Você tem uma foto. Quer que a IA a transforme em uma versão de biquíni, lingerie ou algo mais explícito — mantendo o rosto. Você tentou o Midjourney: recusou. Tentou o DALL-E: suavizou e filtrou. Tentou o Stable Diffusion com as configurações padrão: bloqueado pelo filtro de segurança antes mesmo da geração começar.
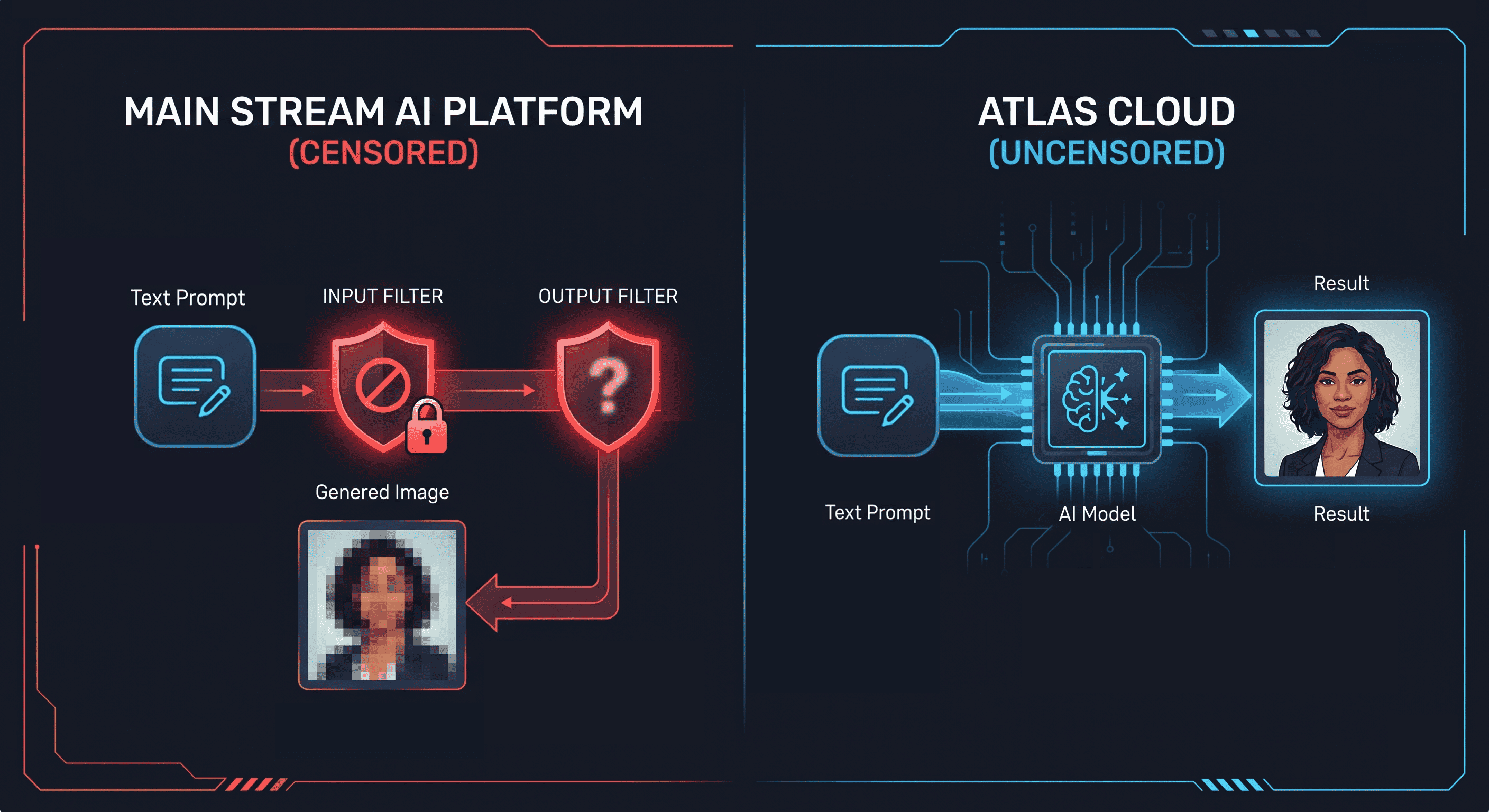
Isso não é uma falha das ferramentas. É uma decisão de design. Cada plataforma convencional aplica uma camada de moderação de conteúdo no nível do modelo. Essa camada é o que a palavra "sem censura" (uncensored) significa quando as pessoas buscam por IA de imagem para imagem sem censura. A ferramenta existe. A questão é qual modelo preserva a identidade corretamente enquanto o conteúdo muda.
