Gemini Omni Flash API for Conversational Video Editing
A Gemini Omni API traz para o seu stack o modelo multimodal de geração e edição de vídeo do Google DeepMind, apresentado no Google I/O 2026. O Gemini Omni funde o motor de raciocínio do Gemini com mídia generativa, aceitando qualquer combinação de texto, imagens, vídeo e áudio para produzir resultados consistentes e fundamentados em conhecimento. Refine os resultados por meio de conversas naturais — troque objetos, reescreva cenas e mude estilos, enquanto a física, os personagens e a continuidade permanecem intactos. A Atlas Cloud oferece toda a linha Gemini Omni Flash — texto para vídeo, imagem para vídeo com até 7 imagens de referência e referência para vídeo — por meio de uma única API unificada, com preços transparentes por segundo a partir de $0.112 e sem assinatura. Comece a construir hoje mesmo.
Explorar Modelos Líderes
O Atlas Cloud oferece os modelos criativos mais avançados e inovadores do setor.







Quatro maneiras de gerar com a Gemini Omni Flash API
Escolha o endpoint da API Gemini Omni Flash que se adequa à tarefa, desde texto para vídeo e imagem para vídeo até a geração baseada em referências e edição conversacional.
| Modalidade | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | Tem apenas um prompt de texto? A Gemini Omni Flash Text-to-Video API o transforma em um clipe de 720p com áudio sincronizado em uma única passagem, seguindo uma direção baseada em raciocínio sobre cena, movimento e câmera para clipes de até 10 segundos. |
| Gemini Omni Flash Image-to-Video API (I2V) | A API Image-to-Video do Gemini Omni Flash transforma uma imagem estática em movimento, fixando a fonte original como o quadro inicial. Com movimentos naturais e áudio sincronizado, ela dá vida a fotos de produtos, retratos e conceitos em 720p. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Guie uma geração com até sete imagens de referência e três clipes de vídeo curtos usando a Gemini Omni Flash Reference-to-Video API. Ela mantém a consistência de personagens, estilo e cenário em todo o clipe, ideal para conteúdo de marca e em série. |
| Gemini Omni Flash Video Edit API | Quando um clipe precisa de alterações, a Gemini Omni Flash Video Edit API aplica instruções em linguagem natural por meio de uma Interactions API com estado. Ela troca elementos, ajusta a iluminação e reestiliza cenas, mantendo o restante da filmagem intacto ao longo dos turnos de interação. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
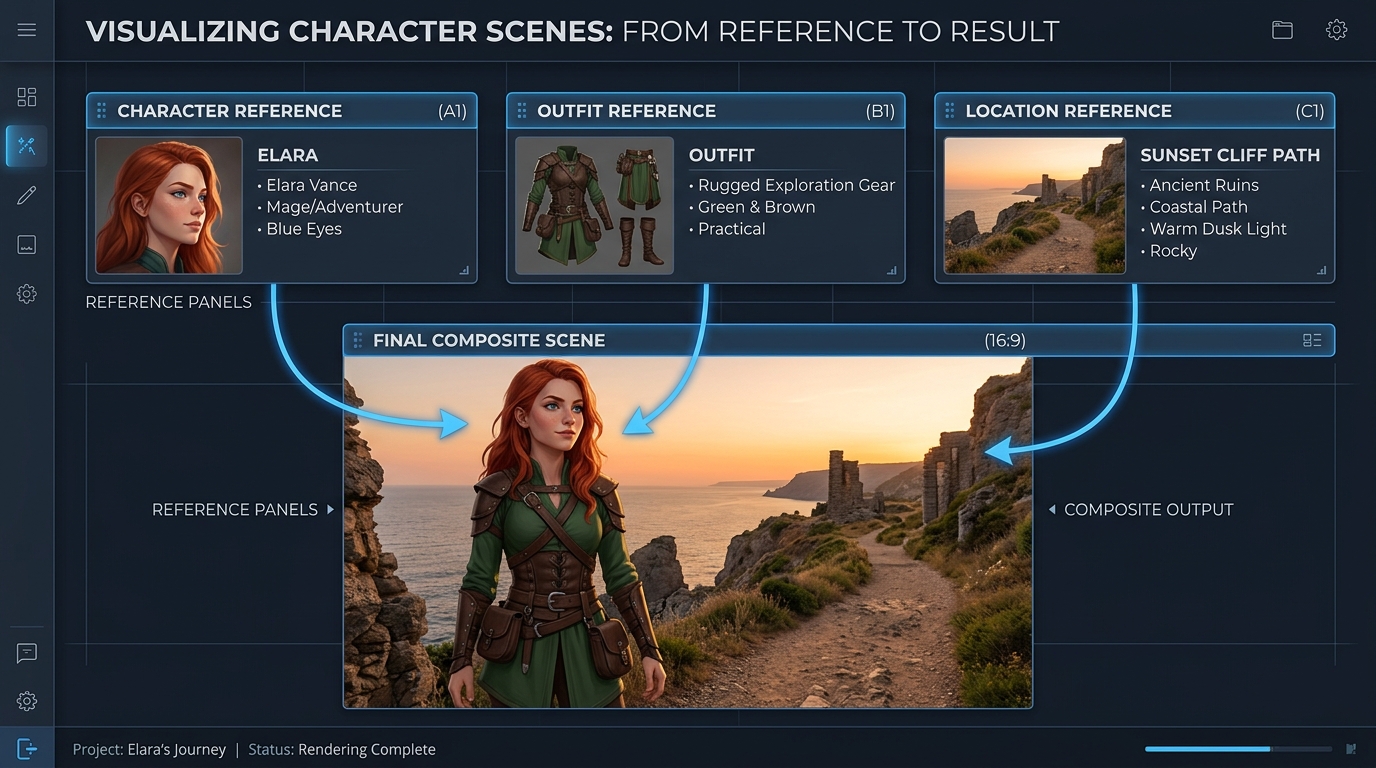
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Como a API Gemini Omni Flash se compara
