpenAI, o código existente do OpenAI SDK funciona após alterar apenas a base URL e a chave. Não há lista de espera nem assinatura, e novos lançamentos chegam com acesso Day-0, para que você possa enviar sua primeira requisição no mesmo dia.
Os preços variam conforme o modelo escolhido. GPT 5.6 Luna é o mais econômico, a $1 por milhão de tokens de entrada e $6 por milhão de tokens de saída, GPT 5.6 Terra custa $2.5 e $15, e GPT 5.6 Sol fica em $5 e $30. O cache de prompts reduz o custo de entradas repetidas, e a cobrança continua no modelo de pagamento conforme o uso, portanto você paga apenas pelos tokens que usar.
Sim. O endpoint segue o formato OpenAI Chat Completions, portanto os OpenAI SDKs oficiais, LangChain e a maioria das bibliotecas compatíveis com OpenAI funcionam depois que você troca a base URL e a chave. Isso significa que uma integração existente com a ChatGPT API pode ser migrada sem reescrever sua lógica de requisição.
Streaming e function calling funcionam sem alterações em relação à implementação da OpenAI, portanto você define stream como true para saída token a token e passa um array tools para acionar chamadas de função. Respostas JSON estruturadas seguem o mesmo formato de requisição compatível com OpenAI, o que mantém a orquestração de agentes e os pipelines de extração de dados previsíveis.
Esses modelos aceitam prompts grandes para fluxos de trabalho com documentos longos e repositórios completos. Os preços são escalonados no marco de 272,000 tokens, com uma tarifa padrão para prompts abaixo dele e uma segunda tarifa para prompts que excedem 272,000 tokens. Assim, você pode fornecer contexto extenso em uma única requisição e saber exatamente como a tarifa muda à medida que o prompt cresce.
Escolha o modelo de acordo com a tarefa. Use GPT 5.6 Sol quando precisar de raciocínio de fronteira e resolução de problemas ambiciosos, escolha GPT 5.6 Terra para análises fundamentadas e prontas para produção, e use GPT 5.6 Luna para trabalho conversacional ou criativo em que o custo seja o fator mais importante. GPT 5.4 e GPT 5.5 continuam sendo opções multimodais fortes para codificação e raciocínio geral.
O Atlas Cloud executa a ChatGPT API em infraestrutura gerenciada que escala com seu tráfego, evitando o provisionamento de GPUs e a orquestração de nós do self-hosting. Novas versões de modelos chegam com acesso Day-0, mantendo você atualizado sem trabalho de migração. Se suas necessidades crescerem, a mesma chave compatível com OpenAI cobre todos os modelos da família, portanto escalar nunca significa criar uma nova integração.
Explorar Mais Séries
Seedance 2.0
A API do Seedance 2.0 oferece acesso de produção ao modelo de vídeo multimodal da ByteDance — entradas quadrimodais (texto, imagem, vídeo, áudio) e um sistema "Universal Reference" líder do setor que fixa a composição, o movimento da câmera e as ações dos personagens entre as cenas. Integre um controle de nível de diretor com uma única chamada de API, uma taxa fixa de $0,09/s, chave instantânea e sem lista de espera — respaldado por tempo de atividade e conformidade de nível corporativo. O Seedance 2.0 Native 4K já está no ar!
Grok Imagine
A Grok Imagine API oferece aos desenvolvedores a geração de imagens, vídeos e áudio da xAI em um único pacote. Ela produz imagens de até 2K com renderização de texto multilíngue, além de vídeos de até 15 segundos com áudio nativo sincronizado e edição baseada em referências. Na Atlas Cloud, uma única chave executa todos os modos do Grok Imagine, permitindo que você alterne entre imagem, vídeo e áudio sem configurações separadas, a partir de US$ 0,02 por imagem e US$ 0,05 por segundo.
