
ChatGPT API for Frontier GPT 5.6 Reasoning
Atlas Cloud の ChatGPT API は、OpenAI の最新 GPT 5.6 ファミリーを 1 つの統合で利用できるようにし、深いフロンティア推論に対応する Sol、根拠に基づく本番ワークロード向けの Terra、自然な会話とコンテンツ生成向けの Luna を網羅します。すべてのモデルを単一の OpenAI-compatible key でルーティングでき、本番環境レベルの稼働率を期待でき、100 万入力トークンあたり $1 から始まる透明性の高い pay-as-you-go 料金で利用できます。今すぐ構築を始めましょう。
主要モデルを探索
Atlas Cloudは、業界をリードする最新のクリエイティブモデルを提供します。
適切な ChatGPT API Model を選ぶ:すべての Endpoint を比較
フロンティア級の推論から低コストな会話までをカバーする 5 つの text generation endpoint を、透明な従量課金で利用できる単一の OpenAI-compatible key から提供します。
| モダリティ | 説明 |
|---|---|
| GPT 5.6 Sol API (Text to Text) | フロンティア AI ワークロード向けに設計された GPT 5.6 Sol は、複雑なテキストプロンプトを、難度の高い課題解決に適した深い多段階推論の出力へ変換します。標準料金は入力 100 万 token あたり $5、出力 100 万 token あたり $30 で、コストより回答品質を重視する場合のフラッグシップ候補です。 |
| GPT 5.6 Terra API (Text to Text) | 信頼できる本番環境のデフォルトが必要ですか?GPT 5.6 Terra は、プロンプトを実運用のワークフローや分析パイプラインに適した、根拠のある実用的なテキストへ変換します。料金は 100 万 token あたり入力 $2.50、出力 $15 です。実験的な深さより一貫性が重要な、顧客向けアプリケーションでの導入に適しています。 |
| GPT 5.6 Luna API (Text to Text) | 会話系やクリエイティブ系のトラフィックは GPT 5.6 Luna にルーティングできます。自然な対話、コンテンツ生成、パーソナライズされた AI 体験に最適化されたテキストモデルです。料金は 100 万 token あたり入力 $1、出力 $6 で、この ChatGPT API ラインアップの中で最も経済的なエントリーポイントであり、チャット製品や大量のコピー生成に適しています。 |
| GPT 5.4 API (Text to Text) | GPT 5.4 はテキスト指示を、高精度で信頼性の高いコード、長文コンテンツ、構造化された問題解決の出力へ処理します。設計上は高度な multimodal model であり、料金は 100 万 token あたり入力 $2.50、出力 $15 のミッドレンジに位置し、コーディングアシスタントやコンテンツプラットフォームに実用的に適合します。 |
| GPT 5.5 API (Text to Text) | 難しい課題にプレミアムなコストをかける価値がある場合、GPT 5.5 は単一のテキスト endpoint から高度な推論、コーディング、コンテンツ生成を提供します。料金は 100 万 token あたり入力 $5、出力 $30 で、エージェントオーケストレーションや技術分析など、複雑で信頼性が重視されるワークロードを対象としています。 |