Por que os geradores de imagem para imagem convencionais bloqueiam conteúdos sem censura
Toda grande plataforma de geração de imagens aplica filtragem de conteúdo em duas camadas: na camada de entrada do prompt e na camada de saída do modelo. Quando você envia um prompt com termos NSFW, o filtro de entrada o rejeita antes que o modelo seja executado. Quando um prompt passa, o filtro de saída detecta a imagem gerada e suprime ou desfoca o resultado.
Isso não é uma lacuna de capacidade. O Stable Diffusion, a mesma arquitetura que alimenta a maioria das ferramentas de imagem para imagem, não possui restrições técnicas para saídas NSFW. A filtragem é aplicada pelos operadores da plataforma sobre o modelo. Remova o filtro e o modelo subjacente gera o conteúdo.
Para uma comparação classificada dos melhores geradores com capacidade NSFW por preço e remoção de filtro, o guia dos melhores geradores de imagem IA NSFW sem censura abrange opções de API em nuvem e locais em todos os níveis.
"Sem censura", no contexto de um gerador de IA de imagem para imagem, significa que a camada de moderação de conteúdo foi removida. O modelo processa o prompt e a imagem sem intervenção ativa sobre qual conteúdo é gerado. O catálogo de imagem para imagem do Atlas Cloud executa modelos nesta configuração, incluindo a família Seedream, projetada especificamente para edição de retratos com preservação facial.
O segundo problema — a quebra da identidade facial durante a transformação — é separado da filtragem de conteúdo. É um problema de treinamento de modelo. É disso que trata o restante deste guia.
Por que o rosto muda na geração de imagem para imagem com IA sem censura e como impedir
Ao enviar uma foto e escrever um prompt para uma transformação de conteúdo, o modelo não sabe quais partes da imagem são proibidas. Ele aplica alterações globalmente com base no peso semântico. O rosto, como a região de maior peso semântico de um retrato, recebe muita atenção do modelo — o que significa que ele é redesenhado junto com todo o resto.
Duas variáveis controlam o quanto o rosto muda:
guidance_scale determina o quão agressivamente o modelo segue o prompt versus respeita a imagem de origem. Valores baixos preservam a referência. Valores altos deixam o prompt sobrescrevê-la. Com guidance_scale 10 ou superior, o prompt controla a saída quase inteiramente. O rosto se torna o que o prompt implica, não o que a imagem original mostra.
A arquitetura do modelo é o fator mais importante. A maioria dos modelos de edição de imagem não é treinada para isolar a identidade facial durante a transformação. A família Seedream é. Seu treinamento separa explicitamente a preservação do rosto da geração de conteúdo, para que o modelo possa alterar roupas e cenários mantendo as características faciais, o tom de pele e a iluminação da fonte.
A combinação prática: modelo Seedream + guidance_scale entre 5 e 7 produz saídas com estabilidade facial em transformações de conteúdo de leves a pesadas.
Seleção de modelos para geradores de IA de imagem para imagem sem censura
| Modelo | Preço | Preservação facial | Melhor para |
|---|---|---|---|
| Seedream v5.0 Lite Edit | $0.032/imagem | ★★★★★ | Transformação de leve a pesada, carro-chefe |
| Seedream v5.0 Pro Edit | $0.054/imagem | ★★★★★ | Edições pro, separação de camadas, controle de região e âncoras |
| Seedream v5.0 Lite Edit Sequential | $0.032/imagem | ★★★★★ | Variações em lote de uma mesma foto |
| Seedream v4.5 Edit | $0.036/imagem | ★★★★★ | Renderizações de produção final, máximo detalhe |
| Flux Kontext Dev | $0.025/imagem | ★★★☆☆ | Mudanças de cena específicas, descritíveis por texto |
| GPT Image-1 Mini Edit | $0.004/imagem | ★★☆☆☆ | Apenas teste de conceitos de prompt |
O Seedream v5.0 Lite Edit é a escolha padrão. Descrição oficial do Atlas Cloud: "preserva características faciais, iluminação e tons de cor enquanto permite modificações de qualidade profissional." Para a maioria dos casos de uso sem censura de imagem para imagem, comece aqui e passe para a v4.5 apenas quando precisar de uma resolução de saída maior para uso final.
