O verdadeiro gargalo no vídeo com IA não é a saída parecer "errada". É que ela parece lenta.
1. Por que 15 segundos de ação em IA continuam decepcionando
Qualquer um que tenha passado um tempo real com o Seedance 2.0 atingiu o mesmo limite: quando você pede um clipe de 15 segundos, o modelo entrega três ou quatro takes — e só.
Você fornece uma cena de luta. O que volta é "lutador entra → levanta a arma → congela". Preparação, ação, fim. Sobem os créditos.
Mas não é assim que uma luta é lida na tela. Antes do soco atingir, o ombro gira. Após a esquiva, o contra-ataque já está sendo carregado. Um plano geral de perseguição corta para um close-up extremo, que corta para um impacto em câmera lenta. A tensão vem da densidade dos cortes — não de tornar cada take individual mais bonito.
E o modelo não lhe dará dezesseis takes por conta própria, não importa como você o instrua.
Esse é o problema. Veja como nós o resolvemos.
2. Três pilares que mudaram o fluxo de trabalho
Após executar a demo completa de ação de personagem único do início ao fim, chegamos a três pontos fundamentais:
① A tensão da ação vem da densidade dos cortes, não da qualidade de um take isolado. Pare de tentar tornar um take perfeito. Divida os 15 segundos em um storyboard de 16 quadros primeiro, e então entregue-o ao modelo de vídeo.
② A força real do GPT Image 2 é a compreensão de roteiro e o layout de planos — não a consistência de estilo. Inicialmente, queríamos que o GPT Image 2 mantivesse um estilo único em toda a cadeia. Após testes, aceitamos que a referência para vídeo naturalmente pende para o CG — não há uma maneira limpa de forçar isso. Mas o que o GPT Image 2 pode fazer — ler um roteiro, planejar os takes, definir um storyboard de 16 quadros — é algo que nenhum outro modelo em nosso conjunto faz tão bem.
③ Todo o pipeline roda com uma única chave de API da AtlasCloud. GPT Image 2, Nano Banana 2 e Seedance 2.0 residem no mesmo conjunto de modelos na AtlasCloud. Uma chave. Um endpoint. Uma fatura. Uma cota. Sem a complexidade de múltiplos fornecedores.
3. O teste de estresse com um único personagem
Para testar verdadeiramente o GPT Image 2, escolhemos o personagem mais complexo que pudemos imaginar.
Conheça Ranx — uma operadora tática cibernética. Cabelo dourado em dois coques. E quatro peças de equipamento completamente assimétricas:
- Uma meia preta até a coxa apenas na perna direita
- Um coldre rígido vermelho apenas na coxa direita
- Detalhes em ciano apenas no joelho direito
- Uma bobina preta espessa indo da parte traseira direita do seu cinto até sua panturrilha esquerda
A única imagem de referência que entregamos ao modelo foi uma foto de costas de três quartos. O modelo precisou deduzir a frente, as laterais, as expressões e os detalhes da arma — e não espelhar nenhuma dessas quatro assimetrias.
Resultado: uma geração. Seis ângulos, quatro estudos de cabeça, quatro expressões, painel de armas, mãos, pés — tudo em uma página. Todas as quatro assimetrias mantidas. Nenhum espelhamento.


O ambiente foi tratado como uma referência de design finalizada (beco úmido cyberpunk, estética estilo Stray):

4. O teste A/B que comprova o método
Este é o experimento sobre o qual todo o fluxo de trabalho se baseia. Mesmo roteiro. Mesma ficha de personagem. Mesma referência de cena. A única variável é se existe um storyboard.
Controle: apenas prompt em prosa, sem storyboard
Inputs para o referência-para-vídeo do Seedance 2.0:
- 1× ficha de personagem
- 1× referência de cena
- Um prompt detalhado de 15 segundos em prosa descrevendo quatro cortes secos
A filmagem é legível e o trabalho é bom. Mas o clipe inteiro parece ter aproximadamente três batidas lentas — caminhar pelo beco, levantar a arma, congelar. Parece uma demonstração de personagem, não uma luta.