ChatGPT API:GPT 5.x ティアとオープンウェイト
1つの ChatGPT API で GPT 5.x の全ラインアップとオープンウェイトの GPT OSS 120B を利用できます。reasoning effort は low から xhigh まで調整でき、テキスト、画像、ファイルを1回の呼び出しで組み合わせ、OpenAI 互換キー1つでライブ Web 検索付きのネイティブツールを呼び出せます。
1回の ChatGPT API 呼び出しでテキスト、画像、ファイルを扱う
1つの ChatGPT API リクエストで、プレーンテキスト、画像 URL、ドキュメントファイルを1つのメッセージにまとめられます。別途 OCR やビジョンサービスを用意する必要がなくなり、スキャン済み契約書の要約やスクリーンショットの読み取りを1回で行えます。
ChatGPT API における指示遵守性
GPT OSS 120B は階層化されたシステムプロンプトに従い、出力全体でフォーマット、制約、トーンをぶれずに安定させます。この信頼性は、自律エージェント、構造化抽出、ルール遵守が必須の本番パイプラインに適しています。
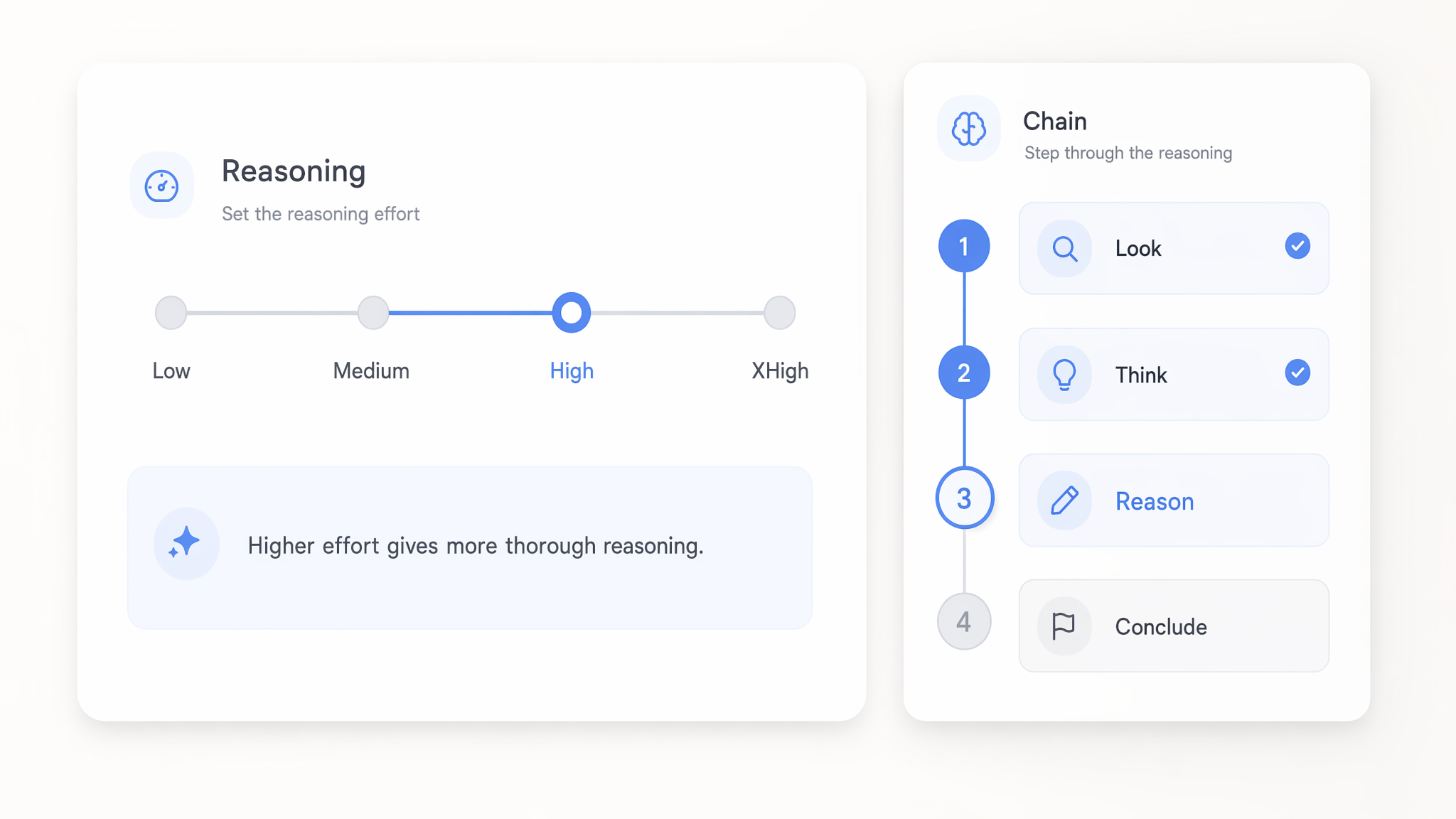
reasoning effort を low から xHigh まで調整
GPT 5.x モデルでは reasoning effort を low から xhigh まで任意に設定し、回答前にどれだけ深く考えさせるかを制御できます。low 設定では単純な呼び出しに高速かつ低コストで回答し、xhigh では難しい多段階ロジックにより多くの計算資源を使います。
完全に所有できる Apache 2.0 ウェイト
GPT OSS 120B は Apache 2.0 ライセンスで配布されており、商用利用と単一の 80GB GPU でのプライベート fine-tuning が可能です。オンプレミスでホストすれば、独自データを社内に保持し、トークン単位の料金を完全に回避できます。

5つの GPT ティアを1つの ChatGPT API で
1つの ChatGPT API で GPT 5.x の全ラインアップを利用でき、料金は入力 100万トークンあたり Luna の $1 から Sol の $5 までです。エンドポイントを変更せずに、各呼び出しをコストと知能要件に合ったティアへ割り当てられます。
Vibecoding 向けに調整された推論
OpenAI o4-mini に近い性能により、GPT OSS 120B は多段階のコード生成や数学的証明を処理できます。自然言語のアイデアを動作する Web アプリに変換し、ネストしたロジックをデバッグし、複雑なタスクスケジューリングフローをオーケストレーションできます。

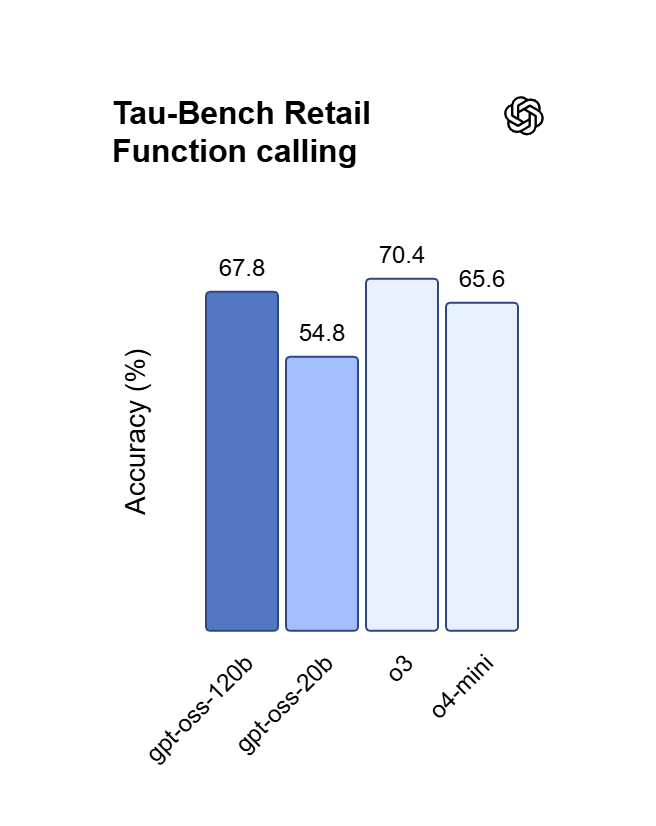
ライブ Web 検索付きの関数呼び出し
GPT 5.x モデルは、自動ツール選択に対応した function calling と、最新の結果を取得する組み込み Web 検索をサポートしています。サーバー送信イベントとして応答をストリーミングでき、prompt caching により GPT 5.6 Sol のキャッシュ済み入力は 100万トークンあたり $0.5 まで削減されます。
1つのプロンプト、3つの競合:ChatGPT API 真っ向比較
まったく同じビルド指示を、ChatGPT API 経由のモデルと2つの競合フラッグシップに与え、生の HTML レスポンスを一切手を加えずにレンダリングしました。推論の深さ、コード品質、デザインセンスを横並びで比較できます。