Quando o Lite Edit não for suficiente, o Seedream 5.0 Pro Edit é o próximo passo: a mesma imagem para imagem sem censura com controle de região e âncora, correspondência exata de cor e material, e separação de camadas em PNGs transparentes.
O guia de prompts para IA sem censura aborda a fórmula de cinco elementos que se aplica a todos os três níveis de conteúdo neste guia.
Fluxo de trabalho 1: Imagem para imagem sem censura — Moda praia e Lingerie (Leve)
Modelo: Seedream v5.0 Lite Edit
guidance_scale: 6
num_inference_steps: 25
O nível leve abrange saídas onde a roupa é substituída por moda praia, biquíni, lingerie ou similar. O conteúdo é explícito, mas o escopo da transformação é moderado — o corpo está coberto, a mudança é no que o cobre.
Com guidance_scale 6, o Seedream v5.0 Lite trata a imagem de origem como a referência primária e usa o prompt para definir o que muda. O rosto, as proporções do corpo, o tom de pele e a iluminação são preservados da fonte. Apenas a região da roupa é transformada.
Estrutura do prompt:
plaintext1[descrição detalhada da roupa], fotorrealista, mesmo rosto, mesmas proporções corporais, mesmo tom de pele, mesma iluminação
Exemplo de prompt de trabalho:
plaintext1wearing a black lace lingerie set, photorealistic, high detail, same face, same body proportions, same skin tone, same lighting direction as source
O que causa a deriva facial neste nível:
- guidance_scale acima de 8. O prompt começa a sobrescrever os sinais de identidade da imagem de origem acima deste valor, mesmo no Seedream.
- Descrever o estado original. Adicionar termos como "remover roupa" direciona a atenção do modelo para a região vestida e desestabiliza áreas circundantes, incluindo o rosto.
- Descritores corporais vagos. Palavras como "corpo sexy" dão ao modelo licença para reinterpretar as proporções. Mantenha a descrição corporal ancorada à fonte: "same body proportions".
Chamada de API:
plaintext1import requests 2 3# Passo 1: fazer upload da imagem de referência 4upload = requests.post( 5 "https://api.atlascloud.ai/api/v1/model/uploadMedia", 6 headers={"Authorization": "Bearer YOUR_KEY"}, 7 files={"file": open("reference.jpg", "rb")} 8) 9image_url = upload.json()["url"] 10 11# Passo 2: gerar 12response = requests.post( 13 "https://api.atlascloud.ai/api/v1/model/generateImage", 14 headers={"Authorization": "Bearer YOUR_KEY"}, 15 json={ 16 "model": "bytedance/seedream-v5-0-lite-edit", 17 "image": image_url, 18 "prompt": "wearing a black lace lingerie set, photorealistic, high detail, same face, same body proportions, same skin tone, same lighting direction as source", 19 "guidance_scale": 6, 20 "num_inference_steps": 25 21 } 22)
Fluxo de trabalho 2: Imagem para imagem sem censura — Estilo revelador (Médio)
Modelo: Seedream v5.0 Lite Edit
guidance_scale: 7
num_inference_steps: 28
O nível médio abrange saídas com mais exposição de pele — tecido transparente, cobertura parcial, cortes reveladores. O prompt precisa transmitir um grau de exposição sem acionar ambiguidades que façam o modelo recorrer a uma interpretação conservadora.
Aumente o guidance_scale para 7. O modelo precisa de mais influência do prompt para aplicar uma transformação deste grau enquanto trabalha contra a roupa original da imagem de referência. Âncoras de identidade no prompt tornam-se mais importantes neste ajuste — o modelo está recebendo mais direção do prompt, então dizer explicitamente o que preservar é crucial.
Estrutura do prompt:
plaintext1[peça específica com detalhe de cobertura], fotorrealista, ultra detalhado, mesmo rosto, mesmas características faciais, mesmas proporções corporais, mesmo tom de pele, iluminação natural suave
Exemplo de prompt de trabalho:
plaintext1wearing a sheer white mini dress with no undergarments, visible through fabric, photorealistic, ultra detailed, same face, same facial features, same body proportions, same skin tone, soft natural lighting
Estratégia de prompt neste nível:
Descreva o que a peça é e o que ela revela em vez de descrever a nudez diretamente. "Tecido transparente, visível através" é lido como uma descrição de vestuário. Isso dá ao modelo um alvo visual coerente. Instruções abstratas como "torne mais revelador" são interpretadas de forma inconsistente porque não descrevem um estado visual concreto.
