
Doubao Seed API for Reasoning and Coding
L’API Doubao Seed donne accès à toute la gamme Seed de ByteDance, du modèle phare Seed 2.1 Pro à une version Code Preview dédiée, ainsi qu’aux niveaux Lite et Mini efficaces. Chaque modèle prend en charge le raisonnement approfondi, la planification agentique et le codage à l’échelle d’un dépôt, avec le streaming et un contexte partagé de 256K. Atlas Cloud les sert tous via un seul endpoint, avec une tarification à l’usage à partir de $0.1 par million de tokens et un accès Day-0. Commencez à créer dès aujourd’hui.
Explorez les Modèles Leaders
Atlas Cloud vous offre les derniers modèles créatifs de pointe de l'industrie.








Comparaison des spécifications
Famille Doubao Seed : une suite complète de modèles de langage, du raisonnement de pointe à l’inférence à haut débit.
| Model | Niveau | Idéal pour | Contexte | Sortie max |
|---|---|---|---|---|
| Doubao Seed 2.0 Pro | Produit phare | Raisonnement complexe, agents, tâches les plus difficiles | 256K | 131K |
| Doubao Seed 2.0 Code Preview | Code (aperçu) | Génération de code, refactorisation, travail à l’échelle d’un dépôt | 256K | 131K |
| Doubao Seed 2.0 Lite | Équilibré | Applications de production nécessitant de la qualité à moindre coût | 256K | 131K |
| Doubao Seed 2.0 Mini | Efficacité | Inférence à fort volume, sensible à la latence et économique | 256K | 131K |
| Doubao Seed 1.8 | Produit phare de génération précédente | Raisonnement généraliste stable et éprouvé | 256K | 131K |
| Doubao Seed 1.6 Flash | Rapide de génération précédente | Réponses rapides, UX en temps réel | 256K | 131K |
| Doubao Seed 1.6 | Base de génération précédente | Tâches généralistes économiques | 256K | 65K |
Dans les coulisses de la Doubao Seed API : raisonnement, codage et niveaux optimisés pour les coûts
La Doubao Seed API réunit toute la gamme Seed de ByteDance derrière une seule clé compatible OpenAI, avec un modèle phare de raisonnement, un modèle dédié au codage, ainsi que des niveaux Lite et Mini optimisés pour les coûts, tous dotés d’une fenêtre de contexte de 256K tokens et d’une tarification à l’usage à partir de $0.1 par million de tokens.

