Gemini Omni Flash API for Conversational Video Editing
Gemini Omni API は、Google I/O 2026 で発表された Google DeepMind のマルチモーダル動画生成・編集モデルを、あなたのスタックで利用可能にします。Gemini Omni は Gemini の推論エンジンと生成メディアを融合し、テキスト・画像・動画・音声を自由に組み合わせた入力から、一貫性があり知識に裏付けられた出力を生成します。自然な対話で結果を磨き上げましょう。オブジェクトの差し替え、シーンの書き換え、スタイルの変更を行っても、物理法則、キャラクター、連続性はそのまま保たれます。Atlas Cloud は、テキストからの動画生成、最大 7 枚の参照画像に対応した画像からの動画生成、そして参照ベースの動画生成という Gemini Omni Flash の全ラインアップを、単一の統合 API で提供します。料金は $0.112 からの秒単位の透明な従量課金で、サブスクリプションは不要です。今すぐ開発を始めましょう。
主要モデルを探索
Atlas Cloudは、業界をリードする最新のクリエイティブモデルを提供します。







Gemini Omni Flash API で生成する4つの方法
テキストから動画、画像から動画、リファレンス主導の生成、対話型編集まで、タスクに適した Gemini Omni Flash API エンドポイントを選択してください。
| モダリティ | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | テキストプロンプトしかありませんか?Gemini Omni Flash Text-to-Video APIは、それを1回の処理で同期された音声付きの720pクリップに変換し、最大10秒の動画に対してシーン、モーション、カメラにわたる推論主導の制御に従います。 |
| Gemini Omni Flash Image-to-Video API (I2V) | Gemini Omni Flash Image-to-Video APIは、元の画像を最初のフレームとして固定し、静止画を動画へとアニメーション化します。自然な動きと同期したオーディオにより、製品写真、ポートレート、コンセプトを720pの解像度で鮮やかに表現します。 |
| Gemini Omni Flash Reference-to-Video API (R2V) | Gemini Omni Flash Reference-to-Video APIを使用して、最大7枚の参照画像と3つの短いビデオクリップで生成をガイドします。クリップ全体でキャラクター、スタイル、シーンの一貫性を保つため、ブランドコンテンツやシリーズコンテンツに最適です。 |
| Gemini Omni Flash Video Edit API | クリップの変更が必要な場合、Gemini Omni Flash Video Edit API はステートフルな Interactions API を通じて自然言語の指示を適用します。ターン間で映像の他の部分をそのまま維持しながら、要素の入れ替え、照明の調整、シーンのスタイルの再設定を行います。 |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
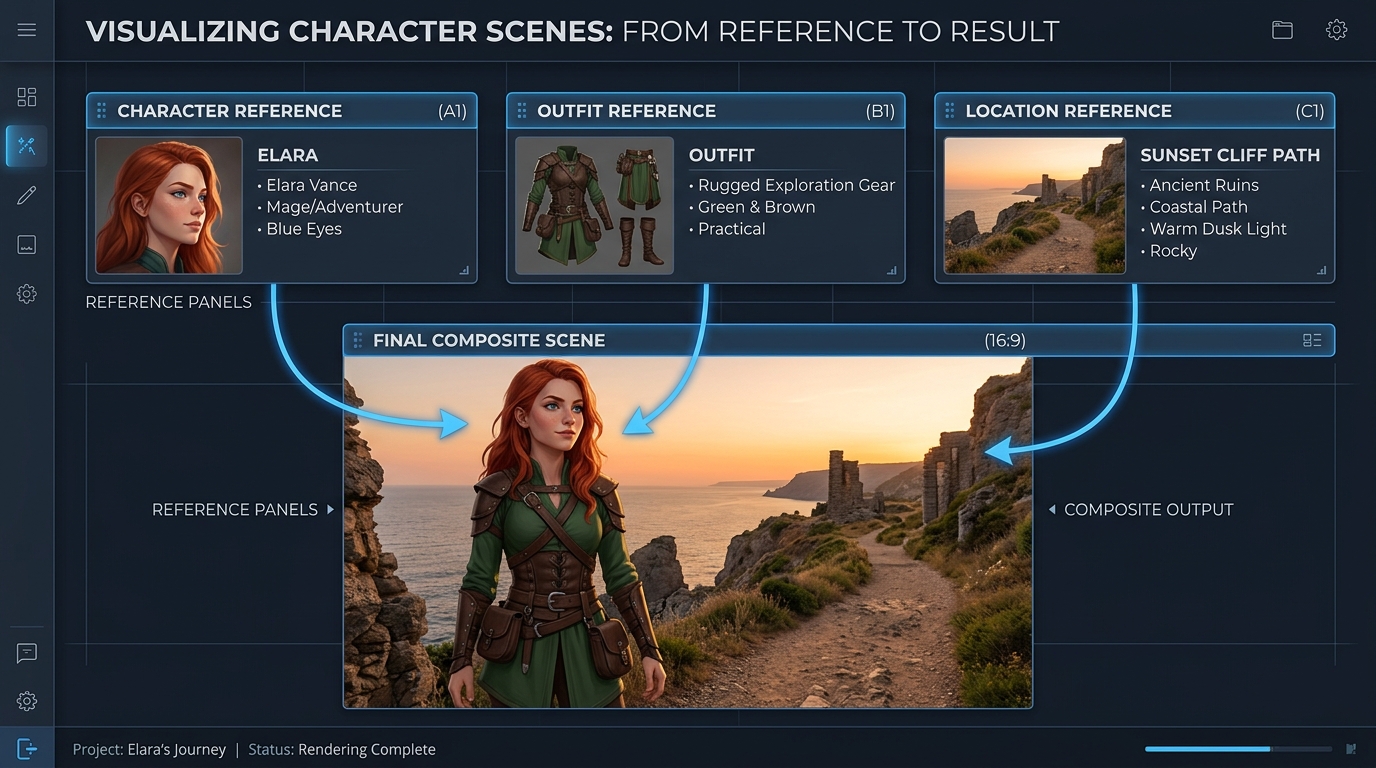