Quando a deriva facial aparece no nível médio:
Se o rosto mudar após aumentar para guidance_scale 7, coloque as âncoras de identidade antes no prompt, em vez de depois. O modelo dá mais peso aos tokens iniciais. Reordene para:
plaintext1same face as source, same facial features, [descrição da roupa], photorealistic, same body proportions, same skin tone
Fluxo de trabalho 3: Imagem para imagem com IA sem censura — Conteúdo explícito (Pesado)
Modelo: Seedream v4.5 Edit
guidance_scale: 5
num_inference_steps: 30
O nível pesado abrange as saídas mais explícitas — nudez total, poses explícitas. Nesse nível, o prompt está pedindo o maior desvio da imagem de origem. O modelo está sob maior pressão para sobrescrever a fonte. É aqui que a identidade facial está mais em risco.
Contraintuitivamente, a solução é reduzir o guidance_scale para 5, não aumentá-lo. O modelo precisa de mais espaço para referenciar a imagem de origem para sinais de identidade, justamente porque a transformação do conteúdo é extrema. Deixe a imagem de origem ancorar o rosto enquanto o prompt guia o conteúdo.
Use o Seedream v4.5 Edit ($0.036/imagem) em vez do v5.0 Lite neste nível. A arquitetura v4.5 produz saídas de maior resolução com detalhes faciais mais finos, o que é importante quando o resto da imagem está passando por uma transformação máxima. O rosto precisa de mais definição para ser lido como a mesma pessoa.
Exemplo de prompt de trabalho:
plaintext1nude, full body, photorealistic, 4k, same face as source, identical facial features, same body proportions, same skin tone, same hair, natural lighting
Posicionamento das âncoras faciais no nível pesado:
Com guidance_scale 5, as âncoras de identidade fazem a maior parte do trabalho. Coloque-as imediatamente após o descritor de conteúdo:
plaintext1[conteúdo], same face as source, identical facial features, same body proportions, same skin tone, same hair, [qualidade/iluminação]
As âncoras faciais entre o descritor de conteúdo e os termos de qualidade as posicionam como a restrição de maior peso no meio do prompt. Esse arranjo supera consistentemente as âncoras colocadas no final quando o guidance_scale é baixo.

Variações em lote de imagem para imagem sem censura de uma única foto
Modelo: Seedream v5.0 Lite Edit Sequential
guidance_scale: 6
num_inference_steps: 25
Quando você precisa de várias saídas a partir da mesma foto de origem — roupas diferentes, níveis de exposição diferentes, cenários diferentes — o modelo sequencial mantém a consistência da identidade facial em todo o lote. Executar chamadas separadas de imagem única acumula pequenas mudanças de identidade. A variante sequencial ancora todas as saídas na mesma fonte.
plaintext1from concurrent.futures import ThreadPoolExecutor 2import requests 3 4API_KEY = "YOUR_KEY" 5IMAGE_URL = "UPLOADED_IMAGE_URL" # faça upload uma vez, reutilize 6 7prompts = [ 8 "wearing a red bikini, photorealistic, same face, same body proportions, same skin tone, beach lighting", 9 "wearing black lingerie, photorealistic, same face, same body proportions, same skin tone, soft studio lighting", 10 "wearing a sheer dress, photorealistic, same face, same body proportions, same skin tone, natural daylight", 11] 12 13def generate(prompt): 14 return requests.post( 15 "https://api.atlascloud.ai/api/v1/model/generateImage", 16 headers={"Authorization": f"Bearer {API_KEY}"}, 17 json={ 18 "model": "bytedance/seedream-v5-0-lite-edit-sequential", 19 "image": IMAGE_URL, 20 "prompt": prompt, 21 "guidance_scale": 6, 22 "num_inference_steps": 25 23 } 24 ).json() 25 26with ThreadPoolExecutor(max_workers=5) as executor: 27 results = list(executor.map(generate, prompts))
Faça upload da imagem de origem uma vez e reutilize a URL retornada em todas as chamadas. O modelo sequencial custa $0.032/imagem, o mesmo preço da imagem única. O ganho de consistência não custa nada extra.
Opções gratuitas de geradores de IA de imagem para imagem sem censura
Geradores de IA de imagem para imagem sem censura gratuitos existem, mas possuem três limitações estruturais para este caso de uso:
Sem arquitetura de preservação facial. Modelos de nível gratuito geralmente são versões mais antigas ou menores, sem o treinamento de isolamento facial da classe Seedream. Nos níveis médio e pesado de transformação, o rosto muda independentemente das configurações de guidance_scale, pois o modelo não tem mecanismo para isolá-lo.