Teste: com um storyboard de 16 quadros
Pedimos ao GPT Image 2 que dividisse o mesmo roteiro em um storyboard de 4×4 = 16 quadros, com cada célula marcada para:
- Número do take (① ② ③ … ⑯)
- Tamanho do plano (WIDE / MS / CU / ECU)
- Seta de movimento de câmera (→ ↘ ↙ ↑ ↓ ↗)
- Nota de ritmo ("static rise" / "hard cut" / "impact" / "kill shot" / "outro")
- Uma curta nota de direção em chinês escrito à mão — puramente uma escolha de densidade; o chinês permite colocar mais intenção de direção em uma pequena célula de storyboard (tanto o GPT Image 2 quanto o Seedance 2.0 leem ambos os idiomas igualmente bem)
Em seguida, um prompt de uma linha para o referência-para-vídeo do Seedance 2.0:
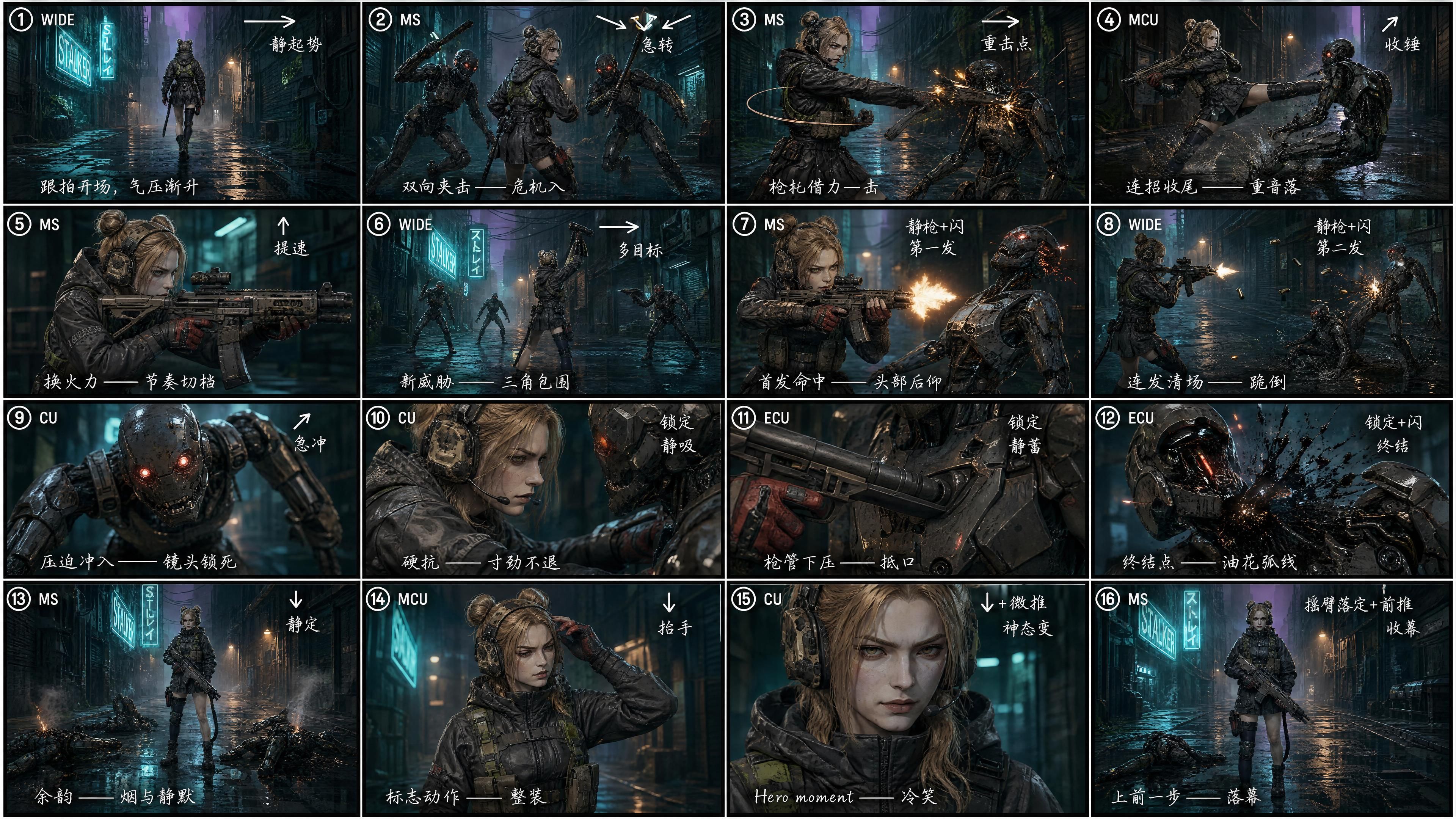
"Gere um vídeo que siga estritamente a imagem de referência 3 como storyboard. Forte sensação cinematográfica e linguagem de câmera, dinâmicas exageradas, ação que impacta forte."
