MiniMax LLM Models
As a premier suite of Large Language Models (LLMs) developed by MiniMax AI, MiniMax is engineered to redefine real-world productivity through cutting-edge artificial intelligence. The ecosystem features MiniMax M2.5, which is purpose-built for high-efficiency professional environments, and MiniMax M2.1, a model that offers significantly enhanced multi-language programming capabilities to master complex, large-scale technical tasks. By achieving SOTA performance in coding, agentic tool use, intelligent search, and office workflow automation, MiniMax empowers users to streamline a wide range of economically valuable operations with unparalleled precision and reliability.
Explorar Modelos Líderes
O Atlas Cloud oferece os modelos criativos mais avançados e inovadores do setor.
O Que Faz MiniMax LLM Models Se Destacar
Atlas Cloud fornece os modelos criativos líderes da indústria mais recentes.
Raciocínio em escala de fronteira
Modelos de linguagem de última geração desenvolvidos para raciocínio profundo, resolução de problemas complexos e planejamento em várias etapas.
Compreensão de contexto ultralongo
A atenção estilo Lightning e a arquitetura otimizada permitem que os modelos MiniMax processem e retenham contextos longos,
Desempenho MoE com custo-benefício
Os designs de Mixture-of-Experts proporcionam alta inteligência, baixa latência e uma relação custo-benefício significativamente melhor.
Família de modelos versáteis
De poderosos modelos de propósito geral a variantes otimizadas para programação e agentes.
Confiabilidade de nível empresarial
Infraestrutura estável e escalável com monitoramento e segurança para uso em produção.
Aberto e amigável ao desenvolvedor
APIs ricas, SDKs e lançamentos de pesos abertos dão aos desenvolvedores flexibilidade para integrar, fazer ajustes finos ou auto-hospedar.
Velocidade máxima
Menor custo
| Modelo | Descrição |
|---|---|
| MiniMax M2.5 | O MiniMax M2.5 é um LLM carro-chefe otimizado para a produtividade no mundo real, integrando arquiteturas de inferência avançadas com capacidades expansivas de processamento de contexto de 196,61K; ostentando desempenho SOTA em automação de escritório e busca inteligente, ele serve como um motor de alta eficiência para gerenciar tarefas economicamente valiosas e raciocínio geral complexo em ambientes profissionais. |
| MiniMax M2.1 | O MiniMax M2.1 é um LLM de alto desempenho adaptado para desafios técnicos complexos, integrando programação multilíngue significativamente aprimorada com um processamento de contexto robusto de 196.61K; ostentando precisão excepcional no uso de ferramentas agênticas, serve como base para a construção de Agents sofisticados de agendamento de tarefas e para a resolução de problemas de engenharia intrincados e em grande escala. |
| MiniMax M2 | O MiniMax M2 é um LLM de uso geral SOTA, integrando módulos de raciocínio altamente eficientes com capacidades expansivas de processamento de contexto de 196.61K; ostentando versatilidade competitiva em codificação, pesquisa e fluxos de trabalho profissionais, serve como um pilar confiável para operações empresariais diárias que exigem integração perfeita da execução de tarefas em várias etapas. |
Novos recursos de MiniMax LLM Models + Showcase
A combinação de modelos avançados com a plataforma acelerada por GPU do Atlas Cloud oferece velocidade, escalabilidade e controle criativo incomparáveis para geração de imagens e vídeos.
Programação Avançada e Planejamento de Agentes com MiniMax M2.5
O MiniMax M2.5 suporta mais de 10 linguagens de programação, incluindo Rust, Go e Python, para facilitar o desenvolvimento full-stack abrangente em plataformas Web, móveis e desktop. Ao integrar profundo conhecimento da indústria para formatação de documentos profissionais e modelagem financeira, ele permite transições perfeitas do design da arquitetura do sistema até os testes finais de entrega. É a solução definitiva para engenharia de software complexa e fluxos de trabalho de produtividade de escritório de alta responsabilidade.
