Resumo: O GLM-5-Turbo, desenvolvido pela Zhipu AI (Z.ai), é um modelo de linguagem de grande escala projetado para casos de uso do OpenClaw e o primeiro lançamento de código fechado da empresa (anteriormente testado sob o codinome Pony-Alpha-2), com lançamento previsto em breve na Atlas Cloud.
O modelo entrega melhorias significativas no uso de ferramentas, execução de instruções, fluxos de trabalho de várias etapas e tratamento de tarefas de longo prazo, suportando uma janela de contexto de até 200 mil tokens. Suas capacidades de análise de dados são comparáveis ao Claude Opus 4.6, superando o GLM-5 em tarefas de automação e processamento de informações. Aproveitando a API unificada e o ecossistema multimodelos da Atlas Cloud, o GLM-5-Turbo permite uma implementação eficiente em automações de negócios complexas, análise de documentos longos e desenvolvimento de software, oferecendo uma solução de IA econômica e facilmente integrável para desenvolvedores e empresas.
Estamos empolgados em anunciar que o GLM-5-Turbo chegará à Atlas Cloud!
- O que é o GLM-5-Turbo: Desenvolvido pela Zhipu AI (Z.ai), o GLM-5-Turbo é um modelo de linguagem de grande escala feito sob medida para casos de uso do OpenClaw. Ele marca o primeiro lançamento de código fechado da equipe, oferecendo maior eficiência de tempo de execução do que o GLM-5 a um custo menor por chamada. Antes disso, a Zhipu AI testou informalmente seu modelo de próxima geração sob o codinome Pony-Alpha-2.
- Principais recursos: O GLM-5-Turbo entrega melhorias substanciais no uso de ferramentas, seguimento de instruções, fluxos de trabalho de várias etapas e execução persistente de tarefas. Ele suporta modos de raciocínio dinâmico entre cenários, saída de streaming em tempo real, integração aprimorada de ferramentas e manuseio de contexto longo de até 200 mil tokens.
- Data de Lançamento: 24/03/2026.
O GLM-5 chamou a atenção anteriormente como o modelo de código aberto com melhor desempenho no Artificial Analysis Intelligence Index, superando o Gemini 3 Pro. Como seu sucessor, o GLM-5-Turbo introduz uma série de atualizações iterativas, detalhadas abaixo.
Posicionamento Principal: Um Modelo Otimizado para ClawBench
Desempenho Sólido em Benchmarks
Otimizado para cenários OpenClaw, o GLM-5-Turbo aprimora significativamente as capacidades de invocação de ferramentas, execução de instruções e orquestração de tarefas complexas. Seu desempenho em análise de dados está no mesmo nível do Claude Opus 4.6, superando o GLM-5 em automação, recuperação de informações, produtividade de escritório e tarefas analíticas.
Fonte da imagem: Site oficial da Zhipu AI (Z.ai).