Raisonnement de pointe avec la Doubao Seed API
Le niveau phare Seed 2.1 Pro constitue le socle de la famille avec un raisonnement haut de gamme, des capacités de codage et une résolution de problèmes de niveau entreprise sur un contexte de 256K tokens. Il maintient de longues chaînes de pensée en plusieurs étapes dans une seule requête, afin de résoudre les tâches analytiques et de planification difficiles sans troncature. Choisissez-le lorsque l’exactitude sur les charges de travail les plus exigeantes prime sur le coût brut, à $0.9 par million de tokens d’entrée.
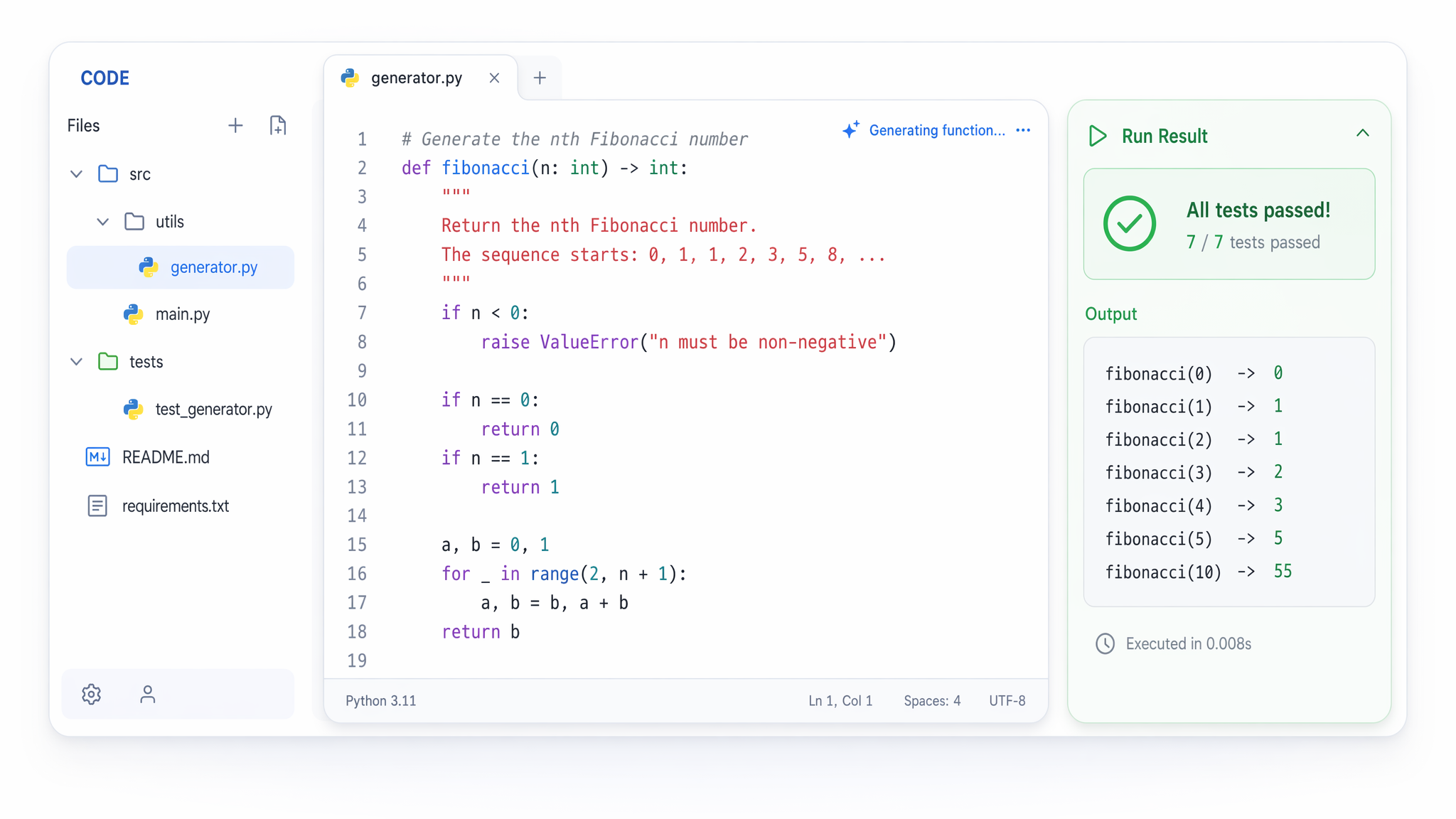
Un modèle dédié à l’ingénierie logicielle
Seed 2.0 Code Preview est spécialement optimisé pour les agents de codage, la compréhension de dépôts et l’ingénierie logicielle au quotidien. La même fenêtre de 256K lui permet de parcourir tout un codebase avant d’écrire de nouvelles fonctions, de refactoriser des modules ou d’expliquer une logique inconnue. Il s’intègre également aux assistants de codage IA via Atlas Cloud Skills et le MCP Server, au prix de $0.5 par million de tokens d’entrée.

Associer chaque tâche au bon niveau Seed
Besoin d’une qualité de production sans le tarif du modèle phare ? Seed 2.0 Lite offre des résultats proches du niveau phare à $0.25 par million de tokens d’entrée, tandis que Seed 2.0 Mini descend à seulement $0.1 pour la classification à grand volume, le routage et les étapes légères d’agents. Comme toute la gamme partage une interface unique, vous pouvez diriger chaque requête vers le niveau le moins cher qui reste à la hauteur.

Contexte de 256K tokens sur la Doubao Seed API
Chaque modèle de la famille dispose d’une fenêtre de contexte de 256K tokens, soit plusieurs centaines de pages de texte dans un seul appel. Fournissez-lui de longs documents, des dépôts multifichiers ou un historique de conversation étendu : il conserve une vue d’ensemble complète. Les réponses sont diffusées token par token via des server-sent events standard, afin que votre interface reste réactive même sur les tâches volumineuses.