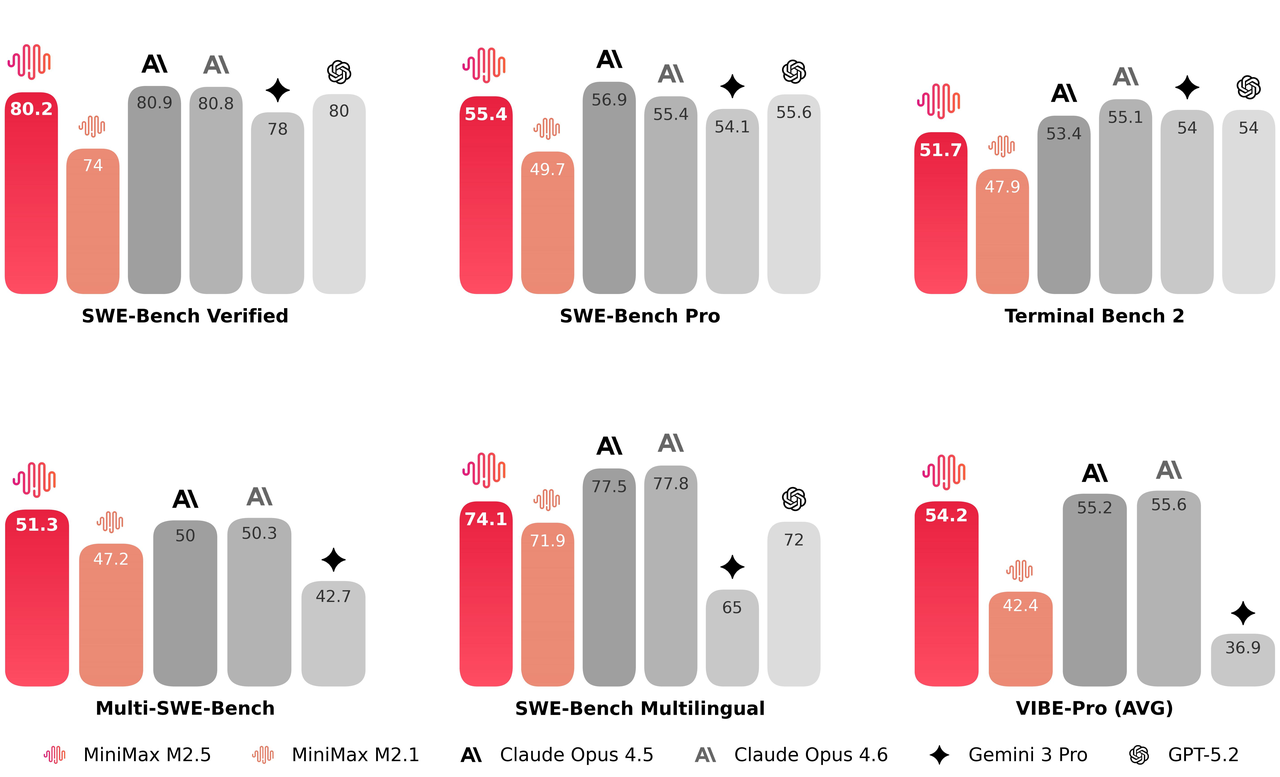
Resposta rápida e eficiência na decisão de tarefas usando MiniMax M2.5
A arquitetura M2.5 alcança um aumento de velocidade de 37% na execução de ponta a ponta, reduzindo significativamente a duração de tarefas complexas de 31,3 para 22,8 minutos no SWE-bench. Ao otimizar a lógica de decomposição de tarefas, o modelo requer 20% menos tokens e rodadas de busca para atingir objetivos em benchmarks como o BrowseComp. Ele oferece uma solução simplificada para tomadas de decisão de alta velocidade, eliminando a sobrecarga computacional redundante.