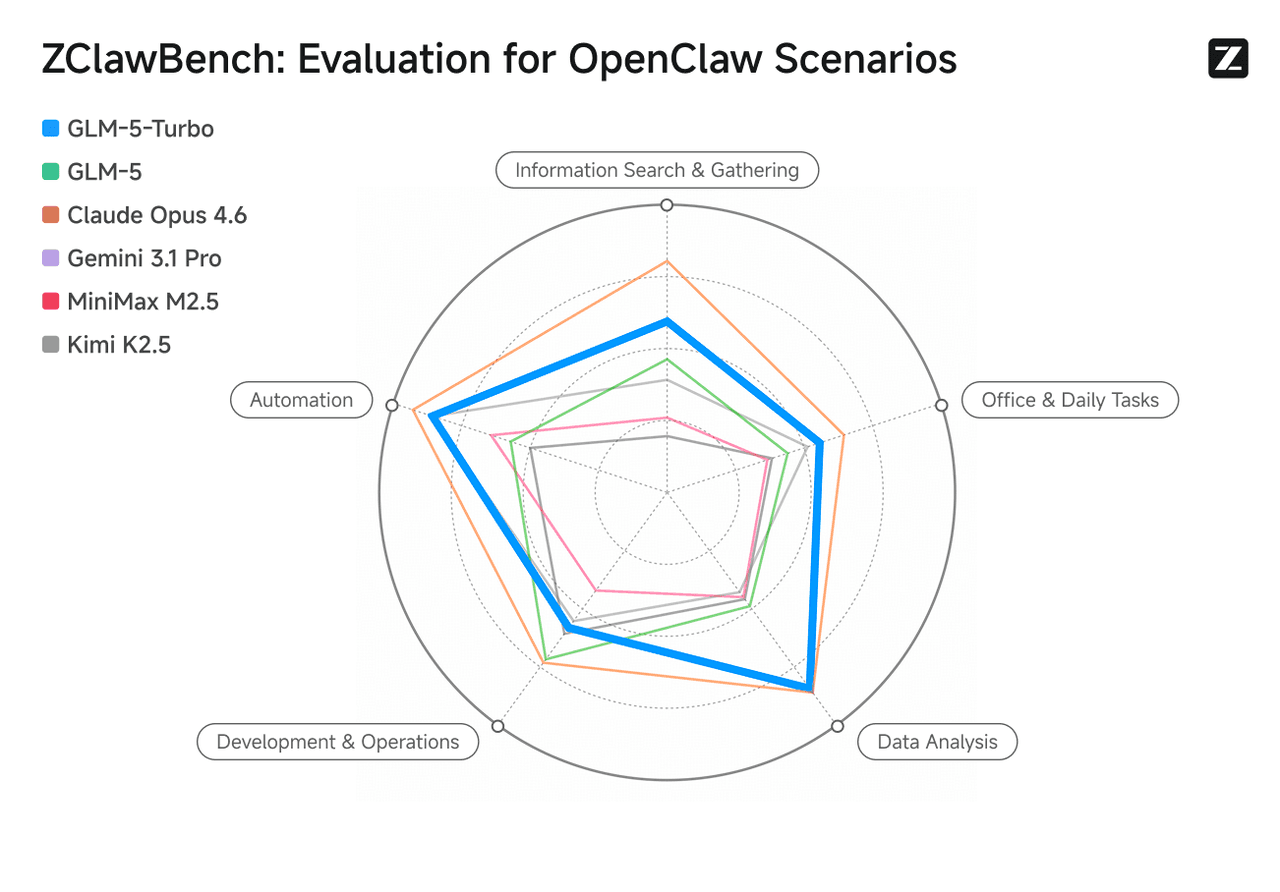
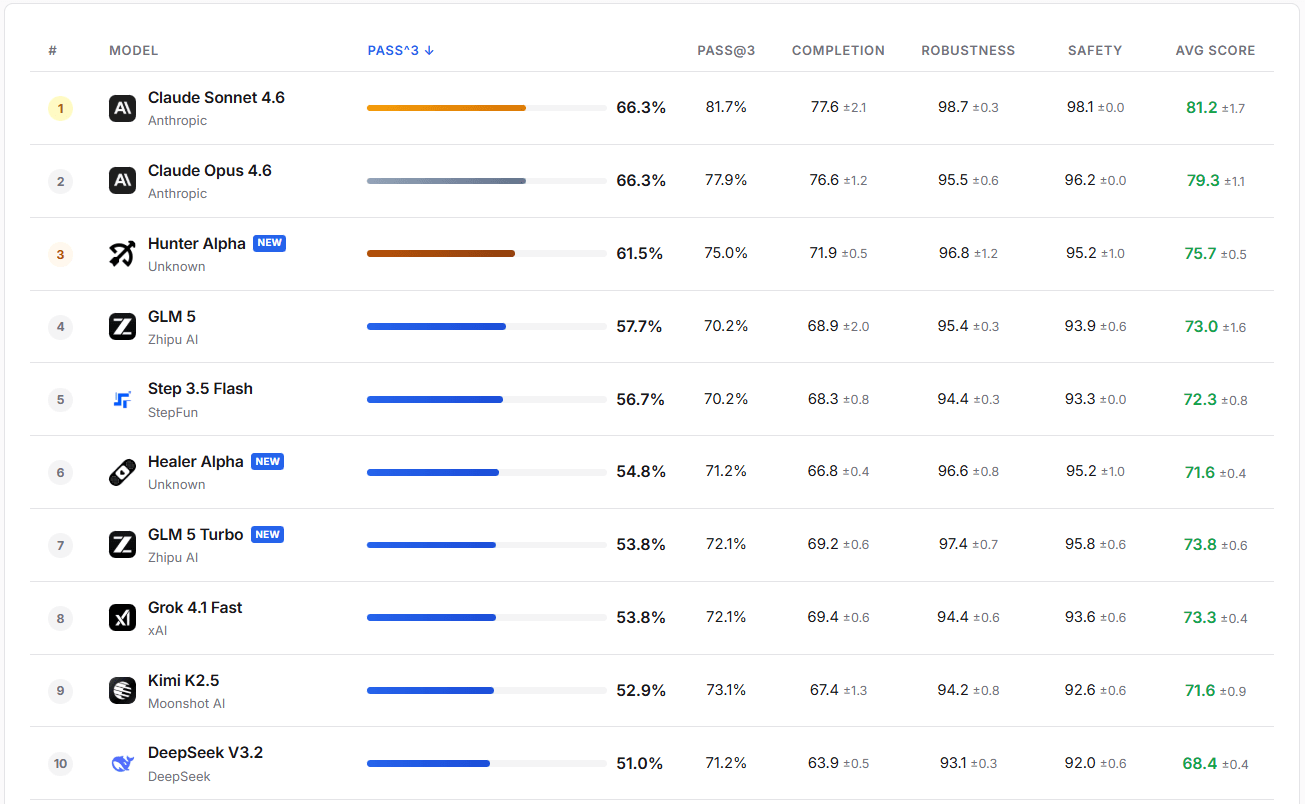
Em avaliações práticas, o GLM-5-Turbo demonstra alta robustez e segurança. Sua taxa de sucesso PASS@3 excede a do GLM-5, Step 3.5 Flash e Kimi K2.5.
Fonte da imagem: https://claw-eval.github.io/
Uso Aprimorado de Ferramentas e Integração Externa
A Z.ai fortaleceu as capacidades de agente do GLM-5-Turbo durante o treinamento, permitindo uma interação perfeita com ferramentas externas. Essa orientação focada na execução traz compensações: alguns usuários relatam um tom ligeiramente mais mecânico em comparação ao GLM-5 em cenários de role-playing.
Para acomodar os diferentes pontos fortes entre os modelos, a Atlas Cloud fornece uma interface unificada que permite aos usuários consultar vários modelos simultaneamente, permitindo comparação e seleção lado a lado.
Além disso, os usuários podem definir habilidades personalizadas ou permitir que o GLM-5-Turbo as descubra e instale autonomamente.
Fonte da imagem: Atlas Cloud

Execução Autônoma de Longo Horizonte
O GLM-5-Turbo é otimizado para tarefas que exigem disparadores agendados ou tempos de execução estendidos. Ele lida com fluxos de trabalho persistentes, de várias etapas e intertemporais com forte continuidade de tarefas.
O modelo sugere proativamente estratégias de execução com base na complexidade da tarefa. Em testes comparativos de otimização de código, o GLM-5-Turbo produziu recomendações que superaram modelos concorrentes em aproximadamente 10% dos casos.
Janela de Contexto de 200K Tokens
Com suporte para até 200 mil tokens (aproximadamente 133 mil palavras em inglês), o GLM-5-Turbo pode reter e utilizar um contexto extenso em uma única sessão. Isso permite a recuperação precisa de informações anteriores mesmo em estágios avançados de uma conversa.
