
Grok API: xAI Reasoning and Coding Models
xAIによって開発されたGrokは、リアルタイムの認識と最先端の推論機能を中心に構築された大規模言語モデルのシリーズです。Grok 4.3はxAIの高度な対話型モデルであり、自然な対話、知識の探索、および1,000,000トークンのコンテキストウィンドウでのマルチステップ推論に最適化されています。Grok Build 0.1は異なる方向性をとっており、ソフトウェア開発専用に構築され、複雑な開発者ワークフローにおけるコード生成、デバッグ、リファクタリングに焦点を当てた機能を備えています。両方のモデルは、OpenAI互換のAPIエンドポイントを介してAtlas Cloudで利用でき、100万トークンあたり1ドルから提供されています。
主要モデルを探索
Atlas Cloudは、業界をリードする最新のクリエイティブモデルを提供します。


Grok API モデルの比較
Match each job to the right model: Grok 4.3 for reasoning across a 1M token context and Grok Build 0.1 for agentic coding, both reachable through one OpenAI-compatible key on Atlas Cloud.
| Model | Type | Best For | Context | Inputs | Function Calling | Structured Outputs | Prompt Caching | Status |
|---|---|---|---|---|---|---|---|---|
| Grok 4.3 | Flagship reasoning model | Logic, analysis, multi-step agents, long-document work | 1M tokens | Text, image | Yes | Yes | Yes | Flagship, GA |
| Grok Build 0.1 | Coding-focused model | Code generation, debugging, refactoring, coding agents | 256K tokens | Text, image | Yes | Yes | Yes | Early access |