A diferença é visível sem precisar medir. A densidade de cortes aumenta aproximadamente 4×. Perseguição em plano aberto para montagem de ombro em plano médio para close-up extremo no cano, finalizando com uma pose heroica — quinze segundos, totalmente preenchidos. Mesmo roteiro, ritmo diferente. A primeira versão parece uma demonstração. A segunda soa como um trailer.
Essa é a tese completa deste fluxo de trabalho: o GPT Image 2 não serve para fixar estilo. Serve para quebrar um roteiro em uma sequência densa de takes.
5. Escalando: um duelo entre dois lutadores
Assim que a versão de personagem único ficou limpa, escalamos para um duelo. A parte mais difícil de uma luta entre duas pessoas é fixar quatro coisas ao mesmo tempo — Personagem A, Personagem B, ambiente e ritmo da ação.
Em vez de gerar quatro imagens separadas e tentar encadeá-las, pedimos ao GPT Image 2 que lidasse com todas as quatro em uma única imagem:
- Personagem A (A-27): uma versão ajustada da Ranx — operadora tática de rabo de cavalo dourado em um casaco de combate curto
- Personagem B: um design original de mercenário — sobretudo longo preto e vermelho, cabelo preso, espada larga no quadril
- O ambiente: um cenário industrial chamado Ash City — luz âmbar de crepúsculo, brilho de fornalha ao longe, fumaça por toda parte
- Dez batidas de ação desenhadas à mão: sondar → avançar → bloquear → desviar → gancho → contra-atacar → imobilizar → joelhada → fechar → cair

Importante ressaltar: apenas o Personagem A usou uma imagem de referência (a Ranx anteriormente). O Personagem B, todo o ambiente e todas as dez batidas de ação — o GPT Image 2 projetou tudo sozinho. Nós descrevemos a vibe; ele entregou o resto.
Estilo, ambas as identidades, o ambiente e dez batidas — tudo fixado em uma única geração. Nada se desvia entre as imagens. A roupa de ninguém muda no meio do caminho.
Depois, direto para o referência-para-vídeo do Seedance 2.0:
Um impasse no telhado ancorado por dois emblemas de facção no piso da plataforma, uma luta agarrada no meio e um golpe finalizador — quinze segundos de coreografia para duas pessoas em uma única passagem.
6. Por que este pipeline roda com uma única chave de API
A cadeia — personagem → cena → storyboard → vídeo — costumava significar manipular chaves de API, SDKs, documentação, faturamento e limites de taxa entre vários fornecedores. Você sabe como é.
Na AtlasCloud, tudo isso fica atrás de um único endpoint:
| Passo | Modelo | Plataforma |
|---|---|---|
| Ficha de personagem | GPT Image 2 | AtlasCloud |
| Conceito de cena | Nano Banana 2 | AtlasCloud |
| Storyboard | GPT Image 2 | AtlasCloud |
| Vídeo | Seedance 2.0 | AtlasCloud |
Uma chave. Um endpoint. Uma cota. Uma fatura. A integração e a sobrecarga operacional caem para quase zero.
7. A conclusão: pare de lutar pelo estilo entre modelos, comece a explorar a força de cada um
Gastamos esforço real tentando fixar um estilo único em cada etapa da cadeia. No modo referência-para-vídeo, essa luta é impossível de vencer — quanto mais você força, pior fica o resultado.
Assim que abandonamos esse objetivo, o fluxo de trabalho se abriu. Deixe cada modelo fazer o que ele é realmente bom em fazer.
- GPT Image 2 — dividir o roteiro, organizar os takes
- Seedance 2.0 — desdobrar o tempo, renderizar a ação
- AtlasCloud — uma chave, uma cadeia
Se você está criando curtas de ação, cenas de luta ou coreografias de duelo com IA, este é o fluxo de trabalho que recomendamos.
Experimente você mesmo
Ambos os modelos vivem no mesmo conjunto de modelos da AtlasCloud — uma chave de API roda toda a cadeia:
- Seedance 2.0 (referência-para-vídeo) → atlascloud.ai/collections/seedance2
- GPT Image 2 (ficha de personagem + storyboard) → atlascloud.ai/collections/gpt-image-2
- Nano Banana 2 (conceito de cena) → atlascloud.ai/collections/nanobanana-2
O passo a passo completo e todos os prompts usados neste artigo estão publicados juntamente com o vídeo explicativo no YouTube.
Vá criar algo.