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Gemini Omni Flash API の比較分析
異なるプロバイダーのモデルを比較 — パフォーマンス、料金、独自の強みを確認して最適な選択を。
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | 対話を通じた完成動画の編集 | Yes | はい、ステートフルです | テキスト、画像、動画、音声 |
| Veo 3.1 | シーン拡張機能を備えたシネマティッククリップ | Yes | No | テキスト、画像、参照 |
| Seedance 2.0 | 最高品質のリファレンス制御動画 | Yes | No | テキスト、画像、動画、音声 |
| Kling 3.0 | マルチショットAIディレクターによるストーリーテリング | Yes | No | テキスト、画像、リファレンス |
Atlas Cloud で Gemini Omni Flash を使う方法
数分で始められます — 以下の簡単なステップに従って、Atlas Cloud プラットフォームでモデルを統合・デプロイしましょう。
Atlas Cloud アカウントを作成
atlascloud.ai でサインアップし、認証を完了します。新規ユーザーには無料クレジットが付与され、プラットフォームの探索やモデルのテストに使用できます。
Atlas CloudでGemini Omni Flashを使用する理由
高度なGemini Omni FlashモデルとAtlas CloudのGPU加速プラットフォームを組み合わせることで、比類のないパフォーマンス、スケーラビリティ、開発者エクスペリエンスを提供。
パフォーマンスと柔軟性
低レイテンシ:
リアルタイム推論のためのGPU最適化推論。
統合API:
1つの統合でGemini Omni Flash、GPT、Gemini、DeepSeekを実行。
透明な料金:
サーバーレスオプション付きの予測可能なtoken単位の課金。
エンタープライズとスケール
開発者エクスペリエンス:
SDK、分析、ファインチューニングツール、テンプレート。
信頼性:
99.99%の稼働率、RBAC、コンプライアンス対応ロギング。
セキュリティとコンプライアンス:
SOC 2 Type II、HIPAA準拠、米国内のデータ主権。
Google Gemini Omni Flash API に関するよくある質問
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
さらにファミリーを探索
Seedance 2.0
Seedance 2.0 APIは、ByteDanceのマルチモーダルビデオモデルへのプロダクションアクセスを提供します。これには、クアッドモーダル入力(テキスト、画像、ビデオ、オーディオ)と、ショット間で構図、カメラワーク、キャラクターのアクションを固定する業界最高水準の「Universal Reference」システムが含まれます。1回のAPIコールでディレクターレベルの制御を統合でき、一律$0.09/秒、即時キー発行、順番待ちリストなしで利用可能です。これらはエンタープライズクラスの稼働率とコンプライアンスによって裏付けられています。Seedance 2.0 Native 4Kが提供開始されました!