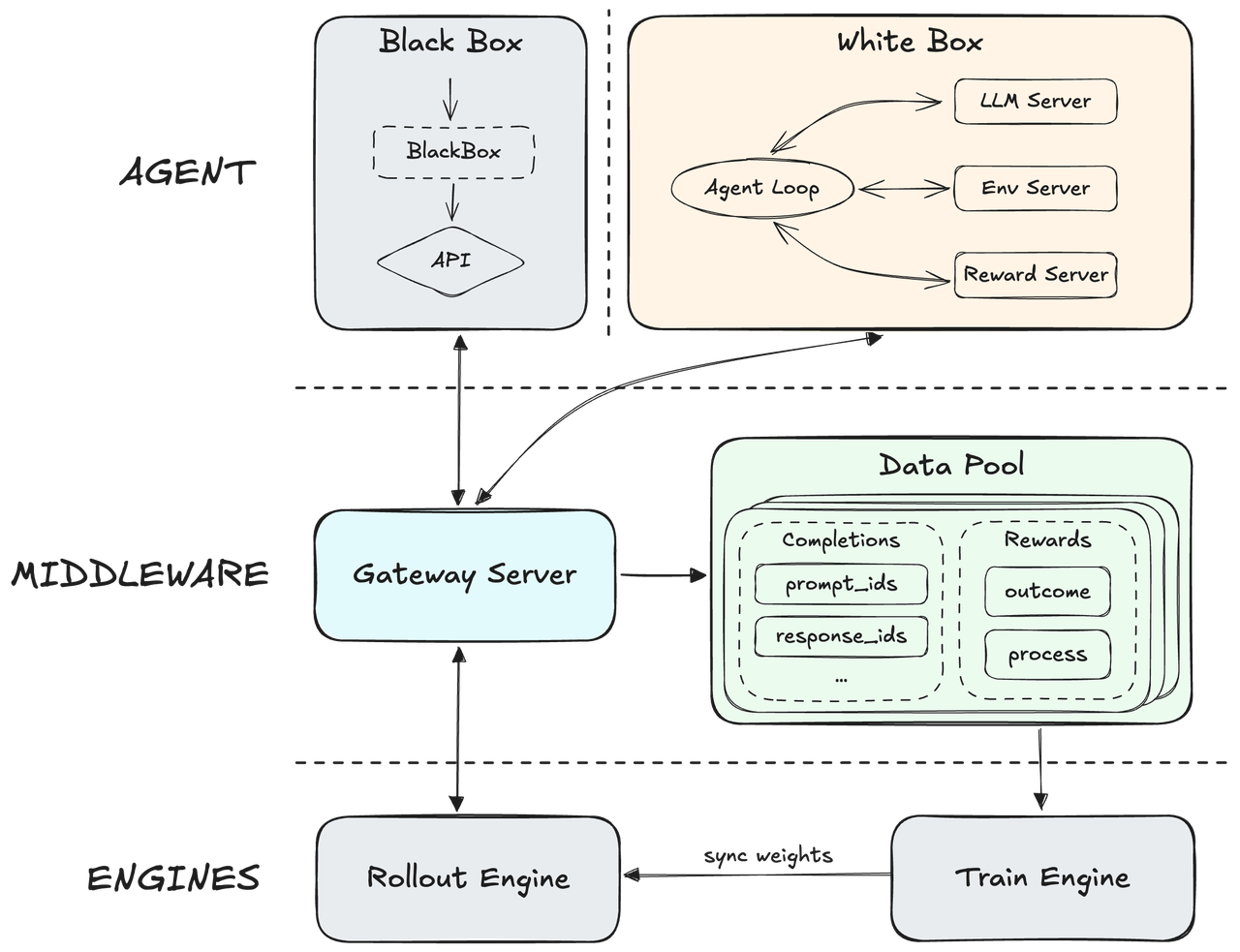
Arquitetura Evolutiva através de Aprendizado por Reforço em Grande Escala usando MiniMax M2.5
Construído sobre uma estrutura nativa de Agent RL, o MiniMax desacopla seu motor central do arcabouço do agente para generalizar em centenas de milhares de diversos ambientes do mundo real. Ele incorpora um sofisticado mecanismo de recompensa de processo que utiliza feedback de execução em tempo real para refinar caminhos de raciocínio e garantir qualidade de saída de elite. Isso cria um sistema altamente adaptável capaz de manter precisão superior enquanto maximiza a velocidade geral de resposta operacional.
O Que Você Pode Fazer com MiniMax LLM Models
Descubra casos de uso práticos e fluxos de trabalho que você pode construir com esta família de modelos — da criação de conteúdo e automação a aplicações de nível produção.
Depuração Full-Stack pronta para produção com MiniMax M2.5
O MiniMax M2.5 atua como um arquiteto técnico sênior, rastreando erros de lógica em APIs de backend, bancos de dados e frameworks de frontend como React ou Swift. Em vez de simples trechos de código, ele refatora módulos inteiros para garantir compatibilidade em todo o sistema. Ideal para prototipagem rápida, a API lida com tudo, desde a configuração do ambiente até testes de casos extremos e modernização de código legado para sistemas empresariais.