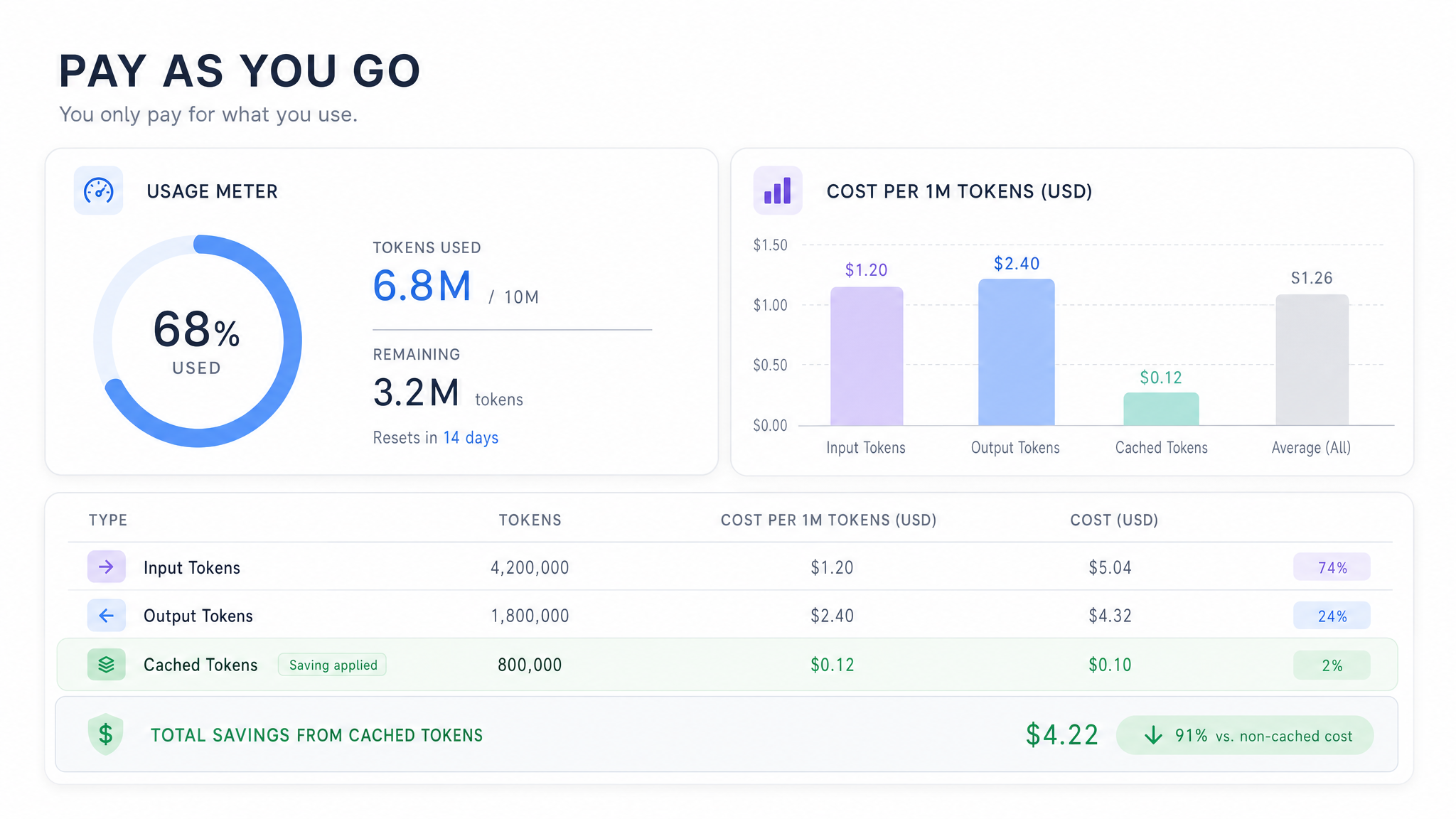
Tarification transparente des tokens à l’usage
La tarification est entièrement à l’usage, facturée par token, sans abonnement requis. La mise en cache des prompts réduit fortement le coût des contextes répétés, avec les entrées mises en cache sur Seed 2.0 Mini facturées seulement $0.02 par million de tokens. Les prompts plus longs passent à des paliers tarifaires supérieurs publiés clairement, afin que vos dépenses restent prévisibles lorsque les charges de travail passent du prototype à la production.
Une seule clé pour toute la Doubao Seed API
Faut-il standardiser sur un seul niveau ou en combiner plusieurs ? Une unique clé compatible OpenAI donne accès à tous les modèles Doubao Seed, du modèle phare 2.1 Pro au Mini économique, en passant par la ligne 1.6 de génération précédente. Le code existant basé sur les SDK OpenAI fonctionne après remplacement de la base-URL et de la clé, ce qui vous permet d’envoyer les requêtes difficiles vers Pro et les sous-étapes peu coûteuses vers Mini au sein d’une même application.
Un prompt, trois builds : comparatif direct de la Doubao Seed API
Donnez le même prompt à trois modèles sur la Doubao Seed API et comparez la façon dont chacun transforme une instruction unique en une page HTML fonctionnelle et autonome.