Veja como os modelos de diferentes provedores se comparam — compare desempenho, preços e pontos fortes exclusivos para tomar uma decisão informada.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Edição de vídeo finalizado por meio de conversação | Yes | Sim, com estado | Texto, imagem, vídeo, áudio |
| Veo 3.1 | Clipes cinematográficos com extensão de cena | Yes | No | Texto, imagem, referência |
| Seedance 2.0 | Vídeo controlado por referência de altíssima qualidade | Yes | No | Texto, imagem, vídeo, áudio |
| Kling 3.0 | Narrativa de múltiplas tomadas dirigida por IA | Yes | No | Texto, imagem, referência |
Como Usar Gemini Omni Flash no Atlas Cloud
Comece em minutos — siga estes passos simples para integrar e implantar modelos pela plataforma da Atlas Cloud.
Crie uma Conta no Atlas Cloud
Cadastre-se em atlascloud.ai e conclua a verificação. Novos usuários recebem créditos gratuitos para explorar a plataforma e testar modelos.
Por Que Usar Gemini Omni Flash no Atlas Cloud
Combine modelos avançados de Gemini Omni Flash com a plataforma acelerada por GPU do Atlas Cloud, fornecendo desempenho, escalabilidade e experiência de desenvolvimento incomparáveis.
Desempenho e Flexibilidade
Baixa Latência:
Inferência otimizada por GPU para respostas em tempo real.
API Unificada:
Uma única integração para acessar Gemini Omni Flash, GPT, Gemini e DeepSeek.
Preços Transparentes:
Faturamento por Token, suporta modo Serverless.
Empresa e Escala
Experiência do Desenvolvedor:
SDK, análise de dados, ferramentas de ajuste fino e modelos tudo em um.
Confiabilidade:
99.99% de disponibilidade, controle de permissões RBAC, logs de conformidade.
Segurança e Conformidade:
Certificação SOC 2 Type II, conformidade HIPAA, soberania de dados nos EUA.
Perguntas frequentes sobre o Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Explorar Mais Séries
Seedance 2.0
A API do Seedance 2.0 oferece acesso de produção ao modelo de vídeo multimodal da ByteDance — entradas quadrimodais (texto, imagem, vídeo, áudio) e um sistema "Universal Reference" líder do setor que fixa a composição, o movimento da câmera e as ações dos personagens entre as cenas. Integre um controle de nível de diretor com uma única chamada de API, uma taxa fixa de $0,09/s, chave instantânea e sem lista de espera — respaldado por tempo de atividade e conformidade de nível corporativo. O Seedance 2.0 Native 4K já está no ar!
Grok Imagine
A Grok Imagine API oferece aos desenvolvedores a geração de imagens, vídeos e áudio da xAI em um único pacote. Ela produz imagens de até 2K com renderização de texto multilíngue, além de vídeos de até 15 segundos com áudio nativo sincronizado e edição baseada em referências. Na Atlas Cloud, uma única chave executa todos os modos do Grok Imagine, permitindo que você alterne entre imagem, vídeo e áudio sem configurações separadas, a partir de US$ 0,02 por imagem e US$ 0,05 por segundo.