Grok Imagine
Grok Imagine API は、開発者に xAI の画像、動画、音声生成を1つのスイートで提供します。多言語テキストレンダリングを備えた最大 2K の画像に加え、ネイティブで同期された音声とリファレンスベースの編集を備えた最大15秒の動画を生成します。Atlas Cloud 上では、1つのキーで Grok Imagine のすべてのモードを実行できるため、個別の設定なしで画像、動画、音声の間を移行できます。料金は画像1枚あたり0.02ドル、1秒あたり0.05ドルからです。
Gemini Omni Flash
Gemini Omni API は、Google I/O 2026 で発表された Google DeepMind のマルチモーダル動画生成・編集モデルを、あなたのスタックで利用可能にします。Gemini Omni は Gemini の推論エンジンと生成メディアを融合し、テキスト・画像・動画・音声を自由に組み合わせた入力から、一貫性があり知識に裏付けられた出力を生成します。自然な対話で結果を磨き上げましょう。オブジェクトの差し替え、シーンの書き換え、スタイルの変更を行っても、物理法則、キャラクター、連続性はそのまま保たれます。Atlas Cloud は、テキストからの動画生成、最大 7 枚の参照画像に対応した画像からの動画生成、そして参照ベースの動画生成という Gemini Omni Flash の全ラインアップを、単一の統合 API で提供します。料金は $0.112 からの秒単位の透明な従量課金で、サブスクリプションは不要です。今すぐ開発を始めましょう。
GPT Image 2
GPT Image 2 API は、GPT Image 1.5 の後継となる OpenAI の最新画像モデルへのアクセスを開発者に提供します。ラテン文字およびCJKスクリプト全体で正確なテキストレンダリングを使用して画像を生成および編集できるほか、ポスター、モックアップ、インフォグラフィック向けの強力なコンポジション(構図)機能を備えています。Atlas Cloud では、300以上のモデルと並んで1つの統合 API を通じてアクセスでき、無料クレジット、99.99% のアップタイムが提供され、OpenAI の組織検証は不要です。
Googleの最も強力なクリエイティブモデルはすべてAtlas Cloudで利用可能です。Veo 3.1はシネマティックな動画生成を実現し、Nano Banana 2は高忠実度な画像作成を強化し、Geminiはあらゆるワークフローにマルチモーダルなインテリジェンスをもたらします。Day-0の可用性と従量課金制(pay-as-you-go)の料金体系を備えた単一のAPI keyを通じて、Googleモデルスイート全体にアクセスできます。
Seedance 2.0 Mini
Seedance 2.0 Mini は、速度とコストが最も重視されるワークフローに ByteDance のマルチモーダル動画生成をもたらします。より軽量なフットプリントで Seedance 2.0 のコア機能を提供し、より高速な生成、動画あたりのコスト削減、そしてすでに使用しているものと同じ API 統合を実現します。大容量のパイプラインを運用したり、大規模なプロトタイピングを行ったりするチームにとって、Mini は実用的なデフォルトの選択肢です。
ByteDance
シネマティックな動画生成から高忠実度の画像作成まで、ByteDanceの最も強力なモデルがAtlas Cloudで利用可能になりました。最低水準の推論価格とゼロのインフラストラクチャオーバーヘッドで、SeedanceとSeedreamを大規模に実行できます。
Alibaba
Atlas Cloudは、Alibabaの全モデルラインナップを単一のAPIに統合します。言語および画像タスク用のQwen、最大1080pの動画生成用のWanが利用可能です。すべてのモデルはサブスクリプション不要の従量課金制(pay-as-you-go)でアクセスできます。Alibaba APIは、既存のOpenAI互換クライアントを使用し、単一のベースURLを介して利用可能です。
OpenAI
Atlas Cloudは、画像生成用のGPT Image 2から動画用のSora 2まで、OpenAI APIの全ラインナップへのアクセスを提供します。すべてのモデルは、月額の固定コミットメントなしの従量課金制でご利用いただけます。OpenAI互換APIを使用し、ベースURLを一つ変更するだけで簡単に組み込むことができます。
xAI
Atlas Cloud 上で xAI API を使用して、完全な画像および動画パイプラインを構築します。2K解像度での生成、参照画像を使用した編集、そして画像を音声同期クリップへとアニメーション化することが可能です。
Kwaivgi
Kwaivgi APIを標準価格より15%オフで提供。Atlas Cloudは、新しいKlingリリースへのDay-0アクセスを、従量課金制(Pay-as-you-go)およびシート数無制限で提供します。1つのアカウント、1つのキーで、スタンダードからマスター階層まで、すべてのKlingモデルをご利用いただけます。
Seedream 5.0 Pro
Seedream 5.0 Pro API は、開発者に Atlas Cloud 上で ByteDance の制御可能な画像編集モデルを提供します。アンカーと座標を使用して編集を正確に配置し、画像を編集可能なレイヤーに分離し、複数の参照を融合し、正確な色と素材を一致させ、2K および 3K での多言語テキストをサポートします。Atlas Cloud では、単一のキーでアクセスできます!