Crée une page HTML complète en un seul fichier — un document .html unique avec tout le CSS et le JavaScript intégrés, zéro dépendance externe, aucun lien CDN, aucune police web, aucun fichier image ni data URI. Chaque élément visuel doit être dessiné procéduralement à l’exécution avec la Canvas 2D API ou du SVG inline ; il ne doit y avoir aucun bitmap, aucune photographie ni aucun emoji. La page est un canvas génératif en temps réel intitulé quelque chose comme « Harvest Field — Aerial Geometry Studio », et tout le concept repose sur une vue zénithale, comme vue de dieu, d’une terre agricole cultivée que l’utilisateur façonne avec des sliders, pendant qu’une unique moissonneuse-batteuse pixelisée la parcourt lentement, effaçant des bandes ordonnées dans une culture brute — ce moment calme et satisfaisant où l’ordre est découpé dans le chaos. Composition et rendu : remplis tout le viewport avec une grille rectangulaire régulière de parcelles de champ évoquant le seigle, disposées en formes vectorielles plates avec un léger relief isométrique / faux 2.5D, afin que chaque parcelle se lise comme un bloc bas plutôt que comme un simple rectangle plat. Éclaire la scène avec un unique soleil directionnel de crépuscule venant en rasant depuis un coin (chaud, angle bas) ; chaque parcelle et la moissonneuse doivent projeter une longue ombre douce dans la direction opposée afin de renforcer la solidité géométrique et bloc du champ. La palette doit rester sobre, raffinée, dans une famille de tons terreux : jaune moutarde, ocre, vert olive, et un seul accent de terre labourée brûlée, brun ombre calciné, pour le sol fraîchement retourné — pas de néon, pas de couleurs primaires pures, garde un rendu haut de gamme et feutré. Le style général doit être un croisement entre vectoriel plat et micro-relief isométrique, précis et architectural. Comportement vivant : dans chaque parcelle, dessine de fines lignes de semis en rangs (lignes parallèles très fines) dont la densité est ajustable. Une seule moissonneuse-batteuse pixelisée — un petit sprite anguleux dessiné à partir de quelques rectangles — est le SEUL élément mobile et le seul qui rompt la symétrie de la grille. Elle avance lentement soit le long d’un chemin en spirale vers l’intérieur, soit selon un parcours serpentin en boustrophédon (回字 / aller-retour) à travers les parcelles. En se déplaçant, elle doit « effacer » la culture sur pied directement dans sa largeur de coupe et laisser derrière elle, en temps réel, des bandes de récolte — bandes claires et sombres alternées, comme une pelouse tondue ou la trace réelle de la barre de coupe d’une moissonneuse — peintes de façon permanente sur le champ jusqu’à la réinitialisation. La récolte est une animation continue et autonome via requestAnimationFrame ; la regarder remplir le champ doit produire une sensation calme et hypnotique. Interactivité — tous les contrôles sont des sliders (avec quelques petits toggles/boutons) dans un panneau latéral ou inférieur propre et minimal, et chacun doit réagir en direct sans rechargement de page : un slider pour le nombre de parcelles (résolution de grille, par ex. de 3×3 à 12×12), un slider pour la densité des rangs de semis, un slider pour la teinte des cultures (faisant varier la culture sur pied dans la gamme moutarde-ocre-olive), un slider pour la progression de la récolte ou la vitesse de la moissonneuse, et un toggle pour basculer le chemin de la moissonneuse entre spirale et boustrophédon. Prévois un bouton discret Reset/Replant qui régénère le champ et relance le passage. Changer le nombre de parcelles ou la densité doit régénérer la mise en page avec fluidité ; faire glisser la teinte doit recolorer en temps réel. Rends le tout entièrement responsive afin que la grille et les ombres soient recalculées au redimensionnement de la fenêtre, maintiens une fréquence d’images fluide, et veille à ce que le code soit propre et autonome pour s’ouvrir correctement par double-clic sur le fichier. Ce n’est ni un jeu ni un dashboard — c’est un instrument d’art génératif. Pousse aussi loin que possible la géométrie procédurale, l’animation du chemin et le couplage des paramètres ; la qualité de l’ombrage isométrique, les longues ombres crépusculaires et la netteté des bandes de récolte doivent être ce qui fait ressortir ce rendu.