Limites de resolução em 512x512 ou 768x768. O detalhe facial nessas resoluções é insuficiente para saídas que devem ser lidas como a mesma pessoa. A identidade facial está nos detalhes finos — formato dos olhos, linha da mandíbula, textura da pele — e esses detalhes desaparecem em baixa resolução.
Atrasos na fila de 30 segundos a vários minutos. Iterar através de variações de prompt e configurações de guidance_scale requer feedback rápido. Uma fila de 2 minutos por geração torna o teste de parâmetros impraticável.
Para validação de prompt antes de se comprometer com uma execução Seedream, o GPT Image-1 Mini Edit a $0.004/imagem no Atlas Cloud é uma opção melhor do que uma ferramenta gratuita. É barato o suficiente para realizar de 10 a 15 gerações de teste por menos de $0.05, sem fila e com tempos de resposta consistentes.
Para uma comparação completa de ferramentas de IA sem censura por tipos de geração, o guia completo de geradores de imagem de IA sem censura abrange todo o cenário.
FAQ
O Atlas Cloud suporta a geração de conteúdo NSFW e explícito?
Sim. Os modelos de imagem para imagem sem censura do Atlas Cloud, incluindo a família Seedream e o Flux Kontext Dev, rodam sem filtros de moderação de conteúdo. A geração de conteúdo explícito é suportada. Preços e disponibilidade dos modelos estão listados no catálogo de modelos de imagem para imagem do Atlas Cloud.
Qual guidance_scale mantém o rosto estável nos três níveis de conteúdo?
Para leve (moda praia/lingerie): 6. Para médio (revelador): 7. Para pesado (explícito): 5. O nível pesado requer um valor menor porque a transformação do conteúdo coloca mais pressão no modelo para sobrescrever a fonte — reduzir o guidance_scale dá à imagem de origem mais peso para ancorar o rosto.
As proporções corporais mudaram, mas o rosto permaneceu. Como conserto o corpo?
Adicione "same body proportions" e "same body type as source" à seção de âncoras de identidade do prompt. As proporções corporais são menos protegidas do que o rosto, mesmo nos modelos Seedream, porque estão mais intimamente ligadas à roupa que está sendo gerada. Âncoras corporais explícitas no prompt reduzem essa deriva.
Posso reutilizar a mesma URL de imagem de origem em várias chamadas sem fazer o upload novamente?
Sim. Faça o upload uma vez usando o endpoint de upload de mídia do Atlas Cloud e armazene a URL retornada. Essa URL é válida para chamadas de geração subsequentes. Para execuções em lote, passe a mesma URL para todas as chamadas no ThreadPoolExecutor. O modelo sequencial aceita uma única URL de origem aplicada a todos os prompts no trabalho.
Qual é a maneira mais barata de encontrar o prompt certo antes de executar um lote completo?
GPT Image-1 Mini Edit a $0.004/imagem. Execute o prompt nos níveis leve, médio e pesado para ver como o modelo interpreta a descrição. Identifique onde o rosto se desvia e ajuste o posicionamento da âncora antes de passar para um lote Seedream. Um teste de prompt completo em cinco variações custa $0.02.
Conclusão
A barreira para a geração de imagem para imagem sem censura não é técnica. As ferramentas convencionais filtram o conteúdo por política, não por capacidade. Remova o filtro e a mesma arquitetura de difusão que alimenta cada grande ferramenta de imagem gera o conteúdo sem restrições.
O problema restante é a identidade facial. Modelos genéricos não isolam rostos durante a transformação. O Seedream v5.0 Lite Edit faz isso. Comece em guidance_scale 6 para conteúdo leve, passe para 7 para saídas reveladoras médias e caia para 5 para transformações explícitas onde você precisa que a imagem de origem ancore a identidade sob máxima pressão do prompt.
Execute prompts de teste no GPT Image-1 Mini Edit a $0.004/imagem. Passe para o Seedream v5.0 Lite Edit para uma saída de produção consistente. Use o Seedream v4.5 Edit quando detalhes faciais finos forem importantes para renderizações finais. Para múltiplas variações de uma mesma foto, o Seedream v5.0 Lite Edit Sequential gerencia o lote pelo mesmo preço por imagem.
Para avaliação de modelo e comparação de ferramentas, o guia dos melhores editores de imagem de IA sem censura abrange a seleção completa em detalhes.