Gemini Omni Flash
A Gemini Omni API traz para o seu stack o modelo multimodal de geração e edição de vídeo do Google DeepMind, apresentado no Google I/O 2026. O Gemini Omni funde o motor de raciocínio do Gemini com mídia generativa, aceitando qualquer combinação de texto, imagens, vídeo e áudio para produzir resultados consistentes e fundamentados em conhecimento. Refine os resultados por meio de conversas naturais — troque objetos, reescreva cenas e mude estilos, enquanto a física, os personagens e a continuidade permanecem intactos. A Atlas Cloud oferece toda a linha Gemini Omni Flash — texto para vídeo, imagem para vídeo com até 7 imagens de referência e referência para vídeo — por meio de uma única API unificada, com preços transparentes por segundo a partir de $0.112 e sem assinatura. Comece a construir hoje mesmo.
GPT Image 2
A API do GPT Image 2 dá aos desenvolvedores acesso ao mais recente modelo de imagem da OpenAI, o sucessor do GPT Image 1.5. Ele gera e edita imagens com renderização de texto precisa em caracteres latinos e CJK, além de uma forte composição para pôsteres, mockups e infográficos. Na Atlas Cloud, você o acessa através de uma API unificada junto a mais de 300 modelos, com créditos gratuitos, 99,99% de tempo de atividade e sem a necessidade de verificação de organização da OpenAI.
Os modelos criativos mais poderosos do Google estão todos disponíveis na Atlas Cloud. O Veo 3.1 oferece geração de vídeo cinematográfico, o Nano Banana 2 impulsiona a criação de imagens de alta fidelidade e o Gemini traz inteligência multimodal para cada fluxo de trabalho. Acesse o pacote completo de modelos do Google por meio de uma única API key com disponibilidade Day-0 e preços de pagamento conforme o uso (pay-as-you-go).
Seedance 2.0 Mini
O Seedance 2.0 Mini leva a geração de vídeo multimodal da ByteDance para fluxos de trabalho onde a velocidade e o custo são essenciais. Ele oferece os principais recursos do Seedance 2.0 com menor impacto — geração mais rápida, menor custo por vídeo e a mesma integração de API que você já usa. Para equipes que executam pipelines de alto volume ou prototipagem em escala, o Mini é a opção padrão prática.
ByteDance
Da geração de vídeo cinematográfico à criação de imagens de alta fidelidade, os modelos mais poderosos da ByteDance estão disponíveis no Atlas Cloud. Execute o Seedance e o Seedream em grande escala com os preços de inferência mais baixos e zero custos indiretos de infraestrutura.
Alibaba
O Atlas Cloud reúne toda a linha de modelos da Alibaba sob uma única API: Qwen para tarefas de linguagem e imagem, e Wan para geração de vídeo em até 1080p. Acesse cada modelo no formato pré-pago (pay-as-you-go) sem necessidade de assinaturas. A API da Alibaba está disponível por meio de uma única URL base usando seu cliente compatível com OpenAI existente.
OpenAI
O Atlas Cloud oferece acesso a toda a linha da API da OpenAI, desde o GPT Image 2 para geração de imagens até o Sora 2 para vídeo. Todos os modelos estão disponíveis na modalidade de pagamento conforme o uso, sem compromisso mensal. Integre-se trocando apenas uma URL base usando a API compatível com a OpenAI.
xAI
Construa pipelines completos de imagem e vídeo usando a xAI API no Atlas Cloud. Gere em 2K, edite com imagens de referência e anime imagens em clipes sincronizados com áudio.
Kwaivgi
A API da Kwaivgi com preço 15% abaixo do padrão. A Atlas Cloud oferece acesso Day-0 a novos lançamentos da Kling com preços de pagamento conforme o uso e sem limite de assentos. Uma conta, uma chave, todos os modelos da Kling do nível padrão ao nível master.
Seedream 5.0 Pro
A API do Seedream 5.0 Pro fornece aos desenvolvedores o modelo de edição de imagens controlável da ByteDance no Atlas Cloud. Ela posiciona as edições com precisão usando âncoras e coordenadas, separa as imagens em camadas editáveis, funde múltiplas referências e combina cores e materiais exatos, com texto multilíngue em 2K e 3K. No Atlas Cloud, você pode acessá-lo por meio de uma única chave!