単一の自己完結型 HTML ファイルを作成してください(インライン CSS と JavaScript のみ — 外部ライブラリ、CDN、フレームワーク、フォント、画像 URL は一切使用禁止)。現代的なブラウザで直接開け、フラットな Canvas/SVG ベクターイラストだけで描画される、生きて成長し続けるガラス温室エコシステムシミュレーターとして動作するものにしてください。全画面ビューポートのシーンは、ドーム型のヴィクトリア調温室です。上部には構図を縁取る要素として湾曲したガラスの円蓋が弧を描き、ガラス板は半透明の翡翠グリーンのポリゴンとして描き、柔らかな鏡面ハイライトと細い桟のアウトラインを入れてください。下部には暗い栽培用の土の帯を配置します。アートディレクションはクリーンなベクターイラストです — 葉や茎は、くっきりした葉脈ラインのアウトラインと半透明のレイヤー状の塗りで描き、霧がかったセージグリーンと苔むしたブラウンを基調に、琥珀色の陽光と翡翠色のガラスアクセントを加えたパレットにしてください。フォトリアリズムは禁止、テクスチャとしてのグラデーションも避け、グラフィックで手描きイラストのような印象を保ってください。 中心となるインタラクション:土の任意の場所をクリックするとその位置に種が植えられ、植物が実際の L-system を使ってリアルタイムに成長します — 公理と生成規則、分岐括弧を備えた再帰的な書き換え文法を実装し、インスタンスごとに角度や長さにランダムな揺らぎを加えて、同じ植物が2つとないようにしてください。派生過程をアニメーション化し、枝が数秒かけて伸び、分岐し、葉をほどいていくようにし、完成形が突然表示されないようにします。熱帯のシダやつる植物は、ドラッグ可能な太陽に向かって光屈性で曲がり、巻き付くようにしてください。ユーザーが空のどこへでもつかんでドラッグできる、光る琥珀色の太陽の円盤を描画し、成長中のすべての先端が太陽の現在位置へ向けて成長方向を継続的に再調整するようにしてください。太陽をドラッグすると、庭全体の傾きや登っていく方向が目に見えて変わる必要があります。芽生えはイージングアニメーションでほどけ、ガラスには結露の滴が形成され、ループしながらゆっくり滑り落ちます。 すべてを、太陽の位置に連動した昼夜サイクルで駆動してください。環境光と空のウォッシュは、暖かなゴールドから冷たいブルーへのグラデーション上をなめらかに移行します。太陽の位置によって、床に落ちる植物の柔らかな影の方向と長さ、そしてガラス上を漂う光の斑点が決まります。夕暮れには、ホタルが小さく脈打つ光点として葉の間を漂いながらフェードインします。構図は、植物の成長が根元から中央上方へ放射状に広がり、ドームの弧の内側に収まるようにしてください。requestAnimationFrame を使って、静かに呼吸するような連続アニメーションループにし、画面上に多数の植物があっても滑らかなパフォーマンスを保ってください。さりげなく邪魔にならないコントロール(例:時刻のスライダーまたは自動進行トグル、リセット/クリアボタン)を含め、イラストの雰囲気に合うスタイルにしてください。さらに、土をクリックして植え、太陽をドラッグして成長を導くことを伝える1行のヒントを表示してください。あらゆるウィンドウサイズにレスポンシブ対応し、感情的なトーンは穏やかで、静かで、生きているものにしてください — 朝一番の光が差し込み、柔らかな芽が一斉に開いていくように。これはゲームやダッシュボードではなく、ジェネレーティブなシミュレーションです。真に再帰的な成長アルゴリズム、アニメーションループ、光・影・光屈性の物理表現を優先してください。
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