Modelagem Financeira e Relatórios Profissionais usando MiniMax M2.5
Para analistas que exigem precisão absoluta, a API automatiza a modelagem financeira complexa no Excel e gera relatórios de pesquisa prontos para publicação, seguindo estruturas de investimento profissionais. Ela interpreta dados brutos para construir lógica de controle de risco e apresentações de slides profissionais com formatação padronizada. Isso se adequa a ambientes de consultoria e bancários de alto risco, onde a precisão e a adesão aos padrões formais de relatórios são inegociáveis.
Pesquisa web autônoma em várias etapas com MiniMax M2.5
O MiniMax M2.5 executa tarefas de pesquisa complexas e em várias rodadas para sintetizar informações díspares da web em resumos executivos coesos. Ao decompor de forma inteligente consultas amplas e navegar com redundância mínima de tokens, ele evita o raciocínio circular para fornecer fatos verificados. É uma ferramenta poderosa para pesquisadores de mercado e equipes de estratégia que precisam de inteligência aprofundada sem filtrar manualmente centenas de fontes.
Comparação de Modelos
Veja como os modelos de diferentes provedores se comparam — compare desempenho, preços e pontos fortes exclusivos para tomar uma decisão informada.
| Modelo | Contexto | Saída máxima | Entrada | Posicionamento |
|---|---|---|---|---|
| MiniMax M2.5 | 196.61K | 196.61K | Texto | Programação agêntica de ponta |
| MiniMax M2 | 196.61K | 196.61K | Texto | Modelo de alto desempenho |
| MiniMax M2 | 196.61K | 196.61K | Texto | Geral topo de linha |
| GLM-5 | 202.75K | 202.75K | Texto | Modelo fundacional carro-chefe |
| DeepSeek V3.2 | 163.84K | 163.84K | Texto | Insígnia Geral |
How to Use MiniMax LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Por Que Usar MiniMax LLM Models no Atlas Cloud
Combine modelos avançados de MiniMax LLM Models com a plataforma acelerada por GPU do Atlas Cloud, fornecendo desempenho, escalabilidade e experiência de desenvolvimento incomparáveis.
Desempenho e Flexibilidade
Baixa Latência:
Inferência otimizada por GPU para respostas em tempo real.
API Unificada:
Uma única integração para acessar MiniMax LLM Models, GPT, Gemini e DeepSeek.
Preços Transparentes:
Faturamento por Token, suporta modo Serverless.
Empresa e Escala
Experiência do Desenvolvedor:
SDK, análise de dados, ferramentas de ajuste fino e modelos tudo em um.
Confiabilidade:
99.99% de disponibilidade, controle de permissões RBAC, logs de conformidade.
Segurança e Conformidade:
Certificação SOC 2 Type II, conformidade HIPAA, soberania de dados nos EUA.
Perguntas Frequentes sobre MiniMax LLM Models
Oferecemos três versões principais: MiniMax M2.5 (o carro-chefe para produtividade de escritório e pesquisa), MiniMax M2.1 (aprimorado para codificação e lógica complexa) e MiniMax M2 (o modelo equilibrado de uso geral).
A série MiniMax M2 suporta uniformemente um contexto ultralongo de 196.61K, permitindo processar centenas de páginas de documentação técnica ou bases de código de engenharia massivas em uma única solicitação.
Nos testes de ponta a ponta do SWE-bench, o M2.5 reduziu o tempo de processamento para tarefas complexas de 31,3 minutos para 22,8 minutos, marcando um aumento de 37% na velocidade geral de conclusão das tarefas.
Explorar Mais Séries
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
Grok-Imagine Models
Grok Imagine Image Quality is xAI's latest AI image generation model, delivering studio-grade visuals with up to 2K resolution and razor-sharp detail. It offers best-in-class text rendering across multiple languages, photorealistic outputs with natural lighting, rich textures, and believable physics, plus tighter prompt following and image editing with reference inputs for precise creative control. Ideal for hero images, ad creatives, product renders, and brand-grade visuals.
Gemini Omni
Gemini Omni (by Google DeepMind) is a video generation and editing model launched on May 20, 2026 at Google I/O that redefines the standard for "reasoning-driven creation," built specifically to solve the core challenge of AI video: making output that actually understands what you mean, not just what you type. It fuses Gemini's reasoning engine with generative capability, accepting any mix of images, text, video, and audio to produce consistent, knowledge-grounded output. Unlike models that start from scratch each time, Omni lets you edit through natural conversation — swapping objects, rewriting scenes, shifting styles — while keeping physics, characters, and continuity intact across every turn.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.