Fonte da imagem: Jim Allen Wallace (Redis)
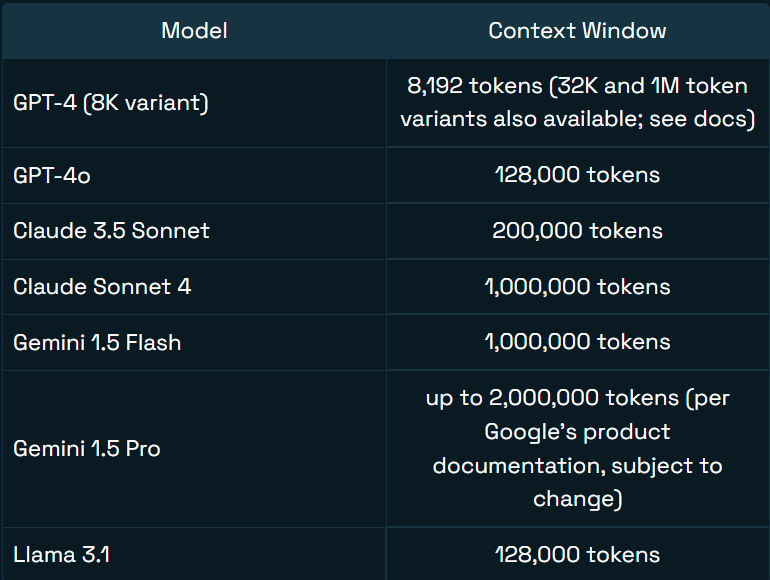
Casos de Uso
Automação de Fluxos de Trabalho Complexos
Com suas capacidades aprimoradas de OpenClaw, o GLM-5-Turbo pode decompor processos de negócios complexos, identificar a lógica subjacente e localizar ou gerar autonomamente as habilidades necessárias para executar tarefas.
Por exemplo, na produção de vídeos curtos, o modelo pode pesquisar, instalar e orquestrar ferramentas de escrita, geração de imagens e produção de vídeo — planejando e executando todo o fluxo de trabalho de ponta a ponta.
QA de Documentos Longos e Análise Profunda
O modelo mantém o contexto total em documentos longos dentro de uma única sessão, permitindo perguntas e respostas precisas em vários turnos. Sua alta eficiência de tokens garante respostas rápidas com menor custo computacional.
Em bases de código de grande escala, o GLM-5-Turbo pode analisar o design arquitetural, mapear dependências entre componentes e sinalizar potenciais efeitos colaterais de mudanças em códigos de baixo nível.
“Vibe Coding”
Dentro do ciclo de vida de desenvolvimento de software, o GLM-5-Turbo funciona mais como um engenheiro full-stack inserido em fluxos de trabalho complexos. Os desenvolvedores podem delinear a lógica de alto nível enquanto o modelo constrói incrementalmente a arquitetura da aplicação em tempo real.
Combinado com habilidades multimodais, os usuários podem fazer upload de imagens de interface, gravações de tela ou rascunhos, que o modelo pode converter diretamente em componentes funcionais de frontend.
Por que usar o GLM-5-Turbo na Atlas Cloud?
Como uma plataforma de infraestrutura de IA all-modal, a Atlas Cloud oferece aos usuários uma interface de API unificada. Uma vez conectado, os usuários podem desbloquear facilmente mais de 300 modelos avançados de IA, incluindo modelos geradores de texto, imagem, vídeo ou multimodais.
Público-Alvo
- Desenvolvedores Independentes que buscam soluções simplificadas e de baixo custo para chamar vários modelos de IA.
- Empresas que necessitam de infraestrutura estável, segura e escalável para apoiar seus negócios principais.
- Equipes de Desenvolvimento que precisam integrar de forma eficiente múltiplos modelos cross-modal em seus projetos.
- Usuários de Fluxos de Trabalho que priorizam a compatibilidade com cadeias de ferramentas e usam ComfyUI ou n8n.