単一ファイルで完結する HTML ページを作成してください。内容は、8つの業界セクターについて5年間分の架空だが内部的に一貫したデータを持つ、インタラクティブなグローバルスタートアップ資金調達ダッシュボードです。CSS と JavaScript はすべてインラインにし、外部依存はゼロ、チャートライブラリ、CDN、画像は使用しないでください。canvas または SVG 上に、手書き実装の可視化を3つ描画してください。ユーザーがスライダーで年を選ぶとイージング付きで再ソートされるアニメーション棒グラフ、ホバー時に正確な値と縦方向のトラッキングガイドを表示する折れ線グラフ、ホバー時にセグメントがスプリングアニメーションで広がるドーナツグラフです。バイオレットからティールへのアクセントパレットを使ったダークでモダンな UI、4つの KPI 統計カード内のアニメーション数値カウンター、すべてのチャートを即座に更新するセクターフィルター行のトグルチップ、なめらかな色遷移を伴うライト/ダークテーマ切り替えを含めてください。レイアウトはレスポンシブにし、768px 未満では1カラムに折りたたまれるようにしてください。すべてのインタラクションはページのリロードなしにリアルタイムで反応する必要があります。
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
ChatGPT API が対応できるあらゆるワークロード
エージェント型コーディングや構造化抽出から、根拠に基づくサポートチャット、大量コンテンツ生成まで。Atlas Cloud 上の ChatGPT API は、1つの OpenAI-compatible key で各ジョブを最適な GPT 5.6 tier にルーティングします。

ChatGPT API でエージェント型コーディングツールを出荷
複雑なリファクタリングや複数ファイルにまたがるコード生成は、最先端のエンジニアリングワークロード向けに設計された、ファミリーの深い推論 tier である GPT 5.6 Sol にルーティングできます。コーディングコパイロット、自動レビュー bot、テストジェネレーターを構築するチームは、本番品質のロジックを利用できます。

ブランドトーンを保ったコンテンツ生成を大規模に
ファミリーのクリエイティブ tier である GPT 5.6 Luna は、ブログ記事、商品説明、ローカライズ済みコピーを、自然なトーンとパーソナライズされた出力で作成します。コンテンツチームや ecommerce プラットフォームは、ブランドボイスを損なうことなく大量のコピーを生成できます。

ChatGPT API でサポートアシスタントを強化
台本から外れない chatbot が必要ですか?GPT 5.6 Terra は、本番環境の会話向けに設計された、信頼性が高く根拠に基づく応答を提供します。サポートチームや SaaS 製品は、チケット対応を自動化し、繰り返しの問い合わせを安定して削減できます。

検索拡張型ナレッジシステム
ポリシーマニュアル全体や研究アーカイブを long-context model に投入し、ソースへの忠実性を保った根拠ある回答を取得できます。法務、医療、社内検索チームは、retrieval-augmented question answering のための信頼できるエンジンを手に入れられます。

ChatGPT API による構造化データ抽出
煩雑な請求書、メール、PDF を、下流システムが信頼できるクリーンな JSON に変換します。信頼性の高い指示追従によりスキーマを維持し、ドリフトを許容できないデータパイプライン、CRM 自動化、分析ワークフローを支えます。