Generated with Doubao Seed 2.1 Pro on Atlas Cloud
Generated with DeepSeek V4 Pro on Atlas Cloud
Generated with Doubao Seed 2.0 Pro on Atlas Cloud
Crée un fichier HTML unique et autonome (CSS et JavaScript inline uniquement — absolument aucune bibliothèque externe, aucun CDN, aucun framework, aucune police ni URL d’image) qui affiche un établi interactif de démontage de mouvement de montre de poche mécaniquement plausible, entièrement dessiné en SVG et/ou Canvas. La page doit s’ouvrir et fonctionner correctement par simple double-clic dans n’importe quel navigateur moderne, avec tout calculé et animé en temps réel. LA SCÈNE. Une vue de dessus d’un mouvement de montre en laiton éclaté, disposé sur un établi d’atelier. Rends, sous forme d’art vectoriel vivant, un barillet de ressort moteur, un train d’engrenages empilé (barrel wheel → center wheel → third wheel → fourth wheel → escape wheel), une ancre qui oscille d’avant en arrière, un balancier avec un spiral, ainsi que des aiguilles des heures/minutes/secondes balayant un discret cercle de minuterie. Dessine de vraies dents d’engrenage (flancs de style développante, pas de simples cercles), un engrènement correct au niveau des cercles primitifs, et des axes, rubis, ponts et vis visibles. L’ensemble de l’assemblage est composé concentriquement autour du cœur du mouvement ; le panneau de contrôle est glissé dans un coin sombre. LA MÉCANIQUE (c’est le point essentiel — fais-en une vraie simulation, pas un simulacre). Modélise le train d’engrenages avec de vrais rapports : la vitesse angulaire de chaque roue est égale à celle de sa voisine multipliée par le rapport négatif de leurs nombres de dents, de sorte que les roues engrenées contre-tournent visiblement à des vitesses proportionnelles et que les dents s’emboîtent sans se chevaucher ni glisser. L’échappement doit réellement faire tic-tac : la roue d’échappement avance dent par dent, par pas discrets, verrouillée puis libérée par l’ancre oscillante, elle-même entraînée par le balancier qui bat à une fréquence fixe. Chaque libération (« tic ») produit un pas net de la roue d’échappement et un tic audible avec la Web Audio API (synthétisé, sans fichiers audio). L’aiguille des secondes avance au rythme de l’échappement ; les aiguilles des minutes et des heures en dérivent via les rapports d’engrenage. Pilote l’animation avec requestAnimationFrame et le temps réellement écoulé afin que le timing reste précis. LES INTERACTIONS (toutes doivent réagir en direct). - Une couronne / molette de remontage déplaçable : fais-la glisser (souris ou tactile) pour remonter le ressort moteur — une jauge de remontage se remplit et la spirale du ressort se resserre visiblement. Relâche pour laisser l’énergie stockée se décharger et alimenter le train ; le mouvement tourne jusqu’à ce que le ressort se détende, puis ralentit jusqu’à l’arrêt. - Un slider « rate » qui module le rythme / la vitesse de marche afin de pouvoir observer le tic-tac lentement ou le voir s’emballer. - Un slider « explode » qui sépare continûment les composants empilés le long de leurs axes, depuis l’assemblage complet jusqu’à un diagramme éclaté en éventail, avec interpolation fluide, lignes guides de connexion entre les pièces séparées, et tous les éléments qui continuent à tourner correctement à n’importe quel niveau d’éclatement. - Au survol (ou au toucher), n’importe quel composant doit agir comme une loupe de joaillier : mettre cette pièce en évidence, estomper le reste, et afficher une infobulle flottante avec le nom de la pièce et une description en une ligne de sa fonction. - Boutons : Wind, Release, Reset. LE STYLE. Esthétique industrielle réaliste d’atelier d’horlogerie : laiton chaud vieilli, gris acier patiné, fond noir encre profond, reflets métalliques nets, dents d’engrenage finement gravées et ponts biseautés. Simule un unique faisceau de lumière de fenêtre arrivant en rasant depuis le coin supérieur gauche de l’établi, afin que les pièces projettent des ombres douces et allongées, et laisse des reflets spéculaires se déplacer le long des faces des engrenages lorsqu’ils tournent. Utilise des dégradés, des filtres et un grain subtil pour donner de la profondeur. Contrôles et libellés propres, lisibles, de style HUD, dans le coin sombre. EXIGENCES. Tout dans un seul fichier .html ; mise en page responsive qui s’adapte au viewport ; animation fluide à 60fps ; aucun graphique temporaire — le mouvement doit être dessiné procéduralement et réellement couplé mécaniquement, de sorte qu’un modèle capable produise une montre qui se remonte, s’engrène et fait tic-tac pour de vrai, tandis qu’un modèle faible s’effondrerait en simples cercles statiques qui tournent. Ajoute de courts commentaires inline nommant les rapports d’engrenage et la logique de l’échappement.
Generated with Doubao Seed 2.1 Pro on Atlas Cloud
Generated with DeepSeek V4 Pro on Atlas Cloud
Generated with Doubao Seed 2.0 Pro on Atlas Cloud
Construisez des systèmes de production avec la Doubao Seed API
Des agents de code et du refactoring à l’échelle d’un dépôt au chat en temps réel et aux pipelines à haut volume, les niveaux de la Doubao Seed API s’intègrent à chaque couche d’une stack de production derrière une seule clé compatible OpenAI.

Créez des assistants de code avec la Doubao Seed API
Seed 2.0 Code Preview est optimisé pour les agents de code et la compréhension des dépôts, avec la lecture d’un contexte de 256K tokens en un seul appel. Intégrez-le à des copilotes d’IDE, des reviewers de PR et des bots de refactoring via Atlas Cloud Skills.