Recursos do Produto
- Integração Altamente Simplificada: A plataforma fornece uma API compatível com OpenAI, simplificando instantaneamente a carga de trabalho do desenvolvedor. Chega de gerenciar várias chaves de fornecedores ou se preocupar com custos de manutenção entre plataformas.
- Vantagem de Custo: Comparado aos concorrentes, a Atlas Cloud possui custos de implantação mais baixos. O Nano Banana 2 custa USD0.056/imagem (concorrente: USD0.07/imagem); o Veo 3.1 custa USD0.09/segundo (concorrente: USD0.1/segundo). Além disso, a interface do Playground oferece total transparência de preços, com o botão "Run" rotulando diretamente o valor da dedução por imagem ou segundo de vídeo.
- Estabilidade e Suporte de Nível Empresarial: A Atlas Cloud garante que a proteção de dados atenda a padrões rigorosos de privacidade e possa lidar com informações sensíveis.
- Pronto para Plug-and-Play: Criado para funcionar sem esforço com ferramentas como ComfyUI e n8n, ajudando as empresas a reduzir custos de transição e começar a trabalhar imediatamente.
Comparação com Produtos Similares
- Fal.ai: Embora ofereçam alguns modelos, a Atlas Cloud oferece uma seleção mais ampla (300+), preços mais competitivos e novos usuários registrados recebem USD1 de crédito de teste.
- Wavespeed: Os preços são significativamente mais altos. A Atlas Cloud oferece suporte adicional de conformidade empresarial e orientação técnica especializada que a Wavespeed não enfatiza.
- Kie.ai: Usa um sistema de crédito opaco. A Atlas Cloud exibe o custo exato para cada execução diretamente na interface. A contagem de modelos também é maior do que a do Kie.ai.
- Replicate: Foca em hospedagem de modelos. As vantagens da Atlas Cloud estão na unificação de API, na velocidade de implantação de modelos e em políticas de suporte mais amigáveis aos desenvolvedores.
- OpenAI ou Google: Esses fornecedores fornecem apenas seus próprios modelos. Usuários com necessidades cross-modal geralmente precisam integrar múltiplos serviços. A Atlas Cloud integra modelos proprietários e de código aberto sob uma única API, reduzindo a complexidade do sistema.
Como usar o GLM-5-Turbo na Atlas Cloud?
Método 1: Usar diretamente na plataforma
Método 2: Usar via integração de API
Passo 1: Obtenha sua chave de API. Crie e cole sua chave de API no console:


Passo 2: Consulte a Documentação da API. Verifique os parâmetros de solicitação, métodos de autenticação, etc.
Passo 3: Faça sua primeira solicitação (Exemplo em Python)
Exemplo com o GLM-5.
plaintext1{ 2 "model": "zai-org/glm-5", 3 "messages": [ 4 { 5 "role": "user", 6 "content": "Hello" 7 } 8 ], 9 "max_tokens": 1024, 10 "temperature": 0.7, 11 "stream": false 12}
FAQ
Qual é a diferença entre o GLM-5-Turbo e o GLM-5? O GLM-5-Turbo é mais rápido e econômico, com eficiência de tokens significativamente melhorada — relatada como até três vezes a do GLM-5. Ele também é especificamente otimizado para cenários OpenClaw.
Como o GLM-5-Turbo se compara ao MiniMax M2.7? Ambos os modelos são otimizados para uso de ferramentas de agente e apresentam maior eficiência de tokens do que o GLM-5. Cada um suporta janelas de contexto de cerca de 200 mil tokens (o MiniMax M2.7 suporta 196.608 tokens). Estamos preparando uma postagem no blog para uma avaliação comparativa mais detalhada. Fique ligado!
Qual modelo GLM é recomendado para implementação no OpenClaw? O GLM-5-Turbo, pois é especificamente otimizado para cenários OpenClaw e alcança um desempenho de análise de dados comparável ao Claude Opus 4.6.