Grok API Features
The Grok API brings xAI's reasoning and coding models to Atlas Cloud with a 1M token context window, always-on reasoning, function calling, structured outputs, vision input, and prompt caching, all behind one OpenAI-compatible key.

1M Token Context Window
Grok 4.3 handles up to one million tokens in a single request, enough for full contract sets, large codebases, or long multi-turn agent sessions. The wide context removes chunked retrieval and preserves cross-document reasoning that shorter models lose.
Always-On Reasoning with the Grok API
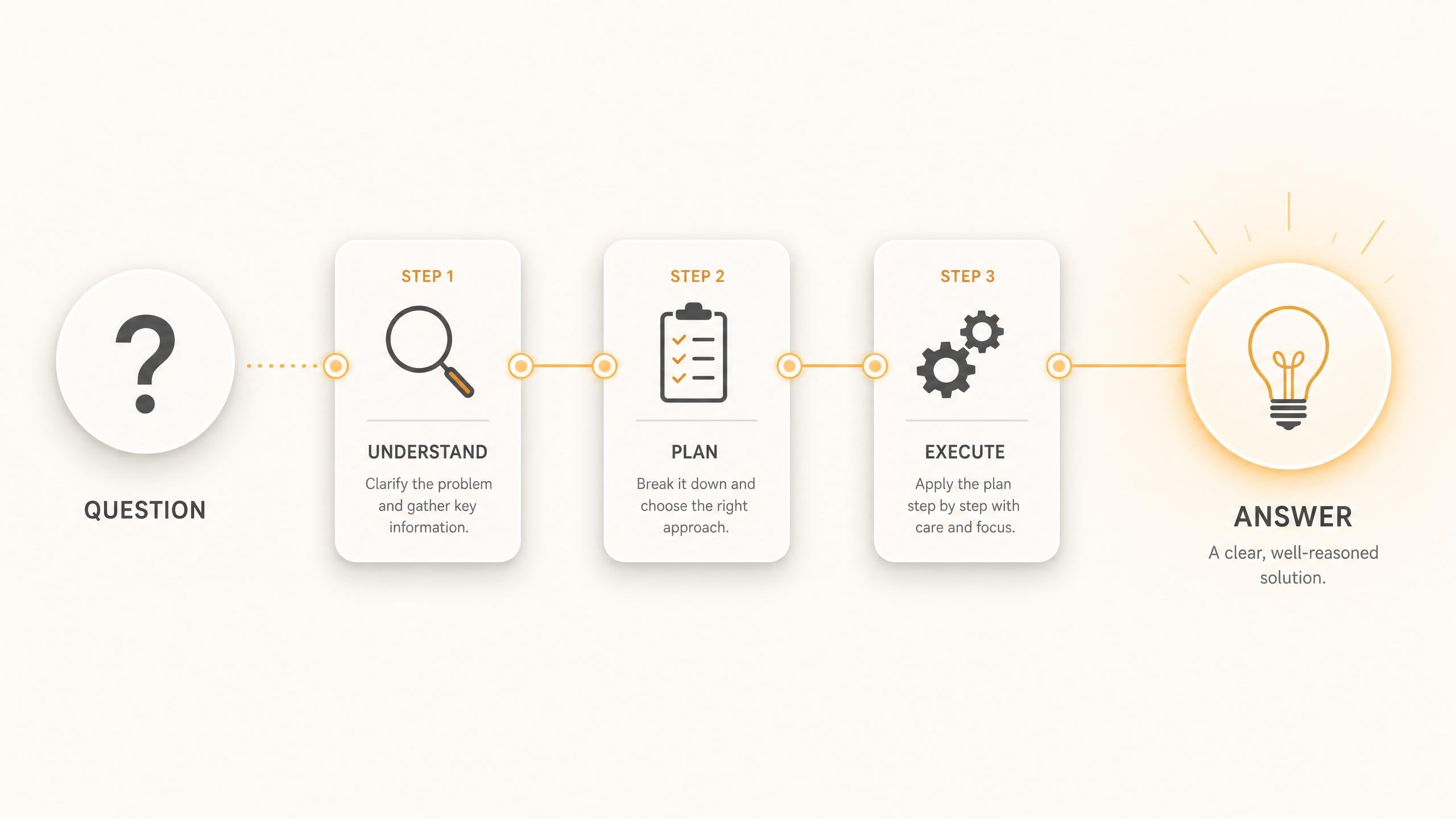
The Grok API runs Grok 4.3 with built-in step-by-step reasoning, tuned for accuracy-critical work like logic, math, and multi-step analysis. The model thinks before it answers, which lifts factual reliability and instruction following on complex prompts.
Agentic Tool Calling
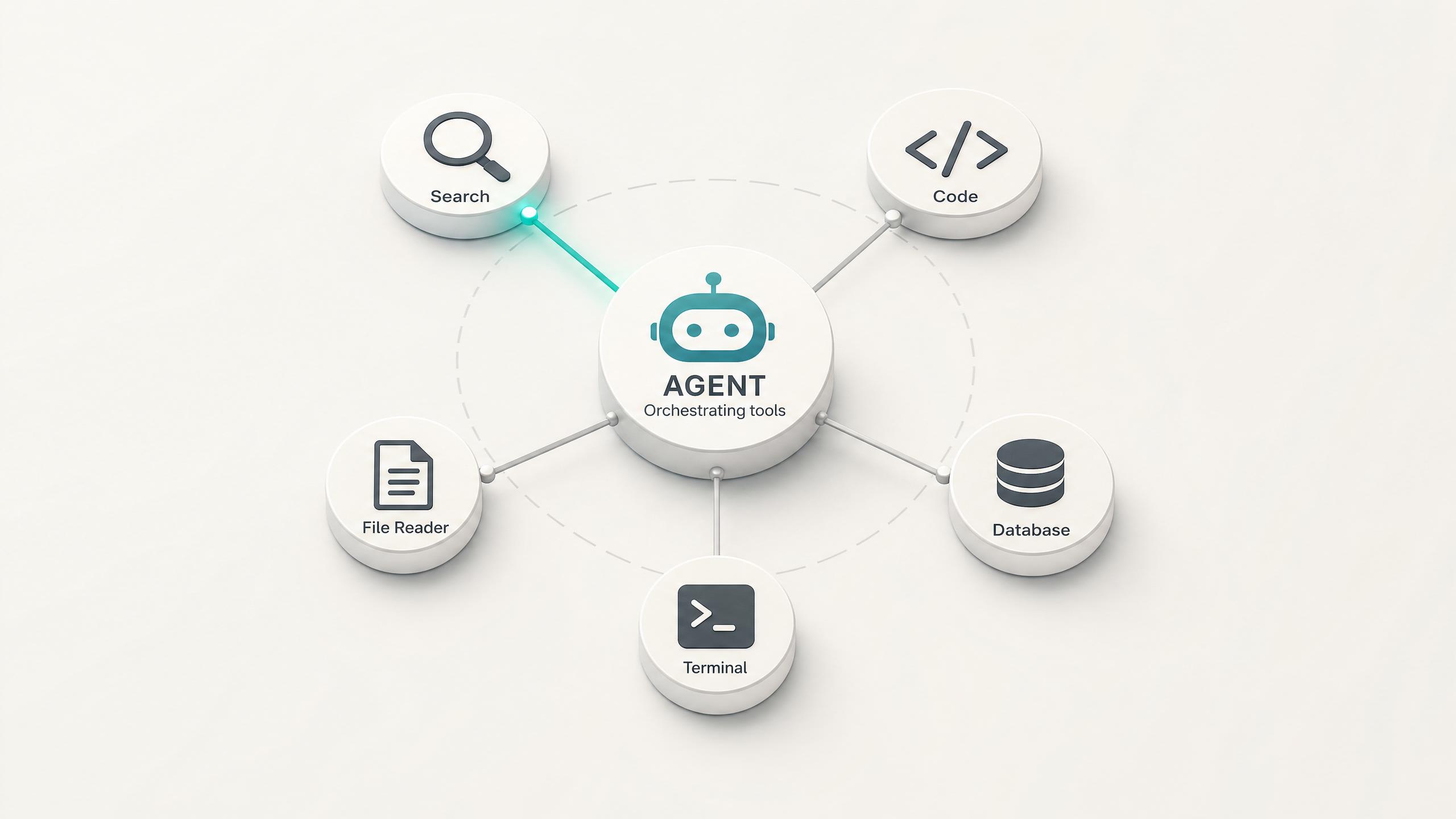
Grok 4.3 is built for agents: it plans, calls functions in sequence, and adjusts on intermediate results. Native function calling lets it trigger tools and APIs mid-task, the foundation for research agents, support bots, and automation that runs without a human in the loop.
Structured Outputs and Vision with the Grok API
The Grok API returns structured JSON that matches your schema, so extracted data flows straight into downstream code. Grok 4.3 also accepts images alongside text, handling diagrams, screenshots, and UI mockups in the same call.

Coding with Grok Build 0.1
Grok Build 0.1 is xAI's coding-tuned model for code generation, debugging, and refactoring across developer workflows, with a 256K token context. It targets interactive coding agents and multi-step development tasks rather than general chat.

Prompt Caching on the Grok API
The Grok API supports prompt caching, which reuses a shared system prompt or context prefix at a lower token rate. For agentic loops that send the same instructions across many calls, this cuts repeated input cost without changing your code.