あらゆるタスクを最適な Model Tier に対応付け
コストとレイテンシが重要な場合は、1つの OpenAI-compatible key で Sol、Terra、Luna を切り替えられます。スタートアップやインディー開発者は従量課金で素早くプロトタイプを作成し、そのまま同じ統合を本番規模へ拡張できます。
| モデル | コンテキスト | 最大出力 | 入力 | 位置づけ |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | テキスト | 高効率推論 LLM |
| GLM-5 | 202.75K | 202.75K | テキスト | フラッグシップ基盤モデル |
| DeepSeek V3.2 | 163.84K | 163.84K | テキスト | 汎用フラッグシップモデル |
| MiniMax-M2.5 | 204.8K | 196.6K | テキスト | SOTA エージェント型コーディング |
Atlas Cloud で ChatGPT を使う方法
数分で始められます — 以下の簡単なステップに従って、Atlas Cloud プラットフォームでモデルを統合・デプロイしましょう。
Atlas Cloud アカウントを作成
atlascloud.ai でサインアップし、認証を完了します。新規ユーザーには無料クレジットが付与され、プラットフォームの探索やモデルのテストに使用できます。
Atlas CloudでChatGPTを使用する理由
高度なChatGPTモデルとAtlas CloudのGPU加速プラットフォームを組み合わせることで、比類のないパフォーマンス、スケーラビリティ、開発者エクスペリエンスを提供。
パフォーマンスと柔軟性
低レイテンシ:
リアルタイム推論のためのGPU最適化推論。
統合API:
1つの統合でChatGPT、GPT、Gemini、DeepSeekを実行。
透明な料金:
サーバーレスオプション付きの予測可能なtoken単位の課金。
エンタープライズとスケール
開発者エクスペリエンス:
SDK、分析、ファインチューニングツール、テンプレート。
信頼性:
99.99%の稼働率、RBAC、コンプライアンス対応ロギング。
セキュリティとコンプライアンス:
SOC 2 Type II、HIPAA準拠、米国内のデータ主権。
ChatGPT API:開発者の疑問に回答
ChatGPT APIを使うと、開発者はチャットインターフェイス経由ではなく、OpenAIのGPTモデルへプログラムからプロンプトを送信し、補完結果を受け取れます。Atlas Cloudでは、1つのOpenAI互換エンドポイントから、GPT 5.4およびGPT 5.5に加えて、GPT 5.6の全ラインアップにアクセスできます。すべての呼び出しはトークン単位で課金され、透明性の高い従量課金制のため、生成した分だけ支払います。
深い推論から日常的なチャットまでをカバーする5つのモデルを利用できます。GPT 5.6 Solは高度な問題解決や最先端のワークロード向け、GPT 5.6 Terraは信頼性の高い本番ワークフロー向け、GPT 5.6 Lunaは自然な会話やコンテンツ生成向けに調整されています。GPT 5.4とGPT 5.5は、実績ある汎用性能を求めるチームに向けて、マルチモーダル推論とコーディング機能を提供します。