Gemini Omni Flash
A Gemini Omni API traz para o seu stack o modelo multimodal de geração e edição de vídeo do Google DeepMind, apresentado no Google I/O 2026. O Gemini Omni funde o motor de raciocínio do Gemini com mídia generativa, aceitando qualquer combinação de texto, imagens, vídeo e áudio para produzir resultados consistentes e fundamentados em conhecimento. Refine os resultados por meio de conversas naturais — troque objetos, reescreva cenas e mude estilos, enquanto a física, os personagens e a continuidade permanecem intactos. A Atlas Cloud oferece toda a linha Gemini Omni Flash — texto para vídeo, imagem para vídeo com até 7 imagens de referência e referência para vídeo — por meio de uma única API unificada, com preços transparentes por segundo a partir de $0.112 e sem assinatura. Comece a construir hoje mesmo.
GPT Image 2
A API do GPT Image 2 dá aos desenvolvedores acesso ao mais recente modelo de imagem da OpenAI, o sucessor do GPT Image 1.5. Ele gera e edita imagens com renderização de texto precisa em caracteres latinos e CJK, além de uma forte composição para pôsteres, mockups e infográficos. Na Atlas Cloud, você o acessa através de uma API unificada junto a mais de 300 modelos, com créditos gratuitos, 99,99% de tempo de atividade e sem a necessidade de verificação de organização da OpenAI.
Os modelos criativos mais poderosos do Google estão todos disponíveis na Atlas Cloud. O Veo 3.1 oferece geração de vídeo cinematográfico, o Nano Banana 2 impulsiona a criação de imagens de alta fidelidade e o Gemini traz inteligência multimodal para cada fluxo de trabalho. Acesse o pacote completo de modelos do Google por meio de uma única API key com disponibilidade Day-0 e preços de pagamento conforme o uso (pay-as-you-go).
Seedance 2.0 Mini
O Seedance 2.0 Mini leva a geração de vídeo multimodal da ByteDance para fluxos de trabalho onde a velocidade e o custo são essenciais. Ele oferece os principais recursos do Seedance 2.0 com menor impacto — geração mais rápida, menor custo por vídeo e a mesma integração de API que você já usa. Para equipes que executam pipelines de alto volume ou prototipagem em escala, o Mini é a opção padrão prática.
ByteDance
Da geração de vídeo cinematográfico à criação de imagens de alta fidelidade, os modelos mais poderosos da ByteDance estão disponíveis no Atlas Cloud. Execute o Seedance e o Seedream em grande escala com os preços de inferência mais baixos e zero custos indiretos de infraestrutura.
Alibaba
O Atlas Cloud reúne toda a linha de modelos da Alibaba sob uma única API: Qwen para tarefas de linguagem e imagem, e Wan para geração de vídeo em até 1080p. Acesse cada modelo no formato pré-pago (pay-as-you-go) sem necessidade de assinaturas. A API da Alibaba está disponível por meio de uma única URL base usando seu cliente compatível com OpenAI existente.
OpenAI
O Atlas Cloud oferece acesso a toda a linha da API da OpenAI, desde o GPT Image 2 para geração de imagens até o Sora 2 para vídeo. Todos os modelos estão disponíveis na modalidade de pagamento conforme o uso, sem compromisso mensal. Integre-se trocando apenas uma URL base usando a API compatível com a OpenAI.
xAI
Construa pipelines completos de imagem e vídeo usando a xAI API no Atlas Cloud. Gere em 2K, edite com imagens de referência e anime imagens em clipes sincronizados com áudio.
Kwaivgi
A API da Kwaivgi com preço 15% abaixo do padrão. A Atlas Cloud oferece acesso Day-0 a novos lançamentos da Kling com preços de pagamento conforme o uso e sem limite de assentos. Uma conta, uma chave, todos os modelos da Kling do nível padrão ao nível master.
Seedream 5.0 Pro
A API do Seedream 5.0 Pro fornece aos desenvolvedores o modelo de edição de imagens controlável da ByteDance no Atlas Cloud. Ela posiciona as edições com precisão usando âncoras e coordenadas, separa as imagens em camadas editáveis, funde múltiplas referências e combina cores e materiais exatos, com texto multilíngue em 2K e 3K. No Atlas Cloud, você pode acessá-lo por meio de uma única chave!