複数モデル間で共通の単一ビルドプロンプト
同じビルドプロンプトをGrokやAtlas Cloud上の他のモデルに渡し、それぞれが完全で実行可能なウェブページを生成する様子を観察することで、コーディングスタイルと出力結果を並べて比較することができます。
CDNからThree.jsを使用して、インタラクティブな3D太陽系を表示する単一の自己完結型HTMLファイルを構築してください。色と発光で近似されたテクスチャ、アニメーション化された軌道、および星空の背景を備えた太陽と8つの周回惑星をレンダリングします。ユーザーがマウスでカメラを回転およびズームできるようにし、惑星をクリックするとカメラがスムーズにその惑星に向かって飛行し、統計データを表示するようにします。洗練されたオーバーレイタイトルと、時間を加速または減速するためのコントロールを含めてください。Three.jsのCDNインポートを含め、すべてを1つのHTMLファイルに保持します。見事で映画のような視覚効果を優先してください。
Grok 4.3
GLM 5
Grok Build 0.1
アニメーション化された分析ダッシュボードとなる、単一の自己完結型 HTML ファイルを構築してください。アニメーション付きの棒グラフ、読み込み時に自動描画される折れ線グラフ、ドーナツグラフ、およびカウントアップするサマリー統計カードを含めます。ハードコードされたサンプルデータ、スムーズなエントランスアニメーション、およびクリーンでモダンなダークダッシュボードレイアウトを使用してください。各グラフ要素に控えめなホバーツールチップを追加します。外部ライブラリは使用せず、インライン CSS と、canvas または SVG を用いたバニラ JavaScript のみを使用してください。プレミアムな SaaS ダッシュボードのような外観に仕上げてください。
Grok 4.3
GLM 5
Grok Build 0.1
Atlas CloudのGrok LLM APIでできること
Grok 4.3は、100万トークンのコンテキストウィンドウとリアルタイムのウェブおよびX検索を組み合わせており、深い推論とともに最新の情報を必要とする本番環境のワークフローに実用的なものとなっています。

リアルタイムのリサーチおよびインテリジェンスパイプライン
リサーチツールを構築するチームは、Grok 4.3のWeb SearchおよびX Searchアドオンを使用して、個別の検索レイヤーを必要とせずに、WebおよびXからのライブデータを直接生成プロセスに抽出します。これは、モデルのトレーニングのカットオフ日以降に公開された情報に回答が依存するような、競合分析、ニュースの要約、マーケットインテリジェンスのワークフローにおいて有用です。Web SearchおよびX Searchは、xAI API上で1,000回の呼び出しにつき5ドルで課金されます。

コスト効率の高い本番用LLMバックエンド
GPT-4.1やClaude Sonnetから移行するエンジニアリングチームは、Atlas CloudのOpenAI-compatibleエンドポイントを介して、Grok 4.3をドロップインの代替として使用しています。入力トークン100万個あたり1.25ドルで、Grok 4.3の入力コストはGPT-4.1より約37%、Claude Sonnet 4.6より58%安価です。この移行では、既存のSDKコード内でbase URLとAPIキーを変更するだけで済みます。

1Mコンテキストでの長文ドキュメント分析
法務、財務、および研究チームは、Grok 4.3の100万トークンのコンテキストウィンドウを使用して、単一のAPI呼び出しで完全な契約書セット、財務報告書、または技術ドキュメントを処理します。この大規模なコンテキストにより、チャンク化された検索パイプラインが不要になり、短いコンテキストのモデルでは損なわれるドキュメント間の推論が維持されます。複数の分析呼び出しで同じドキュメントコンテキストが再利用される場合、プロンプトキャッシングによりコストがさらに削減されます。

マルチモーダルコーディングと視覚分析
開発者はGrok 4.3の画像理解機能を利用して、図、スクリーンショット、UIモックアップ、エラーログをテキストとともに同じAPIコール内で渡します。これは、エラーのスクリーンショットやシステムアーキテクチャ図が、テキストだけでは伝えられないコンテキストを提供するデバッグワークフローに役立ちます。関数呼び出しと構造化出力が同じコールでサポートされているため、抽出された視覚データを、ダウンストリームの処理に適したスキーマで返すことができます。

エージェント型マルチステップタスク実行