Orchestrez des agents multi-étapes
Laissez Seed 2.0 Pro gérer la planification et l’orchestration des outils, puis déléguez les sous-étapes peu coûteuses à Mini afin de garder un coût par exécution prévisible. Cette répartition alimente les agents de recherche, l’automatisation des workflows et les pipelines qui enchaînent de nombreux appels.

Exécutez des pipelines d’inférence à haut volume
Vous lancez des milliers d’appels pour de la classification, du tagging ou de l’extraction structurée ? Seed 2.0 Mini est conçu pour les scénarios en périphérie et l’automatisation sensible aux coûts, afin que l’économie par token reste avantageuse à grande échelle.

Analysez des documents longs en profondeur
Lorsqu’une tâche couvre de longs contrats, des articles de recherche ou des bases de connaissances complètes, Seed 2.0 Pro applique un raisonnement approfondi sur sa fenêtre de 256K tokens. Les équipes l’utilisent pour l’analyse, l’extraction et les questions-réponses sur de grands documents.

Acheminez le trafic sur la Doubao Seed API
Une seule clé compatible OpenAI donne accès à tous les niveaux de la Doubao Seed API, du modèle phare Pro à l’efficace Mini. Acheminez les requêtes difficiles vers le modèle le plus puissant et les traitements à haut volume vers le moins coûteux afin de maîtriser les dépenses.

Alimentez le chat en temps réel avec la Doubao Seed API
Seed 2.1 Turbo et Seed 1.6 Flash sont conçus pour une latence ultra-faible, un débit élevé et des réponses en streaming. Ils permettent aux chatbots, assistants en direct et expériences produit interactives de rester réactifs même sous un volume important de requêtes.
Doubao Seed API face aux meilleurs modèles de raisonnement et de code sur Atlas Cloud
Découvrez comment Doubao Seed API se compare aux principaux modèles de raisonnement et de code disponibles sur Atlas Cloud en matière de fenêtre de contexte, de limite de sortie et de tarification transparente par token.
| Modèle | Fournisseur | Fenêtre de contexte | Sortie maximale | Prix (entrée / sortie par 1M tokens) |
|---|---|---|---|---|
| Doubao Seed 2.1 Pro | ByteDance | 256K | 256K | $0.90 / $4.50 |
| Doubao Seed 2.0 Code Preview | ByteDance | 256K | 128K | $0.50 / $3.00 (prompt ≤128K), $1.00 / $6.00 (>128K) |
| Doubao Seed 2.1 Turbo | ByteDance | 256K | 256K | $0.45 / $2.25 |
| DeepSeek V4 Pro | DeepSeek | 1M | 384K | $1.74 / $3.45 |
| Kimi K2.7 Code | Moonshot AI | 256K | 256K | $0.95 / $4.00 |
| GLM 5.2 | Zhipu AI | 1M | 128K | $1.40 / $4.40 |
| Qwen3.6 Plus | Alibaba Qwen | 1M | 64K | $0.50 / $3.00 (prompt ≤256K), $2.00 / $6.00 (>256K) |
Comment utiliser Seed sur Atlas Cloud
Soyez opérationnel en quelques minutes — suivez ces étapes simples pour intégrer et déployer des modèles via la plateforme Atlas Cloud.
Créer un compte Atlas Cloud
Inscrivez-vous sur atlascloud.ai et complétez la vérification. Les nouveaux utilisateurs reçoivent des crédits gratuits pour explorer la plateforme et tester les modèles.
Pourquoi Utiliser Seed sur Atlas Cloud
Combiner les modèles Seed avancés avec la plateforme accélérée par GPU d'Atlas Cloud offre des performances, une évolutivité et une expérience développeur inégalées.
Performance et Flexibilité
Faible Latence :
Inférence optimisée par GPU pour un raisonnement en temps réel.
API Unifiée :
Exécutez Seed, GPT, Gemini et DeepSeek avec une seule intégration.
Tarification Transparente :
Facturation prévisible par token avec options serverless.
Entreprise et Échelle
Expérience Développeur :
SDK, analytiques, outils de fine-tuning et modèles.
Fiabilité :
99,99% de disponibilité, RBAC et journalisation conforme.
Sécurité et Conformité :
SOC 2 Type II, alignement HIPAA, souveraineté des données aux États-Unis.