APIキーを1つ生成し、ベースURLをhttps://api.atlascloud.ai/v1に設定して、openai/gpt-5.6-terraのようなモデルIDを指定します。ここで提供されるChatGPT APIは完全にOpenAI互換であるため、既存のOpenAI SDKコードはベースURLとキーを変更するだけで動作します。ウェイトリストもサブスクリプションも不要で、新リリースはDay-0アクセスで利用できるため、その日のうちに最初のリクエストを送信できます。
料金は選択するモデルに応じて変わります。GPT 5.6 Lunaは最も低コストで、100万入力トークンあたり$1、100万出力トークンあたり$6です。GPT 5.6 Terraは$2.5と$15、GPT 5.6 Solは$5と$30です。プロンプトキャッシュにより繰り返し入力のコストを削減でき、課金は従量課金制のままなので、使用したトークン分だけ請求されます。
はい。エンドポイントはOpenAI Chat Completions形式に準拠しているため、公式のOpenAI SDK、LangChain、ほとんどのOpenAI互換ライブラリは、ベースURLとキーを差し替えるだけで動作します。つまり、既存のChatGPT API連携は、リクエストロジックを書き換えずに移行できます。
ストリーミングとfunction callingはいずれもOpenAIの実装と同じように動作するため、トークン単位の出力にはstreamをtrueに設定し、function callsをトリガーするにはtools配列を渡します。構造化されたJSONレスポンスも同じOpenAI互換のリクエスト形式に従うため、エージェントのオーケストレーションやデータ抽出パイプラインを予測可能に保てます。
これらのモデルは、長文ドキュメントやリポジトリ全体を扱うワークフロー向けに、大きなプロンプトを受け付けます。料金は272,000トークンを境に段階設定されており、それ未満のプロンプトには標準料金、272,000トークンを超えるプロンプトには別の料金が適用されます。そのため、広範なコンテキストを1回のリクエストで投入でき、プロンプトが大きくなるにつれて料金がどのように変わるかを正確に把握できます。
用途に合わせてモデルを選びましょう。最先端の推論や高度な問題解決が必要な場合はGPT 5.6 Sol、堅実で本番品質の分析にはGPT 5.6 Terra、コストを最重視する会話型またはクリエイティブな作業にはGPT 5.6 Lunaが適しています。GPT 5.4とGPT 5.5も、コーディングや一般的な推論向けの強力なマルチモーダル選択肢です。
Atlas Cloudは、トラフィックに合わせてスケールするマネージドインフラ上でChatGPT APIを運用するため、セルフホスティングで必要になるGPUのプロビジョニングやノードのオーケストレーションを避けられます。新しいモデルバージョンはDay-0アクセスで提供されるため、移行作業なしに最新状態を維持できます。ニーズが拡大しても、同じOpenAI互換キーでファミリー内のすべてのモデルを利用できるため、スケーリングのために新たな連携を作る必要はありません。
さらにファミリーを探索
Seedance 2.0
Seedance 2.0 APIは、ByteDanceのマルチモーダルビデオモデルへのプロダクションアクセスを提供します。これには、クアッドモーダル入力(テキスト、画像、ビデオ、オーディオ)と、ショット間で構図、カメラワーク、キャラクターのアクションを固定する業界最高水準の「Universal Reference」システムが含まれます。1回のAPIコールでディレクターレベルの制御を統合でき、一律$0.09/秒、即時キー発行、順番待ちリストなしで利用可能です。これらはエンタープライズクラスの稼働率とコンプライアンスによって裏付けられています。Seedance 2.0 Native 4Kが提供開始されました!