プロダクトチームはGrok 4.3のエージェント最適化を活用し、途中の人間によるプロンプト入力を必要とせずに、複数のステップにわたって計画、実行、および反復を行うエージェントを構築しています。このモデルは、複雑なタスクの分解(高度な目標をサブタスクに分割し、順番にツールを呼び出し、中間結果に基づいて調整すること)に特化して調整されています。関数呼び出しおよびWeb Searchアドオンと組み合わせることで、「競合他社の検索、価格の分析、比較レポートの作成」といった調査から出力までのワークフローを、単一のエージェント実行でカバーします。

データ分析のためのコンテキスト内コード実行
データおよび分析チームは、Code Executionアドオンを備えたGrok 4.3を使用し、推論呼び出し内で直接Pythonを実行し、データを処理して、モデルの推論と共に計算結果を返します。これにより、データ分析ツールや自動レポートパイプラインを構築する際に、独立したコード実行環境が不要になります。Code Executionは、トークンコストとは別に、xAI APIでの1,000回の呼び出しにつき5ドルで課金されます。
Grok APIの比較
コンテキスト、入力、フォーカスの観点から、Atlas Cloud 上で Grok API が他の主要な LLMs とどのように比較されるかをご確認ください。これにより、単一のキーの下で、各タスクを適切なモデルにルーティングできるようになります。
| Model | Provider | Context Window | Inputs | Best For |
|---|---|---|---|---|
| Grok 4.3 | xAI | 1M tokens | Text | Agentic reasoning, long-document analysis, high factual accuracy |
| Grok Build 0.1 | xAI | 256K tokens | Text | Code generation, debugging, refactoring |
| DeepSeek V4 Pro | DeepSeek | 1M tokens | Text | Cost-efficient reasoning and agentic tool use at scale |
| Kimi K2.6 | Moonshot | 262K tokens | Text, image | Long-horizon coding agents and multimodal workflows |
| GLM 5.2 | Z.ai | 202.8K tokens | Text | Long-horizon agentic engineering and project-scale coding |
Atlas Cloud で Grok を使う方法
数分で始められます — 以下の簡単なステップに従って、Atlas Cloud プラットフォームでモデルを統合・デプロイしましょう。
Atlas Cloud アカウントを作成
atlascloud.ai でサインアップし、認証を完了します。新規ユーザーには無料クレジットが付与され、プラットフォームの探索やモデルのテストに使用できます。
Atlas CloudでGrokを使用する理由
高度なGrokモデルとAtlas CloudのGPU加速プラットフォームを組み合わせることで、比類のないパフォーマンス、スケーラビリティ、開発者エクスペリエンスを提供。
パフォーマンスと柔軟性
低レイテンシ:
リアルタイム推論のためのGPU最適化推論。
統合API:
1つの統合でGrok、GPT、Gemini、DeepSeekを実行。
透明な料金:
サーバーレスオプション付きの予測可能なtoken単位の課金。
エンタープライズとスケール
開発者エクスペリエンス:
SDK、分析、ファインチューニングツール、テンプレート。
信頼性:
99.99%の稼働率、RBAC、コンプライアンス対応ロギング。
セキュリティとコンプライアンス:
SOC 2 Type II、HIPAA準拠、米国内のデータ主権。
Grok LLM に関するよくある質問
Atlas Cloudは、xAIの現在のフラッグシップLLMであるGrok 4.3をホストしており、100万入力トークンあたり1.25ドルで利用可能です。このモデルは、単一のAPIでチャット、推論、関数呼び出し、構造化出力、画像理解をサポートしています。追加のGrokバージョンが追加された場合は、Atlas CloudのxAIコレクションページを確認してください。