Doubao Seed API : questions fréquentes des développeurs
Doubao Seed API est le point de terminaison unifié d’Atlas Cloud pour la famille Seed de grands modèles de langage de ByteDance, conçue pour le raisonnement, le codage et les charges de travail agentiques à grand volume. Elle couvre les modèles phares Seed 2.1 Pro et Seed 2.0 Pro, le modèle dédié Seed 2.0 Code Preview, les niveaux Lite et Mini économiques, ainsi que les générations éprouvées Seed 1.8 et 1.6. Une seule clé compatible OpenAI donne accès à tous les modèles, ce qui vous permet d’associer le bon niveau à chaque tâche via une interface unique.
La gamme va du raisonnement de pointe à l’inférence à haut débit. Seed 2.1 Pro et Seed 2.0 Pro prennent en charge les tâches de raisonnement et d’agents les plus exigeantes, Seed 2.1 Turbo vise les réponses à faible latence, et Seed 2.0 Code Preview est spécialisé dans l’ingénierie logicielle. Le trafic sensible aux coûts peut être dirigé vers Seed 2.0 Lite et Mini, tandis que les checkpoints antérieurs Seed 1.8 et 1.6 restent disponibles pour les équipes qui privilégient un comportement stable et prévisible.
Inscrivez-vous sur Atlas Cloud, générez une clé API, puis pointez votre SDK OpenAI existant vers l’URL de base d’Atlas Cloud. La facturation se fait à l’usage, avec une tarification transparente par token et sans abonnement, et les nouvelles versions de Seed sont disponibles dès le Day-0. Commencez à développer dès aujourd’hui.
Oui. Tous les modèles Doubao utilisent le format standard chat-completions, avec temperature, top_p, des pénalités frequency et presence, jusqu’à quatre séquences d’arrêt, ainsi que le streaming SSE. Votre code SDK OpenAI existant fonctionne après simple remplacement de l’URL de base et de la clé, sans réécrire votre logique de requête.
Tous les modèles de la famille offrent une fenêtre de contexte de 256K tokens (262K) pour les grands documents et les longues conversations. La sortie maximale dépend du niveau : jusqu’à 262K tokens sur les modèles Seed 2.1, 131K sur les niveaux Seed 2.0, et 65K ou 32K sur les checkpoints antérieurs 1.8 et 1.6.
Atlas Cloud propose un accès SDK en Python, JavaScript, Swift, Kotlin, Java et Dart. Vous pouvez également connecter les modèles à des assistants de codage IA via Atlas Cloud Skills et le MCP Server, ce qui est pratique pour les agents sensibles au contexte du dépôt construits sur Seed 2.0 Code Preview.
La tarification est à l’usage par token, sans abonnement. Les tarifs standard commencent à $0.075 par million de tokens d’entrée sur Seed 1.6 Flash et à $0.1 sur Seed 2.0 Mini, jusqu’à $0.9 en entrée et $4.5 en sortie sur le modèle phare Seed 2.1 Pro. Comme tous les niveaux sont accessibles avec une seule clé, vous pouvez optimiser vos dépenses en acheminant chaque requête vers le modèle le moins cher qui atteint le niveau de qualité requis.
Absolument. Une seule clé Atlas Cloud donne accès à toutes les générations Seed ; un schéma courant consiste donc à diriger les requêtes difficiles vers Seed 2.1 Pro ou Seed 2.0 Pro, et à déléguer les sous-étapes à fort volume à Mini ou Lite. Vous maintenez ainsi la qualité là où elle compte, tout en maîtrisant le coût par exécution.
ByteDance positionne les modèles Seed 2.1 et 2.0 face aux systèmes américains de pointe sur les tâches de raisonnement et de codage, et des évaluations indépendantes font état de résultats compétitifs en mathématiques difficiles et en ingénierie logicielle. Pour les développeurs, l’intérêt pratique est que Doubao Seed API offre ce niveau de capacité avec un tarif par token bas et transparent, nettement inférieur à celui de la plupart des modèles phares occidentaux.
Explorer Plus de Familles
Seedance 2.0
L'API Seedance 2.0 vous donne un accès en production au modèle vidéo multimodal de ByteDance — des entrées quadrimodales (texte, image, vidéo, audio) et un système « Universal Reference » leader du secteur qui verrouille la composition, les mouvements de caméra et les actions des personnages à travers les plans. Intégrez un contrôle de niveau réalisateur avec un seul appel d'API, un tarif fixe de 0,09 $/s, une clé instantanée et aucune liste d'attente — le tout soutenu par une disponibilité et une conformité de niveau entreprise. Seedance 2.0 Native 4K est désormais disponible !
GPT Image 2
L'API GPT Image 2 offre aux développeurs un accès au dernier modèle d'image d'OpenAI, le successeur de GPT Image 1.5. Elle génère et modifie des images avec un rendu de texte précis pour les caractères latins et CJK, ainsi qu'une composition solide pour les affiches, les maquettes et les infographies. Sur Atlas Cloud, vous y accédez via une API unifiée aux côtés de plus de 300 modèles, avec des crédits gratuits, une disponibilité de 99,99 % et sans aucune vérification d'organisation OpenAI requise.