Grok Imagine
Grok Imagine API は、開発者に xAI の画像、動画、音声生成を1つのスイートで提供します。多言語テキストレンダリングを備えた最大 2K の画像に加え、ネイティブで同期された音声とリファレンスベースの編集を備えた最大15秒の動画を生成します。Atlas Cloud 上では、1つのキーで Grok Imagine のすべてのモードを実行できるため、個別の設定なしで画像、動画、音声の間を移行できます。料金は画像1枚あたり0.02ドル、1秒あたり0.05ドルからです。
Gemini Omni Flash
Gemini Omni API は、Google I/O 2026 で発表された Google DeepMind のマルチモーダル動画生成・編集モデルを、あなたのスタックで利用可能にします。Gemini Omni は Gemini の推論エンジンと生成メディアを融合し、テキスト・画像・動画・音声を自由に組み合わせた入力から、一貫性があり知識に裏付けられた出力を生成します。自然な対話で結果を磨き上げましょう。オブジェクトの差し替え、シーンの書き換え、スタイルの変更を行っても、物理法則、キャラクター、連続性はそのまま保たれます。Atlas Cloud は、テキストからの動画生成、最大 7 枚の参照画像に対応した画像からの動画生成、そして参照ベースの動画生成という Gemini Omni Flash の全ラインアップを、単一の統合 API で提供します。料金は $0.112 からの秒単位の透明な従量課金で、サブスクリプションは不要です。今すぐ開発を始めましょう。
GPT Image 2
GPT Image 2 API は、GPT Image 1.5 の後継となる OpenAI の最新画像モデルへのアクセスを開発者に提供します。ラテン文字およびCJKスクリプト全体で正確なテキストレンダリングを使用して画像を生成および編集できるほか、ポスター、モックアップ、インフォグラフィック向けの強力なコンポジション(構図)機能を備えています。Atlas Cloud では、300以上のモデルと並んで1つの統合 API を通じてアクセスでき、無料クレジット、99.99% のアップタイムが提供され、OpenAI の組織検証は不要です。
Googleの最も強力なクリエイティブモデルはすべてAtlas Cloudで利用可能です。Veo 3.1はシネマティックな動画生成を実現し、Nano Banana 2は高忠実度な画像作成を強化し、Geminiはあらゆるワークフローにマルチモーダルなインテリジェンスをもたらします。Day-0の可用性と従量課金制(pay-as-you-go)の料金体系を備えた単一のAPI keyを通じて、Googleモデルスイート全体にアクセスできます。
Seedance 2.0 Mini
Seedance 2.0 Mini は、速度とコストが最も重視されるワークフローに ByteDance のマルチモーダル動画生成をもたらします。より軽量なフットプリントで Seedance 2.0 のコア機能を提供し、より高速な生成、動画あたりのコスト削減、そしてすでに使用しているものと同じ API 統合を実現します。大容量のパイプラインを運用したり、大規模なプロトタイピングを行ったりするチームにとって、Mini は実用的なデフォルトの選択肢です。
ByteDance
シネマティックな動画生成から高忠実度の画像作成まで、ByteDanceの最も強力なモデルがAtlas Cloudで利用可能になりました。最低水準の推論価格とゼロのインフラストラクチャオーバーヘッドで、SeedanceとSeedreamを大規模に実行できます。
Alibaba
Atlas Cloudは、Alibabaの全モデルラインナップを単一のAPIに統合します。言語および画像タスク用のQwen、最大1080pの動画生成用のWanが利用可能です。すべてのモデルはサブスクリプション不要の従量課金制(pay-as-you-go)でアクセスできます。Alibaba APIは、既存のOpenAI互換クライアントを使用し、単一のベースURLを介して利用可能です。
OpenAI
Atlas Cloudは、画像生成用のGPT Image 2から動画用のSora 2まで、OpenAI APIの全ラインナップへのアクセスを提供します。すべてのモデルは、月額の固定コミットメントなしの従量課金制でご利用いただけます。OpenAI互換APIを使用し、ベースURLを一つ変更するだけで簡単に組み込むことができます。
xAI
Atlas Cloud 上で xAI API を使用して、完全な画像および動画パイプラインを構築します。2K解像度での生成、参照画像を使用した編集、そして画像を音声同期クリップへとアニメーション化することが可能です。
Kwaivgi
Kwaivgi APIを標準価格より15%オフで提供。Atlas Cloudは、新しいKlingリリースへのDay-0アクセスを、従量課金制(Pay-as-you-go)およびシート数無制限で提供します。1つのアカウント、1つのキーで、スタンダードからマスター階層まで、すべてのKlingモデルをご利用いただけます。
Seedream 5.0 Pro
Seedream 5.0 Pro API は、開発者に Atlas Cloud 上で ByteDance の制御可能な画像編集モデルを提供します。アンカーと座標を使用して編集を正確に配置し、画像を編集可能なレイヤーに分離し、複数の参照を融合し、正確な色と素材を一致させ、2K および 3K での多言語テキストをサポートします。Atlas Cloud では、単一のキーでアクセスできます!