Grok 4.3は、100万トークンのコンテキストウィンドウをサポートしています。これは、単一の呼び出しで完全なコードベース、長大な研究ドキュメント、または拡張されたマルチターンエージェントセッションを処理するのに十分な大きさです。このコンテキスト制限は、テキスト入力と画像入力の合計に適用されます。
はい。xAI APIはオプションのアドオンとしてWeb SearchとX Searchをサポートしており、1,000コールあたり5ドルで別途請求されます。これにより、Grokは生成中にウェブまたはXからリアルタイムの情報を取得できるようになります。これらの機能には、通常のAPIコールとともに標準のAPIエンドポイントを通じてアクセスできます。
はい。xAI APIはプロンプトキャッシングをサポートしており、同じシステムプロンプトやコンテキストプレフィックスを再利用するリクエストのコストを削減します。キャッシュされた入力トークンは、キャッシュされていないトークンよりも大幅に低いレートで課金されます。これは、複数の呼び出しにわたって同じ命令を送信するエージェントワークフローに特に役立ちます。
はい。Grok 4.3はマルチモーダル入力をサポートしており、同一のAPI呼び出しでテキストと一緒に画像を受け付けることができます。標準のメッセージ形式を通じて、画像のURLやbase64エンコードされた画像を渡すことが可能です。これにより、視覚的な質問応答、ドキュメント分析、画像主導のコード生成などのユースケースが可能になります。
はい。Grok 4.3は、関数呼び出し、構造化出力、およびストリーミング応答をサポートしています。これらの機能は、標準のOpenAI互換の関数スキーマで動作するため、GPTベースの統合からの既存のツール定義を直接転送できます。コード実行もオプションのアドオンとして1,000回の呼び出しにつき5ドルで利用可能です。
プロンプトキャッシングは、長いシステムプロンプトや共有の指示など、繰り返されるコンテキストプレフィックスを、以降の呼び出しにおいて割引された入力トークンレートで再利用します。各リクエストで同じ設定を再送信するチャットボットやエージェントの場合、これによりコードを変更することなく、繰り返される入力コストを削減できます。キャッシュが適用されるように、静的コンテンツをプロンプトの先頭に、可変のユーザーコンテンツを最後に配置してください。
レート制限と同時実行数はアカウント層によって異なるため、エクスポネンシャルバックオフを追加し、429レスポンス時には再試行を行い、トラフィックスパイク時にはリクエストをキューに入れてください。大規模なオフラインジョブの場合、バッチ処理によって大量の作業がリアルタイムの制限を消費するのを防ぎます。スケール時の一般的な隠れたコストは、各呼び出しで会話履歴全体を再送信することです。そのため、スレッド全体ではなく簡潔な要約を渡し、成長に合わせてサポートに連絡して制限を引き上げてください。
Grok APIはトークン使用量に基づく従量課金制を採用しており、入力および出力トークンはリクエストごとに計量され、サブスクリプションは不要です。Atlas Cloud上で300以上の他のモデルと並行してGrokを実行することで、プロバイダーごとに個別の契約を結ぶ代わりに、1つのアカウントと1つの請求書で済みます。プロンプトキャッシングとバッチ処理により、反復的またはオフラインのワークロードにおける実質コストを削減できます。
Atlas Cloudでアカウントを作成し、APIキーを生成して、既存のOpenAI互換クライアントをGrokモデル名を使用してAtlasエンドポイントに向けます。推論にはGrok 4.3、コーディングにはGrok Build 0.1に最初のリクエストを送信し、必要に応じてスケールアップします。同じキーで300以上のモデルにアクセスできるため、追加の設定なしで他のモデルをテストできます。
さらにファミリーを探索
Seedance 2.0
Seedance 2.0 APIは、ByteDanceのマルチモーダルビデオモデルへのプロダクションアクセスを提供します。これには、クアッドモーダル入力(テキスト、画像、ビデオ、オーディオ)と、ショット間で構図、カメラワーク、キャラクターのアクションを固定する業界最高水準の「Universal Reference」システムが含まれます。1回のAPIコールでディレクターレベルの制御を統合でき、一律$0.09/秒、即時キー発行、順番待ちリストなしで利用可能です。これらはエンタープライズクラスの稼働率とコンプライアンスによって裏付けられています。Seedance 2.0 Native 4Kが提供開始されました!