Seedream 5.0 Pro
L'API Seedream 5.0 Pro offre aux développeurs le modèle d'édition d'images contrôlable de ByteDance sur Atlas Cloud. Elle positionne les modifications avec précision à l'aide d'ancrages et de coordonnées, sépare les images en calques modifiables, fusionne de multiples références et fait correspondre les couleurs et matériaux exacts, avec du texte multilingue en 2K et 3K. Sur Atlas Cloud, vous y accédez via une seule clé !
Gemini Omni Flash
La Gemini Omni API apporte à votre stack le modèle multimodal de génération et d'édition vidéo de Google DeepMind, présenté à Google I/O 2026. Gemini Omni fusionne le moteur de raisonnement de Gemini avec les médias génératifs : il accepte n'importe quelle combinaison de texte, d'images, de vidéo et d'audio pour produire des résultats cohérents et ancrés dans la connaissance. Affinez vos résultats par simple conversation — remplacez des objets, réécrivez des scènes, changez de style — tandis que la physique, les personnages et la continuité restent intacts. Atlas Cloud propose toute la gamme Gemini Omni Flash — texte vers vidéo, image vers vidéo avec jusqu'à 7 images de référence, et référence vers vidéo — via une API unifiée, avec une tarification transparente à la seconde à partir de $0.112 et sans abonnement. Commencez à développer dès aujourd'hui.
Grok Imagine
La Grok Imagine API offre aux développeurs la génération d'images, de vidéos et d'audio de xAI dans une seule suite. Elle produit des images jusqu'à 2K avec un rendu de texte multilingue, ainsi que des vidéos allant jusqu'à 15 secondes avec un audio natif synchronisé et une édition basée sur des références. Sur Atlas Cloud, une seule clé exécute chaque mode Grok Imagine, ce qui vous permet de passer d'une image, d'une vidéo et d'un audio à l'autre sans configuration distincte, à partir de 0,02 $ par image et 0,05 $ par seconde.
Les modèles créatifs les plus puissants de Google sont tous disponibles sur Atlas Cloud. Veo 3.1 offre une génération de vidéos cinématographiques, Nano Banana 2 permet de créer des images haute fidélité, et Gemini apporte une intelligence multimodale à chaque flux de travail. Accédez à la suite complète de modèles Google via une seule API key avec une disponibilité Day-0 et une tarification à l'usage (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini apporte la génération de vidéos multimodale de ByteDance aux flux de travail où la vitesse et les coûts sont primordiaux. Il offre les capacités de base de Seedance 2.0 avec une empreinte plus légère — une génération plus rapide, un coût par vidéo réduit et la même intégration API que celle que vous utilisez déjà. Pour les équipes qui gèrent des pipelines à haut volume ou du prototypage à grande échelle, Mini est le choix par défaut pratique.
ByteDance
De la génération de vidéos cinématiques à la création d'images haute fidélité, les modèles les plus puissants de ByteDance sont disponibles sur Atlas Cloud. Exécutez Seedance et Seedream à grande échelle avec les prix d'inférence les plus bas et aucune surcharge d'infrastructure.
Alibaba
Atlas Cloud rassemble l'ensemble de la gamme de modèles d'Alibaba sous une seule API : Qwen pour les tâches linguistiques et d'imagerie, et Wan pour la génération de vidéos jusqu'en 1080p. Accédez à chaque modèle avec une tarification à l'usage (pay-as-you-go) sans abonnement. L'API Alibaba est disponible via une URL de base unique en utilisant votre client existant compatible avec OpenAI.
OpenAI
Atlas Cloud vous donne accès à l'ensemble de la gamme de l'API OpenAI, de GPT Image 2 pour la génération d'images à Sora 2 pour la vidéo. Chaque modèle est disponible en paiement à l'usage sans engagement mensuel. Intégrez-le en remplaçant simplement l'URL de base à l'aide de l'API compatible OpenAI.
xAI
Créez des pipelines complets d'images et de vidéos en utilisant la xAI API sur Atlas Cloud. Générez en 2K, éditez avec des images de référence et animez des images en clips synchronisés avec l'audio.
Kwaivgi
L'API Kwaivgi à 15 % en dessous du tarif standard. Atlas Cloud offre un accès Day-0 aux nouvelles versions de Kling avec une tarification à l'usage et sans limite de postes. Un seul compte, une seule clé, tous les modèles Kling du niveau standard au niveau master.
Articles recommandés
Guides, tutoriels et actualités produit pour tirer le meilleur d'Atlas Cloud.