Grok Imagine
Grok Imagine API は、開発者に xAI の画像、動画、音声生成を1つのスイートで提供します。多言語テキストレンダリングを備えた最大 2K の画像に加え、ネイティブで同期された音声とリファレンスベースの編集を備えた最大15秒の動画を生成します。Atlas Cloud 上では、1つのキーで Grok Imagine のすべてのモードを実行できるため、個別の設定なしで画像、動画、音声の間を移行できます。料金は画像1枚あたり0.02ドル、1秒あたり0.05ドルからです。
Gemini Omni Flash
Gemini Omni API は、Google I/O 2026 で発表された Google DeepMind のマルチモーダル動画生成・編集モデルを、あなたのスタックで利用可能にします。Gemini Omni は Gemini の推論エンジンと生成メディアを融合し、テキスト・画像・動画・音声を自由に組み合わせた入力から、一貫性があり知識に裏付けられた出力を生成します。自然な対話で結果を磨き上げましょう。オブジェクトの差し替え、シーンの書き換え、スタイルの変更を行っても、物理法則、キャラクター、連続性はそのまま保たれます。Atlas Cloud は、テキストからの動画生成、最大 7 枚の参照画像に対応した画像からの動画生成、そして参照ベースの動画生成という Gemini Omni Flash の全ラインアップを、単一の統合 API で提供します。料金は $0.112 からの秒単位の透明な従量課金で、サブスクリプションは不要です。今すぐ開発を始めましょう。
GPT Image 2
GPT Image 2 API は、GPT Image 1.5 の後継となる OpenAI の最新画像モデルへのアクセスを開発者に提供します。ラテン文字およびCJKスクリプト全体で正確なテキストレンダリングを使用して画像を生成および編集できるほか、ポスター、モックアップ、インフォグラフィック向けの強力なコンポジション(構図)機能を備えています。Atlas Cloud では、300以上のモデルと並んで1つの統合 API を通じてアクセスでき、無料クレジット、99.99% のアップタイムが提供され、OpenAI の組織検証は不要です。
Googleの最も強力なクリエイティブモデルはすべてAtlas Cloudで利用可能です。Veo 3.1はシネマティックな動画生成を実現し、Nano Banana 2は高忠実度な画像作成を強化し、Geminiはあらゆるワークフローにマルチモーダルなインテリジェンスをもたらします。Day-0の可用性と従量課金制(pay-as-you-go)の料金体系を備えた単一のAPI keyを通じて、Googleモデルスイート全体にアクセスできます。
Seedance 2.0 Mini
Seedance 2.0 Mini は、速度とコストが最も重視されるワークフローに ByteDance のマルチモーダル動画生成をもたらします。より軽量なフットプリントで Seedance 2.0 のコア機能を提供し、より高速な生成、動画あたりのコスト削減、そしてすでに使用しているものと同じ API 統合を実現します。大容量のパイプラインを運用したり、大規模なプロトタイピングを行ったりするチームにとって、Mini は実用的なデフォルトの選択肢です。
ByteDance
シネマティックな動画生成から高忠実度の画像作成まで、ByteDanceの最も強力なモデルがAtlas Cloudで利用可能になりました。最低水準の推論価格とゼロのインフラストラクチャオーバーヘッドで、SeedanceとSeedreamを大規模に実行できます。
Alibaba
Atlas Cloudは、Alibabaの全モデルラインナップを単一のAPIに統合します。言語および画像タスク用のQwen、最大1080pの動画生成用のWanが利用可能です。すべてのモデルはサブスクリプション不要の従量課金制(pay-as-you-go)でアクセスできます。Alibaba APIは、既存のOpenAI互換クライアントを使用し、単一のベースURLを介して利用可能です。
OpenAI
Atlas Cloudは、画像生成用のGPT Image 2から動画用のSora 2まで、OpenAI APIの全ラインナップへのアクセスを提供します。すべてのモデルは、月額の固定コミットメントなしの従量課金制でご利用いただけます。OpenAI互換APIを使用し、ベースURLを一つ変更するだけで簡単に組み込むことができます。
xAI
Atlas Cloud 上で xAI API を使用して、完全な画像および動画パイプラインを構築します。2K解像度での生成、参照画像を使用した編集、そして画像を音声同期クリップへとアニメーション化することが可能です。
Kwaivgi
Kwaivgi APIを標準価格より15%オフで提供。Atlas Cloudは、新しいKlingリリースへのDay-0アクセスを、従量課金制(Pay-as-you-go)およびシート数無制限で提供します。1つのアカウント、1つのキーで、スタンダードからマスター階層まで、すべてのKlingモデルをご利用いただけます。
Seedream 5.0 Pro
Seedream 5.0 Pro API は、開発者に Atlas Cloud 上で ByteDance の制御可能な画像編集モデルを提供します。アンカーと座標を使用して編集を正確に配置し、画像を編集可能なレイヤーに分離し、複数の参照を融合し、正確な色と素材を一致させ、2K および 3K での多言語テキストをサポートします。Atlas Cloud では、単一のキーでアクセスできます!


